Integración del flujo de avisos con DevOps de aplicaciones basadas en LLM
En este artículo, aprenderá sobre la integración de flujos de avisos con DevOps de aplicaciones basadas en LLM en Azure Machine Learning. El Flujo de avisos ofrece una experiencia de código primero fácil de usar y de uso sencillo para el desarrollo de flujos y la iteración con todo su flujo de trabajo de desarrollo de aplicaciones basado en LLM.
Proporciona un SDK y una CLI de flujos de avisos, una extensión de código VS y la nueva interfaz de usuario del explorador de carpetas de flujos para facilitar el desarrollo local de flujos, la activación local de ejecuciones de flujos y ejecuciones de evaluación, y la transición de flujos de entornos locales a entornos en la nube (área de trabajo de Azure Machine Learning).
Esta documentación se centra en cómo combinar eficazmente las funcionalidades de la experiencia de código de flujo de avisos y DevOps para mejorar sus flujos de trabajo de desarrollo de aplicaciones basados en LLM.

Introducción de la experiencia "code-first" en flujo de avisos
Cuando se desarrollan aplicaciones utilizando LLM, es común tener un proceso de ingeniería de aplicaciones estandarizado que incluye repositorios de código y canalizaciones CI/CD. Esta integración permite agilizar el proceso de desarrollo, el control de versiones y la colaboración entre los miembros del equipo.
Para los desarrolladores con experiencia en el desarrollo de código que buscan un proceso de iteración LLMOps más eficiente, las siguientes características clave y los beneficios que puede obtener de la experiencia de código de flujo de avisos:
- Flujo de versiones en el repositorio de código. Puede definir su flujo en formato YAML, que puede permanecer alineado con los archivos de origen referenciados en una estructura de carpetas.
- Integración de la ejecución del flujo con la canalización CI/CD. Puede desencadenar ejecuciones de flujo utilizando la CLI o el SDK de flujo de avisos, que pueden integrarse perfectamente en su proceso de entrega y canalización de CI/CD.
- Transición sin problemas de lo local a la nube. Puede exportar fácilmente su carpeta de flujo a su repositorio local o de código para el control de versiones, el desarrollo local y el uso compartido. Del mismo modo, la carpeta de flujo se puede importar sin esfuerzo a la nube para su posterior creación, prueba e implementación en los recursos de la nube.
Acceso a la definición del código de flujo de avisos
A cada flujo se asocia una estructura de carpetas de flujo que contiene los archivos esenciales para definir el flujo en la estructura de carpetasde código. Esta estructura de carpetas organiza su flujo, facilitando transiciones más fluidas.
Azure Machine Learning ofrece un sistema de archivos compartido para todos los usuarios del área de trabajo. Al crear un flujo, se genera automáticamente una carpeta de flujo correspondiente, que se almacena en el directorio Users/<username>/promptflow.

Estructura de carpetas de flujo
Información general sobre la estructura de la carpeta de flujo y los archivos clave que contiene:
- flow.dag.yaml: este archivo primario de definición del flujo, en formato YAML, incluye información sobre entradas, salidas, nodos, herramientas y variantes utilizadas en el flujo. Es integral para la creación y la definición del flujo de avisos.
- Archivos de código fuente (.py, .jinja2): la carpeta del flujo también incluye archivos de código fuente administrados por el usuario, a los que hacen referencia las herramientas/nodos del flujo.
- Los archivos en formato Python (.py) pueden ser referenciados por la herramienta python para definir una lógica python personalizada.
- La herramienta de avisos o la herramienta LLM pueden referenciar a los archivos en formato Jinja 2 (.jinja2) para definir el contexto del aviso.
- Archivos que no son de origen: la carpeta de flujo también puede contener archivos que no sean de origen, como archivos de utilidades y archivos de datos que pueden incluirse en los archivos de origen.
Una vez creado el flujo, puede navegar a la página de creación de flujos para ver y manejar los archivos de flujo en el explorador de archivos correcto. Esto le permite ver, editar y administrar sus archivos. Cualquier modificación realizada en los archivos se refleja directamente en el recurso compartido de archivos.

Con el "Modo de archivos sin procesar" activado, puede ver y editar el contenido sin procesar de los archivos en el editor de archivos, incluido el archivo de definición de flujo y los archivos flow.dag.yaml de origen.


De forma alternativa, puede acceder a todas las carpetas de flujo directamente dentro del bloc de notas de Azure Machine Learning.

