Uso compartido de modelos, componentes y entornos entre áreas de trabajo con registros
El registro de Azure Machine Learning le permite colaborar entre áreas de trabajo dentro de su organización. Con los registros, puede compartir modelos, componentes y entornos.
Hay dos escenarios en los que querría usar el mismo conjunto de modelos, componentes y entornos en varias áreas de trabajo:
- MLOps entre áreas de trabajo: está entrenando un modelo en un área de trabajo
devy tiene que implementarla en las áreas de trabajotestyprod. En este caso, quiere tener linaje de un extremo a otro entre los puntos de conexión en los que se implementa el modelo en las áreas de trabajotestoprody el trabajo de entrenamiento, las métricas, el código, los datos y el entorno que se usó para entrenar el modelo en el área de trabajodev. - Compartir y reutilizar modelos y canalizaciones entre distintos equipos: El uso compartido y la reutilización mejoran la colaboración y la productividad. En este escenario, es posible que quiera publicar un modelo entrenado y los componentes y entornos asociados que se usan para entrenarlo en un catálogo central. A partir de allí, los colegas de otros equipos pueden buscar y reutilizar los recursos compartidos en sus propios experimentos.
En este artículo, aprenderá a:
- Crear un entorno y un componente en el registro.
- Usar el componente del registro para enviar un trabajo de entrenamiento de modelos en un área de trabajo.
- Registrar el modelo entrenado en el registro.
- Implementar el modelo desde el registro en un punto de conexión en línea en el área de trabajo y, a continuación, enviar una solicitud de inferencia.
Prerrequisitos
Antes de seguir los pasos de este artículo, asegúrese de que tiene los siguientes requisitos previos:
- Suscripción a Azure. Si no tiene una suscripción de Azure, cree una cuenta gratuita antes de empezar. Pruebe la versión gratuita o de pago de Azure Machine Learning.
Un registro de Azure Machine Learning para compartir modelos, componentes y entornos. Para crear un registro, consulte Información sobre cómo crear un registro.
Un área de trabajo de Azure Machine Learning. Si no tiene uno, siga los pasos descritos en el artículo Inicio rápido: Creación de recursos del área de trabajo para crear uno.
Importante
La región de Azure (ubicación) donde cree el área de trabajo debe estar en la lista de regiones admitidas para el registro de Azure Machine Learning.
La CLI de Azure y la extensión
mlo el SDK v2 de Python para Azure Machine Learning:Para instalar la CLI de Azure y la extensión, consulte Instalación, configuración y uso de la CLI (v2).
Importante
En los ejemplos de la CLI de este artículo se supone que usa el shell de Bash (o compatible). Por ejemplo, de un sistema Linux o Subsistema de Windows para Linux.
En los ejemplos también se supone que ha configurado los valores predeterminados de la CLI de Azure para que no tenga que especificar los parámetros de la suscripción, el área de trabajo, el grupo de recursos ni la ubicación. Para establecer la configuración predeterminada, use los siguientes comandos. Reemplace los parámetros siguientes por los valores de su configuración:
- Reemplace
<subscription>con la identificación de su suscripción de Azure. - Reemplace
<workspace>por el nombre del área de trabajo de Azure Machine Learning. - Reemplace
<resource-group>por el grupo de recursos de Azure que contiene el área de trabajo. - Reemplace
<location>por la región de Azure que contiene el área de trabajo.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Puede ver cuáles son los valores predeterminados actuales mediante el comando
az configure -l.- Reemplace
Clonación del repositorio de ejemplos
Los ejemplos de código de este artículo se basan en el la muestra nyc_taxi_data_regression del repositorio de ejemplos. Para usar estos archivos en el entorno de desarrollo, use los siguientes comandos para clonar el repositorio y cambiar los directorios en el ejemplo:
git clone https://github.com/Azure/azureml-examples
cd azureml-examples
En el ejemplo de la CLI, cambie los directorios a cli/jobs/pipelines-with-components/nyc_taxi_data_regression en el clon local del repositorio de ejemplos.
cd cli/jobs/pipelines-with-components/nyc_taxi_data_regression
Creación de una conexión de SDK
Sugerencia
Este paso solo es necesario cuando se usa el SDK de Python.
