Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
Extensión ML de la CLI de Azure v2 (actual)SDK de Python azure-ai-ml v2 (actual)
La integración de Azure Machine Learning, con Azure Synapse Analytics, proporciona un acceso sencillo a la funcionalidad de computación distribuida, respaldada por Azure Synapse, para escalar trabajos de Apache Spark en Azure Machine Learning.
En este artículo, aprenderá a enviar un trabajo de Spark mediante el proceso de Spark sin servidor de Azure Machine Learning, la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 y el paso de identidad de usuario en unos sencillos pasos.
Para más información sobre Conceptos de Apache Spark en Azure Machine Learning, visite este recurso.
Requisitos previos
SE APLICA A:Extensión de ML de la CLI de Azure v2 (actual)
- Una suscripción a Azure: si aún no tiene ninguna, cree una cuenta gratuita antes de empezar.
- Un área de trabajo de Azure Machine Learning. Para obtener más información, visite Creación de recursos del área de trabajo.
- Una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2. Para más información, consulte Creación de una cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2.
- Creación de una instancia de proceso de Azure Machine Learning.
- Instalación de la CLI de Azure Machine Learning.
Adición de asignaciones de roles en cuentas de almacenamiento de Azure
Antes de enviar un trabajo de Apache Spark, debemos asegurarnos de que las rutas de acceso de datos de entrada y salida sean accesibles. Asigne los roles Colaborador y Colaborador de datos de Storage Blob a la identidad del usuario que ha iniciado la sesión para habilitar el acceso de lectura y escritura.
Para asignar roles adecuados a la identidad de usuario:
Abrir Microsoft Azure Portal.
Busque y seleccione el servicio Cuentas de almacenamiento.

En la página Cuentas de almacenamiento, seleccione la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 de la lista. Se abre una página que muestra Información general de la cuenta de almacenamiento.
Seleccione Control de acceso (IAM) en el panel izquierdo.
Seleccione Agregar asignación de roles.
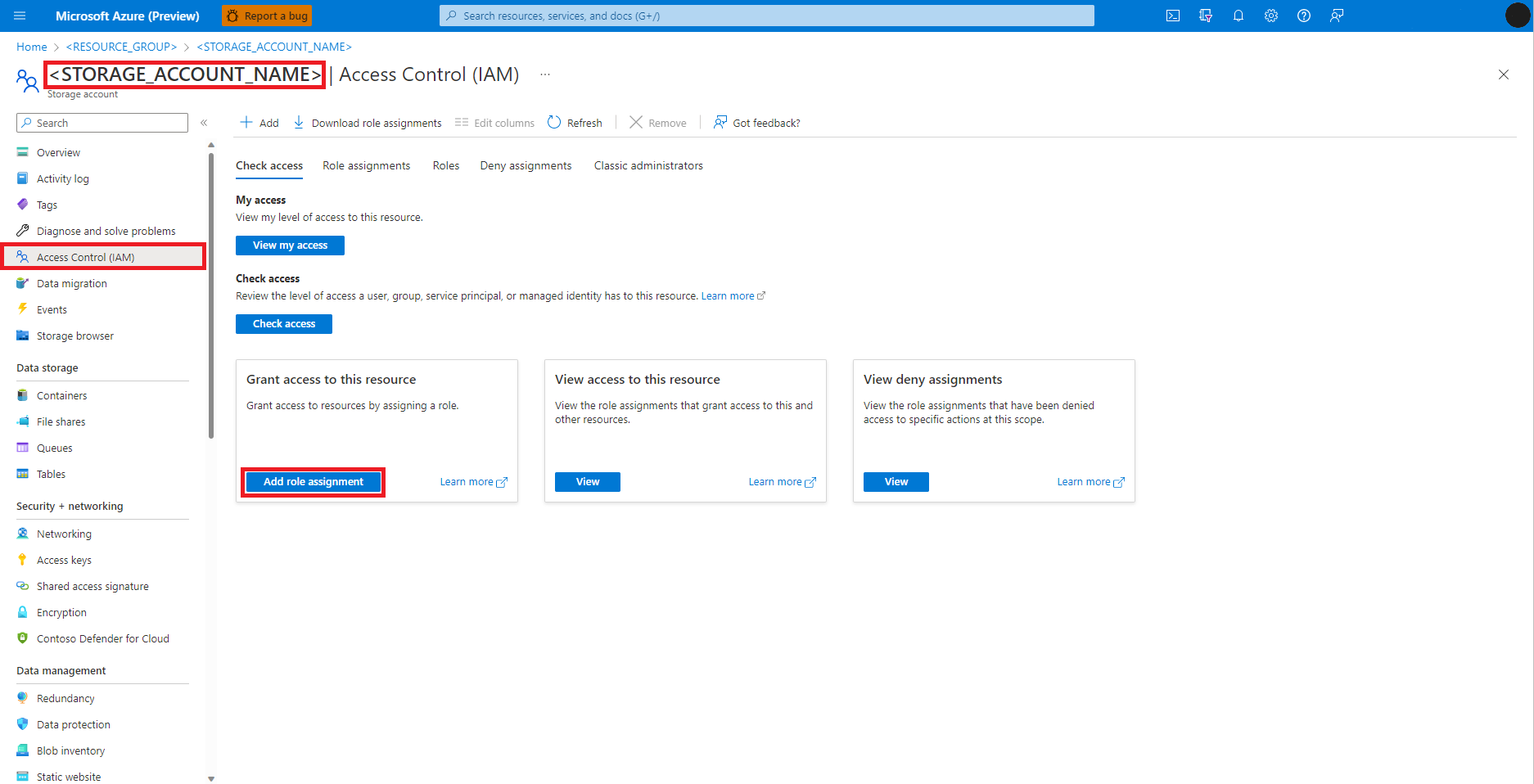
Busque el rol Colaborador de datos de blobs de almacenamiento.
