Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe cómo crear una canalización de datos no estructurada para aplicaciones de inteligencia artificial de generación. Las canalizaciones no estructuradas son particularmente útiles para las aplicaciones de generación Retrieval-Augmented (RAG).
Obtenga información sobre cómo convertir contenido no estructurado como archivos de texto y ARCHIVOS PDF en un índice vectorial que los agentes de IA u otros recuperadores pueden consultar. También aprenderá a experimentar y ajustar la canalización para optimizar la fragmentación, la indexación y el análisis de datos, lo que le permite solucionar problemas y experimentar con la canalización para lograr mejores resultados.
Cuaderno de canalización de datos no estructurado
En el cuaderno siguiente se muestra cómo implementar la información de este artículo para crear una canalización de datos no estructurada.
Canalización de datos no estructurada de Databricks
Componentes clave de la canalización de datos
La base de cualquier aplicación RAG con datos no estructurados es la canalización de datos. Esta canalización es responsable de mantener y preparar los datos no estructurados en un formato que la aplicación RAG puede usar de forma eficaz.

Aunque esta canalización de datos puede ser compleja en función del caso de uso, estos son los componentes clave que debe tener en cuenta al compilar por primera vez la aplicación RAG:
- Composición e ingesta de corpus: seleccione los orígenes de datos y el contenido adecuados en función del caso de uso específico.
-
Preprocesamiento de datos: transforme los datos sin procesar en un formato limpio y coherente adecuado para la inserción y recuperación.
- Análisis: extraiga información relevante de los datos sin procesar mediante técnicas de análisis adecuadas.
-
Enriquecimiento: enriquezca los datos con metadatos adicionales y quite el ruido.
- Extracción de metadatos: extraiga metadatos útiles para implementar una recuperación de datos más rápida y eficaz.
- Desduplicación: analice los documentos para identificar y eliminar duplicados o documentos casi duplicados.
- Filtrado: elimine documentos irrelevantes o no deseados de la colección.
- Fragmentación: divida los datos analizados en fragmentos más pequeños y administrables para una recuperación eficaz.
- Inserción: convierta los datos de texto fragmentados en una representación vectorial numérica que capture su significado semántico.
- Indexación y almacenamiento: cree índices vectoriales eficaces para optimizar el rendimiento de la búsqueda.
Composición e ingesta del corpus
La aplicación RAG no puede recuperar la información necesaria para responder a una consulta de usuario sin el corpus de datos correcto. Los datos correctos dependen completamente de los requisitos y objetivos específicos de la aplicación, lo que hace fundamental dedicar tiempo a comprender los matices de los datos disponibles. Para más información, consulte Flujo de trabajo para desarrolladores de aplicaciones de IA generativas.
Por ejemplo, al compilar un bot de soporte al cliente, puede considerar la posibilidad de incluir lo siguiente:
- Documentos de la base de conocimiento
- Preguntas más frecuentes (FAQ)
- Manuales y especificaciones del producto
- Guías de solución de problemas
Interactúe con expertos en dominio y partes interesadas desde el principio de cualquier proyecto para ayudar a identificar y conservar el contenido relevante que podría mejorar la calidad y la cobertura del corpus de datos. Pueden proporcionar información sobre los tipos de consultas que es probable que los usuarios envíen y ayuden a priorizar la información más crítica que se va a incluir.
Databricks recomienda ingerir datos de forma escalable e incremental. Azure Databricks ofrece varios métodos para la ingesta de datos, incluidos conectores totalmente administrados para aplicaciones SaaS e integraciones de API. Como procedimiento recomendado, los datos de origen sin procesar deben ingerirse y almacenarse en una tabla de destino. Este enfoque garantiza la conservación, la rastreabilidad y la auditoría de los datos. Consulte Conectores estándar en Lakeflow Connect.
Preprocesamiento de datos
Una vez ingeridos los datos, es esencial limpiar y dar formato a los datos sin procesar en un formato coherente adecuado para insertarlos y recuperarlos.
Análisis
Después de identificar los orígenes de datos adecuados para la aplicación del recuperador, el siguiente paso es extraer la información necesaria de los datos sin procesar. Este proceso, conocido como análisis, implica transformar los datos no estructurados en un formato que la aplicación RAG pueda usar de forma eficaz.
