Uso de Apache Ambari Hive View con Apache Hadoop en HDInsight
Aprenda a ejecutar consultas de Hive utilizando Apache Ambari Hive View. La vista de Hive permite crear, optimizar y ejecutar consultas de Hive directamente desde el explorador web.
Prerrequisitos
Un clúster de Hadoop en HDInsight. Consulte Introducción a HDInsight en Linux.
Ejecución de una consulta de Hive
En Azure Portal, seleccione su clúster. Consulte Enumeración y visualización de clústeres para obtener instrucciones. El clúster se abre en una nueva vista del portal.
Desde Paneles de clúster, seleccione Vistas de Ambari. Cuando se le solicite autenticarse, use el nombre de cuenta y la contraseña de inicio de sesión del clúster (el valor predeterminado es
admin) que proporcionó al crear el clúster. También puede ir ahttps://CLUSTERNAME.azurehdinsight.net/#/main/viewsen el explorador, dondeCLUSTERNAMEes el nombre del clúster.En la lista de vistas, seleccione Vista de Hive.
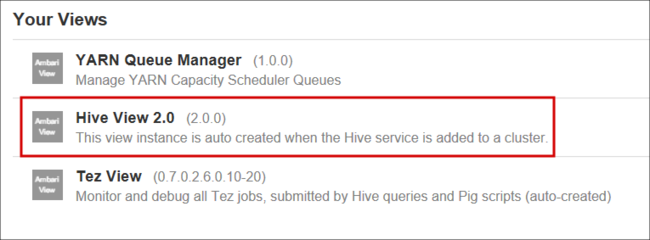
La página de la vista de Hive es similar a la siguiente imagen:
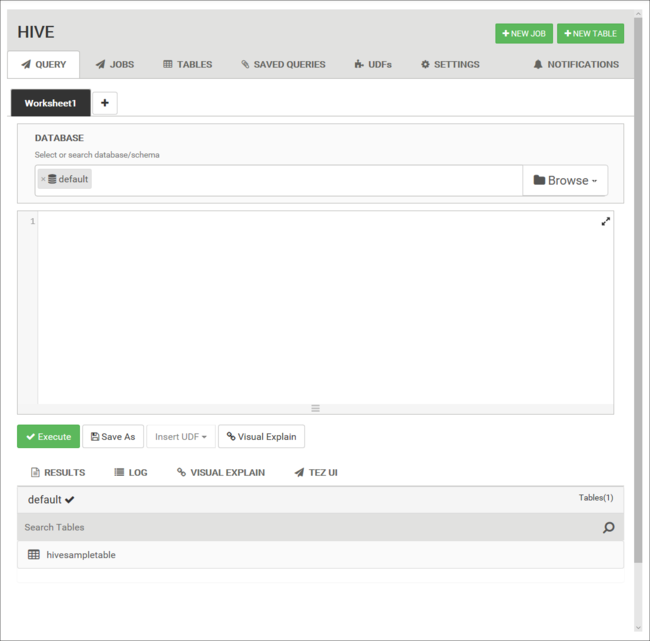
En la pestaña Consulta, pegue las instrucciones HiveQL siguientes en la hoja de cálculo:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;Estas instrucciones realizan las acciones siguientes:
. Descripción DROP TABLE elimina la tabla y el archivo de datos, en caso de que ya exista la tabla. CREATE EXTERNAL TABLE crea una nueva tabla "externa" en Hive. Las tablas externas solo almacenan la definición de tabla en Hive. Los datos permanecen en la ubicación original. ROW FORMAT indica el formato de los datos. En este caso, los campos de cada registro se separan mediante un espacio. STORED AS TEXTFILE LOCATION indica dónde se almacenan los datos y que se almacenan como texto. SELECT selecciona un recuento de todas las filas donde la columna t4 contiene el valor [ERROR]. Importante
Deje la selección de base de datos en el valor predeterminado. Los ejemplos de este documento usan la base de datos predeterminada que se incluye en HDInsight.
Para iniciar la consulta, seleccione Ejecutar debajo de la hoja de cálculo. El botón se vuelve de color naranja y el texto cambia a Detener.
Cuando finalice la consulta, los resultados de la operación aparecerán en la pestaña Resultados. El texto siguiente es el resultado de la consulta:
loglevel count [ERROR] 3Puede utilizar la pestaña Registro para ver la información de registro creada por el trabajo.
Sugerencia
Descargue o guarde los resultados del cuadro de diálogo desplegable Acciones en la pestaña Resultados.
Explicación visual
Para mostrar una visualización del plan de consulta, seleccione la pestaña Explicación visual que se encuentra debajo de la hoja de cálculo.
La vista de explicación visual de la consulta puede ser útil para comprender el flujo de las consultas complejas.
Interfaz de usuario de Tez
Para mostrar la interfaz de usuario de Tez, seleccione la pestaña Tez UI que se encuentra debajo de la hoja de cálculo.
Importante
Tez no se usa para resolver todas las consultas. No es necesario usar Tez para resolver muchas consultas.
