Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se muestra cómo implementar una aplicación de Red Hat JBoss Enterprise Application Platform (EAP) en un clúster de Red Hat OpenShift de Azure. El ejemplo es una aplicación Java respaldada por una base de datos SQL. La aplicación se implementa mediante gráficos de Helm de JBoss EAP.
En esta guía, aprenderá a:
- Prepare una aplicación de JBoss EAP para OpenShift.
- Cree una única instancia de base de datos de Azure SQL Database.
- Dado que Azure Workload Identity aún no es compatible con Azure OpenShift, en este artículo se sigue usando el nombre de usuario y la contraseña para la autenticación de base de datos en lugar de usar conexione de base de datos sin contraseña.
- Implementación de la aplicación en un clúster de Red Hat OpenShift de Azure mediante gráficos de Helm de JBoss y la consola web de OpenShift
La aplicación de ejemplo es una aplicación con estado que almacena información en una sesión HTTP. Usa las funcionalidades de agrupación en clústeres de JBoss EAP y usa las siguientes tecnologías de Jakarta EE y MicroProfile:
- Caras del servidor de Jakarta
- Jakarta Enterprise Beans
- Persistencia de Jakarta
- Salud de MicroProfile
Este artículo es una guía manual paso a paso para ejecutar la aplicación JBoss EAP en un clúster de Red Hat OpenShift de Azure. Para obtener una solución más automatizada que acelere el recorrido al clúster de Red Hat OpenShift de Azure, consulte Inicio rápido: Implementación de JBoss EAP en Red Hat OpenShift en Azure mediante Azure Portal.
Si está interesado en proporcionar comentarios o trabajar estrechamente en su escenario de migración con el equipo de ingeniería que desarrolla JBoss EAP en soluciones de Azure, rellene esta breve encuesta sobre la migración de JBoss EAP e incluya la información de contacto. El equipo de administradores de programas, arquitectos e ingenieros se pondrá en contacto rápidamente con usted para iniciar una estrecha colaboración.
Importante
En este artículo se implementa una aplicación mediante gráficos de Helm de EAP de JBoss. En el momento de redactar este documento, esta característica todavía se ofrece como una versión preliminar de tecnología. Antes de elegir implementar aplicaciones con gráficos de Helm de EAP de JBoss en entornos de producción, asegúrese de que esta característica es una característica compatible con la versión del producto EAP/XP de JBoss.
Importante
Aunque Red Hat y Microsoft Azure diseñan, operan y admiten Red Hat OpenShift en Azure para proporcionar una experiencia de soporte técnico integrada, el software que se ejecuta sobre Red Hat OpenShift de Azure, incluido el descrito en este artículo, está sujeto a sus propios términos de soporte técnico y licencia. Para más información sobre la compatibilidad con Red Hat OpenShift en Azure, consulte Ciclo de vida de soporte técnico para Red Hat OpenShift en Azure 4. Para más información sobre la compatibilidad del software que se describe en este artículo, consulte las páginas principales del software que se enumeran en el artículo.
Requisitos previos
Nota:
Red Hat OpenShift en Azure requiere 40 núcleos como mínimo para crear y ejecutar un clúster de OpenShift. La cuota de recursos de Azure predeterminada para una nueva suscripción de Azure no cumple este requisito. Para solicitar un aumento del límite de recursos, consulte Cuota estándar: Aumento de los límites por serie de máquinas virtuales. La suscripción de evaluación gratuita no es válida para un aumento de cuota, por lo que debe actualizar a una suscripción de pago por uso antes de solicitar ese aumento.
Prepare una máquina local con un sistema operativo similar a Unix compatible con los distintos productos instalados, como Ubuntu, macOS o Subsistema de Windows para Linux.
Instale una implementación de Java Standard Edition (SE). Los pasos de desarrollo local de este artículo se probaron con el Kit de desarrollo de Java (JDK) 17 de la compilación de Microsoft de OpenJDK.
Instale Maven 3.8.6 o posterior.
Instale la CLI de Azure 2.40 o posterior.
Clone el código de esta aplicación de demostración (lista de tareas pendientes) en el sistema local. La aplicación de demostración está en GitHub.
Siga las instrucciones que aparecen en Creación de un clúster de Red Hat OpenShift en Azure 4.
Aunque el paso "Obtención de un secreto de extracción de Red Hat" está etiquetado como opcional, es necesario para este artículo. El secreto de extracción permite que el clúster de Red Hat OpenShift de Azure encuentre las imágenes de aplicación de JBoss EAP.
Si planea ejecutar en el clúster aplicaciones que utilizan mucha memoria, especifique el tamaño de máquina virtual correspondiente para los nodos de trabajo mediante el parámetro
--worker-vm-size. Para más información, vea:Para conectarse al clúster, siga los pasos que aparecen en Conexión a un clúster de Red Hat OpenShift en Azure 4.