Flujo de avisos de versiones en el repositorio
Para registrar su flujo en su repositorio de código, puede exportar fácilmente la carpeta del flujo desde la página de creación del flujo a su sistema local. Esto descarga un paquete que contiene todos los archivos del explorador a su equipo local, que luego puede insertar en su repositorio de código.

Para obtener más información sobre la integración de DevOps con Azure Machine Learning, consulte Integración de Git en Azure Machine Learning
Envío de ejecuciones a la nube desde el repositorio local
Requisitos previos
Completa la Creación de recursos para empezar si aún no tienes un área de trabajo de Azure Machine Learning.
Un entorno Python en el que haya instalado Azure Machine Learning Python SDK v2: instrucciones de instalación. Este entorno es para definir y controlar los recursos de Azure Machine Learning y es independiente del entorno que se usa en tiempo de ejecución. Para más información, vea cómo administrar el runtime para la ingeniería de flujo de avisos.
Instalar el SDK de flujo de avisos
pip install -r ../../examples/requirements.txt
Conexión al área de trabajo de Azure Machine Learning
az login
Prepare para run.yml definir la configuración para este flujo se ejecutan en la nube.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
column_mapping:
url: ${data.url}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specify automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
Puede especificar la conexión y el nombre de implementación para cada herramienta del flujo. Si no especifica el nombre de la conexión y la implementación, utiliza la única conexión e implementación del archivo flow.dag.yaml. Para el formato de las conexiones:
...
connections:
<node_name>:
connection: <connection_name>
deployment_name: <deployment_name>
...
pfazure run create --file run.yml
Prepare run_evaluation.yml para definir la configuración de este flujo de evaluación ejecutado en la nube.
$schema: https://azuremlschemas.azureedge.net/promptflow/latest/Run.schema.json
flow: <path_to_flow>
data: <path_to_flow>/data.jsonl
run: <id of web-classification flow run>
column_mapping:
groundtruth: ${data.answer}
prediction: ${run.outputs.category}
# define cloud resource
# if omitted, it will use the automatic runtime, you can also specify the runtime name, specif automatic will also use the automatic runtime.
runtime: <runtime_name>
# define instance type only work for automatic runtime, will be ignored if you specify the runtime name.
# resources:
# instance_type: <instance_type>
# overrides connections
connections:
classify_with_llm:
connection: <connection_name>
deployment_name: <deployment_name>
summarize_text_content:
connection: <connection_name>
deployment_name: <deployment_name>
pfazure run create --file run_evaluation.yml
Ver los resultados de la ejecución en el área de trabajo de Azure Machine Learning
Enviar ejecución de flujo a la nube devolverá la URL del portal de la ejecución. Puede abrir la URL para ver los resultados de la ejecución en el portal.
También puede utilizar el siguiente comando para ver los resultados de las ejecuciones.
Transmisión de los registros
pfazure run stream --name <run_name>
Ver resultados de la ejecución
pfazure run show-details --name <run_name>
Ver las métricas del proceso de evaluación
pfazure run show-metrics --name <evaluation_run_name>
Importante
Para más información, puede consultar la documentación de la CLI de flujo de avisos para Azure.
Desarrollo iterativo a partir del ajuste de precisión
Desarrollo y pruebas locales
Durante el desarrollo iterativo, a medida que perfecciona y ajusta el flujo o las indicaciones, puede resultarle beneficioso llevar a cabo múltiples iteraciones localmente dentro de su repositorio de código. La versión comunitaria, la extensión Flujo de avisos de VS Code y SDK local y CLI de flujo de avisos se proporcionan para facilitar el desarrollo y las pruebas puramente locales sin vinculación a Azure.
Extensión Flujo de avisos VS Code
Con la extensión Flujo de avisos de VS Code instalada, puede crear fácilmente el flujo localmente desde el editor de VS Code, lo que proporciona una experiencia de interfaz de usuario similar a la de la nube.
Para usar la extensión:
- Abra una carpeta de flujo de avisos en VS Code Desktop.
- Abra el archivo ``flow.dag.yaml`` en la vista de bloc de notas.
- Utilice el editor visual para realizar los cambios necesarios en su flujo, como ajustar las indicaciones en las variantes o agregar más herramientas.
- Para probar su flujo, seleccione el botón Ejecutar flujo en la parte superior del editor visual. Esto desencadena una prueba de flujo.