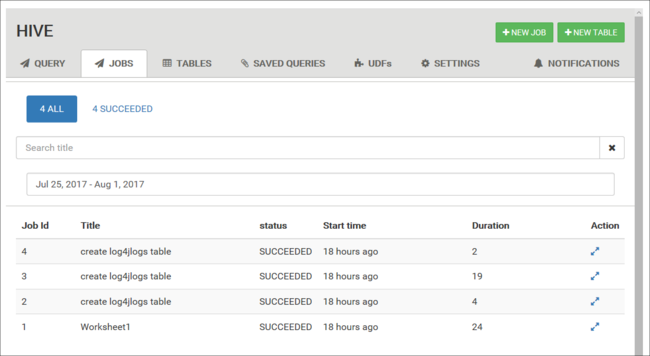
Ver historial de trabajos
La pestaña Trabajos muestra un historial de las consultas de Hive.
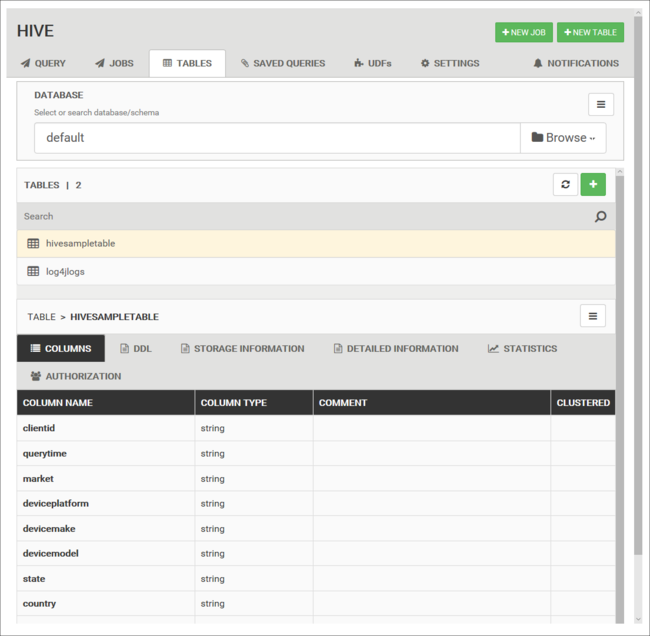
Tablas de la base de datos
Puede usar la pestaña Tablas para trabajar con tablas dentro de una base de datos de Hive.
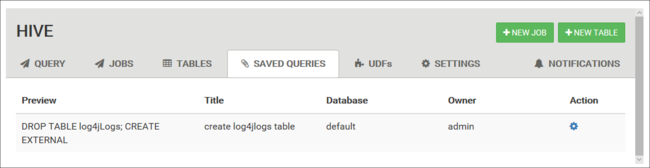
Consultas guardadas
Si lo desea, puede guardar consultas en la pestaña Consulta. Si guarda una consulta, podrá volver a usarla en la pestaña Consultas guardadas.
Sugerencia
Las consultas guardadas se almacenan en el almacenamiento predeterminado del clúster. Puede encontrar las consultas guardadas en la ruta de acceso /user/<username>/hive/scripts. Se almacenan como archivos de texto sin formato .hql.
Si elimina el clúster pero mantiene el almacenamiento, puede usar una utilidad como el Explorador de Azure Storage o el Explorador de Data Lake Storage (desde Azure Portal) para recuperar las consultas.
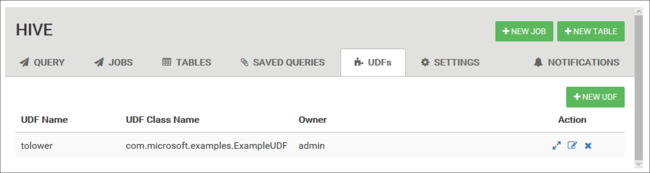
Funciones definidas por el usuario
Puede ampliar la funcionalidad de Hive con funciones definidas por el usuario (UDF). Utilice las UDF para implementar una funcionalidad o lógica que no pueda modelarse fácilmente en HiveQL.
Si desea declarar y guardar un conjunto de UDF, utilice la pestaña UDF situada en la parte superior de la vista de Hive. Estas UDF se pueden usar con el Editor de consultas.
Aparecerá el botón Insertar UDF en la parte inferior del Editor de consultas. Esta entrada muestra una lista desplegable de las UDF definidas en la vista de Hive. Al seleccionar una función definida por el usuario se agregan instrucciones HiveQL a la consulta para habilitar dicha función.
Por ejemplo, si especificó una función definida por el usuario con las siguientes propiedades:
Nombre de recurso: myudfs
Ruta de acceso de recurso: /myudfs.jar
Nombre de la UDF: myawesomeudf
Nombre de la clase UDF: com.myudfs.Awesome
Si usa el botón Insert udfs (Insertar UDF), aparecerá una entrada llamada myudfs con otra lista desplegable en cada UDF establecida para ese recurso. En este caso, será myawesomeudf. Al seleccionar esta entrada se agrega lo siguiente al principio de la consulta:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
A continuación, puede usar la función definida por el usuario en la consulta. Por ejemplo, SELECT myawesomeudf(name) FROM people;.
Para más información sobre el uso de UDF con Hive en HDInsight, consulte los artículos siguientes:
- Uso de Python con Apache Hive y Apache Pig en Azure HDInsight
- Utilización de una función definida por el usuario de Java con Apache Hive en HDInsight
Configuración de Hive
Puede modificar la configuración de Hive; por ejemplo, puede cambiar el motor de ejecución de Hive de Tez (valor predeterminado) a MapReduce.
Pasos siguientes
Para consultar información general sobre Hive en HDInsight:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de