Las técnicas y herramientas de análisis específicas que uses dependen del tipo de datos con los que trabajas. Por ejemplo:
- Documentos de texto (PDF, documentos de Word): bibliotecas comerciales como unstructured y PyPDF2 pueden procesar varios formatos de archivo y proporcionar opciones para personalizar el proceso de análisis sintáctico.
- Documentos HTML: Las bibliotecas de análisis HTML como BeautifulSoup y lxml se pueden usar para extraer contenido relevante de las páginas web. Estas bibliotecas pueden ayudar a navegar por la estructura HTML, seleccionar elementos específicos y extraer el texto o los atributos deseados.
- Imágenes y documentos escaneados: Las técnicas de reconocimiento óptico de caracteres (OCR) suelen ser necesarias para extraer texto de imágenes. Entre las bibliotecas populares de OCR se incluyen bibliotecas de código abierto como Tesseract o versiones saaS como Amazon Textract, Azure AI Vision OCR y Google Cloud Vision API.
Procedimientos recomendados para el análisis de datos
El análisis garantiza que los datos estén limpios, estructurados y listos para insertar generación y búsqueda de vectores. Cuando analices los datos, ten en cuenta los siguientes procedimientos recomendados:
- Limpieza de datos: Preprocese el texto extraído para quitar información irrelevante o ruidosa, como encabezados, pies de página o caracteres especiales. Reduzca la cantidad de información innecesaria o incorrecta que necesita la cadena RAG para procesar.
- Control de errores y excepciones: implementa mecanismos de control y registro de errores para identificar y resolver los problemas detectados durante el proceso de análisis. Esto le ayuda a identificar y corregir problemas rápidamente. Hacerlo a menudo señala problemas subyacentes con la calidad de los datos de origen.
- Personalización de la lógica de análisis: en función de la estructura y el formato de los datos, es posible que tengas que personalizar la lógica de análisis para extraer la información más relevante. Aunque puede requerir esfuerzo adicional por adelantado, invierta el tiempo necesario para hacerlo, ya que a menudo evita muchos problemas de calidad posteriores.
- Evaluación de la calidad del análisis: evalúa periódicamente la calidad de los datos analizados revisando manualmente una muestra de la salida. Esto puede ayudarte a identificar cualquier problema o área para mejorar el proceso de análisis.
Enriquecimiento
Enriquecer los datos con metadatos adicionales y quitar ruido. Aunque el enriquecimiento es opcional, puede mejorar drásticamente el rendimiento general de la aplicación.
Extracción de metadatos
Generar y extraer metadatos que capturan información esencial sobre el contenido, el contexto y la estructura del documento pueden mejorar significativamente la calidad y el rendimiento de la recuperación de una aplicación RAG. Los metadatos proporcionan señales adicionales que mejoran la relevancia, habilitan el filtrado avanzado y admiten requisitos de búsqueda específicos del dominio.
Aunque las bibliotecas como LangChain y LlamaIndex proporcionan analizadores integrados capaces de extraer automáticamente los metadatos estándar asociados, a menudo resulta útil complementarlo con metadatos personalizados adaptados a su caso de uso específico. Este enfoque garantiza que se capture la información crítica específica del dominio, mejorando así la recuperación y generación posterior. También puede usar modelos de lenguaje grande (LLM) para automatizar la mejora de los metadatos.
Entre los tipos de metadatos se incluyen:
- Metadatos de nivel de documento: Nombre de archivo, direcciones URL, información de autor, marcas de tiempo de creación y modificación, coordenadas GPS y control de versiones de documentos.
- Metadatos basados en contenido: Palabras clave extraídas, resúmenes, temas, entidades con nombre y etiquetas específicas del dominio (nombres de producto y categorías como PII o HIPAA).
- Metadatos estructurales: Encabezados de sección, tabla de contenido, números de página y límites de contenido semántico (capítulos o subsecciones).
- Metadatos contextuales: Sistema de origen, fecha de ingesta, nivel de confidencialidad de datos, idioma original o instrucciones transnacionales.
El almacenamiento de metadatos junto con documentos fragmentados o sus incrustaciones correspondientes es esencial para un rendimiento óptimo. También ayudará a reducir la información recuperada y a mejorar la precisión y escalabilidad de la aplicación. Además, la integración de metadatos en canalizaciones de búsqueda híbrida, lo que significa combinar la búsqueda de similitud de vectores con filtrado basado en palabras clave, puede mejorar la relevancia, especialmente en grandes conjuntos de datos o escenarios de criterios de búsqueda específicos.