Cree una conexión de cliente tanto al área de trabajo de Azure Machine Learning como al registro:
ml_client_workspace = MLClient( credential=credential,
subscription_id = "<workspace-subscription>",
resource_group_name = "<workspace-resource-group",
workspace_name = "<workspace-name>")
print(ml_client_workspace)
ml_client_registry = MLClient(credential=credential,
registry_name="<REGISTRY_NAME>",
registry_location="<REGISTRY_REGION>")
print(ml_client_registry)
Creación de un entorno en el registro
Los entornos definen el contenedor de Docker y las dependencias de Python necesarios para ejecutar trabajos de entrenamiento o implementar modelos. Para obtener más información sobre los entornos, consulte los artículos siguientes:
Sugerencia
El mismo comando az ml environment create de la CLI se puede usar para crear entornos en un área de trabajo o registro. Al ejecutar el comando con --workspace-name se crea el entorno en un área de trabajo, mientras que al ejecutar el comando con --registry-name se crea el entorno en el registro.
Crearemos un entorno que use la imagen de Docker python:3.8 e instale los paquetes de Python necesarios para ejecutar un trabajo de entrenamiento mediante el marco Scikit Learn. Si ha clonado el repositorio de ejemplos y está en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression, debería poder ver el archivo de definición de entorno env_train.yml que hace referencia al archivo de Docker env_train/Dockerfile. A continuación se muestra env_train.yml para su referencia:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: SKLearnEnv
version: 1
build:
path: ./env_train
Cree el entorno con az ml environment create como se indica a continuación.
az ml environment create --file env_train.yml --registry-name <registry-name>
Si recibe un error de que ya existe un entorno con este nombre y versión en el registro, puede editar el campo version en env_train.yml o especificar otra versión en la CLI que invalide el valor de versión en env_train.yml.
# use shell epoch time as the version
version=$(date +%s)
az ml environment create --file env_train.yml --registry-name <registry-name> --set version=$version
Sugerencia
version=$(date +%s) solo funciona en Linux. Reemplace $version por un número aleatorio si no funciona.
Anote name y version del entorno de la salida del comando az ml environment create y úselos con los comandos az ml environment show como se indica a continuación. Necesitará name y version en la sección siguiente al crear un componente en el registro.
az ml environment show --name SKLearnEnv --version 1 --registry-name <registry-name>
Sugerencia
Si ha usado otro nombre o versión de entorno, reemplace los parámetros --name y --version en consecuencia.
También puede usar az ml environment list --registry-name <registry-name> para enumerar todos los entornos del registro.
Puede examinar todos los entornos de Estudio de Azure Machine Learning. Asegúrese de navegar a la interfaz de usuario global y busque la entrada Registros.

Creación de un componente en el registro
Los componentes son bloques de creación reutilizables de canalizaciones de Machine Learning en Azure Machine Learning. Puede empaquetar en un componente el código, el comando, el entorno, la interfaz de entrada y la interfaz de salida de un paso de canalización individual. Después, puede volver a usar el componente en varias canalizaciones sin tener que preocuparse de portar las dependencias y el código cada vez que escriba una canalización diferente.
La creación de un componente en un área de trabajo le permite usar el componente en cualquier trabajo de canalización dentro de esa área de trabajo. La creación de un componente en un registro le permite usar el componente en cualquier canalización de cualquier área de trabajo dentro de su organización. La creación de componentes en un registro es una excelente manera de crear utilidades modulares reutilizables o tareas de entrenamiento compartidas que pueden usarse para la experimentación de diferentes equipos dentro de su organización.
Para obtener más información sobre los componentes, consulte los siguientes artículos:
Uso de componentes en canalizaciones (SDK)
Importante
El Registro solo admite recursos con nombre (data/model/component/environment). Si hace referencia a un recurso en un registro, primero debe crearlo en el Registro. Especialmente para el caso de los componentes de canalización, si desea hacer referencia a un componente o entorno en el componente de canalización, primero debe crear el componente o el entorno en el Registro.