- Siga los pasos descritos en "Instalación de la CLI de OpenShift".
- Conéctese a un clúster de Red Hat OpenShift en Azure mediante la CLI de OpenShift con el usuario
kubeadmin.
Ejecute el siguiente comando para crear el proyecto de OpenShift para esta aplicación de demostración:
oc new-project eap-demoEjecute el siguiente comando para agregar el rol de vista a la cuenta de servicio predeterminada. Este rol es necesario para que la aplicación pueda detectar otros pods y configurar un clúster con ellos:
oc policy add-role-to-user view system:serviceaccount:$(oc project -q):default -n $(oc project -q)
Preparar la aplicación
Clone la aplicación de ejemplo mediante el siguiente comando:
git clone https://github.com/Azure-Samples/jboss-on-aro-jakartaee
Ha clonado la aplicación de demostración lista de tareas pendientes y el repositorio local se encuentra en la rama principal. La aplicación de demostración es una aplicación java sencilla que crea, lee, actualiza y elimina registros en Azure SQL. Puede implementar esta aplicación tal como está en un servidor JBoss EAP instalado en el equipo local. Solo tiene que configurar el servidor con el controlador de base de datos y el origen de datos necesarios. También necesita un servidor de bases de datos accesible desde el entorno local.
Sin embargo, cuando tenga como destino OpenShift, es posible que quiera recortar las funcionalidades del servidor JBoss EAP. Por ejemplo, puede que quiera reducir la exposición de seguridad del servidor aprovisionado y reducir la superficie general. Es posible que también quiera incluir algunas especificaciones de MicroProfile para que la aplicación sea más adecuada para ejecutarse en un entorno de OpenShift. Cuando se usa JBoss EAP, una manera de realizar esta tarea es empaquetar la aplicación y el servidor en una sola unidad de implementación conocida como JAR de arranque. Para ello, agregue los cambios necesarios a nuestra aplicación de demostración.
Vaya al repositorio local de la aplicación de demostración y cambie la rama a bootable-jar :
## cd jboss-on-aro-jakartaee
git checkout bootable-jar
Vamos a repasar rápidamente lo que hemos cambiado en esta rama:
- Hemos agregado el
wildfly-jar-mavencomplemento para aprovisionar el servidor y la aplicación en un único archivo JAR ejecutable. La unidad de implementación de OpenShift es nuestro servidor con nuestra aplicación. - En el complemento Maven, especificamos un conjunto de capas de Galleon. Esta configuración nos permite recortar las funcionalidades del servidor solo a lo que necesitamos. Para obtener documentación completa sobre Galleon, consulte la documentación de WildFly.
- Nuestra aplicación usa caras de Jakarta con solicitudes de Ajax, lo que significa que hay información almacenada en la sesión HTTP. No queremos perder esta información si se quita un pod. Podríamos guardar esta información en el cliente y enviarla de vuelta en cada solicitud. Sin embargo, hay casos en los que puede decidir no distribuir cierta información a los clientes. Para esta demostración, decidimos replicar la sesión en todas las réplicas de pod. Para ello, agregamos
<distributable />al web.xml. Esto, junto con las funcionalidades de agrupación en clústeres de servidores, hace que la sesión HTTP se distribuya en todos los pods. - Hemos agregado dos comprobaciones de estado de MicroProfile que le permiten identificar cuándo la aplicación está activa y lista para recibir solicitudes.
Ejecutar la aplicación localmente
Antes de implementar la aplicación en OpenShift, vamos a ejecutarla localmente para comprobar cómo funciona. En los pasos siguientes se da por supuesto que tiene Azure SQL en ejecución y disponible en el entorno local.
Para crear la base de datos, siga los pasos que se indican en Inicio rápido: Creación de una base de datos única de Azure SQL Database, pero realice las siguientes modificaciones.
- En Grupo de recursos , use el grupo de recursos que creó anteriormente.
- En Nombre de base de datos, use
todos_db. - En Inicio de sesión del administrador del servidor use
azureuser. - En Contraseña use
Passw0rd!. - En la sección Reglas de firewall, cambie la opción Permitir que los servicios y recursos de Azure accedan a este servidor a Sí.
Todas las demás opciones de configuración se pueden usar de forma segura desde el artículo vinculado.
En la página Configuración adicional, no tiene que elegir la opción para rellenar previamente la base de datos con datos de ejemplo, pero no hay ningún daño para hacerlo.
Después de crear la base de datos, obtenga el valor del nombre del servidor en la página de información general. Mantenga el mouse sobre el valor del campo Nombre del servidor y seleccione el icono de copia que aparece junto al valor. Guarde este valor para usarlo más adelante (establecemos una variable denominada MSSQLSERVER_HOST en este valor).