SDK de Flujo de avisos local y CLI
Si prefiere utilizar Jupyter, PyCharm, Visual Studio u otros IDE, puede modificar directamente la definición YAML del archivo flow.dag.yaml.

Después, puede desencadenar una ejecución única del flujo para realizar pruebas con la CLI o el SDK de flujo de avisos.
Suponiendo que está en el directorio de trabajo <path-to-the-sample-repo>/examples/flows/standard/
pf flow test --flow web-classification # "web-classification" is the directory name


Esto le permite realizar y probar cambios rápidamente, sin necesidad de actualizar cada vez el repositorio principal de código. Una vez que esté satisfecho con los resultados de sus pruebas locales, puede transferir las ejecuciones de envío a la nube desde el repositorio local para realizar ejecuciones de experimentos en la nube.
Para obtener más detalles e instrucciones sobre el uso de las versiones locales, puede consultar la comunidad GitHub de flujo de avisos.
Volver a la interfaz de usuario del estudio para el desarrollo continuo
Como alternativa, tiene la opción de volver a la interfaz de usuario del estudio, utilizando los recursos y la experiencia de la nube para realizar cambios en su flujo en la página de creación de flujos.
Para seguir desarrollando y trabajando con la versión más actualizada de los archivos de flujo, puede acceder al terminal del bloc de notas y extraer los últimos cambios de los archivos de flujo de su repositorio.
Además, si prefiere seguir trabajando en la interfaz de usuario del estudio, puede importar directamente una carpeta de flujo local como un nuevo borrador de flujo. Esto permite una transición fluida entre el desarrollo local y en la nube.

Integración de CI/CD
CI: El flujo de activación se ejecuta en la canalización de CI
Una vez que haya desarrollado y probado con éxito su flujo, y lo haya registrado como versión inicial, estará listo para la siguiente iteración de ajuste y prueba. En esta fase, puede desencadenar ejecuciones de flujo, incluidas las pruebas por lotes y las ejecuciones de evaluación, mediante la CLI de flujo de avisos. Esto podría servir como un flujo de trabajo automatizado en su canalización de Integración continua (CI).
A lo largo del ciclo de vida de sus iteraciones de flujo, se pueden automatizar varias operaciones:
- Ejecución del flujo de avisos después de una solicitud de cambios
- Ejecución de la evaluación del flujo de solicitud para asegurarse de que los resultados son de alta calidad
- Registro de modelos de flujo de solicitud
- Implementación de modelos de flujo de solicitud
Para obtener una guía completa sobre una canalización de MLOps de un extremo a otro que ejecuta un flujo de clasificación web, vea Configuración de LLMOps de un extremo a otro con Flujo de avisos y GitHub, y el proyecto de demostración de GitHub.
CD: Implementación continua
El último paso para ir a la producción es implementar el flujo como un punto de conexión en línea en Azure Machine Learning. Esto le permite integrar su flujo en su aplicación y hacer que esté disponible para su uso.
Para obtener más información sobre cómo implementar el flujo, consulte Implementación de flujos en el punto de conexión en línea administrado de Azure Machine Learning para la inferencia en tiempo real con CLI y SDK.
Colaboración en el desarrollo de flujos en producción
En el contexto del desarrollo de una aplicación basada en LLM con flujo de avisos, la colaboración entre los miembros del equipo suele ser esencial. Los miembros del equipo pueden participar en la misma creación y prueba de flujo, trabajando en diversas facetas del flujo o realizando cambios iterativos y mejoras simultáneamente.
Esta colaboración requiere un enfoque eficaz y simplificado para compartir código, realizar el seguimiento de modificaciones, administrar versiones e integrar estos cambios en el proyecto final.
La introducción del SDK o la CLI del flujo de avisos y la extensión de Visual Studio Code como parte de la experiencia de código de flujo de avisos facilita la colaboración sencilla en el desarrollo de flujos dentro del repositorio de código. Es aconsejable usar un repositorio de código basado en la nube, como GitHub o Azure DevOps, para realizar el seguimiento de los cambios, administrar versiones e integrar estas modificaciones en el proyecto final.
Procedimiento recomendado para el desarrollo colaborativo
Creación y prueba única del flujo localmente: repositorio de código y extensión de VSC
- El primer paso de este proceso de colaboración implica el uso de un repositorio de código como base para el código del proyecto, que incluye el código de flujo de avisos.
- Este repositorio centralizado permite una organización eficaz, el seguimiento de todos los cambios de código y la colaboración entre los miembros del equipo.