Asegúrese de que se encuentra en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression. Encontrará el archivo de definición de componentes train.yml que empaqueta un script de entrenamiento de Scikit Learn train_src/train.py y el entorno mantenidoAzureML-sklearn-0.24-ubuntu18.04-py37-cpu. Usaremos el entorno de Scikit Learn creado en un paso anterior, en lugar del entorno mantenido. Puede editar el campo environment en train.yml para que haga referencia al entorno de Scikit Learn. El archivo de definición de componente train.yml resultante será similar al ejemplo siguiente:
# <component>
$schema: https://azuremlschemas.azureedge.net/latest/commandComponent.schema.json
name: train_linear_regression_model
display_name: TrainLinearRegressionModel
version: 1
type: command
inputs:
training_data:
type: uri_folder
test_split_ratio:
type: number
min: 0
max: 1
default: 0.2
outputs:
model_output:
type: mlflow_model
test_data:
type: uri_folder
code: ./train_src
environment: azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1`
command: >-
python train.py
--training_data ${{inputs.training_data}}
--test_data ${{outputs.test_data}}
--model_output ${{outputs.model_output}}
--test_split_ratio ${{inputs.test_split_ratio}}
Si ha usado un nombre o versión diferentes, la representación más genérica tiene este aspecto: environment: azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>, así que asegúrese de reemplazar <registry-name>, <sklearn-environment-name> y <sklearn-environment-version> en consecuencia. A continuación, ejecute el comando az ml component create para crear el componente como se indica a continuación.
az ml component create --file train.yml --registry-name <registry-name>
Sugerencia
El mismo comando az ml component create de la CLI se puede usar para crear componentes en un área de trabajo o registro. Al ejecutar el comando con --workspace-name se crea el componente en un área de trabajo, mientras que al ejecutar el comando con --registry-name se crea el componente en el registro.
Si prefiere no editar train.yml, puede invalidar el nombre del entorno en la CLI de la siguiente manera:
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/SKLearnEnv/versions/1
# or if you used a different name or version, replace `<sklearn-environment-name>` and `<sklearn-environment-version>` accordingly
az ml component create --file train.yml --registry-name <registry-name>` --set environment=azureml://registries/<registry-name>/environments/<sklearn-environment-name>/versions/<sklearn-environment-version>
Sugerencia
Si recibe un error que indica que el nombre del componente ya existe en el registro, puede editar la versión en train.yml o invalidar la versión en la CLI con una versión aleatoria.
Anote name y version del componente de la salida del comando az ml component create y úselos con los comandos az ml component show como se indica a continuación. Necesitará name y version en la sección siguiente al crear un trabajo de entrenamiento en el área de trabajo.
az ml component show --name <component_name> --version <component_version> --registry-name <registry-name>
También puede usar az ml component list --registry-name <registry-name> para enumerar todos los componentes del registro.
Puede examinar todos los componentes de Estudio de Azure Machine Learning. Asegúrese de navegar a la interfaz de usuario global y busque la entrada Registros.

Ejecución de un trabajo de canalización en un área de trabajo mediante el componente del registro
Al ejecutar un trabajo de canalización que usa un componente de un registro, los recursos de proceso y los datos de entrenamiento son locales para el área de trabajo. Para obtener más información sobre la ejecución de trabajos, consulte los siguientes artículos:
- Ejecución de trabajos (CLI)
- Ejecución de trabajos (SDK)
- Trabajos de canalización con componentes (CLI)
- Trabajos de canalización con componentes (SDK)
Ejecutaremos un trabajo de canalización con el componente de entrenamiento de Scikit Learn creado en la sección anterior para entrenar un modelo. Compruebe que se encuentra en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression. El conjunto de datos de entrenamiento se encuentra en la carpeta data_transformed. Edite la sección component en la sección train_job del archivo single-job-pipeline.yml para que haga referencia al componente de entrenamiento creado en la sección anterior. A continuación se muestra el archivo single-job-pipeline.yml resultante.
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: nyc_taxi_data_regression_single_job
description: Single job pipeline to train regression model based on nyc taxi dataset
jobs:
train_job:
type: command
component: azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
compute: azureml:cpu-cluster
inputs:
training_data:
type: uri_folder
path: ./data_transformed
outputs:
model_output:
type: mlflow_model
test_data:
El aspecto clave es que esta canalización se va a ejecutar en un área de trabajo mediante un componente que no está en el área de trabajo específica. El componente está en un registro que se puede usar con cualquier área de trabajo de la organización. Puede ejecutar este trabajo de entrenamiento en cualquier área de trabajo a la que tenga acceso sin tener que preocuparse de que el código de entrenamiento y el entorno estén disponibles en esa área de trabajo.
Advertencia
- Antes de ejecutar el trabajo de canalización, confirme que el área de trabajo en la que ejecutará el trabajo se encuentra en una región de Azure admitida por el registro en el que creó el componente.
- Confirme que el área de trabajo tiene un clúster de proceso con el nombre
cpu-clustero edite el campocomputeenjobs.train_job.computecon el nombre del proceso.