Nota:
Para mantener bajos los costos monetarios, el inicio rápido dirige al lector para seleccionar el nivel de proceso sin servidor. Este nivel se escala a cero cuando no hay ninguna actividad. Cuando esto sucede, la base de datos no responde inmediatamente. Si en algún momento al ejecutar los pasos de este artículo observa problemas de base de datos, considere la posibilidad de deshabilitar la pausa automática. Para saber cómo hacerlo, busque Pausa automática en Azure SQL Database sin servidor. En el momento de escribir, el siguiente comando de la CLI de Azure deshabilita la pausa automática de la base de datos configurada en este artículo: az sql db update --resource-group $RESOURCEGROUP --server <Server name, without the .database.windows.net part> --name todos_db --auto-pause-delay -1
Para compilar y ejecutar la aplicación localmente, realice los pasos siguientes.
Compile el archivo JAR de arranque. Dado que estamos usando con la
eap-datasources-galleon-packbase de datos de MS SQL Server, debemos especificar la versión del controlador de base de datos que queremos usar con esta variable de entorno específica. Para obtener más información sobre yeap-datasources-galleon-packMS SQL Server, consulte la documentación de Red Hat.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 mvn clean packageInicie el archivo JAR de arranque mediante los comandos siguientes.
Debe asegurarse de que la base de datos de Azure SQL permite el tráfico de red desde el host en el que se ejecuta este servidor. Dado que seleccionó Agregar dirección IP del cliente actual al realizar los pasos descritos en Inicio rápido: Creación de una base de datos única de Azure SQL Database, si el host en el que se ejecuta el servidor es el mismo host desde el que se conecta el explorador a Azure Portal, se debe permitir el tráfico. Si el host en el que se ejecuta el servidor es otro host, debe consultar Uso de Azure Portal para administrar reglas de firewall de IP de nivel de servidor.
Cuando se inicia la aplicación, es necesario pasar las variables de entorno necesarias para configurar el origen de datos:
export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:runNota:
Microsoft recomienda usar el flujo de autenticación más seguro disponible. El flujo de autenticación descrito en este procedimiento, como para bases de datos, memorias caché, mensajería o servicios de inteligencia artificial, requiere un grado de confianza muy alto en la aplicación y conlleva riesgos que no están presentes en otros flujos. Use este flujo solo cuando las opciones más seguras, como las identidades administradas para conexiones sin contraseña o sin claves, no sean viables. En el caso de las operaciones de máquina local, prefiera identidades de usuario para conexiones sin contraseña o sin claves.
Si quiere más información sobre el entorno de ejecución subyacente que se usa en esta demostración, la documentación de Galleon Feature Pack para integrar orígenes de datos tiene una lista completa de las variables de entorno disponibles. Para más información sobre el concepto de feature-pack, consulte la documentación de WildFly.
Si recibe un error con texto similar al ejemplo siguiente:
Cannot open server '<your prefix>mysqlserver' requested by the login. Client with IP address 'XXX.XXX.XXX.XXX' is not allowed to access the server.Este mensaje indica que los pasos para asegurarse de que el tráfico de red no funciona. Asegúrese de que la dirección IP del mensaje de error se incluye en las reglas de firewall.
Si recibe un mensaje con texto similar al ejemplo siguiente:
Caused by: com.microsoft.sqlserver.jdbc.SQLServerException: There is already an object named 'TODOS' in the database.Este mensaje indica que los datos de ejemplo ya están en la base de datos. Puede ignorar este mensaje.
(Opcional) Si desea comprobar las funcionalidades de agrupación en clústeres, también puede iniciar más instancias de la misma aplicación pasando al archivo JAR de arranque el argumento
jboss.node.namey, para evitar conflictos con los números de puerto, desplazando los números de puerto mediantejboss.socket.binding.port-offset. Por ejemplo, para iniciar una segunda instancia que represente un nuevo pod en OpenShift, puede ejecutar el siguiente comando en una nueva ventana de terminal:export MSSQLSERVER_USER=azureuser export MSSQLSERVER_PASSWORD='Passw0rd!' export MSSQLSERVER_JNDI=java:/comp/env/jdbc/mssqlds export MSSQLSERVER_DATABASE=todos_db export MSSQLSERVER_HOST=<server name saved aside earlier> export MSSQLSERVER_PORT=1433 mvn wildfly-jar:run -Dwildfly.bootable.arguments="-Djboss.node.name=node2 -Djboss.socket.binding.port-offset=1000"Nota:
Microsoft recomienda usar el flujo de autenticación más seguro disponible. El flujo de autenticación descrito en este procedimiento, como para bases de datos, memorias caché, mensajería o servicios de inteligencia artificial, requiere un grado de confianza muy alto en la aplicación y conlleva riesgos que no están presentes en otros flujos. Use este flujo solo cuando las opciones más seguras, como las identidades administradas para conexiones sin contraseña o sin claves, no sean viables. En el caso de las operaciones de máquina local, prefiera identidades de usuario para conexiones sin contraseña o sin claves.
