Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Compile e implemente el primer agente de IA mediante plantillas de Databricks Apps. En este tutorial:
- Compile e implemente el agente desde la interfaz de usuario de Databricks Apps.
- Chatear con el agente mediante una interfaz de chat pregenerada.
Prerrequisitos
Habilite Databricks Apps en el área de trabajo. Consulte Configuración del área de trabajo y el entorno de desarrollo de Databricks Apps.
Implementación de la plantilla del agente
Empiece a usar una plantilla de agente precompilada desde el repositorio de plantillas de aplicación de Databricks.
En este tutorial se usa la agent-openai-agents-sdk plantilla, que incluye:
- Un agente creado mediante el SDK del agente de OpenAI
- Código de inicio para una aplicación de agente con una API REST conversacional y una interfaz de usuario de chat interactiva
- Código para evaluar el agente mediante MLflow
Instale la plantilla de aplicación mediante la interfaz de usuario del área de trabajo. Esto instala la aplicación y la implementa en un recurso de cómputo en el área de trabajo.
En el área de trabajo de Databricks, haga clic en + Nueva>aplicación.
Haga clic en Agentes>Agente - SDK de OpenAI Agents.
Cree un nuevo experimento de MLflow con el nombre
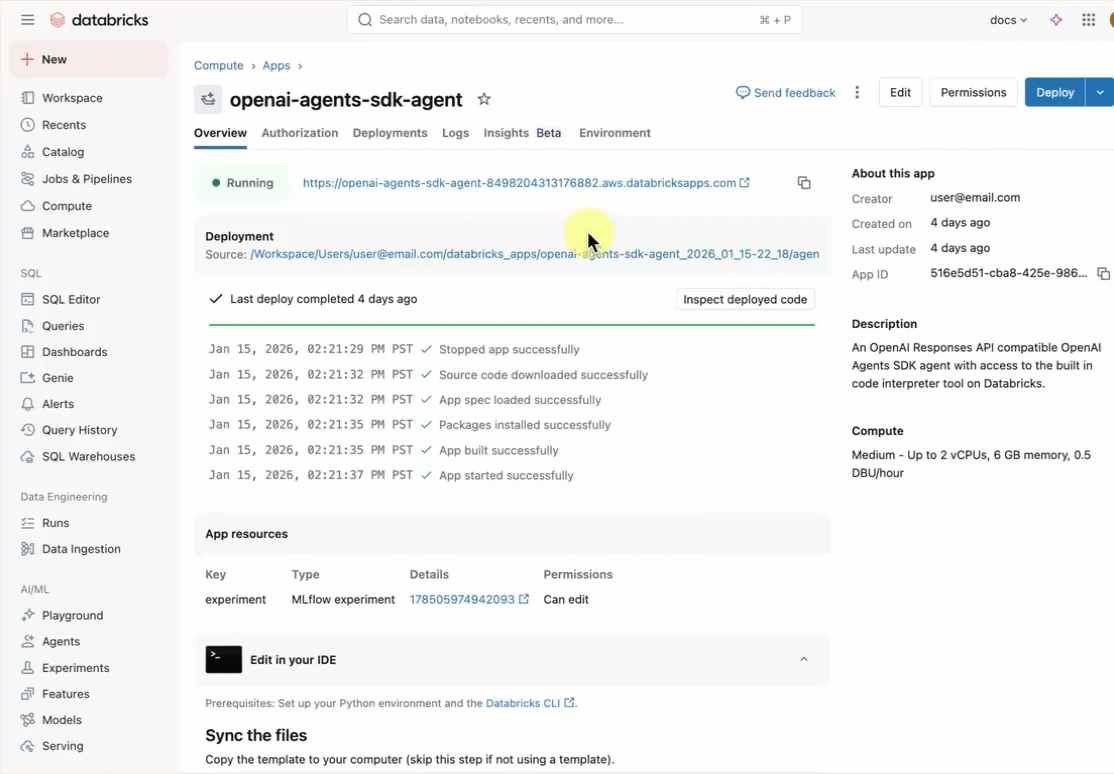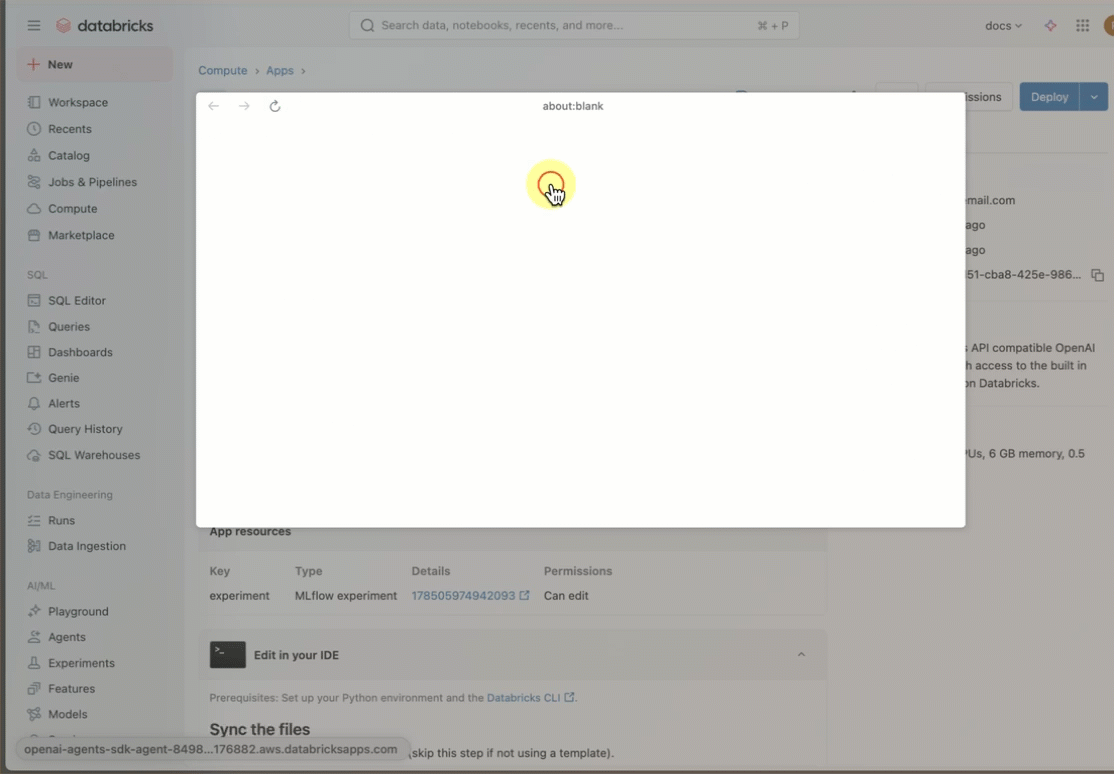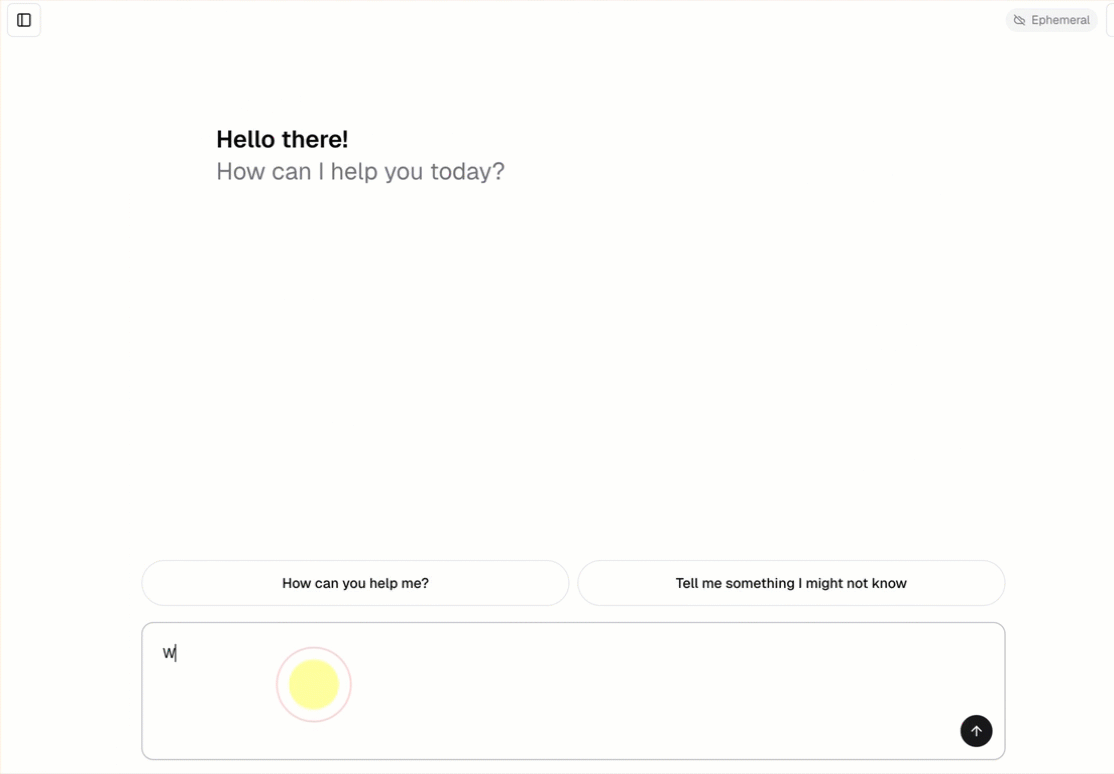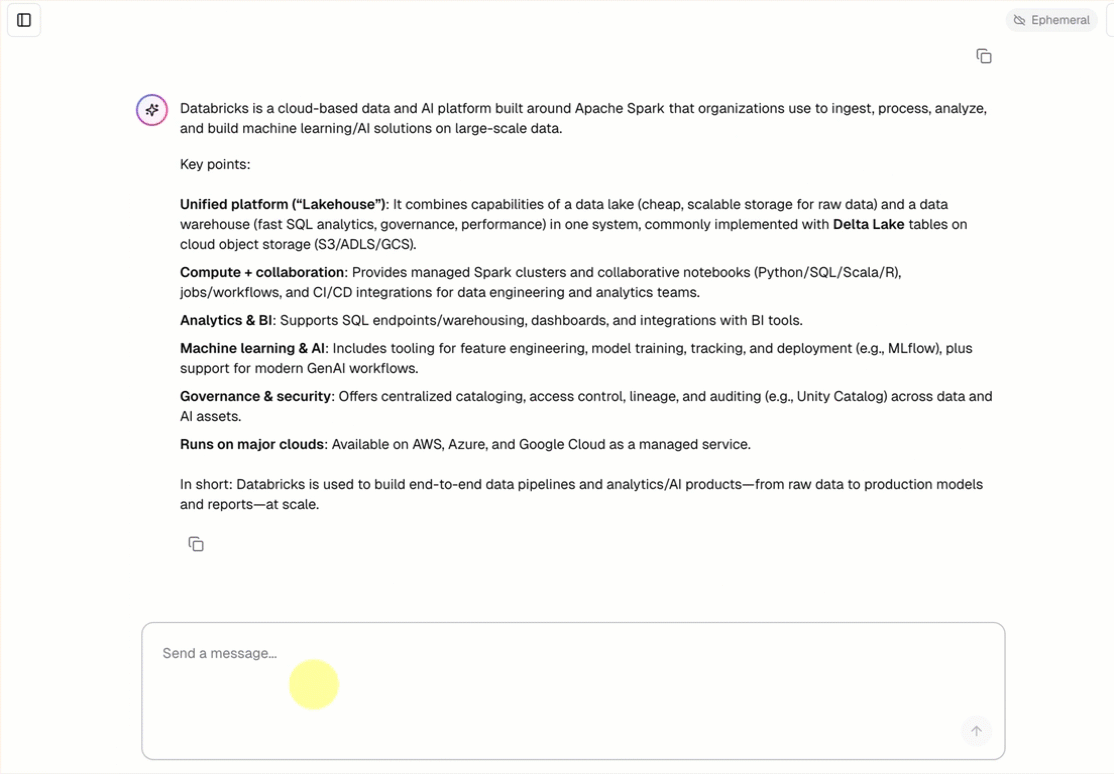
openai-agents-templatey complete el resto de la configuración para instalar la plantilla.Después de crear la aplicación, haga clic en la dirección URL de la aplicación para abrir la interfaz de usuario de chat.
Descripción de la aplicación del agente
La plantilla del agente muestra una arquitectura lista para producción con estos componentes clave:
MLflow AgentServer: un servidor fastAPI asincrónico que controla las solicitudes del agente con seguimiento integrado y observabilidad. AgentServer proporciona el punto de conexión para consultar el /invocations agente y administra automáticamente el enrutamiento de solicitudes, el registro y el control de errores.
SDK de agentes de OpenAI: la plantilla usa el SDK de agentes de OpenAI como marco de trabajo del agente para la administración de conversaciones y la orquestación de herramientas. Puede desarrollar agentes utilizando cualquier framework. La clave está en envolver tu agente con la interfaz MLflow ResponsesAgent.
ResponsesAgent interfaz: esta interfaz garantiza que el agente funcione en diferentes marcos e se integre con las herramientas de Databricks. Compile el agente mediante el SDK de OpenAI, LangGraph, LangChain o Python puro y, a continuación, encapsularlo con ResponsesAgent para obtener compatibilidad automática con la implementación de AI Playground, Agent Evaluation y Databricks Apps.
Servidores MCP (Protocolo de contexto de modelo): la plantilla se conecta a los servidores MCP de Databricks para acceder a los agentes a herramientas y orígenes de datos. Consulte Protocolo de contexto de modelo (MCP) en Databricks.

Pasos siguientes
Aprenda a crear un agente personalizado: Creación de un agente de IA e implementación en Databricks Apps