Desduplicación
Dependiendo de los orígenes, puede acabar con documentos duplicados o casi duplicados. Por ejemplo, si extrae de una o varias unidades compartidas, varias copias del mismo documento podrían existir en varias ubicaciones. Algunas de esas copias pueden tener modificaciones sutiles. De forma similar, la base de conocimiento puede tener copias de la documentación del producto o de borradores de entradas de blog. Si estos duplicados permanecen en el corpus, puede acabar con fragmentos altamente redundantes en el índice final que pueden reducir el rendimiento de la aplicación.
Puede eliminar algunos duplicados usando solo metadatos. Por ejemplo, si un elemento tiene el mismo título y fecha de creación, pero varias entradas de orígenes o ubicaciones diferentes, puede filtrarlas en función de los metadatos.
Sin embargo, esto puede no ser suficiente. Para ayudar a identificar y eliminar duplicados en función del contenido de los documentos, puede usar una técnica conocida como hash con distinción entre localidades. En concreto, una técnica denominada MinHash funciona bien aquí y una implementación de Spark ya está disponible en Spark ML. Funciona creando un hash para el documento en función de las palabras que contiene y luego puede identificar de manera eficiente duplicados o casi duplicados utilizando esos hashes. En un nivel muy alto, se trata de un proceso de cuatro pasos:
- Cree un vector de características para cada documento. Si es necesario, considere la posibilidad de aplicar técnicas como la eliminación de palabras vacías, stemming y lematización para mejorar los resultados y, a continuación, tokenizar en n-gramas.
- Ajuste un modelo MinHash y hashee los vectores mediante MinHash para la distancia de Jaccard.
- Realice una combinación por similitud mediante esos hashes para generar un conjunto de resultados para cada documento duplicado o casi duplicado.
- Filtre los duplicados que no desea conservar.
Un paso de desduplicación de línea base puede seleccionar los documentos para mantener arbitrariamente (como el primero en los resultados de cada duplicado o una elección aleatoria entre los duplicados). Una posible mejora sería seleccionar la versión "mejor" del duplicado mediante otra lógica (por ejemplo, actualización más reciente, estado de publicación o origen más autoritativo). Además, tenga en cuenta que puede que necesite experimentar con el paso de parametrización y el número de tablas hash utilizadas en el modelo MinHash para mejorar los resultados de coincidencia.
Para obtener más información, consulte la documentación de Spark para hash que distingue la localidad.
Filtrado
Algunos de los documentos que ingiere en el corpus pueden no ser útiles para el agente, ya sea porque son irrelevantes para su propósito, demasiado antiguos o no confiables, o porque contienen contenido problemático, como lenguaje dañino. Sin embargo, otros documentos pueden contener información confidencial que no desea exponer a través del agente.
Por lo tanto, considere la posibilidad de incluir un paso en la canalización para filtrar estos documentos mediante cualquier metadato, como aplicar un clasificador de toxicidad al documento para generar una predicción que puede usar como filtro. Otro ejemplo sería aplicar un algoritmo de detección de información de identificación personal (PII) a los documentos para filtrar documentos.
Por último, cualquier fuente documental que se introduzca en el agente puede ser un vector de ataque potencial para que actores malintencionados lancen ataques de envenenamiento de datos. También puede considerar la posibilidad de agregar mecanismos de detección y filtrado para ayudar a identificar y eliminarlos.
Fragmentación
Después de analizar los datos sin procesar en un formato más estructurado, quitar duplicados y filtrar la información no deseada, el siguiente paso consiste en dividirlos en unidades más pequeñas y administrables denominadas fragmentos. La segmentación de documentos grandes en fragmentos más pequeños y concentrados semánticamente garantiza que los datos recuperados se ajusten al contexto del LLM, y minimiza la inclusión de información irrelevante o distracciones. Las opciones tomadas en la fragmentación afectarán directamente a los datos recuperados que proporciona LLM, lo que lo convierte en una de las primeras capas de optimización en una aplicación RAG.
Al fragmentar los datos, ten en cuenta los siguientes factores:
- Estrategia de fragmentación: el método que se usa para dividir el texto original en fragmentos. Esto puede implicar técnicas básicas, como la división por oraciones, párrafos, recuentos de caracteres y tokens específicos y estrategias de división más avanzadas específicas del documento.
- Tamaño del fragmento: Los fragmentos más pequeños pueden centrarse en detalles específicos, pero pierden información contextual circundante. Los fragmentos más grandes pueden capturar más contexto, pero pueden incluir información irrelevante o ser computacionalmente costosa.