Si el clúster funciona, puede ver en la consola del servidor un seguimiento similar al siguiente:
INFO [org.infinispan.CLUSTER] (thread-6,ejb,node) ISPN000094: Received new cluster view for channel ejbNota:
De forma predeterminada, el archivo JAR de arranque configura el subsistema JGroups para usar el protocolo UDP y envía mensajes para detectar otros miembros del clúster a la dirección de multidifusión 230.0.0.4. Para comprobar correctamente las funcionalidades de agrupación en clústeres en el equipo local, el sistema operativo debe ser capaz de enviar y recibir datagramas de multidifusión y enrutarlos a la dirección IP 230.0.0.4 a través de la interfaz Ethernet. Si ve advertencias relacionadas con el clúster en los registros del servidor, consulte la configuración de la red y compruebe si admite la multidifusión en esa dirección.
Abra http://localhost:8080/ en el explorador para ir a la página principal de la aplicación. Si ha creado más instancias, puede acceder a ellas cambiando el número de puerto, por ejemplo, http://localhost:9080/. La aplicación debe tener un aspecto similar a la siguiente imagen:

Compruebe los sondeos de ejecución y preparación de la aplicación. OpenShift usa estos puntos de conexión para comprobar cuándo el pod está activo y listo para recibir solicitudes de usuario.
Para comprobar el estado de ejecución, ejecute:
curl http://localhost:9990/health/liveDebería ver este resultado:
{"status":"UP","checks":[{"name":"SuccessfulCheck","status":"UP"}]}Para comprobar el estado de preparación, ejecute:
curl http://localhost:9990/health/readyDebería ver este resultado:
{"status":"UP","checks":[{"name":"deployments-status","status":"UP","data":{"todo-list.war":"OK"}},{"name":"server-state","status":"UP","data":{"value":"running"}},{"name":"boot-errors","status":"UP"},{"name":"DBConnectionHealthCheck","status":"UP"}]}Presione Ctrl+C para detener la aplicación.
Implementación en OpenShift
Para implementar la aplicación, vamos a usar los gráficos de Helm de JBoss EAP que ya están disponibles en Red Hat OpenShift en Azure. También es necesario proporcionar la configuración deseada, por ejemplo, el usuario de la base de datos, la contraseña de la base de datos, la versión del controlador que queremos usar y la información de conexión utilizada por el origen de datos. En los pasos siguientes se supone que tiene Azure SQL en ejecución y accesible desde el clúster de OpenShift, y almacenó el nombre de usuario, la contraseña, el nombre de host, el puerto y el nombre de la base de datos en un objeto secreto de OpenShift openShift de OpenShift denominado mssqlserver-secret.
Vaya al repositorio local de la aplicación de demostración y cambie la rama actual a bootable-jar-openshift:
git checkout bootable-jar-openshift
Vamos a revisar rápidamente lo que hemos cambiado en esta rama:
- Se ha agregado un nuevo perfil de Maven denominado
bootable-jar-openshiftque prepara el ARCHIVO JAR de arranque con una configuración específica para ejecutar el servidor en la nube. Por ejemplo, permite que el subsistema JGroups use solicitudes de red para detectar otros pods mediante el protocolo KUBE_PING. - Se ha agregado un conjunto de archivos de configuración en el directorio jboss-on-aro-jakartaee/deployment . En este directorio, puede encontrar los archivos de configuración para implementar la aplicación.
Implementación de la aplicación en OpenShift
En los pasos siguientes se explica cómo puede implementar la aplicación con un gráfico de Helm mediante la consola web de OpenShift. Evite codificar valores confidenciales de forma rígida en el gráfico de Helm mediante una característica denominada "secretos". Un secreto es simplemente una colección de pares nombre-valor, donde los valores se especifican en algún lugar conocido antes de que sean necesarios. En nuestro caso, el gráfico de Helm usa dos secretos, con los siguientes pares nombre-valor de cada uno.
mssqlserver-secret-
db-hosttransmite el valor deMSSQLSERVER_HOST. -
db-nametransmite el valor deMSSQLSERVER_DATABASE. -
db-passwordtransmite el valor deMSSQLSERVER_PASSWORD. -
db-porttransmite el valor deMSSQLSERVER_PORT. -
db-usertransmite el valor deMSSQLSERVER_USER.