Ejecute el trabajo de canalización con el comando az ml job create.
az ml job create --file single-job-pipeline.yml
Sugerencia
Si no ha configurado el área de trabajo y el grupo de recursos predeterminados, como se explica en la sección de requisitos previos, tendrá que especificar los parámetros --workspace-name y --resource-group para que az ml job create funcione.
Como alternativa, puede omitir la edición de single-job-pipeline.yml e invalidar el nombre del componente usado por train_job en la CLI.
az ml job create --file single-job-pipeline.yml --set jobs.train_job.component=azureml://registries/<registry-name>/component/train_linear_regression_model/versions/1
Dado que el componente usado en el trabajo de entrenamiento se comparte a través de un registro, puede enviar el trabajo a cualquier área de trabajo a la que tenga acceso en su organización, incluso en distintas suscripciones. Por ejemplo, si tiene dev-workspace, test-workspace y prod-workspace, ejecutar el trabajo de entrenamiento en estas tres áreas de trabajo es tan fácil como ejecutar tres comandos az ml job create.
az ml job create --file single-job-pipeline.yml --workspace-name dev-workspace --resource-group <resource-group-of-dev-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name test-workspace --resource-group <resource-group-of-test-workspace>
az ml job create --file single-job-pipeline.yml --workspace-name prod-workspace --resource-group <resource-group-of-prod-workspace>
En Estudio de Azure Machine Learning, seleccione el vínculo del punto de conexión en la salida del trabajo para ver el trabajo. Aquí puede analizar las métricas de entrenamiento, comprobar que el trabajo usa el componente y el entorno del registro y revisar el modelo entrenado. Anote name del trabajo de la salida o busque la misma información en la información general del trabajo en Estudio de Azure Machine Learning. Necesitará esta información para descargar el modelo entrenado en la sección siguiente sobre la creación de modelos en el registro.

Creación de un modelo en el registro
En esta sección, aprenderá a crear modelos en un registro. Consulte Administración de modelos para obtener más información sobre la administración de modelos en Azure Machine Learning. Veremos dos maneras diferentes de crear un modelo en un registro. La primera es a partir de archivos locales. La segunda es copiar en un registro un modelo registrado en el área de trabajo.
En ambas opciones, creará el modelo con el formato de MLflow, que le ayudará a implementar este modelo para la inferencia sin escribir ningún código de inferencia.
Creación de un modelo en el registro a partir de archivos locales
Descargue el modelo, que está disponible como salida de train_job ; para ello, reemplace <job-name> por el nombre del trabajo de la sección anterior. El modelo, junto con los archivos de metadatos de MLflow, debe estar disponible en ./artifacts/model/.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --query [0].name | sed 's/\"//g')
# download the default outputs of the train_job
az ml job download --name $train_job_name
# review the model files
ls -l ./artifacts/model/
Sugerencia
Si no ha configurado el área de trabajo y el grupo de recursos predeterminados, como se explica en la sección de requisitos previos, tendrá que especificar los parámetros --workspace-name y --resource-group para que az ml model create funcione.
Advertencia
La salida de az ml job list se pasa a sed. Esto solo funciona en shells de Linux. Si está en Windows, ejecute az ml job list --parent-job-name <job-name> --query [0].name y quite las comillas que vea en el nombre del trabajo de entrenamiento.
Si no puede descargar el modelo, puede encontrar el modelo de MLflow de ejemplo entrenado por el trabajo de entrenamiento en la sección anterior en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression/artifacts/model/.
Cree el modelo en el registro:
# create model in registry
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path ./artifacts/model/ --registry-name <registry-name>
Sugerencia
- Use un número aleatorio para el parámetro
versionsi recibe un error que indica que el nombre y la versión del modelo ya existen. - El mismo comando
az ml model createde la CLI se puede usar para crear modelos en un área de trabajo o registro. Al ejecutar el comando con--workspace-namese crea el modelo en un área de trabajo, mientras que al ejecutar el comando con--registry-namese crea el modelo en el registro.
Compartir un modelo del área de trabajo al registro
En este flujo de trabajo, primero creará el modelo en el área de trabajo y, a continuación, lo compartirá con el registro. Este flujo de trabajo es útil cuando desea probar el modelo en el área de trabajo antes de compartirlo. Por ejemplo, impleméntelo en puntos de conexión, pruebe la inferencia con algunos datos de prueba y, luego, copie el modelo en un registro si todo parece estar correcto. Este flujo de trabajo también puede ser útil cuando desarrolla una serie de modelos mediante diferentes técnicas, marcos o parámetros, y desea promover solo uno de ellos al registro como candidato de producción.
