Interpretación de los resultados de un modelo en Machine Learning Studio (clásico)
SE APLICA A: Machine Learning Studio (clásico)
Machine Learning Studio (clásico)  Azure Machine Learning
Azure Machine Learning
Importante
El soporte técnico de Machine Learning Studio (clásico) finalizará el 31 de agosto de 2024. Se recomienda realizar la transición a Azure Machine Learning antes de esa fecha.
A partir del 1 de diciembre de 2021 no se podrán crear recursos de Machine Learning Studio (clásico). Hasta el 31 de agosto de 2024, puede seguir usando los recursos de Machine Learning Studio (clásico) existentes.
- Consulte la información acerca de traslado de proyectos de aprendizaje automático de ML Studio (clásico) a Azure Machine Learning.
- Más información acerca de Azure Machine Learning
La documentación de ML Studio (clásico) se está retirando y es posible que no se actualice en el futuro.
En este tema, se explica cómo ver e interpretar los resultados de la predicción en Estudio de Azure Machine Learning (clásico). Después de entrenar un modelo y realizar predicciones sobre él ("puntuar el modelo"), deberá comprender e interpretar el resultado de predicción.
Hay cuatro tipos principales de modelos de Machine Learning en Estudio de Machine Learning (clásico):
- clasificación
- Agrupación en clústeres
- Regresión
- Sistemas de recomendación
Los módulos usados para la predicción sobre estos modelos son:
- módulo Modelo de puntuación para la clasificación y regresión
- módulo Asignar a clústeres para la agrupación en clústeres
- Score Matchbox Recommender para sistemas de recomendación
Obtenga información sobre cómo elegir parámetros para optimizar los algoritmos en Machine Learning Studio (clásico).
Para obtener información sobre cómo evaluar los modelos, consulte Evaluación del rendimiento de los modelos.
Si no está familiarizado con Machine Learning Studio (clásico), aprenda a crear un experimento sencillo.
clasificación
Existen dos subcategorías de problemas de clasificación:
- Problemas con solo dos clases (clasificación de dos clases o binaria)
- Problemas con más de dos clases (clasificación multiclase)
Estudio de Machine Learning (clásico) tiene diversos módulos para tratar con cada uno de estos tipos de clasificación, pero los métodos para interpretar sus resultados de predicción son similares.
Clasificación multiclase
Experimento de ejemplo
Un ejemplo de un problema de clasificación de dos clases es la clasificación de flores de iris. La tarea consiste en clasificar flores de iris en función de sus características. El conjunto de datos de Iris proporcionado en Estudio de Machine Learning (clásico) es un subconjunto del conjunto de datos de Iris popular, que contiene instancias de solo dos especies de flor (clases 0 y 1). Existen cuatro características para cada flor (longitud del sépalo, ancho del sépalo, longitud del pétalo y ancho del pétalo).
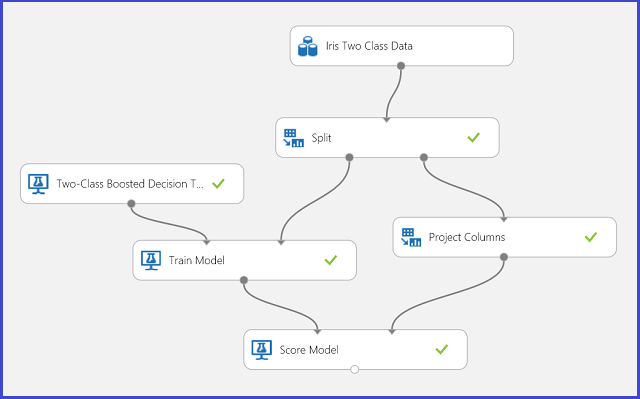
Figura 1. Experimento del problema de clasificación de dos clases de iris
Como se muestra en la figura 1, se ha realizado un experimento para solucionar este problema. Se ha entrenado y puntuado un modelo de árbol de decisión de dos clases. Ahora podemos visualizar los resultados de predicción del módulo Puntuar modelo haciendo clic en el puerto de salida del módulo Puntuar modelo y, a continuación, haciendo clic en Visualizar.
Esto mostrará los resultados de puntuación, como se muestra en la figura 2.
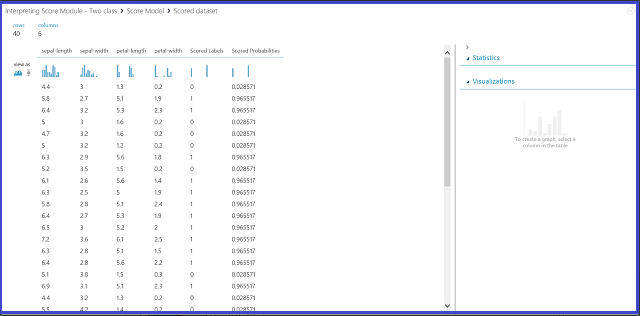
Ilustración 2. Visualización del resultado del modelo de puntuación en la clasificación de dos clases
Interpretación de resultados
Hay seis columnas en la tabla de resultados. Las cuatro columnas de la izquierda son las cuatro características. Las dos columnas de la derecha, Etiquetas puntuadas y Probabilidades puntuadas, son los resultados de predicción. La columna Probabilidades puntuadas muestra la probabilidad de que una flor pertenezca a la clase positiva (Clase 1). Por ejemplo, el primer número de la columna (0,028571) significa que hay una probabilidad de 0,028571 de que la primera flor pertenezca a la Clase 1. La columna Etiquetas puntuadas muestra la clase prevista de cada flor. Esto se basa en la columna Probabilidades de puntuación. Si la probabilidad puntuada de una flor es mayor que 0,5, se prevé que sea la Clase 1. En caso contrario, se prevé que sea la Clase 0.