-
todo-list-secret-
app-cluster-passwordtransmite una contraseña arbitraria y especificada por el usuario para que los nodos del clúster se puedan formar de manera más segura. -
app-driver-versiontransmite el valor deMSSQLSERVER_DRIVER_VERSION. -
app-ds-jnditransmite el valor deMSSQLSERVER_JNDI.
-
Cree
mssqlserver-secret.oc create secret generic mssqlserver-secret \ --from-literal db-host=${MSSQLSERVER_HOST} \ --from-literal db-name=${MSSQLSERVER_DATABASE} \ --from-literal db-password=${MSSQLSERVER_PASSWORD} \ --from-literal db-port=${MSSQLSERVER_PORT} \ --from-literal db-user=${MSSQLSERVER_USER}Cree
todo-list-secret.export MSSQLSERVER_DRIVER_VERSION=7.4.1.jre11 oc create secret generic todo-list-secret \ --from-literal app-cluster-password=mut2UTG6gDwNDcVW \ --from-literal app-driver-version=${MSSQLSERVER_DRIVER_VERSION} \ --from-literal app-ds-jndi=${MSSQLSERVER_JNDI}Nota:
Microsoft recomienda usar el flujo de autenticación más seguro disponible. El flujo de autenticación descrito en este procedimiento, como para bases de datos, memorias caché, mensajería o servicios de inteligencia artificial, requiere un grado de confianza muy alto en la aplicación y conlleva riesgos que no están presentes en otros flujos. Use este flujo solo cuando las opciones más seguras, como las identidades administradas para conexiones sin contraseña o sin claves, no sean viables. En el caso de las operaciones de máquina local, prefiera identidades de usuario para conexiones sin contraseña o sin claves.
Abra la consola de OpenShift y vaya a la vista del desarrollador. Para detectar la dirección URL de la consola del clúster de OpenShift, ejecute este comando. Inicie sesión con el identificador de usuario y la contraseña de
kubeadminque obtuvo de un paso anterior.az aro show \ --name $CLUSTER \ --resource-group $RESOURCEGROUP \ --query "consoleProfile.url" \ --output tsvSeleccione la <perspectiva /> Desarrollador en el menú desplegable de la parte superior del panel de navegación.
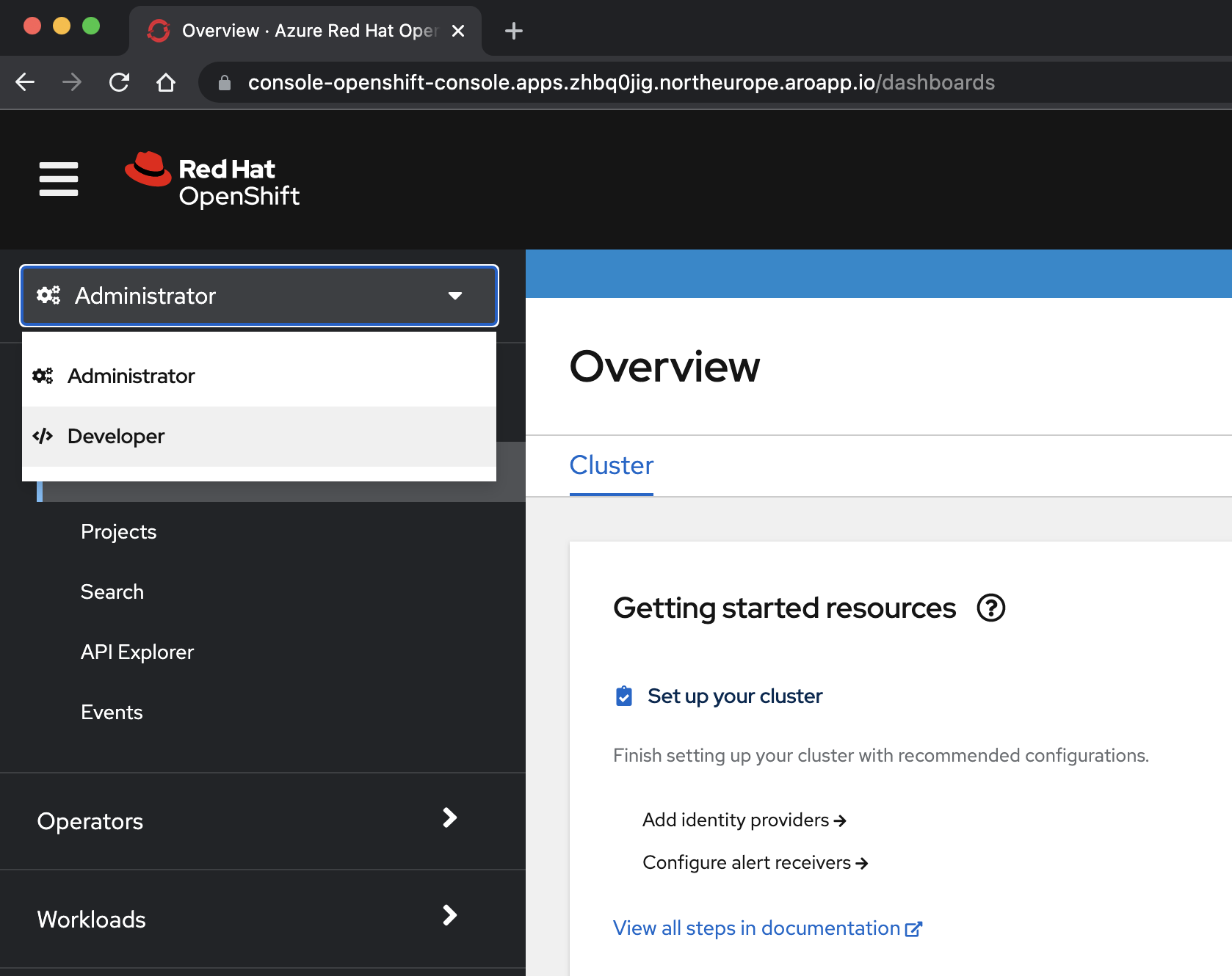
En la <perspectiva /> Developer , seleccione el proyecto eap-demo en el menú desplegable Proyecto .