Asegúrese de que tiene el nombre del trabajo de canalización de la sección anterior y reemplácelo en el comando para capturar el nombre del trabajo de entrenamiento a continuación. Luego registrará el modelo de la salida del trabajo de entrenamiento en el área de trabajo. Observe cómo el parámetro --path hace referencia a la salida train_job con la sintaxis azureml://jobs/$train_job_name/outputs/artifacts/paths/model.
# fetch the name of the train_job by listing all child jobs of the pipeline job
train_job_name=$(az ml job list --parent-job-name <job-name> --workspace-name <workspace-name> --resource-group <workspace-resource-group> --query [0].name | sed 's/\"//g')
# create model in workspace
az ml model create --name nyc-taxi-model --version 1 --type mlflow_model --path azureml://jobs/$train_job_name/outputs/artifacts/paths/model
Sugerencia
- Use un número aleatorio para el parámetro
versionsi recibe un error que indica que el nombre y la versión del modelo ya existen. - Si no ha configurado el área de trabajo y el grupo de recursos predeterminados, como se explica en la sección de requisitos previos, tendrá que especificar los parámetros
--workspace-namey--resource-grouppara queaz ml model createfuncione.
Anote el nombre y la versión del modelo. Para validar si el modelo está registrado en el área de trabajo, puede examinarlo en la interfaz de usuario de Studio o mediante el comando az ml model show --name nyc-taxi-model --version $model_version.
Ahora compartirá el modelo del área de trabajo con el registro.
# share model registered in workspace to registry
az ml model share --name nyc-taxi-model --version 1 --registry-name <registry-name> --share-with-name <new-name> --share-with-version <new-version>
Sugerencia
- Asegúrese de usar el nombre y la versión correctos del modelo si lo cambió en el comando
az ml model create. - El comando anterior tiene dos parámetros opcionales "--share-with-name" y "--share-with-version". Si no se proporcionan, el nuevo modelo tendrá el mismo nombre y versión que el modelo que se comparte.
Anote
nameyversiondel modelo de la salida del comandoaz ml model createy úselos con los comandosaz ml model showcomo se indica a continuación. Necesitaránameyversionen la sección siguiente al implementar el modelo en un punto de conexión en línea para la inferencia.
az ml model show --name <model_name> --version <model_version> --registry-name <registry-name>
También puede usar az ml model list --registry-name <registry-name> para enumerar todos los modelos del registro o examinar todos los componentes de la interfaz de usuario de Estudio de Azure Machine Learning. Asegúrese de navegar a la interfaz de usuario global y busque el centro Registros.
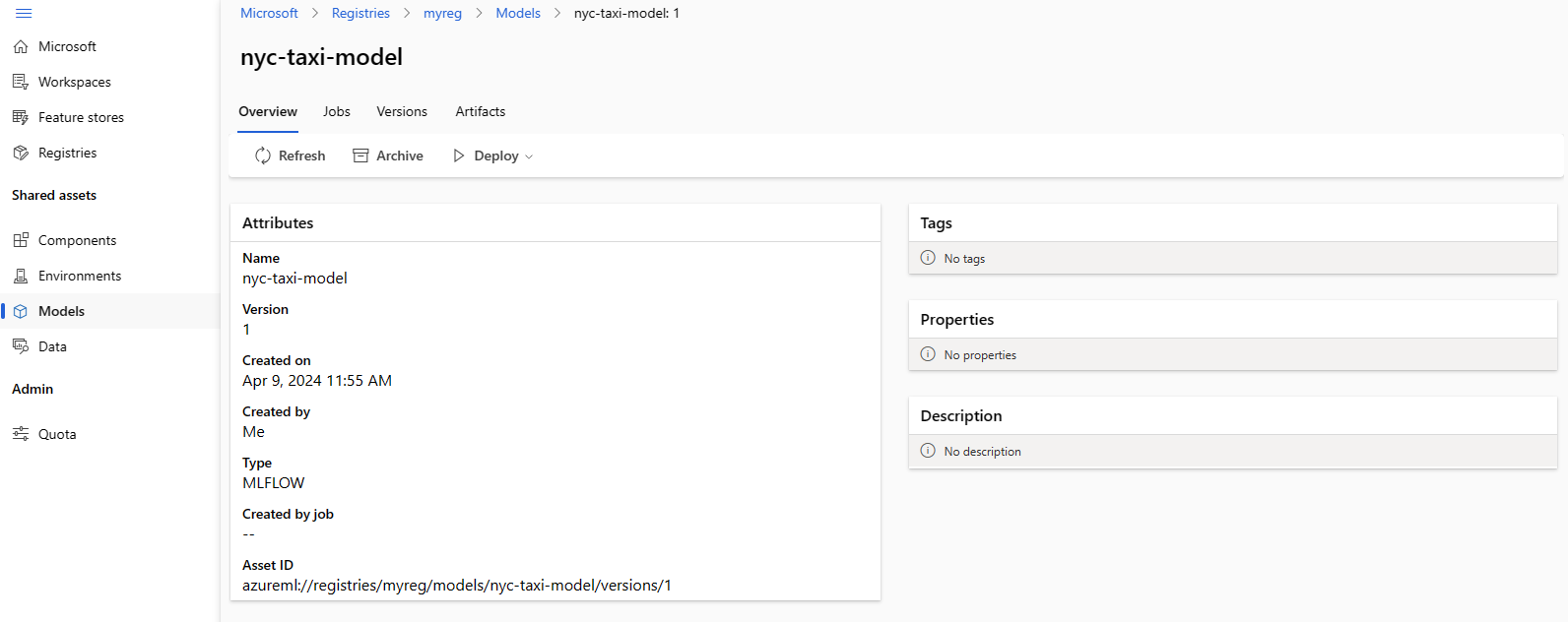
En la captura de pantalla siguiente se muestra un modelo en un registro en Estudio de Azure Machine Learning. Si creó un modelo a partir de la salida del trabajo y después copió el modelo del área de trabajo al registro, verá que el modelo tiene un vínculo al trabajo que entrenó el modelo. Puede usar ese vínculo para navegar al trabajo de entrenamiento para revisar el código, el entorno y los datos usados para entrenar el modelo.