- Superposición entre fragmentos: para asegurarte de que no se pierde información importante al dividir los datos en fragmentos, considera la posibilidad de incluir cierta superposición entre fragmentos adyacentes. La superposición puede garantizar la continuidad y la conservación del contexto entre fragmentos y mejorar los resultados de la recuperación.
- Coherencia semántica: Cuando sea posible, intente crear fragmentos semánticamente coherentes que contengan información relacionada, pero que puedan permanecer de forma independiente como una unidad significativa de texto. Esto se puede lograr teniendo en cuenta la estructura de los datos originales, como párrafos, secciones o límites de temas.
- Metadatos: losmetadatos pertinentes, como el nombre del documento de origen, el encabezado de sección o los nombres de producto, pueden mejorar la recuperación. Esta información adicional puede ayudar a hacer coincidir las consultas de recuperación con fragmentos.
Estrategias de fragmentación de datos
Buscar el método de fragmentación adecuado es iterativo y dependiente del contexto. No hay una solución única para todos. El tamaño óptimo del fragmento y el método dependen del caso de uso específico y de la naturaleza de los datos que se procesan. En general, las estrategias de fragmentación se pueden ver como las siguientes:
- Fragmentación de tamaño fijo: divide el texto en fragmentos de un tamaño predeterminado, como un número fijo de caracteres o tokens (por ejemplo, LangChain CharacterTextSplitter). Aunque la división por un número arbitrario de caracteres o tokens es rápida y fácil de configurar, normalmente no dará lugar a fragmentos coherentes semánticamente. Este enfoque rara vez funciona para aplicaciones de nivel de producción.
- Fragmentación basada en párrafos: usa los límites de párrafo natural del texto para definir fragmentos. Este método puede ayudar a conservar la coherencia semántica de los fragmentos, ya que los párrafos suelen contener información relacionada (por ejemplo, LangChain RecursiveCharacterTextSplitter).
- Fragmentación específica del formato: Los formatos como Markdown o HTML tienen una estructura inherente que puede definir límites de fragmento (por ejemplo, encabezados markdown). Las herramientas como markdownHeaderTextSplitter de LangChain o los divisores basados ensecciones de / HTML se pueden usar para este propósito.