Seleccione el rol Colaborador de datos de Storage Blob.
Seleccione Siguiente.
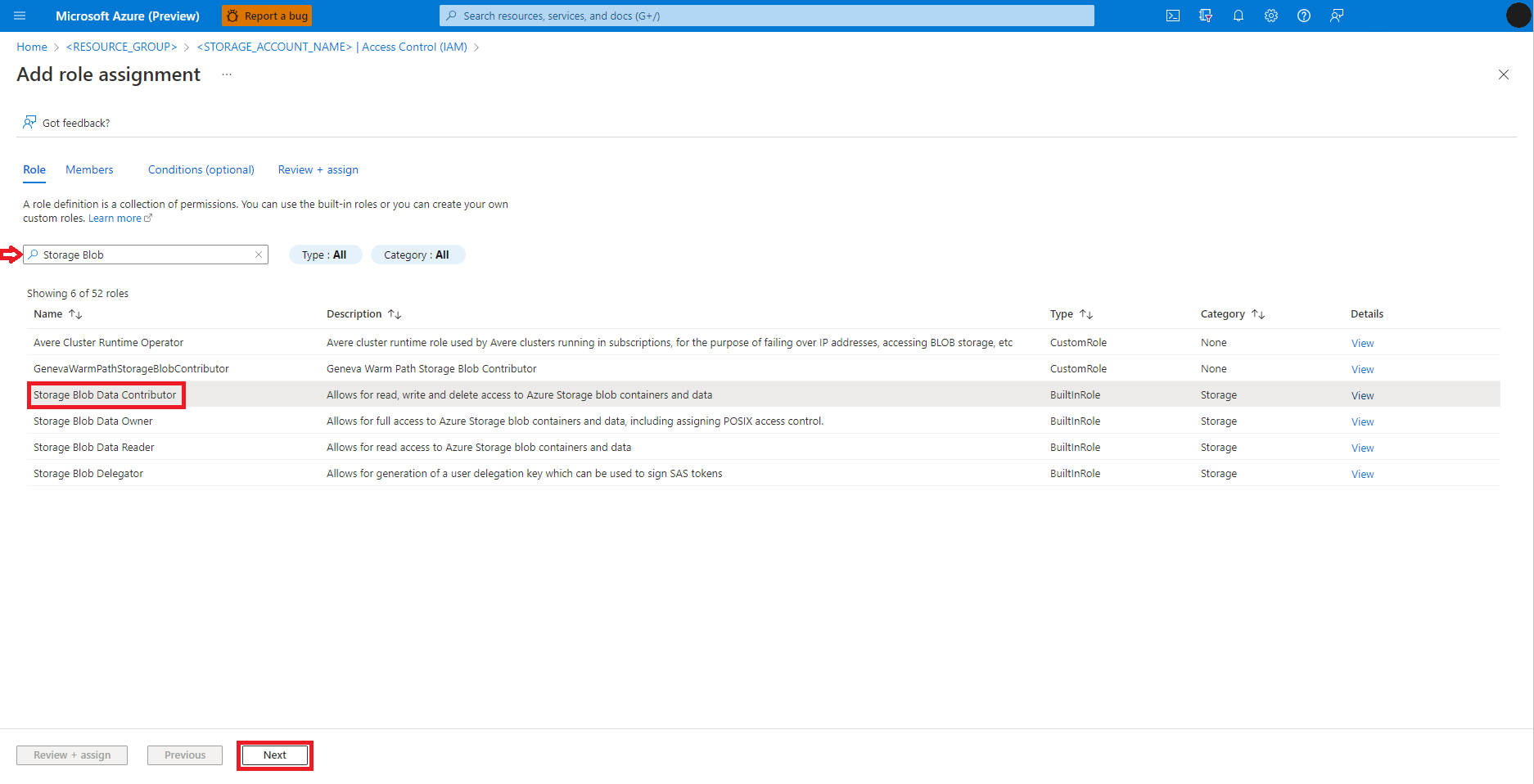
Seleccione Usuario, grupo o entidad de servicio.
Seleccione + Seleccionar miembros.
En el cuadro de texto situado debajo de Seleccionar, busque la identidad del usuario.
Seleccione la identidad de usuario de la lista para que se muestra en Miembros seleccionados.