Seleccione +Agregar. En la sección Catálogo de desarrolladores, seleccione Gráfico de Helm. Llega al catálogo de gráficos de Helm disponible en el clúster de Red Hat OpenShift de Azure. En el cuadro Filtrar por palabra clave, escriba eap. Debería ver varias opciones, como se muestra aquí:
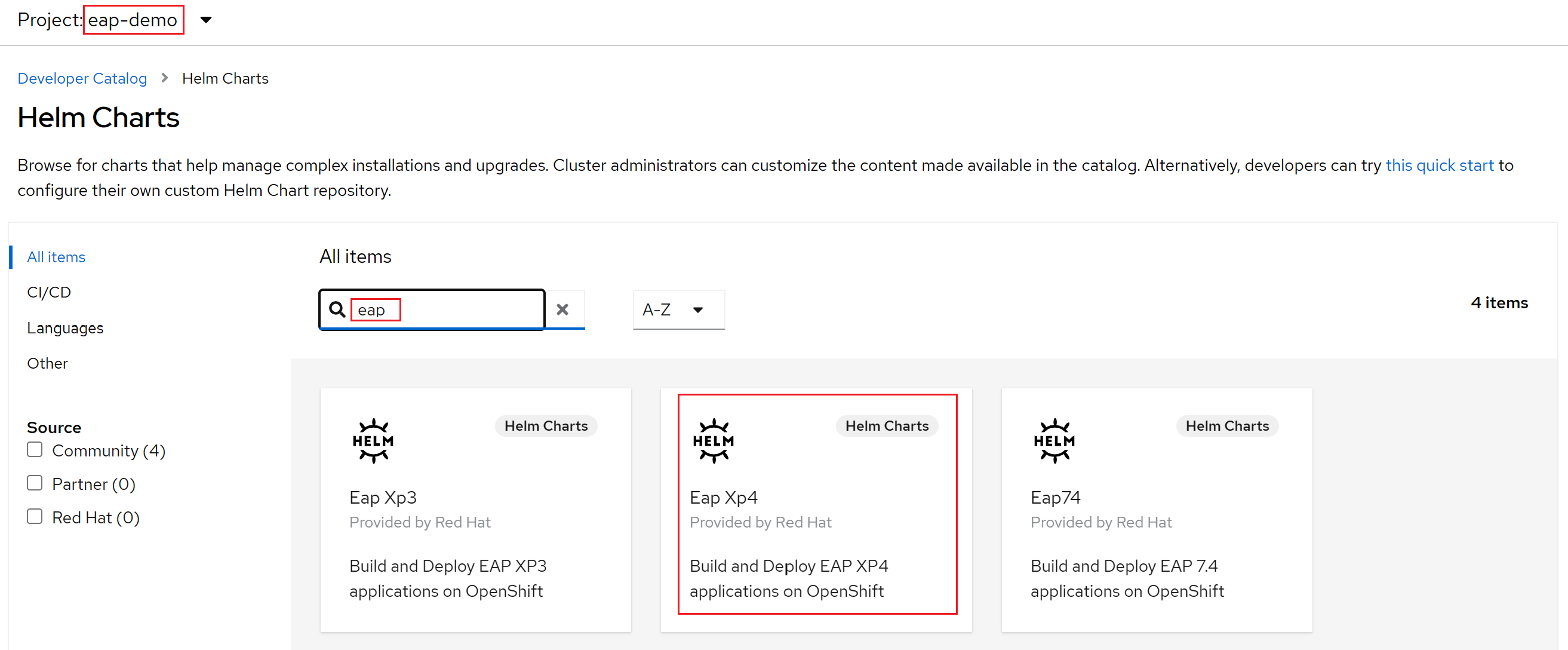
Dado que nuestra aplicación usa funcionalidades de MicroProfile, seleccionamos el gráfico de Helm para EAP Xp. El "Xp" significa Paquete de expansión. Con el paquete de expansión Enterprise Application Platform de JBoss, los desarrolladores pueden usar interfaces de programación de aplicaciones (API) de Eclipse MicroProfile para compilar e implementar aplicaciones basadas en microservicios.