- Fragmentación semántica: Las técnicas como el modelado de temas se pueden aplicar para identificar secciones semánticamente coherentes en el texto. Estos enfoques analizan el contenido o la estructura de cada documento para determinar los límites de fragmentos más adecuados en función de los turnos de tema. Aunque más implicados que los enfoques básicos, la fragmentación semántica puede ayudar a crear fragmentos más alineados con las divisiones semánticas naturales en el texto (vea LangChain SemanticChunker, por ejemplo).
Ejemplo: fragmentación del tamaño de corrección
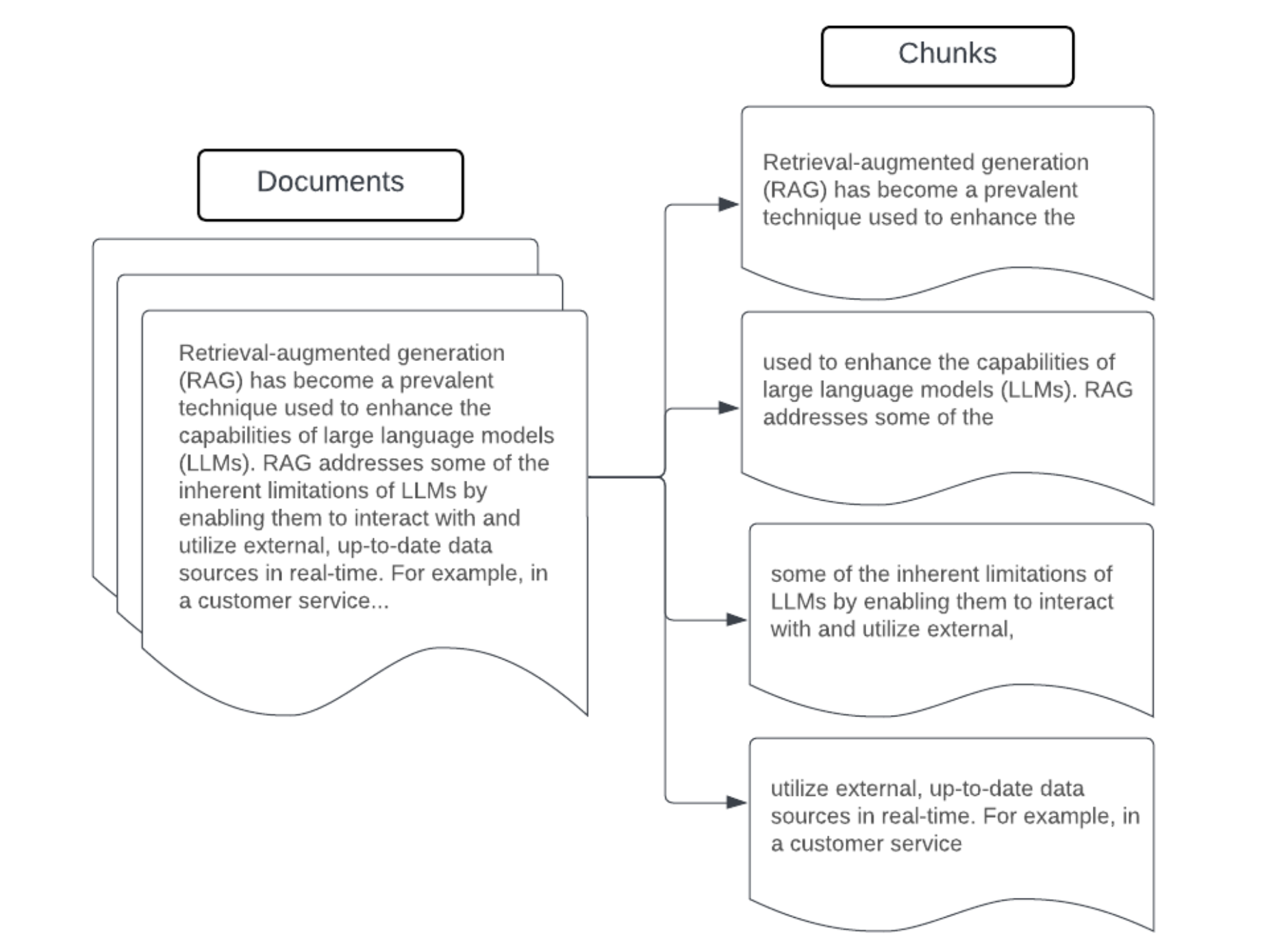
Ejemplo de fragmentación de tamaño fijo mediante RecursiveCharacterTextSplitter de LangChain con chunk_size=100 y chunk_overlap=20. ChunkViz proporciona una manera interactiva de visualizar cómo diferentes tamaños de fragmento y valores de superposición de fragmentos con los separadores de caracteres de Langchain afectan a los fragmentos resultantes.
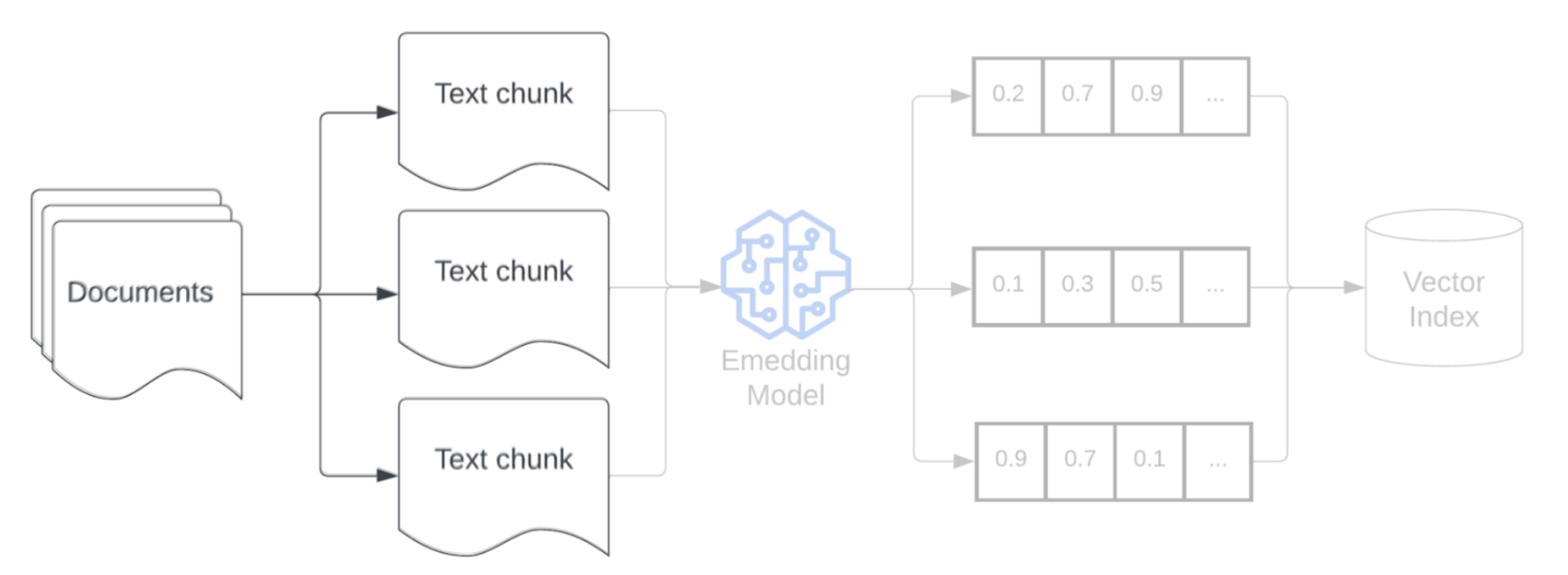
Inserción
Después de fragmentar los datos, el siguiente paso consiste en convertir los fragmentos de texto en una representación vectorial mediante un modelo de inserción. Un modelo de inserción convierte cada fragmento de texto en una representación vectorial que captura su significado semántico. Al representar fragmentos como vectores densos, las incrustaciones permiten una recuperación rápida y precisa de los fragmentos más relevantes en función de su similitud semántica con una consulta de recuperación. La consulta de recuperación se transformará en el momento de la consulta mediante el mismo modelo de inserción que se usa para insertar fragmentos en la canalización de datos.
Al seleccionar un modelo de inserción, ten en cuenta los siguientes factores:
- Elección del modelo: Cada modelo de inserción tiene matices y es posible que las pruebas comparativas disponibles no capturen las características específicas de los datos. Es fundamental seleccionar un modelo entrenado con datos similares. También puede ser beneficioso explorar los modelos de inserción disponibles diseñados para tareas específicas. Experimenta con diferentes modelos de incrustación ya disponibles, incluso aquellos que pueden estar clasificados más bajos en tablas de clasificación estándar como MTEB. Algunos ejemplos que se deben tener en cuenta:
- Número máximo de tokens: Conozca el límite máximo de tokens para el modelo de inserción elegido. Si pasas fragmentos que superan este límite, se truncarán, lo que podría conllevar la pérdida de información importante. Por ejemplo, bge-large-en-v1.5 tiene un límite máximo de 512 tokens.
- Tamaño del modelo: Los modelos de inserción más grandes suelen funcionar mejor, pero requieren más recursos computacionales. En función de su caso de uso específico y de los recursos disponibles, deberá equilibrar el rendimiento y la eficacia.
- Ajuste preciso: Si la aplicación RAG se ocupa del lenguaje específico del dominio (por ejemplo, acrónimos internos de la empresa o terminología), considere la posibilidad de ajustar el modelo de inserción en datos específicos del dominio. Esto puede ayudar al modelo a capturar mejor los matices y la terminología de su dominio concreto y a menudo puede dar lugar a un mejor rendimiento de recuperación.
Indexación y almacenamiento
El siguiente paso de la canalización es crear índices en las integraciones y los metadatos generados en los pasos anteriores. Esta fase implica la organización de incrustaciones de vectores de alta dimensionalidad en estructuras de datos eficaces que permiten búsquedas de similitud rápidas y precisas.
Mosaic AI Vector Search usa las técnicas de indexación más recientes al implementar un punto de conexión de búsqueda vectorial e índice para garantizar búsquedas rápidas y eficaces para las consultas de búsqueda vectorial. No es necesario preocuparse por las pruebas y elegir las mejores técnicas de indexación.
Una vez creado e implementado el índice, está listo para almacenarse en un sistema que admita consultas escalables y de baja latencia. En el caso de las canalizaciones RAG en producción con grandes conjuntos de datos, use una base de datos vectorial o un servicio de búsqueda escalable para garantizar baja latencia y un alto rendimiento. Almacene metadatos adicionales junto con incrustaciones para permitir un filtrado eficaz durante la recuperación.