Julio de 2018
Estas características y las mejoras de la plataforma Azure Databricks se publicaron en julio de 2018.
La API de bibliotecas admite los archivos wheel de Python
Del 31 de julio al 7 de agosto de 2018: versión 2.77
Ahora puede instalar bibliotecas wheel mediante la API de bibliotecas. Al instalar una biblioteca Wheel en un clúster que ejecuta Databricks Runtime 4.2 o posterior, se incluyen todas las dependencias especificadas en el archivo setup.py de biblioteca. Al instalar una biblioteca Wheel en un clúster que ejecuta Databricks Runtime 4.1 o una versión inferior, el archivo se agrega a la variable PYTHONPATH, sin instalar las dependencias.
Exportación de cuadernos de IPython
Del 31 de julio al 7 de agosto de 2018: versión 2.77
Al exportar un cuaderno de Azure Databricks al formato de cuaderno de IPython, los resultados ahora se incluyen en la exportación.
Ámbitos de secreto compatibles con Azure Key Vault
19-24 de julio de 2018: versión 2.76
Los secretos ahora admiten ámbitos con respaldo de una instancia de Azure Key Vault. Una vez creado el ámbito, puede acceder a todos los secretos de la instancia de Key Vault correspondiente desde ese ámbito. Para más información, consulte Creación de un ámbito de secreto con respaldo de Azure Key Vault.
Nota:
El ámbito de secreto con respaldo de Azure Key Vault es una interfaz de solo lectura para el almacén de claves. Para administrar secretos en Azure Key Vault, debe usar la API REST SetSecret de Azure o la interfaz de usuario de Azure Portal.
Áreas de trabajo Premium de prueba
20-24 de julio de 2018: versión 2.76
Azure Databricks ahora ofrece áreas de trabajo Premium de prueba. Durante 14 días, tiene acceso a unidades de Azure Databricks de forma gratuita. Para más información, consulte Creación de un área de trabajo.
Modo del clúster y clústeres de alta simultaneidad
19-24 de julio de 2018: versión 2.76
Al crear un clúster, la opción Cluster Type (Tipo de clúster) se llama ahora Cluster Mode (Modo de clúster). La opción Serverless Pool (Grupo sin servidor) se ha reempalzado por High Concurrency (Alta simultaneidad). Los clústeres de alta simultaneidad están optimizados para proporcionar un uso eficiente de los recursos, aislamiento, seguridad y el mejor rendimiento cuando se comparten entre varios usuarios activos simultáneamente. Un clúster de alta simultaneidad solo admite los lenguajes SQL, Python y R. Los clústeres de alta simultaneidad proporcionan todas las ventajas de los grupos sin servidor, y permiten también flexibilidad en la configuración de los recursos y de Spark. Para más información, consulte Clústeres de alta simultaneidad.
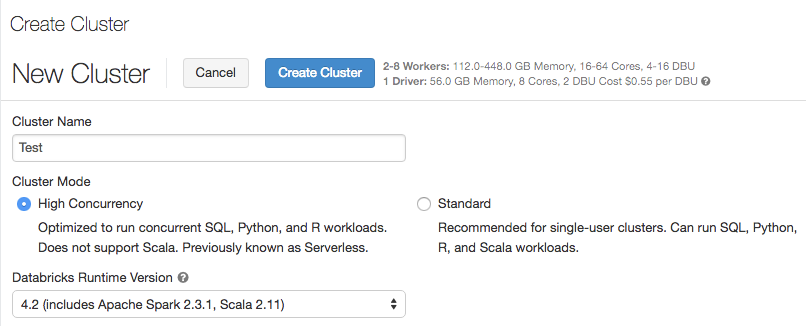
Control de acceso a tabla
19-24 de julio de 2018: versión 2.76
La casilla Table Access Control (Control de acceso a tablas) solo está disponible para clústeres de alta simultaneidad.

Los tipos de nodos de clúster no disponibles se atenúan
3-10 de julio de 2018: versión 2.75
Los tipos de nodo de clúster que no están disponibles para la suscripción y la región ahora están atenuados y no se pueden seleccionar al crear un clúster.
Compatibilidad con R Markdown
3-10 de julio de 2018: versión 2.75
Los cuadernos de R de Azure Databricks se pueden exportar al formato R Markdown y los documentos de R Markdown se pueden importar como cuadernos de Azure Databricks.
Rediseño de la página principal, con la funcionalidad de quitar archivos para importar datos
3-10 de julio de 2018: versión 2.75
La nueva página principal agrega una interfaz más limpia y sencilla, con vínculos a un tutorial de inicio mejorado y la posibilidad de arrastrar y colocar archivos para importar datos. Vea Exploración y creación de tablas en DBFS.
Comportamiento predeterminado de widget:
3-10 de julio de 2018: versión 2.75
El comportamiento de ejecución predeterminado cuando se selecciona un nuevo valor para un widget ahora es Do Nothing (No hacer nada). Debe actualizar la configuración del widget si quiere volver a ejecutar un cuaderno completo o solo los comandos relacionados con el valor al cambiar un valor de widget. Consulte Configuración de las opciones de widget.
Interfaz de usuario de creación de tablas
3-10 de julio de 2018: versión 2.75
Al crear una tabla en la interfaz de usuario, ahora seleccione Add Data (Agregar datos) en la página Data (Datos).
![]()
Vea Exploración y creación de tablas en DBFS.
Importación de datos JSON de varias líneas
3-10 de julio de 2018: versión 2.75
Ahora puede importar archivos de datos JSON de varias líneas al crear tablas. Anteriormente, los archivos de datos JSON se tenían que acoplar a una línea. Consulte Exploración y creación de tablas en DBFS.