Seleccione el gráfico de Helm de JBoss EAP XP 4 y, a continuación, seleccione Instalar gráfico de Helm.
En este punto, es necesario configurar el gráfico para compilar e implementar la aplicación:
Cambie el nombre de la versión a eap-todo-list-demo.
Podemos configurar el gráfico de Helm mediante una vista de formulario o una vista de YAML. En la sección con la etiqueta Configurar mediante, seleccione Vista YAML.
Cambie el contenido de YAML para configurar el gráfico de Helm copiando y pegando el contenido del archivo de gráfico de Helm disponible en deployment/application/todo-list-helm-chart.yaml en lugar del contenido existente:
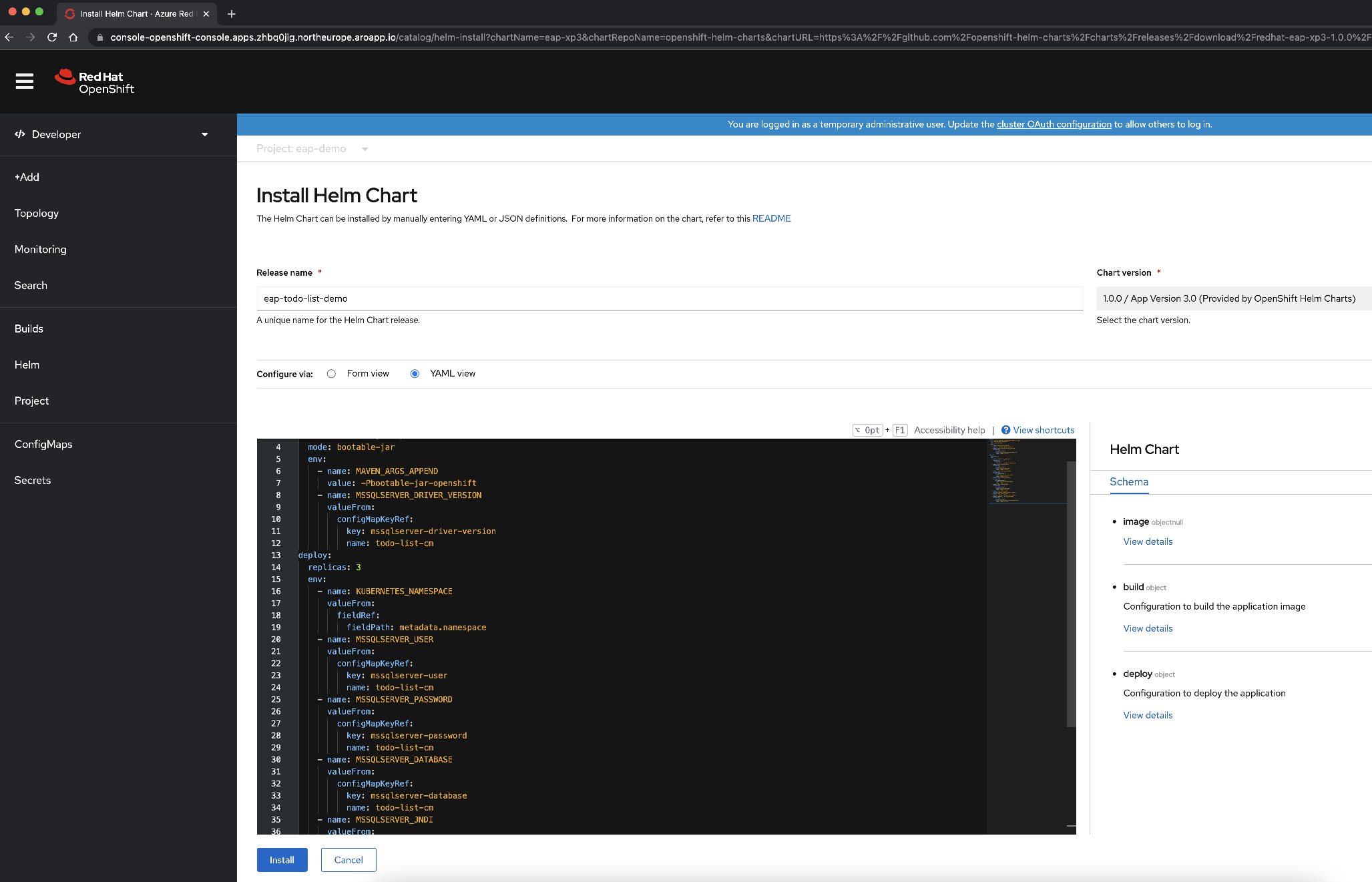
Este contenido hace referencia a los secretos que estableció anteriormente.