- Una vez configurado el repositorio, los miembros del equipo pueden usar la extensión de VSC para la creación local y las pruebas de entrada únicas del flujo.
- Este entorno de desarrollo integrado estandarizado fomenta la colaboración entre varios miembros que trabajan en distintos aspectos del flujo.

- Este entorno de desarrollo integrado estandarizado fomenta la colaboración entre varios miembros que trabajan en distintos aspectos del flujo.
- El primer paso de este proceso de colaboración implica el uso de un repositorio de código como base para el código del proyecto, que incluye el código de flujo de avisos.
Evaluación y pruebas por lotes experimentales basadas en la nube: CLI o SDK del flujo de avisos e interfaz de usuario del portal del área de trabajo
- Después de la fase de desarrollo y pruebas local, los desarrolladores de flujos pueden usar la CLI de pfazure o el SDK para enviar ejecuciones por lotes y ejecuciones de evaluación desde los archivos de flujo local a la nube.
- Esta acción proporciona una manera de consumir recursos en la nube, los resultados se almacenan de forma persistente y administrada de forma eficaz con una interfaz de usuario del portal en el área de trabajo de Azure Machine Learning. +Este paso permite el consumo de recursos en la nube, incluidos el proceso y el almacenamiento y el punto de conexión adicional para las implementaciones.
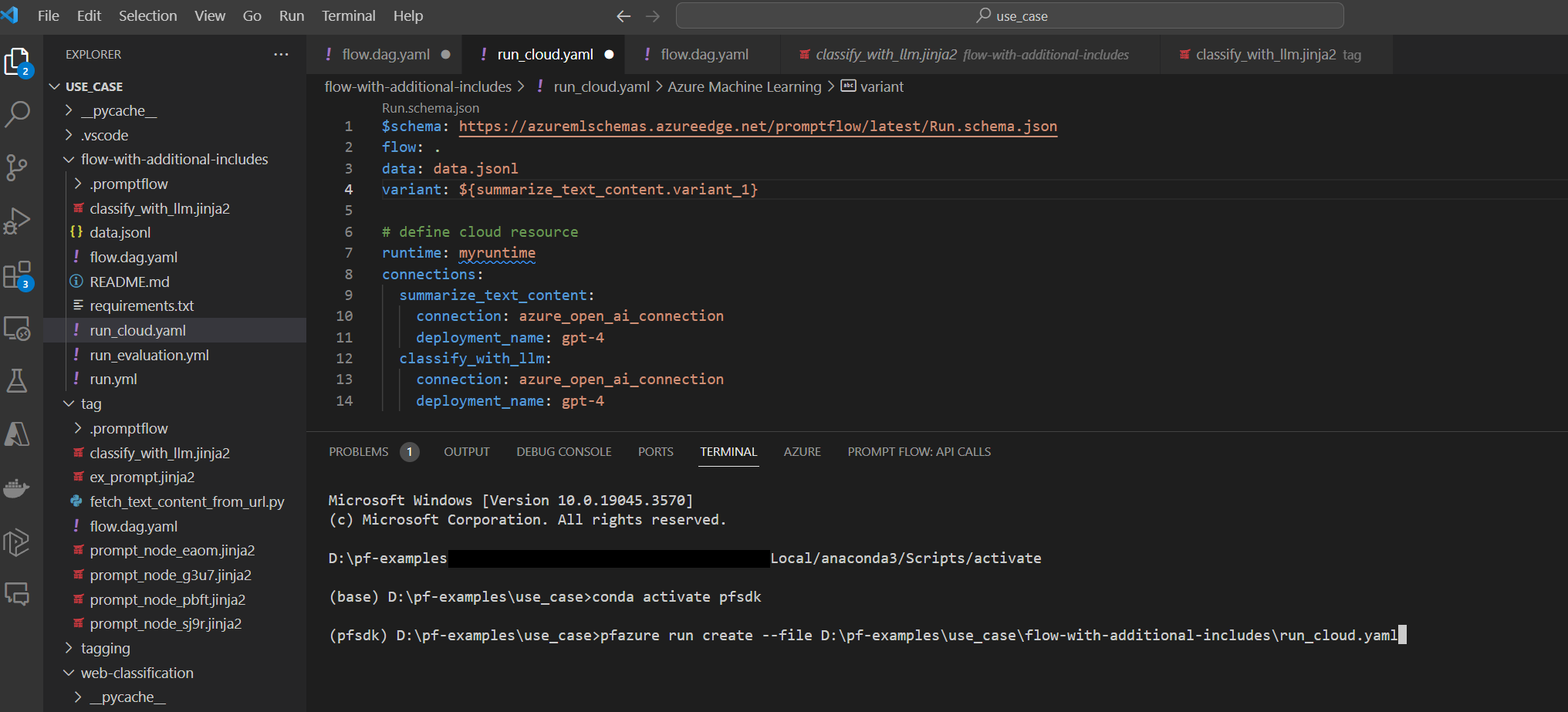
- Esta acción proporciona una manera de consumir recursos en la nube, los resultados se almacenan de forma persistente y administrada de forma eficaz con una interfaz de usuario del portal en el área de trabajo de Azure Machine Learning. +Este paso permite el consumo de recursos en la nube, incluidos el proceso y el almacenamiento y el punto de conexión adicional para las implementaciones.