Publicación de servicios web
Una vez comprendidos los resultados de la predicción, el experimento puede publicarse como un servicio web, de forma que pueda implementarlo en diversas aplicaciones y llamarlo para que obtenga las predicciones de clase en cualquier flor de iris nueva. Para obtener información sobre cómo cambiar un experimento de entrenamiento a un experimento de puntuación y publicarlo como un servicio web, consulte Tutorial 3: Implementación del modelo de riesgo crediticio. Este procedimiento proporciona un experimento de puntuación, como muestra la figura 3.
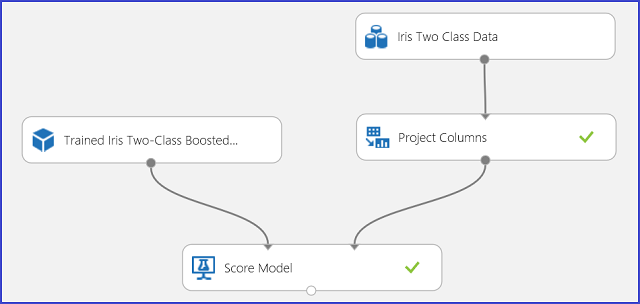
Figura 3. Puntuación del experimento del problema de clasificación de dos clases de iris
Ahora debe establecer la entrada y salida del servicio web. Obviamente, la entrada es el puerto de entrada derecho del Módulo de puntuación, que es la entrada de las características de la flor Iris. La elección del resultado depende de si está interesado en la clase de predicción (etiqueta puntuada), en la probabilidad puntuada o en ambas. En este ejemplo, se supone que está interesado en ambas. Para seleccionar las columnas de salida deseadas, use un módulo Seleccionar columnas de conjunto de datos. Haga clic en Seleccionar columnas de conjunto de datos y en Iniciar el selector de columnas, y seleccione Etiquetas puntuadas y Probabilidades puntuadas. Después de configurar el puerto de salida de Seleccionar columnas de conjunto de datos y ejecutarlo de nuevo, deberíamos estar preparados para publicar el experimento de puntuación como un servicio web haciendo clic en PUBLICAR SERVICIO WEB. El experimento final es similar a la figura 4.
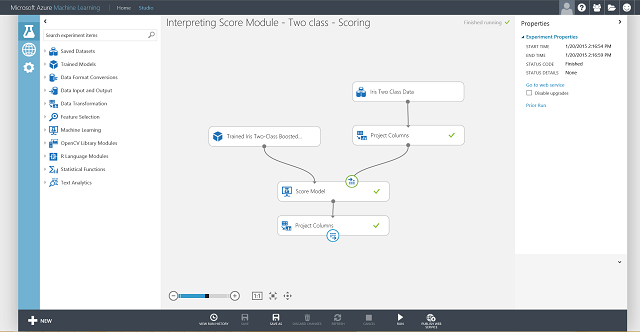
Figura 4. Experimento de puntuación final de un problema de clasificación de dos clases de iris
Después de la ejecución del servicio web y de escribir algunos valores de las características de una instancia de prueba, el resultado devuelve dos números. El primer número es la etiqueta puntuada y, el segundo, la probabilidad puntuada. Se prevé que esta flor sea de Clase 1 con probabilidad de 0,9655.
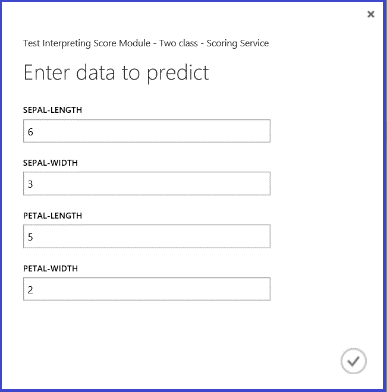

Figura 5. Resultado de servicio web de la clasificación de dos clases de iris
Clasificación multiclase
Experimento de ejemplo
En este experimento se llevará a cabo una tarea de reconocimiento de letras como un ejemplo de clasificación multiclase. El clasificador intentará predecir una letra determinada %28clase%29 en función de algunos valores de atributo escritos a mano extraídos de las imágenes realizadas a mano.
En los datos de entrenamiento, hay 16 funciones extraídas de imágenes de letras escritas a mano. Las 26 letras forman nuestras 26 clases. En la figura 6 se muestra un experimento que entrenará un modelo de clasificación multiclase para el reconocimiento de letras y predecirá en el mismo conjunto de características de un conjunto de datos de prueba.
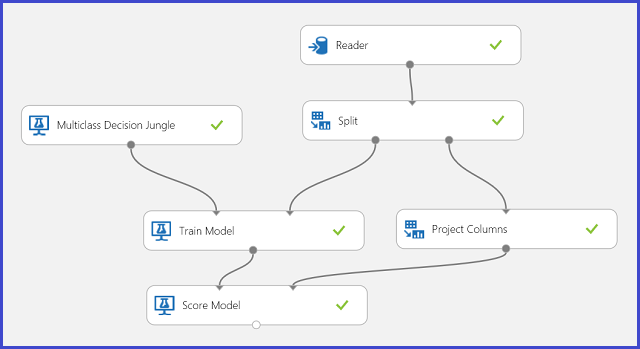
Figura 6. Experimento del problema de clasificación multiclase de reconocimiento de letras
Al visualizar los resultados del módulo Puntuar modelo haciendo clic en el puerto de salida del módulo Puntuar modelo y, a continuación, haciendo clic en Visualizar, debería ver contenido como el que se muestra en la figura 7.