Por último, seleccione Instalar para iniciar la implementación de la aplicación. Esta acción abre la vista Topología con una representación gráfica de la versión de Helm (denominada eap-todo-list-demo) y sus recursos asociados.

La versión de Helm (abreviada HR) se denomina eap-todo-list-demo. Incluye un recurso de implementación (abreviado D) también denominado eap-todo-list-demo.
Si selecciona el icono con dos flechas en un círculo situado en la parte inferior izquierda del cuadro D , se le lleva al panel Registros . Aquí puede observar el progreso de la compilación. Para volver a la vista de topología, seleccione Topología en el panel de navegación izquierdo.
Una vez finalizada la compilación, el icono de la parte inferior izquierda muestra una marca de verificación verde.
Cuando se completa la implementación, el contorno del círculo es azul oscuro. Si mantiene el mouse sobre el azul oscuro, debería aparecer un mensaje que indica algo similar a
3 Running. Cuando vea ese mensaje, puede ir a la aplicación la dirección URL (mediante el icono de la parte superior derecha) desde la ruta asociada a la implementación.
La aplicación se abre en el explorador con un aspecto similar al de la siguiente imagen lista para usarse:

La aplicación muestra el nombre del pod que sirve la información. Para comprobar las funcionalidades de agrupación en clústeres, puede agregar algunos elementos de tareas pendientes. A continuación, elimine el pod con el nombre indicado en el campo Nombre de host del servidor que aparece en la aplicación mediante
oc delete pod <pod-name>. Después de eliminar el pod, cree una nueva tarea pendiente en la misma ventana de aplicación. Puede ver que la nueva tarea pendiente se agrega a través de una solicitud de Ajax y el campo Nombre de host del servidor ahora muestra un nombre diferente. En segundo plano, el equilibrador de carga de OpenShift envió la nueva solicitud y la entregó a un pod disponible. La vista Caras de Jakarta se restaura a partir de la copia de sesión HTTP almacenada en el pod que procesa la solicitud. De hecho, puede ver que el campo Id. de sesión no cambió. Si la sesión no se replica en los pods, obtendrá caras de JakartaViewExpiredExceptiony la aplicación no funcionará según lo previsto.

Limpieza de recursos
Eliminación de la aplicación
Si solo desea eliminar la aplicación, puede abrir la consola de OpenShift y, en la vista para desarrolladores, ir a la opción de menú Helm. En este menú, puede ver todas las versiones del gráfico de Helm instaladas en el clúster.

Busque el gráfico de Helm eap-todo-list-demo. Al final de la fila, seleccione los puntos verticales de árbol para abrir la entrada del menú contextual de acción.
Seleccione la opción de desinstalar la versión de Helm para quitar la aplicación. Observe que el objeto secreto usado para proporcionar la configuración de la aplicación no forma parte del gráfico. Debe quitarlo por separado si ya no lo necesita.
Ejecute el siguiente comando si desea eliminar el secreto que contiene la configuración de la aplicación:
$ oc delete secrets/todo-list-secret
# secret "todo-list-secret" deleted
Eliminación del proyecto de OpenShift
También puede eliminar toda la configuración creada para esta demostración eliminando el proyecto eap-demo. Para ello, ejecute el siguiente comando:
$ oc delete project eap-demo
# project.project.openshift.io "eap-demo" deleted
Eliminación del clúster de Red Hat OpenShift en Azure
Elimine el clúster de Red Hat OpenShift en Azure mediante los pasos que se indican en Tutorial: Eliminación de un clúster de Red Hat OpenShift en Azure 4.
Eliminar el grupo de recursos
Si desea eliminar todos los recursos creados por los pasos anteriores, elimine el grupo de recursos que creó para el clúster de Red Hat OpenShift de Azure.
Pasos siguientes
Puede obtener más información en las referencias que se usan en esta guía:
- Plataforma de aplicaciones empresariales de Red Hat JBoss
- Uso de JBoss EAP en OpenShift Container Platform
- Red Hat OpenShift en Azure
- Gráficos de Helm de EAP de JBoss
- Archivo JAR de arranque de EAP de JBoss
Siga descubriendo más opciones para ejecutar JBoss EAP en Azure.