Creación y ejecución de canalizaciones de aprendizaje automático mediante componentes con el Estudio de Azure Machine Learning
SE APLICA A: Extensión de ML de la CLI de Azure v2 (actual)
Extensión de ML de la CLI de Azure v2 (actual)
En este artículo, aprenderá a crear y ejecutar canalizaciones de aprendizaje automático mediante Estudio de Azure Machine Learning y sus componentes. Puede crear canalizaciones sin usar componentes, pero tenga en cuenta que los componentes ofrecen un nivel mejorado de flexibilidad y reutilización. Las canalizaciones de Azure Machine Learning se pueden definir en YAML y ejecutarse desde la CLI, crearse en Python, o componerse en el Diseñador de Estudio de Azure Machine Learning con una interfaz de usuario que se pueda arrastrar y colocar. Este documento se centra en la interfaz de usuario del diseñador de Estudio de Azure Machine Learning.
Requisitos previos
Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un área de trabajo de Azure Machine Learning. Vea Creación de los recursos de área de trabajo.
Instalación y configuración de la extensión de la CLI de Azure para Machine Learning.
Clone el repositorio de ejemplos:
git clone https://github.com/Azure/azureml-examples --depth 1 cd azureml-examples/cli/jobs/pipelines-with-components/
Nota:
El diseñador admite dos tipos de componentes: componentes precompilados clásicos (v1) y componentes personalizados (v2). Estos dos tipos de componentes NO son compatibles.
Los componentes precompilados clásicos proporcionan componentes precompilados principalmente para el procesamiento de datos y las tareas tradicionales de aprendizaje automático, como la regresión y la clasificación. Este tipo de componentes se sigue admitiendo, pero no se agregará ningún componente nuevo.
Los componentes personalizados le permiten ajustar su propio código como componente. Admite el uso compartido de componentes entre áreas de trabajo y la creación fluida entre las interfaces de Estudio, CLI v2 y SDK v2.
Para los proyectos nuevos, le recomendamos que utilice el componente personalizado, que es compatible con AzureML V2, y seguirá recibiendo nuevas actualizaciones.
Este artículo se aplica a componentes personalizados.
Registro del componente en el área de trabajo
Para compilar la canalización mediante componentes de la interfaz de usuario, primero debe registrar los componentes en el área de trabajo. Puede usar la UI, la CLI o el SDK para registrar los componentes en el área de trabajo, de modo que pueda compartir y reutilizarlos en la misma área de trabajo. Los componentes registrados admiten el control de versiones automático para que pueda actualizar el componente, pero asegúrese de que las canalizaciones que requieren una versión anterior sigan funcionando.
En el ejemplo siguiente se usa la interfaz de usuario para registrar componentes y los archivos de origen del componente se encuentran en el directorio cli/jobs/pipelines-with-components/basics/1b_e2e_registered_components del azureml-examplesrepositorio. Primero debe clonar el repositorio en local.
- En el área de trabajo de Azure Machine Learning, vaya a la página Componentes y seleccione Nuevo componente (aparecerá una de las dos páginas de estilo).


En este ejemplo usa train.ymlen el directorio. El archivo YAML define el nombre, el tipo, la interfaz, incluidas las entradas y salidas, el código, el entorno y el comando de este componente. El código de este componente train.py está en la carpeta ./train_src, que describe la lógica de ejecución de este componente. Para obtener más información sobre el esquema de componentes, consulte la referencia del esquema YAML del componente de comandos.
Nota:
Cuando registra componentes en la interfaz de usuario, code definido en el archivo YAML del componente solo puede apuntar a la carpeta actual donde se encuentra el archivo YAML o las subcarpetas, lo que significa que no se puede especificar ../ para code, ya que la interfaz de usuario no puede reconocer el directorio primario.
additional_includes solo puede apuntar a la carpeta actual o secundaria.
Actualmente la interfaz de usuario solo admite el registro de componentes con el tipo command.
- Seleccione Cargar desde Carpeta y seleccione la carpeta
1b_e2e_registered_componentsque se va a cargar. Seleccionetrain.ymlde la lista desplegable.

Seleccione Siguiente en la parte inferior y puede confirmar los detalles de este componente. Una vez que haya confirmado, seleccione Crear para finalizar el proceso de registro.
Repita los pasos anteriores para registrar el componente Score y Eval mediante
score.ymlyeval.yml.Después de registrar correctamente los tres componentes, puede ver los componentes en la interfaz de usuario de Studio.

Creación de una canalización mediante el componente registrado
Cree una canalización en el diseñador. No olvide seleccionar la opción Personalizado.

Asigne un nombre descriptivo a la canalización seleccionando el icono de lápiz junto al nombre generado automáticamente.

En la biblioteca de recursos del diseñador, puede ver las pestañas Datos, Modelo y Componentes. Cambie a la pestaña Componentes; en ella podrá ver los componentes registrados en la sección anterior. Si hay demasiados componentes, puede buscar con el nombre del componente.
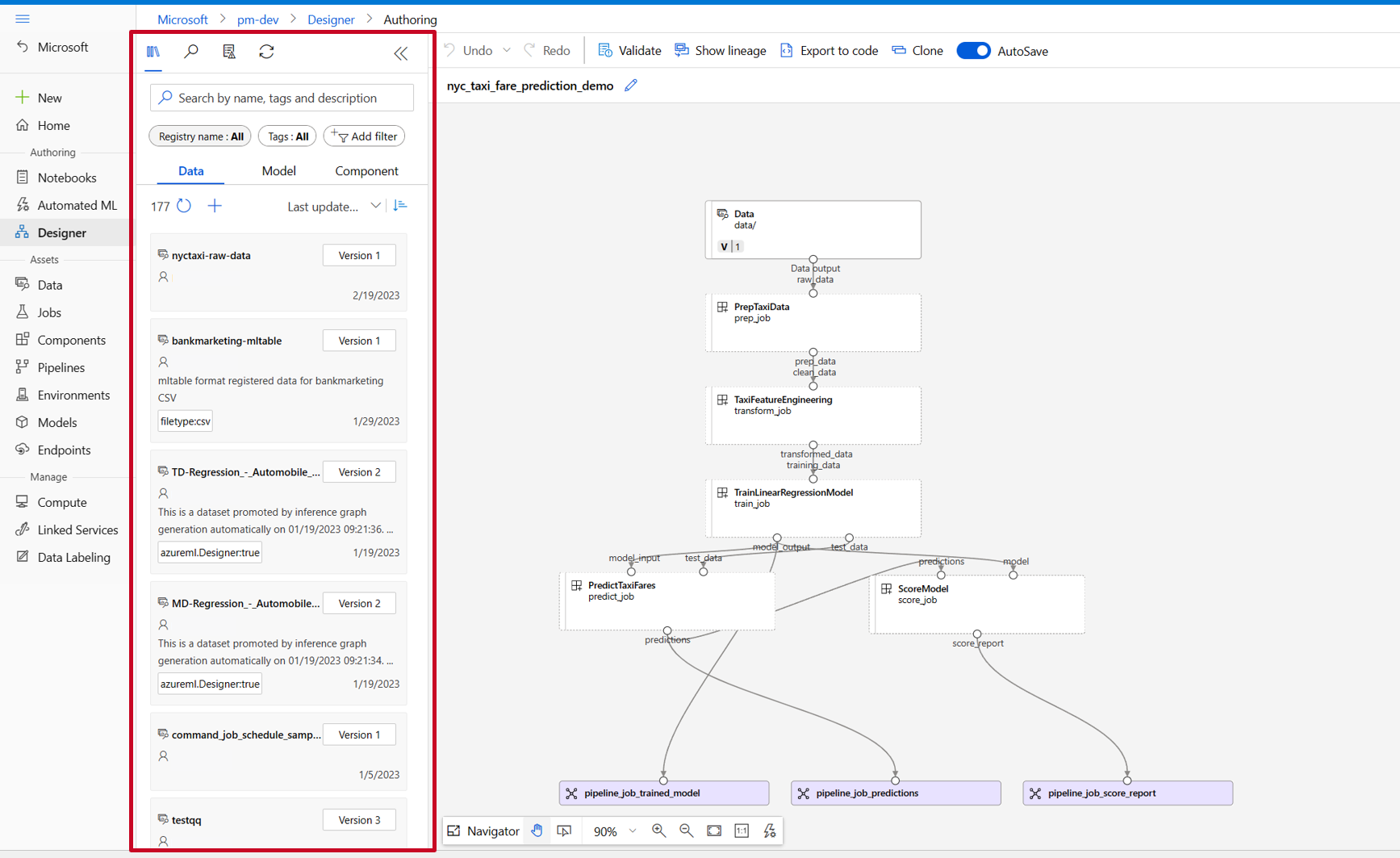
Busque los componentes entrenar, puntuación y eval registrados en la sección anterior y arrástrelos y colóquelos en el lienzo. Normalmente usa la versión predeterminada del componente, pero puede cambiar a una versión específica en el panel derecho del componente. El panel derecho del componente se invoca haciendo doble clic en él.
En este ejemplo, usaremos los datos de ejemplo en esta ruta de acceso. Para registrar los datos en el área de trabajo, seleccione el icono Agregar en la biblioteca de recursos del diseñador: -> pestaña datos, establezca Tipo = Carpeta(uri_folder) y, a continuación, siga el asistente para registrar los datos. El tipo de datos debe ser uri_folder para alinearse con la definición del componente de entrenamiento.

A continuación, arrastre y coloque los datos en el lienzo. Ahora, la apariencia de la canalización debería ser similar a la siguiente captura de pantalla.

Conecte los datos y los componentes arrastrando conexiones en el lienzo.

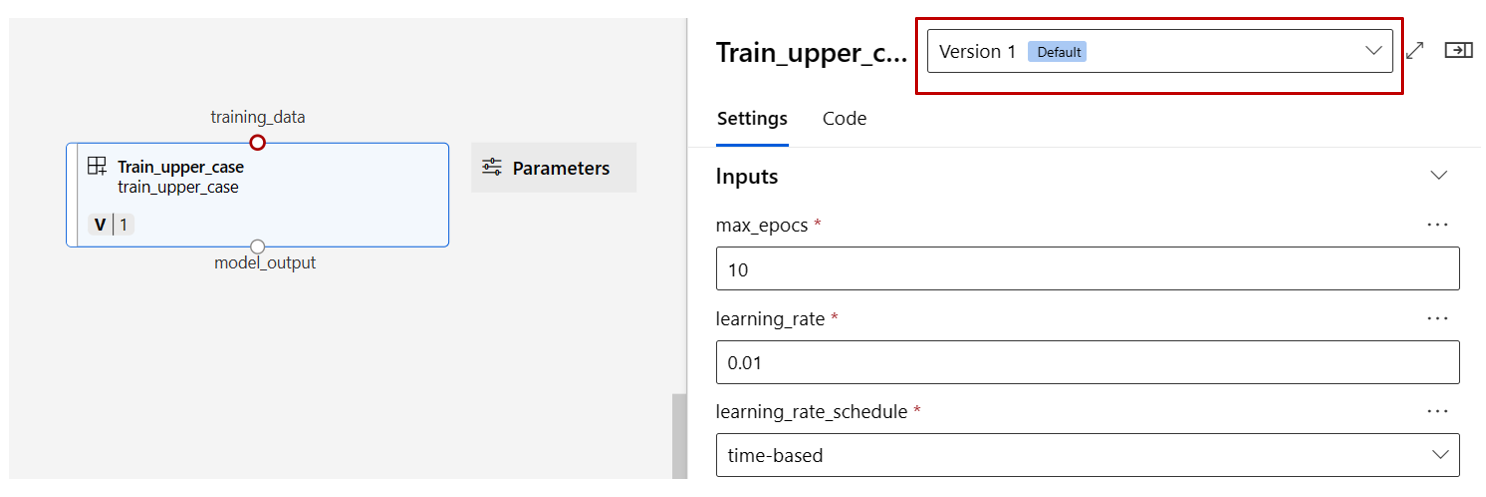
Haga doble clic en un componente (verá un panel derecho donde lo puede configurar).

En el caso de los componentes con entradas de tipo primitivo como "number", "integer", "string" y "boolean", puede cambiar los valores de estas entradas en el panel detallado del componente, en la sección Entradas.
También puede cambiar la configuración de salida (dónde almacenar la salida del componente) y la configuración de ejecución (destino de proceso para ejecutar este componente) en el panel derecho.
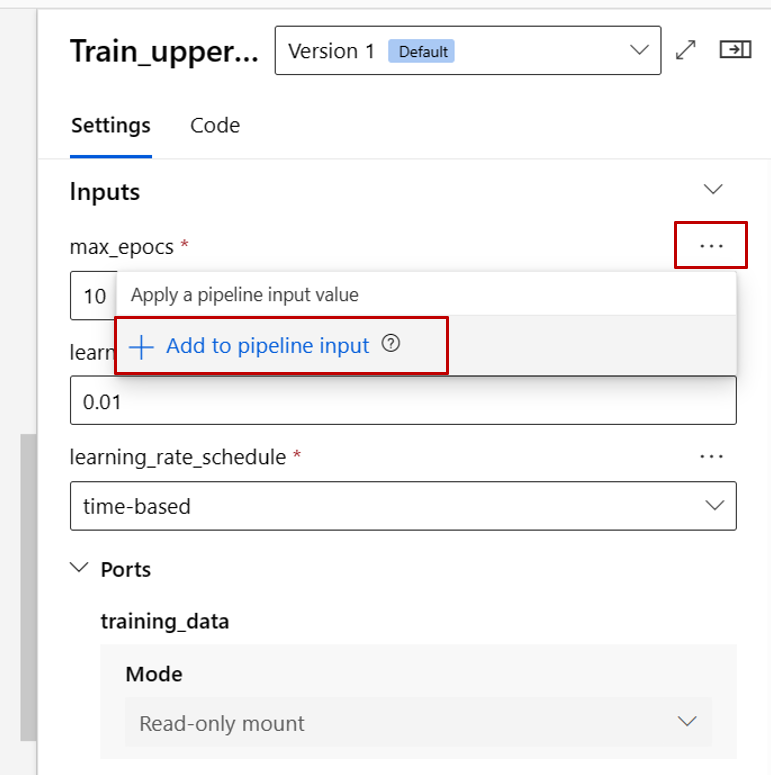
Ahora vamos a promover la entrada de max_epocs del componente de entrenamiento a la entrada de nivel de canalización. Al hacerlo, puede asignar un valor diferente a esta entrada cada vez antes de enviar la canalización.









Nota
Los componentes personalizados y los componentes precompilados clásicos del diseñador no se pueden usar juntos.
Envío de la canalización
Seleccione Configurar y enviar en la esquina superior derecha para enviar la canalización.

A continuación, verá un asistente paso a paso, siga el asistente para enviar el trabajo de canalización.

En el paso Aspectos básicos, puede configurar el experimento, el nombre para mostrar el trabajo, la descripción del trabajo, etc.
En el paso Entradas y salidas, puede configurar las entradas o salidas que se promueven al nivel de canalización. En el paso anterior, promocionamos la max_epocs del componente de entrenamiento a la entrada de canalización, por lo que debería poder ver y asignar valor a max_epocs aquí.
En Configuración del entorno de ejecución, puede configurar el almacén de datos predeterminado y el proceso predeterminado en la canalización. Es el almacén de datos o proceso predeterminado de todos los componentes de la canalización. Tenga en cuenta que si establece un proceso o almacén de datos diferente para un componente explícitamente, el sistema respeta la configuración de nivel de componente. De lo contrario, usa el valor predeterminado de la canalización.
El paso Revisar y enviar es el último paso para revisar toda las opciones de configuración antes de enviar. El asistente recuerda la configuración de la última vez si alguna vez envía la canalización.
Después de enviar el trabajo de canalización, habrá un mensaje en la parte superior con un vínculo al detalle del trabajo. Puede seleccionar este vínculo para revisar los detalles del trabajo.

Pasos siguientes
- Use estos cuadernos de Jupyter Notebook en GitHub para explorar en profundidad las canalizaciones de aprendizaje automático.
- Aprenda cómo se usa la CLI v2 para crear canalizaciones mediante componentes.
- Aprenda a usar el SDK v2 para crear canalizaciones mediante componentes.