- Después de enviar envíos a la nube, los miembros del equipo pueden acceder a la interfaz de usuario de Cloud Portal para ver los resultados y administrar los experimentos de forma eficaz.
- Este área de trabajo en la nube proporciona una ubicación centralizada para recopilar y administrar todo el historial de ejecuciones, los registros, las instantáneas, los resultados completos, incluidas las entradas y salidas del nivel de instancia.
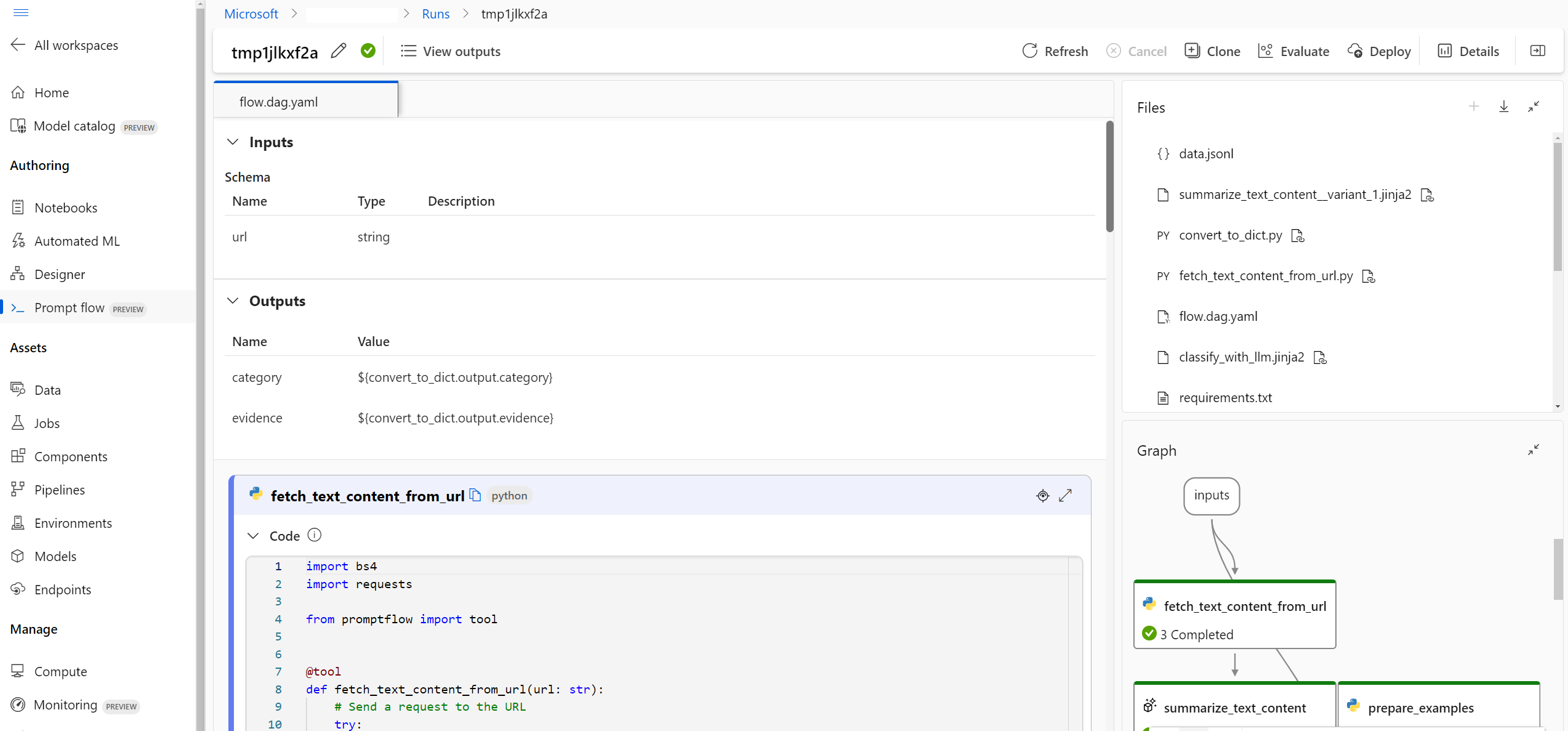
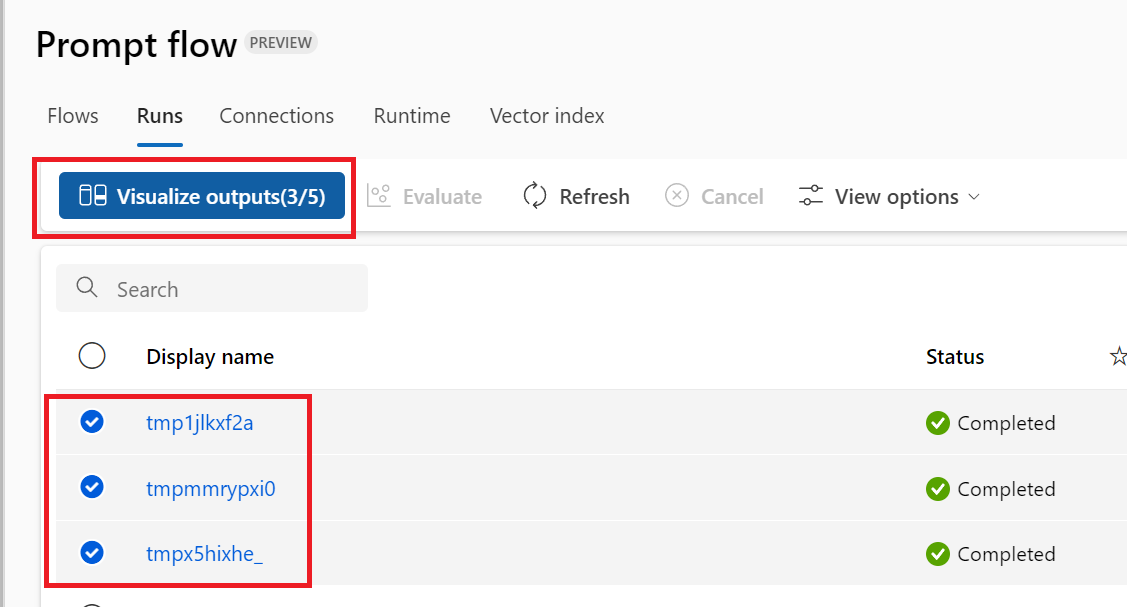
- En la lista de ejecución que registra todo el historial de ejecuciones de durante el desarrollo, los miembros del equipo pueden comparar fácilmente los resultados de diferentes ejecuciones, lo que ayuda en el análisis de calidad y los ajustes necesarios.

- Este área de trabajo en la nube proporciona una ubicación centralizada para recopilar y administrar todo el historial de ejecuciones, los registros, las instantáneas, los resultados completos, incluidas las entradas y salidas del nivel de instancia.
- Después de la fase de desarrollo y pruebas local, los desarrolladores de flujos pueden usar la CLI de pfazure o el SDK para enviar ejecuciones por lotes y ejecuciones de evaluación desde los archivos de flujo local a la nube.
Desarrollo iterativo local o implementación de interfaz de usuario de un solo paso para producción
- Después del análisis de experimentos, los miembros del equipo pueden volver al repositorio de código para otro desarrollo y ajuste preciso. Después, las ejecuciones posteriores se pueden enviar a la nube de forma iterativa.
- Este enfoque iterativo garantiza una mejora coherente hasta que el equipo esté satisfecho con la calidad lista para producción.
- Una vez que el equipo está totalmente seguro de la calidad del flujo, se puede implementar sin problemas a través de un asistente de interfaz de usuario como punto de conexión en línea en Azure Machine Learning. Una vez que el equipo está completamente seguro de la calidad del flujo, se puede pasar sin problemas a producción a través de un asistente de implementación de la interfaz de usuario como punto de conexión en línea en un entorno de nube sólido.