Implementación del modelo del registro al punto de conexión en línea en el área de trabajo
En la última sección, implementará un modelo del registro en un punto de conexión en línea en un área de trabajo. Puede optar por implementar cualquier área de trabajo a la que tenga acceso en su organización, siempre que la ubicación del área de trabajo sea una de las ubicaciones admitidas por el registro. Esta funcionalidad es útil si ha entrenado un modelo en un área de trabajo dev y ahora tiene que implementar el modelo en el área de trabajo test o prod, a la vez que conserva la información de linaje en relación con el código, el entorno y los datos usados para entrenar el modelo.
Los puntos de conexión en línea permiten implementar modelos y enviar solicitudes de inferencia a través de las API de REST. Para más información, consulte Implementación y puntuación de un modelo de Machine Learning mediante un punto de conexión en línea.
Cree un punto de conexión en línea.
az ml online-endpoint create --name reg-ep-1234
Actualice la línea model: de deploy.yml disponible en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression para que haga referencia al nombre y la versión del modelo desde el paso anterior. Cree una implementación en línea en el punto de conexión en línea. A continuación se muestra el archivo deploy.yml para referencia.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: demo
endpoint_name: reg-ep-1234
model: azureml://registries/<registry-name>/models/nyc-taxi-model/versions/1
instance_type: Standard_DS2_v2
instance_count: 1
Cree la implementación en línea. La implementación tarda varios minutos en completarse.
az ml online-deployment create --file deploy.yml --all-traffic
Capture el URI de puntuación y envíe una solicitud de puntuación de ejemplo. Los datos de ejemplo de la solicitud de puntuación están disponibles en scoring-data.json en la carpeta cli/jobs/pipelines-with-components/nyc_taxi_data_regression.
ENDPOINT_KEY=$(az ml online-endpoint get-credentials -n reg-ep-1234 -o tsv --query primaryKey)
SCORING_URI=$(az ml online-endpoint show -n reg-ep-1234 -o tsv --query scoring_uri)
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --data @./scoring-data.json
Sugerencia
- El comando
curlsolo funciona en Linux. - Si no ha configurado el área de trabajo y el grupo de recursos predeterminados, como se explica en la sección de requisitos previos, tendrá que especificar los parámetros
--workspace-namey--resource-grouppara que los comandosaz ml online-endpointyaz ml online-deploymentfuncionen.
Limpieza de recursos
Si no va a usar la implementación, debe eliminarla para reducir costos. En el ejemplo siguiente se elimina el punto de conexión y todas las implementaciones subyacentes:
az ml online-endpoint delete --name reg-ep-1234 --yes --no-wait