Seleccione la identidad de usuario adecuada.
Seleccione Siguiente.
Seleccione Revisar y asignar.
Repita los pasos del 2 al 13 para la asignación de roles de Colaborador de Storage Blob.






Los datos de la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2 deben ser accesibles una vez que la identidad del usuario tenga asignados los roles adecuados.
Creación de código de Python parametrizado
Un trabajo de Spark requiere un script de Python que acepte argumentos. Para compilar este script, puede modificar el código de Python desarrollado a partir de la limpieza y transformación de datos. Aquí se muestra un script de Python de ejemplo:
# titanic.py
import argparse
from operator import add
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
parser = argparse.ArgumentParser()
parser.add_argument("--titanic_data")
parser.add_argument("--wrangled_data")
args = parser.parse_args()
print(args.wrangled_data)
print(args.titanic_data)
df = pd.read_csv(args.titanic_data, index_col="PassengerId")
imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy(
"mean"
) # Replace missing values in Age column with the mean value
df.fillna(
value={"Cabin": "None"}, inplace=True
) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
df.to_csv(args.wrangled_data, index_col="PassengerId")
Nota:
- En este ejemplo de código de Python se usa
pyspark.pandas, que solo admite Spark runtime versión 3.2. - Asegúrese de que el archivo
titanic.pyse carga en una carpeta denominadasrc. La carpetasrcdebe encontrarse en el mismo directorio donde ha creado el script o cuaderno de Python o el archivo de especificación de YAML que define el trabajo de Spark independiente.
Ese script admite dos argumentos: --titanic_data y --wrangled_data. Estos argumentos pasan la ruta de acceso de datos de entrada y la carpeta de salida, respectivamente. El script utiliza el archivo titanic.csv, disponible aquí. Cargue este archivo en un contenedor creado en la cuenta de almacenamiento de Azure Data Lake Storage (ADLS) Gen 2.
Enviar un trabajo independiente de Spark
SE APLICA A:Extensión de ML de la CLI de Azure v2 (actual)
Sugerencia
Puede enviar un trabajo de Spark desde:
- el terminal de una instancia de proceso de Azure Machine Learning.
- el terminal de Visual Studio Code, conectado a una instancia de proceso de Azure Machine Learning.
- el equipo local que tenga instalada la CLI de Azure Machine Learning.
En este ejemplo de especificación YAML se muestra un trabajo de Spark independiente. Usa un proceso de Spark sin servidor de Azure Machine Learning el acceso directo de la identidad de usuario y un URI de datos de entrada y salida en el formato abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>. Aquí, <FILE_SYSTEM_NAME> coincide con el nombre del contenedor.
$schema: http://azureml/sdk-2-0/SparkJob.json
type: spark
code: ./src
entry:
file: titanic.py
conf:
spark.driver.cores: 1
spark.driver.memory: 2g
spark.executor.cores: 2
spark.executor.memory: 2g
spark.executor.instances: 2
inputs:
titanic_data:
type: uri_file
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv
mode: direct
outputs:
wrangled_data:
type: uri_folder
path: abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled/
mode: direct
args: >-
--titanic_data ${{inputs.titanic_data}}
--wrangled_data ${{outputs.wrangled_data}}
identity:
type: user_identity
resources:
instance_type: standard_e4s_v3
runtime_version: "3.2"
En el archivo de especificación YAML anterior:
- la propiedad
codedefine la ruta de acceso relativa de la carpeta que contiene el archivo con parámetrostitanic.py. - La propiedad
resourcedefine los valores deinstance_typey Apache Sparkruntime_versionque usa el proceso de Spark sin servidor. Actualmente se admiten estos valores de tipo de instancia:standard_e4s_v3standard_e8s_v3standard_e16s_v3standard_e32s_v3standard_e64s_v3
El archivo YAML mostrado anteriormente se puede usar en el comando az ml job create, con el parámetro --file, para crear un trabajo de Spark independiente como se muestra:
az ml job create --file <YAML_SPECIFICATION_FILE_NAME>.yaml --subscription <SUBSCRIPTION_ID> --resource-group <RESOURCE_GROUP> --workspace-name <AML_WORKSPACE_NAME>
Sugerencia
Es posible que tenga un grupo de Synapse Spark existente en el área de trabajo de Azure Synapse. Para usar un grupo de Synapse Spark existente, siga las instrucciones para asociar un grupo de Synapse Spark en el área de trabajo de Azure Machine Learning.
Pasos siguientes
- Apache Spark en Azure Machine Learning
- Inicio rápido: Limpieza y transformación de datos interactivos con Apache Spark
- Asociación y administración de un grupo de Spark de Synapse en Azure Machine Learning
- Limpieza y transformación de datos interactivos con Apache Spark en Azure Machine Learning
- Envío de trabajos de Spark en Azure Machine Learning
- Ejemplos de código para trabajos de Spark mediante la CLI de Azure Machine Learning
- Ejemplos de código para trabajos de Spark mediante el SDK de Python de Azure Machine Learning