Tutorial: Previsión de la demanda con aprendizaje automático automatizado sin código en el Estudio de Azure Machine Learning
Aprenda a crear un modelo de previsión de series temporales sin escribir ninguna línea de código mediante el aprendizaje automático automatizado de Estudio de Azure Machine Learning. Este modelo predice la demanda de alquiler de un servicio de uso compartido de bicicletas.
En este tutorial no se escribe ni una sola línea de código, se usa la interfaz de Studio para realizar el entrenamiento. Aprenderá a realizar las siguientes tareas:
- Creación y carga de un conjunto de datos.
- Configuración y ejecución de un experimento de ML automatizado.
- Especifique la configuración de la previsión.
- Exploración de los resultados del experimento.
- Implementación del mejor modelo.
Pruebe también el aprendizaje automático automatizado para estos otros tipos de modelos:
- Para ver un ejemplo sin código de un modelo de clasificación, consulte Tutorial: Creación de un modelo de clasificación con aprendizaje automático automatizado en Azure Machine Learning.
- Para ver un primer ejemplo de código de un modelo de detección de objetos, consulte Tutorial: Entrenamiento de un modelo de detección de objetos con AutoML y Python.
Prerrequisitos
Un área de trabajo de Azure Machine Learning. Consulte Creación de recursos del área de trabajo.
Descargue el archivo de datos bike-no.csv.
Inicio de sesión en Estudio de Azure Machine Learning
En este tutorial, se crea el experimento de aprendizaje automático automatizado que se ejecuta en Azure Machine Learning Studio, una interfaz web consolidada que incluye herramientas de aprendizaje automático para llevar a la práctica escenarios de ciencia de datos para los profesionales de ciencia de datos de todos los niveles de conocimiento. Studio no se admite en Internet Explorer.
Inicie sesión en Azure Machine Learning Studio.
Seleccione la suscripción y el área de trabajo que ha creado.
Seleccione Comenzar.
Seleccione ML automatizado en la sección Autor en el panel de la izquierda.
Seleccione +New automated ML job (+Nuevo trabajo de ML automatizado).
Creación y carga de un conjunto de datos
Antes de configurar el experimento, cargue el archivo de datos en el área de trabajo en forma de conjunto de datos de Azure Machine Learning. Así podrá asegurarse de que los datos tienen el formato adecuado para el experimento.
En el formulario Select dataset (Seleccionar un conjunto de datos), seleccione From local files (De archivos locales) del menú desplegable +Create dataset (Crear conjunto de datos).
En el formulario Basic info (Información básica), asígnele un nombre al conjunto de datos y, si lo desea, incluya una descripción. De forma predeterminada, el tipo de datos es Tabular, ya que el aprendizaje automático automatizado en Azure Machine Learning Studio por ahora solo admite los conjuntos de datos tabulares.
Seleccione Next (Siguiente) en la parte inferior izquierda.
En el formulario Datastore and file selection (Selección del archivo y el almacén de datos), seleccione el almacén de archivos predeterminado que se configuró automáticamente durante la creación del área de trabajo, workspaceblobstore (Azure Blob Storage) . Esta es la ubicación de almacenamiento en la que se carga el archivo de datos.
Seleccione Cargar archivos en el menú desplegable Cargar.
Seleccione el archivo bike-no.csv en el equipo local. Este es el archivo que descargó como requisito previo.
Seleccione Siguiente.
Una vez completada la carga, el formulario de configuración y vista previa se rellena de forma inteligente en función del tipo de archivo.
Compruebe que el formulario Settings y Preview (Configuración y vista previa) se rellenan como se indica a continuación y seleccione Next (Siguiente).
Campo Descripción Valor para el tutorial Formato de archivo Define el diseño y el tipo de datos almacenados en un archivo. Delimitado Delimitador Uno o más caracteres para especificar el límite entre regiones independientes en texto sin formato u otros flujos de datos. Coma Encoding Identifica qué tabla de esquema de bit a carácter se va a usar para leer el conjunto de elementos. UTF-8 Encabezados de columna Indica cómo se tratarán los encabezados del conjunto de datos, si existen. Solo el primer archivo tiene encabezados Omitir filas Indica el número de filas, si hay alguna, que se omiten en el conjunto de datos. None El formulario Scheme (Esquema) permite una configuración adicional de los datos para este experimento.