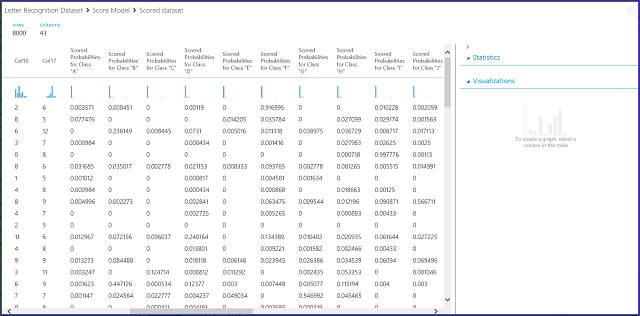
Ilustración 7. Visualización de los resultados del modelo de puntuación en una clasificación multiclase
Interpretación de resultados
Las 16 columnas de la izquierda representan los valores de funciones del conjunto de pruebas. Las columnas con nombres como Probabilidades puntuadas de la clase "XX" son iguales que la columna Probabilidades puntuadas en el caso de dos clases. Muestran la probabilidad de que la entrada correspondiente se encuentre en una clase determinada. Por ejemplo, para la primera entrada, hay una probabilidad de 0,003571 de que sea una "A", una probabilidad de 0,000451 de que sea una "B", etc. Las última columna (Etiquetas puntuadas) es la misma que Etiquetas puntuadas en el caso de dos clases. Selecciona la clase con la mayor probabilidad puntuada como la clase de predicción de la entrada correspondiente. Por ejemplo, para la primera entrada, la etiqueta puntuada es "F", ya que tiene la mayor probabilidad de que sea una "F" (0,916995).
Publicación de servicios web
También puede obtener la etiqueta puntuada para cada entrada y la probabilidad de la etiqueta puntuada. La lógica básica es encontrar la probabilidad más alta entre todas las probabilidades puntuadas. Para ello, debe usar el módulo Ejecutar script R. El código R se muestra en la figura 8, mientras que el resultado del experimento se muestra en la figura 9.

Figura 8. Código R para extraer etiquetas puntuadas y las probabilidades asociadas de las etiquetas
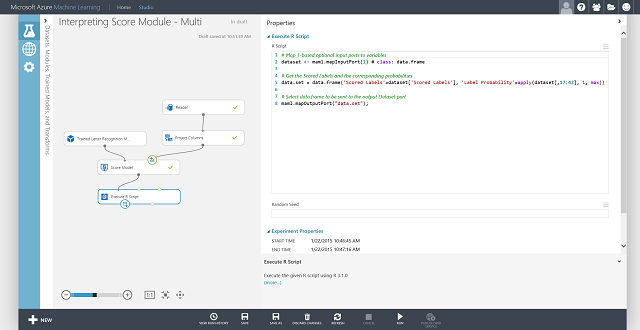
Figura 9. Experimento de puntuación final del problema de clasificación multiclase de reconocimiento de letras
Después de publicar y ejecutar el servicio web y especificar algunos valores de características de entrada, el resultado devuelto será como el mostrado en la figura 10. Se prevé que esta letra escrita a mano, con sus 16 funciones extraídas, sea una "T", con una probabilidad del 0,9715.
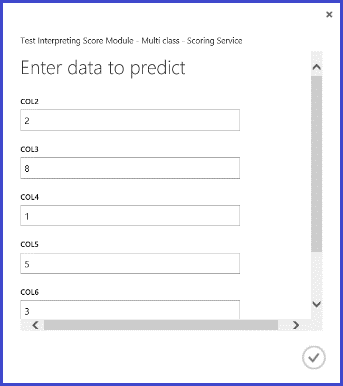

Figura 10. Resultado de servicio web de la clasificación multiclase
Regresión
Los problemas de regresión son diferentes de los problemas de clasificación. En un problema de clasificación, intenta predecir clases discretas, como a qué clase pertenece una flor iris. Sin embargo, como puede ver en el siguiente ejemplo de un problema de regresión, intenta predecir una variable continua, como el precio de un automóvil.
Experimento de ejemplo
Use la predicción de precios de automóviles como su ejemplo de regresión. Intentaremos predecir el precio de un automóvil en función de sus características, como la fabricación, el tipo de combustible, el tipo de carrocería y el volante. El experimento se muestra en la figura 11.
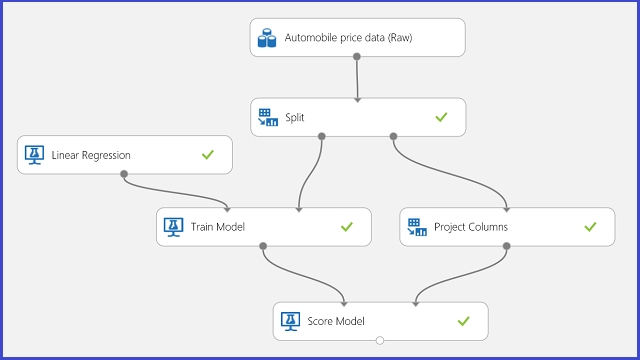
Figura 11. Experimento del problema de regresión de precios de automóviles
Al ver el módulo Modelo de puntuación, el resultado es parecido al de la figura 12.
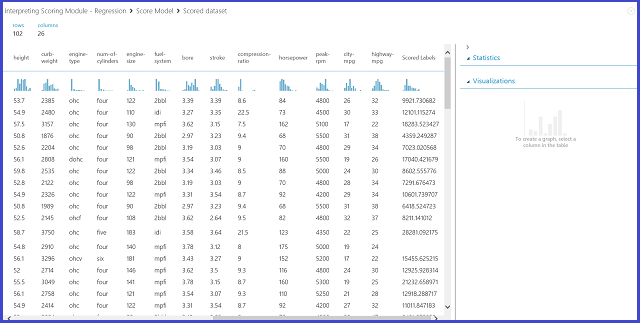
Ilustración 12. Resultado de puntuación del problema de predicción de precios de automóviles
Interpretación de resultados
Etiquetas puntuadas es la columna de resultados en el resultado de esta puntuación. Los números son el precio de predicción de cada uno.
Publicación de servicios web
Puede publicar el experimento de regresión en un servicio web y llamarlo para la predicción de precios de automóviles de la misma forma que con el caso de uso de clasificación de dos clases.
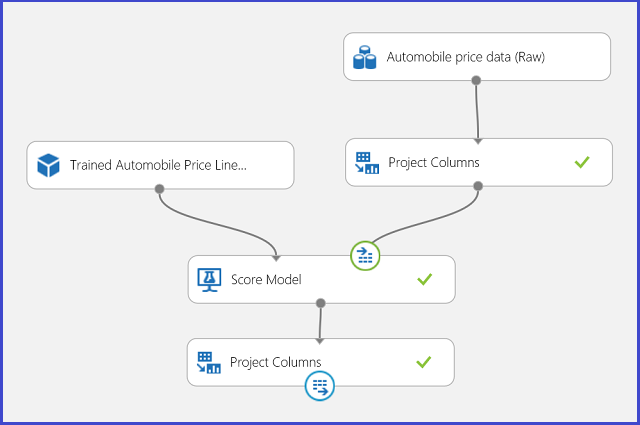
Ilustración 13. Experimento de puntuación de un problema de regresión de precios de automóviles
Al ejecutar el servicio web, el resultado devuelto es similar al de la figura 14. El precio de predicción para este automóvil es de 15.085,52 $.
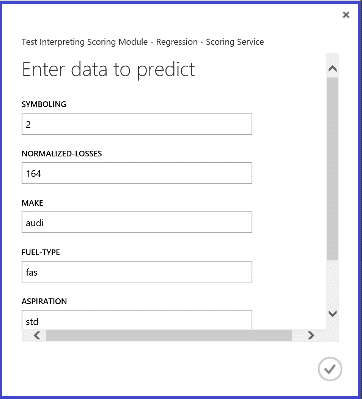

Figura 14. Resultado del servicio web de un problema de regresión de precios de automóviles
Agrupación en clústeres
Experimento de ejemplo
Usemos de nuevo el conjunto de datos de Iris para generar un experimento de agrupación en clústeres. Aquí puede filtrar las etiquetas de clase del conjunto de datos, de forma que solo tenga características y pueda usarse para la agrupación en clústeres. En este caso de uso de iris, especifique el número de clústeres en dos durante el proceso de entrenamiento, lo que significa que le gustaría agrupar las flores en dos clases. El experimento se muestra en la figura 15.
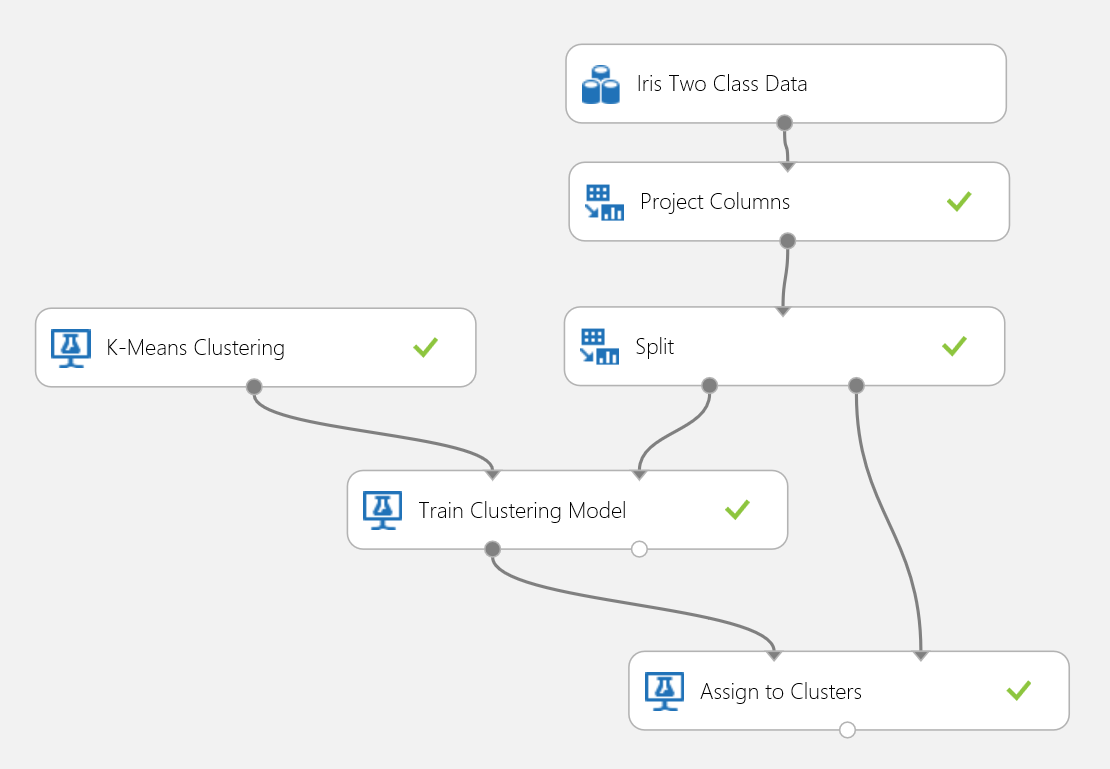
Figura 15. Experimento del problema de agrupación en clústeres de iris
La agrupación en clústeres se diferencia de la clasificación en que el conjunto de datos de entrenamiento no tiene etiquetas de realidad por sí mismo. La agrupación en clústeres agrupa las instancias del conjunto de datos en clústeres diferentes. Durante el proceso de entrenamiento, el modelo etiqueta las entradas al conocer las diferencias entre sus características. Después, el modelo entrenado se puede usar para clasificar entradas futuras. Hay dos partes del resultado que nos interesan en un problema de agrupación en clústeres. La primera parte es el etiquetado del conjunto de datos de entrenamiento y, la segunda, la clasificación de un nuevo conjunto de datos con el modelo entrenado.
La primera parte del resultado se puede visualizar haciendo clic en el puerto de salida izquierdo de Entrenar modelo de agrupación en clústeres y, a continuación, en Visualizar. La visualización se muestra en la figura 16.
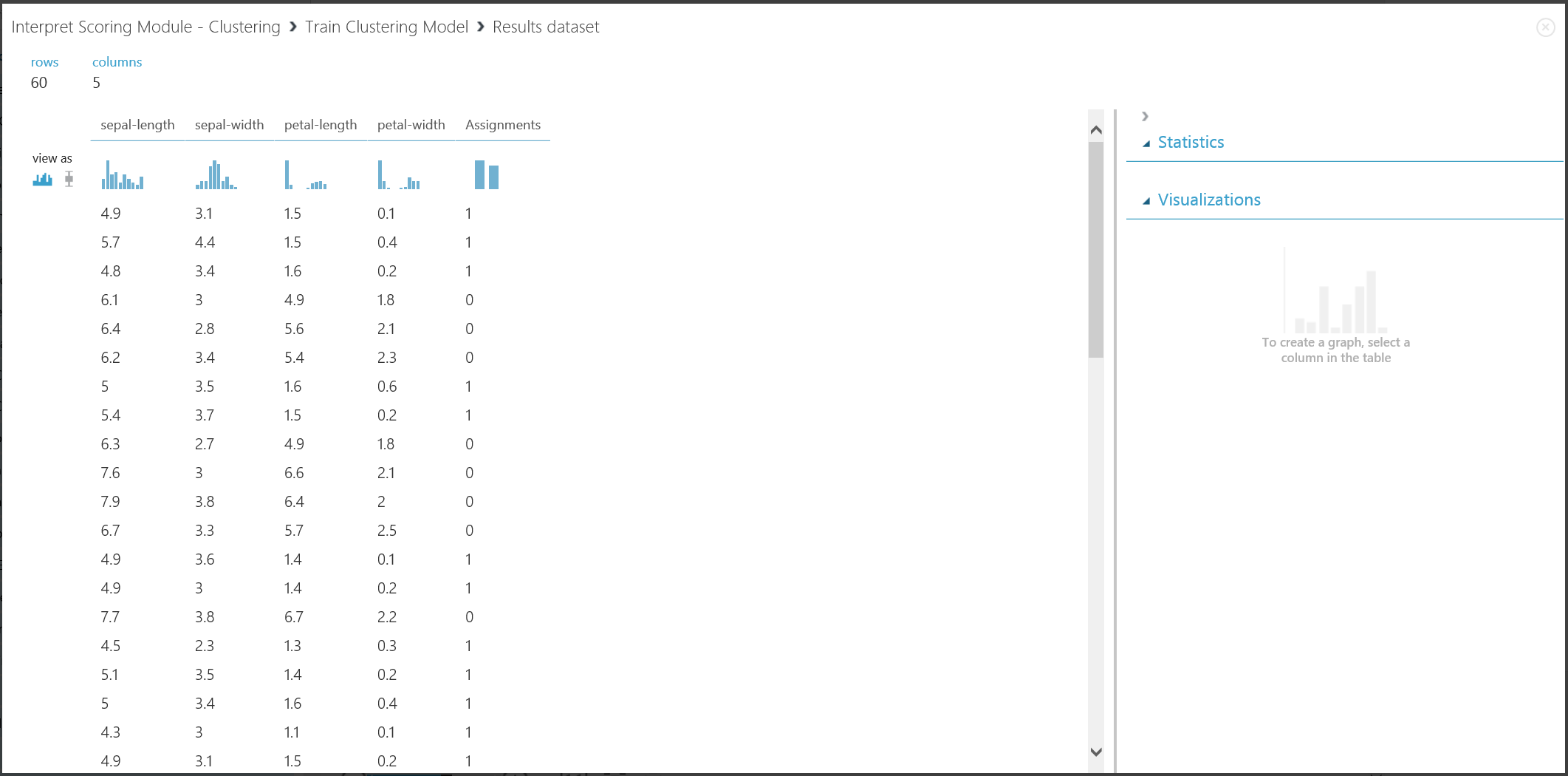
Figura 16. Visualización de resultado de agrupación en clústeres para el conjunto de datos de entrenamiento
El resultado de la segunda parte, agrupación en clústeres nuevas entradas con el modelo de agrupación en clústeres de aprendizaje, se muestra en la figura 17.
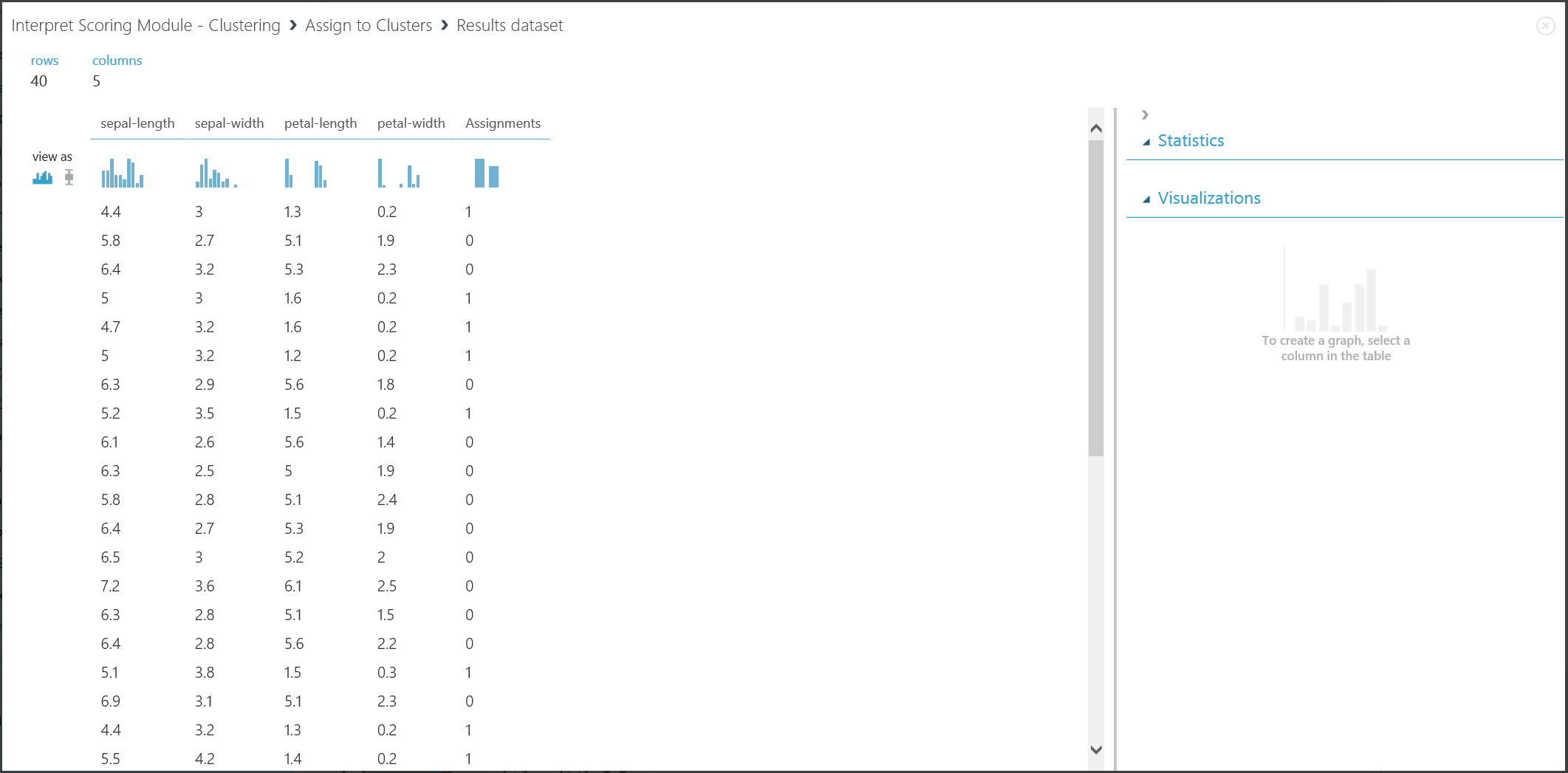
Figura 17. Visualización de resultado de agrupación en clústeres en un nuevo conjunto de datos
Interpretación de resultados
Aunque los resultados de las dos partes se derivan de diferentes fases del experimento, tienen el mismo aspecto y se interpretan de la misma manera. Las primeras cuatro columnas son características. La última columna, Asignaciones, es el resultado de predicción. Se prevé que las entradas asignadas al mismo número estén en el mismo clúster, es decir, que compartan similitudes de alguna manera (este experimento usa la métrica de distancia euclidiana predeterminada). Al haber especificado que el número de clústeres es 2, las entradas de Asignaciones se etiquetan como 0 o 1.
Publicación de servicios web
Puede publicar el experimento de agrupación en clústeres en un servicio web y llamarlo para las predicciones de agrupación en clústeres de la misma forma que con el caso de uso de clasificación de dos clases.
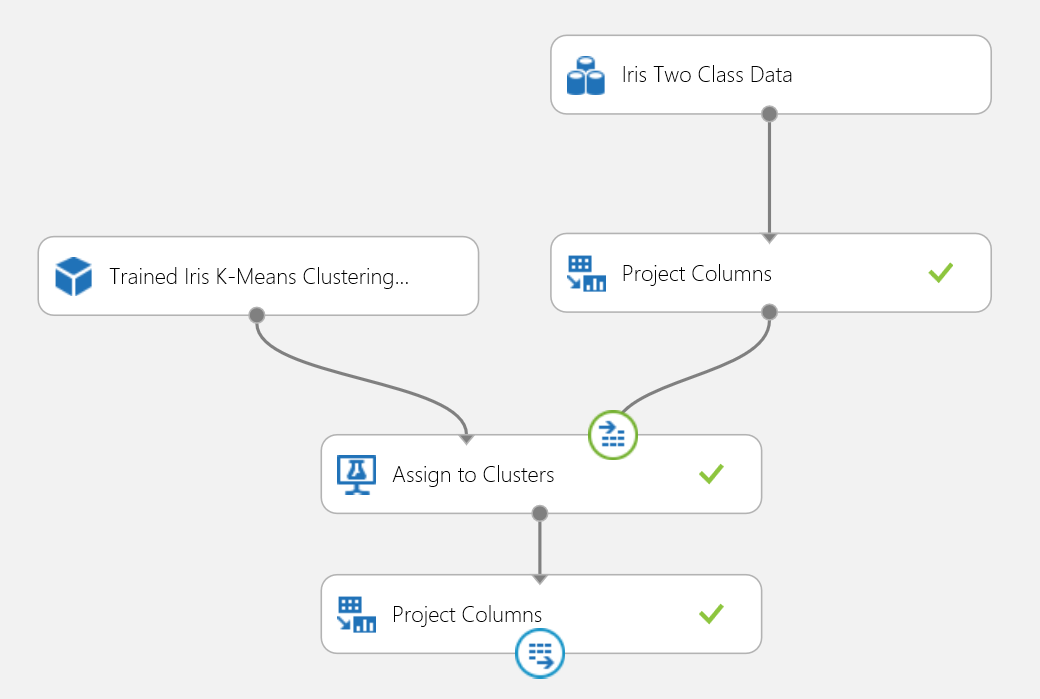
Figura 18. Experimento de puntuación de un problema de agrupación en clústeres de iris
Tras ejecutar el servicio web, el resultado devuelto es similar al de la figura 19. Se prevé que esta flor esté en el clúster 0.
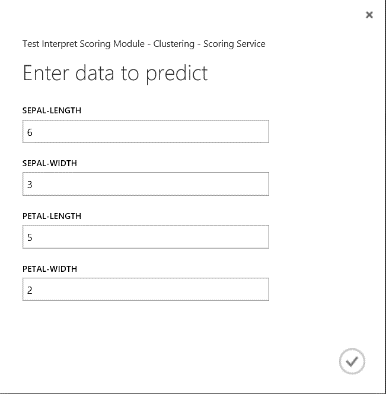

Figura 19. Resultado de servicio web de la clasificación de dos clases de iris
Sistema de recomendación
Experimento de ejemplo
Para los sistemas de recomendación, puede usar el problema de la recomendación de restaurante como ejemplo: puede recomendar restaurantes a los clientes basándose en su historial de valoración. Los datos de entrada constan de tres partes:
- Valoraciones de restaurantes de los clientes
- Datos de características de los clientes
- Datos de características de restaurantes
Hay varias tareas que podemos hacer con el módulo integrado Train Matchbox Recommender de Estudio de Machine Learning (clásico):
- predecir las valoraciones para un usuario determinado y un elemento;
- recomendar elementos a un usuario determinado;
- buscar usuarios relacionados con un usuario determinado;
- buscar elementos relacionados con un elemento determinado.
Puede elegir lo que quiere hacer mediante la selección de las cuatro opciones en el menú Tipo de predicción de recomendación. De este modo, podrá recorrer los cuatro escenarios.
Un experimento de Estudio de Machine Learning (clásico) típico para un sistema de recomendación es similar al de la figura 20. Para información sobre cómo usar los módulos del sistema de recomendación, vea la página de ayuda Train Matchbox Recommender y Score Matchbox Recommender.
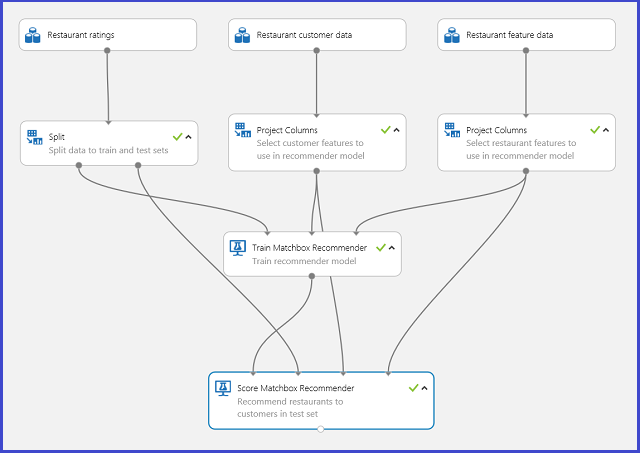
Figura 20. Experimento del sistema de recomendación
Interpretación de resultados
Predecir las valoraciones para un usuario determinado y un elemento
Al seleccionar la predicción de valoración en Tipo de predicción de recomendación, pide al sistema de recomendación que prediga la valoración de un usuario y un elemento determinados. La visualización del resultado del Score Matchbox Recommender es similar a la de la figura 21.
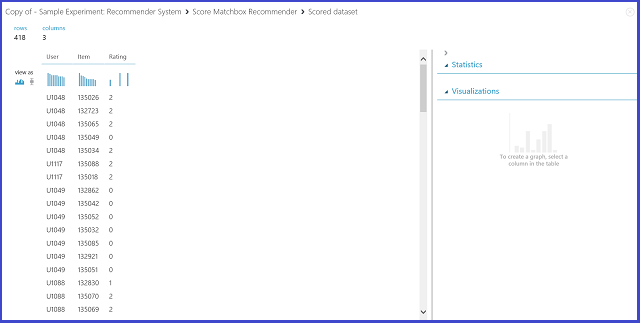
Figura 21. Visualización del resultado de puntuación del sistema de recomendación: valoración de predicción
Las dos primeras columnas son los pares de elemento-usuario proporcionados por los datos de entrada. La tercera columna es la valoración de predicción de un usuario para un elemento determinado. Por ejemplo, en la primera fila, se prevé que el cliente U1048 valore el restaurante 135026 como 2.
Recomendar elementos a un usuario determinado
Al seleccionar Recomendación de elementos en Tipo de predicción de recomendación, pide al sistema de recomendación que recomiende elementos a un usuario determinado. El último parámetro que elegir en este escenario es la selección de elementos recomendados. La opción De elementos valorados (para la evaluación de modelos) es principalmente para la evaluación de modelos durante el proceso de entrenamiento. Para esta fase de predicción, elegiremos De todos los elementos. La visualización del resultado del Score Matchbox Recommender es similar a la de la figura 22.
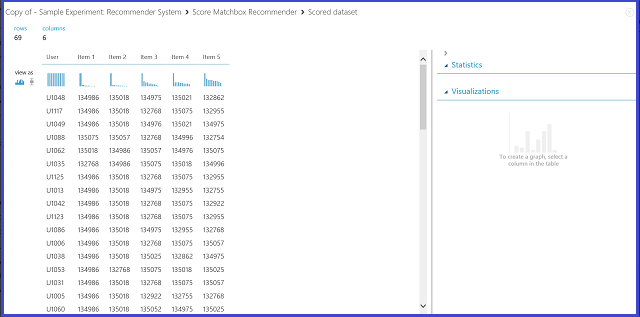
Figura 22. Visualización del resultado de puntuación del sistema de recomendación: recomendación de elementos
La primera de las seis columnas representa los id. de usuario determinados para los que recomendar elementos, proporcionados por los datos de entrada. Las otras cinco columnas representan los elementos que se recomiendan para el usuario en orden descendente de relevancia. Por ejemplo, en la primera fila, el restaurante más recomendado para el cliente U1048 es 134986, seguido de 135018, 134975, 135021 y 132862.
Buscar usuarios relacionados con un usuario determinado
Al seleccionar usuarios relacionados en Tipo de predicción de recomendación, pide al sistema de recomendación que busque usuarios relacionados a un usuario determinado. Los usuarios relacionados son los usuarios que tienen preferencias similares. El último parámetro que elegir en este escenario es la selección de usuarios relacionados. La opción De elementos valorados (para la evaluación de modelos) es principalmente para la evaluación de modelos durante el proceso de entrenamiento. Para esta fase de predicción, elija De todos los usuarios. La visualización del resultado del Score Matchbox Recommender es similar a la de la figura 23.
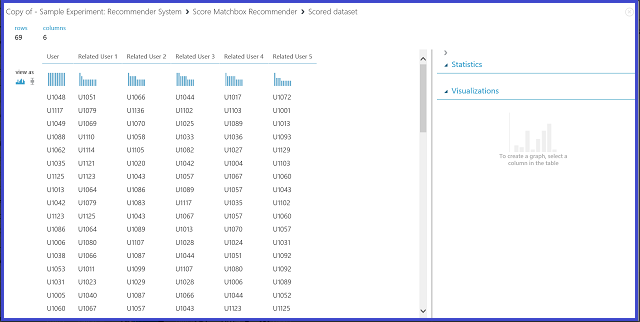
Figura 23. Visualización de los resultados de puntuación del sistema de recomendación: usuarios relacionados
La primera de las seis columnas muestra los id. de usuario determinados necesarios para encontrar usuarios relacionados, proporcionados por los datos de entrada. Las otras cinco columnas almacenan los usuarios relacionados previstos del usuario en orden descendente de relevancia. Por ejemplo, en la primera fila, el cliente más pertinente para el cliente U1048 es U1051, seguido de U1066, U1044, U1017 y U1072.
Buscar elementos relacionados con un elemento determinado
Al seleccionar usuarios relacionados en Tipo de predicción de recomendación, pide al sistema de recomendación que busque elementos relacionados a un elemento determinado. Los elementos relacionados son los que tienen mayor probabilidad de estar vinculados al mismo usuario. El último parámetro que elegir en este escenario es la selección de elementos relacionados. La opción De elementos valorados (para la evaluación de modelos) es principalmente para la evaluación de modelos durante el proceso de entrenamiento. Para esta fase de predicción, elegiremos De todos los elementos . La visualización del resultado del Score Matchbox Recommender es similar a la de la figura 24.
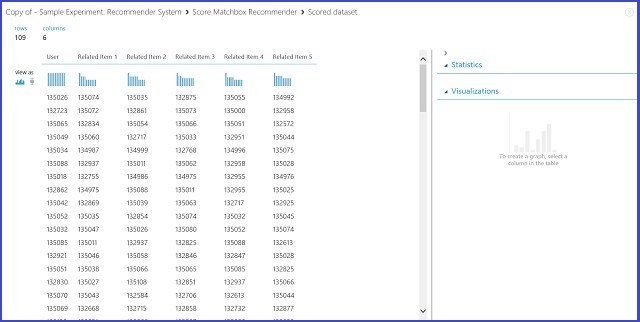
Figura 24. Visualización de los resultados de puntuación del sistema de recomendación: elementos relacionados
La primera de las seis columnas representa los id. de elemento determinados necesarios para encontrar elementos relacionados, proporcionados por los datos de entrada. Las otras cinco columnas almacenan los elementos relacionados previstos del elemento en orden descendente en términos de relevancia. Por ejemplo, en la primera fila, el elemento más pertinente para el elemento 135026 es 135074, seguido de 135035, 132875, 135055 y 134992.
Publicación de servicios web
El proceso de publicación de estos experimentos como servicios web para obtener predicciones es similar para cada uno de los cuatro escenarios. Aquí veremos el segundo escenario (el de recomendar elementos a un usuario determinado) como ejemplo. Puede seguir el mismo procedimiento con los otros tres.
Al guardar el sistema entrenado de recomendación como un modelo entrenado y filtrar los datos de entrada a una columna de identificador de usuario único como se solicitó, puede enlazar el experimento como se muestra en la figura 25 y publicarlo como un servicio web.
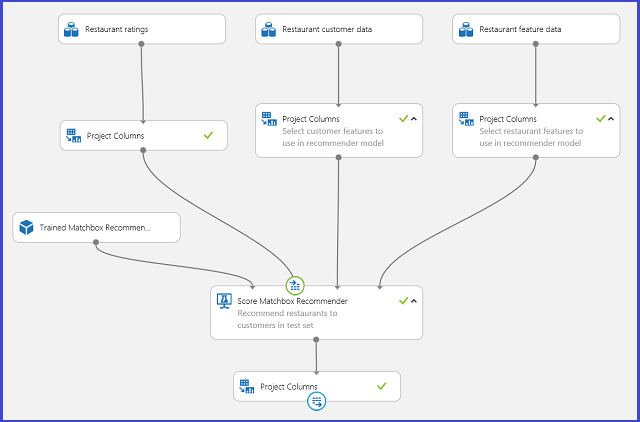
Figura 25. Experimento de puntuación del problema de recomendación de restaurante
Al ejecutar el servicio web, el resultado devuelto es similar al de la figura 26. Los cinco restaurantes recomendados para el usuario U1048 son 134986, 135018, 134975, 135021 y 132862.
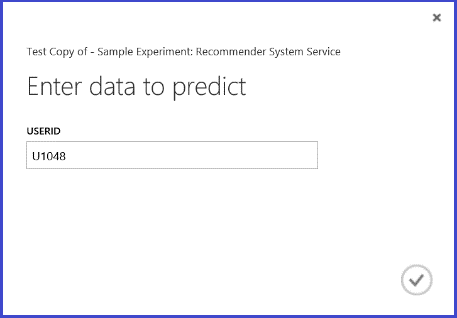

Figura 26. Resultado de servicio web del problema de recomendación de restaurante