- Esta implementación en un punto de conexión en línea se puede basar en una instantánea de ejecución, lo que permite ofrecer servicios estables y seguros, realizar un seguimiento adicional del uso y la asignación de recursos y realizar la supervisión de registros en la nube.
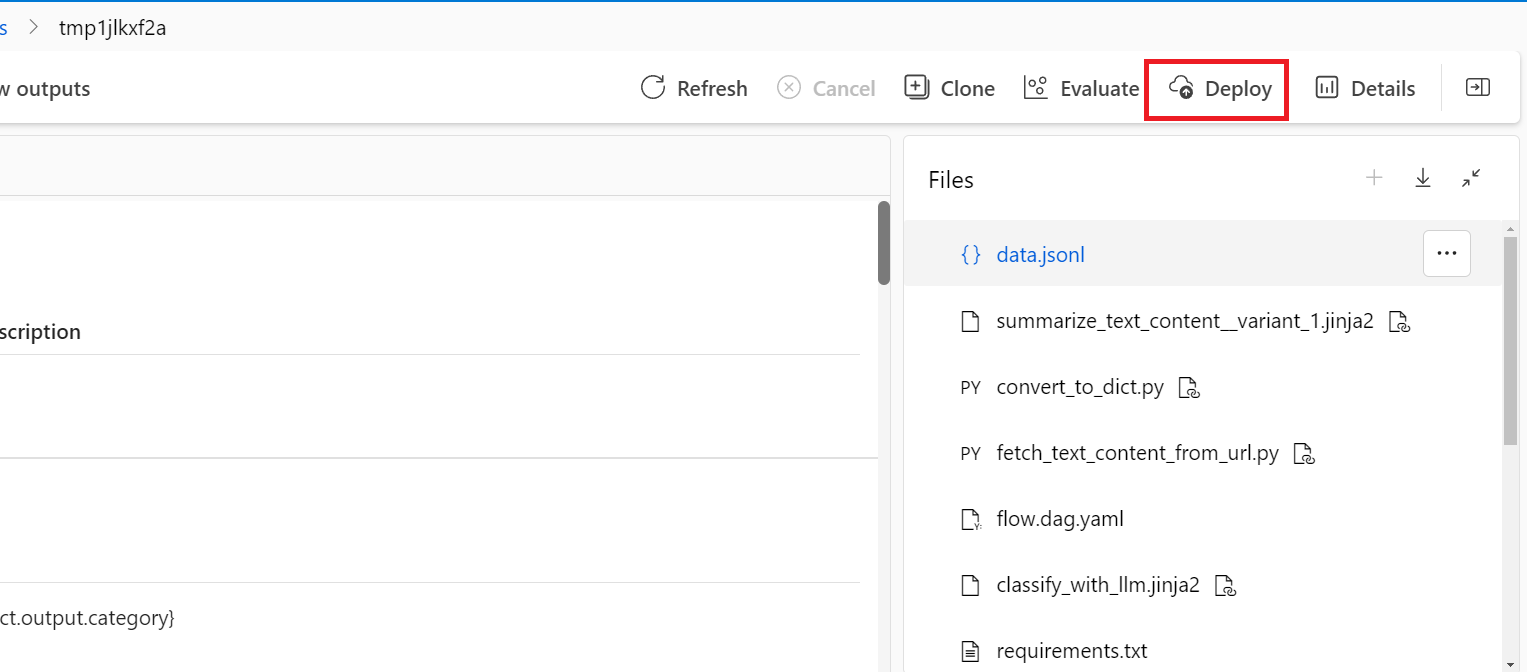
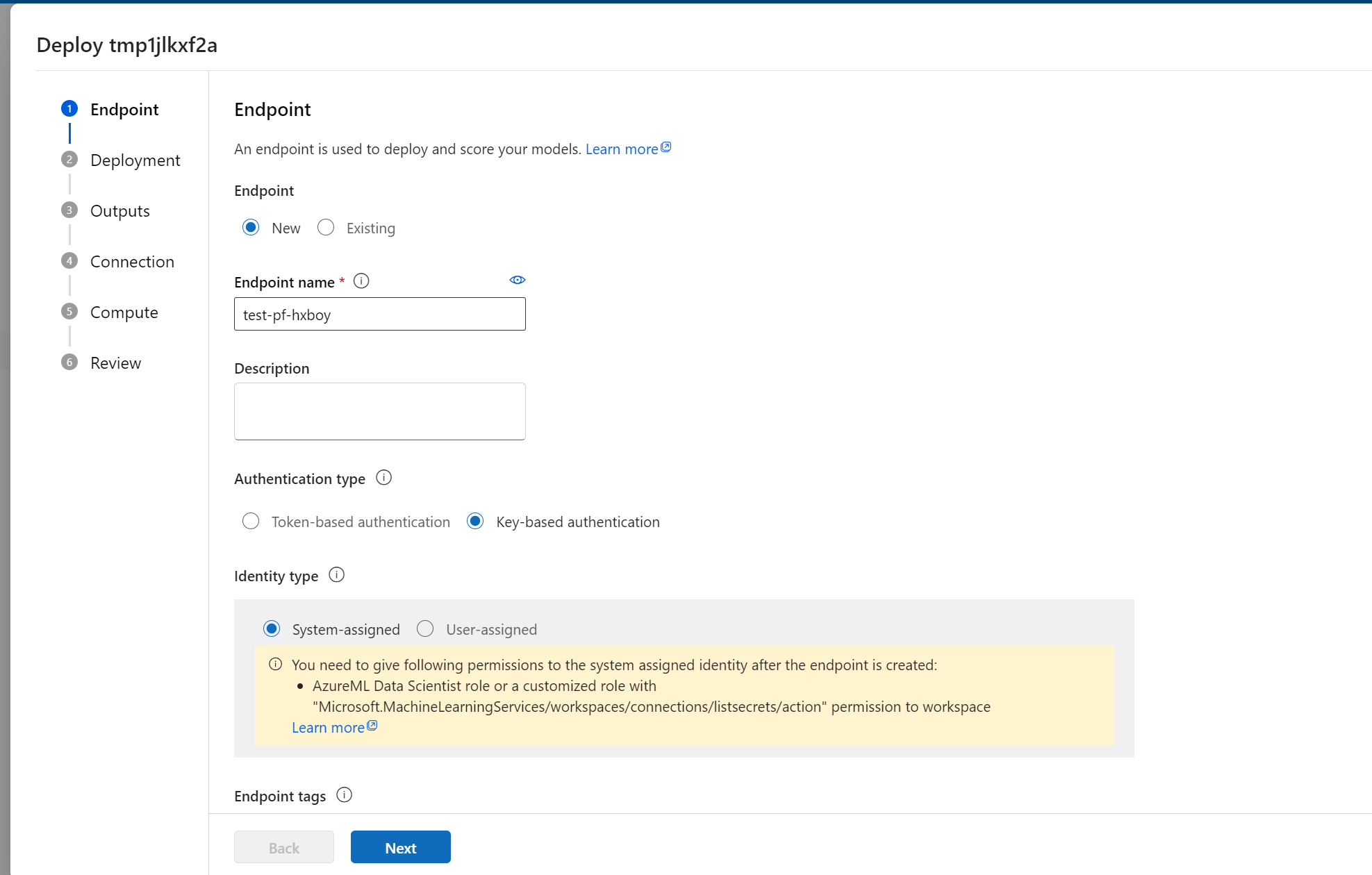
- Esta implementación en un punto de conexión en línea se puede basar en una instantánea de ejecución, lo que permite ofrecer servicios estables y seguros, realizar un seguimiento adicional del uso y la asignación de recursos y realizar la supervisión de registros en la nube.
- Después del análisis de experimentos, los miembros del equipo pueden volver al repositorio de código para otro desarrollo y ajuste preciso. Después, las ejecuciones posteriores se pueden enviar a la nube de forma iterativa.







¿Por qué se recomienda usar el repositorio de código para el desarrollo colaborativo?
Para el desarrollo iterativo, una combinación de un entorno de desarrollo local y un sistema de control de versiones, como Git, suele ser más eficaz. Puede realizar modificaciones y probar el código localmente y, a continuación, confirmar los cambios en Git. Esto crea un registro continuo de los cambios y ofrece la posibilidad de revertir a versiones anteriores si es necesario.
Cuando se requieren flujos de uso compartido en distintos entornos, se recomienda usar un repositorio de código basado en la nube, como GitHub o Azure Repos. Esto le permite acceder a la versión más reciente del código desde cualquier ubicación y proporciona herramientas para la colaboración y la administración de código.
Al seguir este procedimiento recomendado, los equipos pueden crear un entorno de colaboración sin problemas, eficiente y productivo para el desarrollo de flujo de avisos.