En este ejemplo, elija omitir las columnas casual (ocasional) y registered (registrado). Estas columnas son un desglose de la columna cnt (recuento) por lo que no las incluimos.
Además, en este ejemplo, deje los valores predeterminados para Properties (Propiedades) y Type (Tipo).
Seleccione Next (Siguiente).
En el formulario Confirm details (Confirmar detalles) compruebe que la información coincide con lo rellenado anteriormente en los formularios Basic info (Información básica) y Settings and preview (Configuración y vista previa).
Seleccione Create (Crear) para completar la creación del conjunto de datos.
Seleccione el conjunto de datos cuando aparezca en la lista.
Seleccione Next (Siguiente).
Configurar trabajo
Una vez cargados y configurados los datos, configure el destino de proceso remoto y seleccione la columna de los datos que desea predecir.
- Rellene el formulario Configurar trabajo como se indica a continuación:
Escriba el nombre del experimento:
automl-bikeshare.Seleccione cnt (recuento) como columna de destino en la que desea realizar las predicciones. Esta columna indica el total de alquileres de bicicletas.
Seleccione clúster de proceso como tipo de proceso.
Seleccione +Nuevo para configurar el destino de proceso. ML automatizado solo admite el proceso con Azure Machine Learning.
Rellene el formulario Seleccionar máquina virtual para configurar el proceso.
Campo Descripción Valor para el tutorial Nivel de máquina virtual Seleccione qué prioridad debe tener el experimento. Dedicado Tipo de máquina virtual Seleccione el tipo de máquina virtual del proceso. CPU (Unidad central de procesamiento) Tamaño de la máquina virtual Seleccione el tamaño de la máquina virtual para el proceso. Se proporciona una lista de los tamaños recomendados en función de los datos y el tipo de experimento. Standard_DS12_V2 Seleccione Siguiente para rellenar el formulario Parámetros de configuración.
Campo Descripción Valor para el tutorial Nombre del proceso Un nombre único que identifique el contexto del proceso. bike-compute Nodos mín./máx. Para generar perfiles de datos, debe especificar uno o más nodos. Número mínimo de nodos: 1
Número máximo de nodos: 6Segundos de inactividad antes de la reducción vertical Tiempo de inactividad antes de que el clúster se reduzca verticalmente de manera automática hasta el número mínimo de nodos. 120 (valor predeterminado) Configuración avanzada Valores para configurar y autorizar una red virtual para el experimento. None Seleccione Create (Crear) para obtener el destino de proceso.
Tarda unos minutos en completarse.
Después de la creación, seleccione el nuevo destino de proceso en la lista desplegable.
Seleccione Next (Siguiente).
Seleccionar la configuración de la previsión
Complete la configuración del experimento de ML automatizado especificando el tipo de tarea de aprendizaje automático y los valores de configuración.
En el formulario Task type and settings (Configuración y tipo de tarea), seleccione Time series forecasting (Previsión se series temporales) como tipo de tarea de aprendizaje automático.
Seleccione date (fecha) como Time column (Columna de hora) y deje Time series identifiers (Identificadores de serie temporal) en blanco.
La frecuencia es la frecuencia con la que se recopilan los datos históricos. Mantenga seleccionada detección automática.
El horizonte de previsión es la longitud de tiempo en el futuro que se quiere predecir. Anule la selección de detección automática y escriba 14 en el campo.
Seleccione View additional configuration settings (Ver opciones de configuración adicionales) y rellene los campos como se indica a continuación. Esta configuración es para controlar mejor el trabajo de entrenamiento y especificar la configuración de la previsión. De lo contrario, los valores predeterminados se aplican en función de la selección y los datos del experimento.
Configuraciones adicionales Descripción Valor para el tutorial Métrica principal Métrica de evaluación por la que se medirá el algoritmo de aprendizaje automático. Error cuadrático medio normalizado Explicación del mejor modelo Muestra automáticamente la posible explicación relativa al mejor modelo creado mediante ML automatizado. