Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
APPLIES TO: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
En Azure Machine Learning, puede usar un contenedor personalizado para implementar un modelo en un punto de conexión en línea. Las implementaciones de contenedores personalizadas pueden usar servidores web distintos del servidor predeterminado de Python Flask que usa Azure Machine Learning.
Al usar una implementación personalizada, puede hacer lo siguiente:
- Use varias herramientas y tecnologías, como TensorFlow Serving (TF Serving), TorchServe, Triton Inference Server, el paquete Plumber R y la imagen mínima de inferencia de Azure Machine Learning.
- Aún así, aproveche las ventajas de la supervisión, el escalado, las alertas y la autenticación integrados que ofrece Azure Machine Learning.
En este artículo se muestra cómo usar una imagen de servicio de TF para servir un modelo de TensorFlow.
Prerequisites
Un área de trabajo de Azure Machine Learning. Para obtener instrucciones para crear un área de trabajo, consulte Creación del área de trabajo.
La CLI de Azure y la
mlextensión o el SDK de Python de Azure Machine Learning v2:Para instalar la CLI de Azure y la
mlextensión, consulte Instalación y configuración de la CLI (v2).En los ejemplos de este artículo se supone que se usa un shell de Bash o un shell compatible. Por ejemplo, puede usar un shell en un sistema Linux o subsistema de Windows para Linux.
Un grupo de recursos de Azure que contiene tu espacio de trabajo y al que tú o tu entidad de servicio tenéis acceso como Colaborador. Si usa los pasos descritos en Creación del área de trabajo para configurar el área de trabajo, cumple este requisito.
Docker Engine, installed and running locally. This prerequisite is highly recommended. Necesita implementar un modelo localmente y resulta útil para la depuración.
Deployment examples
The following table lists deployment examples that use custom containers and take advantage of various tools and technologies.
| Example | Script de la CLI de Azure | Description |
|---|---|---|
| minimal/multimodel | deploy-custom-container-minimal-multimodel | Implementa varios modelos en una sola implementación mediante la extensión de la imagen mínima de inferencia de Azure Machine Learning. |
| minimal/single-model | deploy-custom-container-minimal-single-model | Implementa un único modelo mediante la extensión de la imagen mínima de inferencia de Azure Machine Learning. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Implementa dos modelos de MLFlow con distintos requisitos de Python en dos implementaciones independientes detrás de un único punto de conexión. Usa la imagen mínima de inferencia de Azure Machine Learning. |
| r/multimodel-plumber | deploy-custom-container-r-multimodel-plumber | Implementa tres modelos de regresión en un punto de conexión. Usa el paquete Plumber R. |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Implementa un modelo Half Plus Two mediante un contenedor personalizado tf Serving. Usa el proceso de registro de modelos estándar. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Implementa un modelo Half Plus Two mediante un contenedor personalizado tf Serving con el modelo integrado en la imagen. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Implementa un único modelo mediante un contenedor personalizado de TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Implementa un modelo de Triton mediante un contenedor personalizado. |
En este artículo se muestra cómo usar el ejemplo tfserving/half-plus-two.
Warning
Es posible que los equipos de soporte técnico de Microsoft no puedan ayudar a solucionar problemas causados por una imagen personalizada. Si tiene problemas, es posible que se le pida que use la imagen predeterminada o una de las imágenes que Proporciona Microsoft para ver si el problema es específico de la imagen.
Descarga del código fuente
The steps in this article use code samples from the azureml-examples repository. Use los comandos siguientes para clonar el repositorio:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Inicialización de las variables de entorno
Para usar un modelo de TensorFlow, necesita varias variables de entorno. Ejecute los siguientes comandos para definir esas variables:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Descarga de un modelo de TensorFlow
Descargue y descomprima un modelo que divide un valor de entrada por dos y agrega dos al resultado:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Prueba una imagen de TF Serving localmente
Use Docker para ejecutar la imagen localmente para realizar pruebas:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Envío de solicitudes de ejecución y puntuación a la imagen
Envíe una solicitud de ejecución para comprobar que el proceso dentro del contenedor se está ejecutando. Debería obtener un código de estado de respuesta de 200 OK.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Envíe una solicitud de puntuación para comprobar que puede obtener predicciones sobre datos sin etiquetar:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
Detención de la imagen
Cuando termine de probar localmente, detenga la imagen:
docker stop tfserving-test
Implementación del punto de conexión en línea en Azure
Para implementar el punto de conexión en línea en Azure, siga los pasos descritos en las secciones siguientes.
Creación de archivos YAML para el punto de conexión y la implementación
Puede configurar la implementación en la nube mediante YAML. Por ejemplo, para configurar el punto de conexión, puede crear un archivo YAML denominado tfserving-endpoint.yml que contenga las siguientes líneas:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
Para configurar la implementación, puede crear un archivo YAML denominado tfserving-deployment.yml que contenga las siguientes líneas:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: <model-version>
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/<model-version>
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
En las secciones siguientes se describen conceptos importantes sobre los parámetros de YAML y Python.
Base image
En la environment sección de YAML o el Environment constructor de Python, especifique la imagen base como parámetro. En este ejemplo se usa docker.io/tensorflow/serving:latest como valor de image.
Si inspecciona el contenedor, puede ver que este servidor usa ENTRYPOINT comandos para iniciar un script de punto de entrada. Ese script toma variables de entorno como MODEL_BASE_PATH y MODEL_NAME, y expone puertos como 8501. Estos detalles pertenecen a este servidor y puede usar esta información para determinar cómo definir la implementación. Por ejemplo, si establece las variables de entorno MODEL_BASE_PATH y MODEL_NAME en la definición de implementación, TF Serving usa esos valores para iniciar el servidor. Del mismo modo, si establece el puerto para cada ruta en 8501 en la definición de implementación, las solicitudes de usuario a esas rutas se enrutan correctamente al servidor TF Serving.
Este ejemplo se basa en el caso tf Serving. Sin embargo, puede usar cualquier contenedor que permanezca funcionando y responda a las solicitudes que van a las rutas de disponibilidad, preparación y puntuación. Para ver cómo formar un Dockerfile para crear un contenedor, puede consultar otros ejemplos. Algunos servidores usan CMD instrucciones en lugar de ENTRYPOINT instrucciones.
Parámetro de configuración de inferencia
En la environment sección o la Environment clase , inference_config es un parámetro . Especifica el puerto y la ruta de acceso para tres tipos de rutas: disponibilidad, preparación y puntuación. El inference_config parámetro es necesario si desea ejecutar su propio contenedor con un punto de conexión en línea administrado.
Rutas de preparación frente a rutas de ejecución
Algunos servidores de API proporcionan una manera de comprobar el estado del servidor. Hay dos tipos de rutas que puede especificar para comprobar el estado:
- Liveness routes: To check whether a server is running, you use a liveness route.
- Readiness routes: To check whether a server is ready to do work, you use a readiness route.
En el contexto de la inferencia de aprendizaje automático, un servidor puede responder con un código de estado 200 Ok a una solicitud de ejecución antes de cargar un modelo. El servidor puede responder con un código de estado 200 OK a una solicitud de disponibilidad solo después de cargar el modelo en memoria.
Para obtener más información sobre los sondeos de estado activo y preparación, consulte Configurar sondeos de estado activo, preparación y inicio.
El servidor de API que elija determina las rutas de ejecución y preparación. Identifica ese servidor en un paso anterior al probar el contenedor localmente. En este artículo, la implementación de ejemplo usa la misma ruta de acceso para las rutas de ejecución y preparación, ya que TF Serving solo define una ruta de ejecución. Para ver otras formas de definir las rutas, consulte otros ejemplos.
Scoring routes
El servidor de API que usa proporciona una manera de recibir la carga útil en la que trabajar. En el contexto de la inferencia de aprendizaje automático, un servidor recibe los datos de entrada a través de una ruta específica. Identifique esa ruta para el servidor de API al probar el contenedor localmente en un paso anterior. Especifique esa ruta como ruta de puntuación al definir la implementación que se va a crear.
La exitosa creación de la implementación también actualiza el parámetro scoring_uri del punto de conexión. Para comprobar este hecho, ejecute el siguiente comando: az ml online-endpoint show -n <endpoint-name> --query scoring_uri.
Buscar el modelo montado
When you deploy a model as an online endpoint, Azure Machine Learning mounts your model to your endpoint. Cuando se monta el modelo, puede implementar nuevas versiones del modelo sin tener que crear una nueva imagen de Docker. By default, a model registered with the name my-model and version 1 is located on the following path inside your deployed container: /var/azureml-app/azureml-models/my-model/1.
Por ejemplo, considere la siguiente configuración:
- Estructura de directorios en la máquina local de /azureml-examples/cli/endpoints/online/custom-container
- Nombre de modelo de
half_plus_two
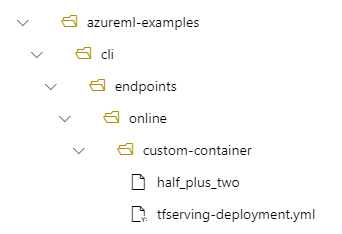
Supongamos que el archivo tfserving-deployment.yml contiene las siguientes líneas en su model sección. En esta sección, el name valor hace referencia al nombre que se usa para registrar el modelo en Azure Machine Learning.
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
En este caso, al crear una implementación, el modelo se encuentra en la carpeta siguiente: /var/azureml-app/azureml-models/tfserving-mounted/1.
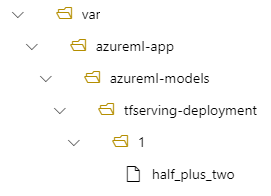
Puede configurar opcionalmente el valor model_mount_path. Al ajustar esta configuración, puede cambiar la ruta de acceso donde se monta el modelo.
Important
El valor model_mount_path debe ser una ruta de acceso absoluta válida en Linux (en el sistema operativo invitado de la imagen de contenedor).
Important
model_mount_path solo se puede usar en el escenario BYOC (Traiga su propio contenedor). En el escenario BYOC, el entorno que usa el despliegue en línea debe tener configurado el parámetro inference_config. Puede usar la CLI de Azure ML o el SDK de Python para especificar el inference_config parámetro al crear el entorno. Actualmente, la interfaz de usuario de Studio no admite la especificación de este parámetro.
Al cambiar el valor de model_mount_path, también debe actualizar la variable de entorno MODEL_BASE_PATH. Ajuste MODEL_BASE_PATH al mismo valor que model_mount_path para evitar una implementación fallida debido a un error relacionado con la ruta de acceso base que no se ha encontrado.
Por ejemplo, puede agregar el model_mount_path parámetro al archivo tfserving-deployment.yml. También puede actualizar el valor MODEL_BASE_PATH en ese archivo.
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
model_mount_path: /var/tfserving-model-mount
environment_variables:
MODEL_BASE_PATH: /var/tfserving-model-mount
...
En la implementación, el modelo se encuentra en /var/tfserving-model-mount/tfserving-mounted/1. Ya no está en azureml-app/azureml-models, sino en la ruta de acceso de montaje que ha especificado:
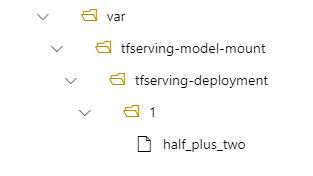
Creación del punto de conexión y la implementación
Después de construir el archivo YAML, use el siguiente comando para crear el punto de conexión:
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-endpoint.yml
Use el comando siguiente para crear la implementación. Este paso puede ejecutarse durante unos minutos.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving/half-plus-two/tfserving-deployment.yml --all-traffic
Invocación del punto de conexión
Una vez completada la implementación, realice una solicitud de puntuación al punto de conexión implementado.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Eliminación del punto de conexión
Si ya no necesita el punto de conexión, ejecute el siguiente comando para eliminarlo:
az ml online-endpoint delete --name tfserving-endpoint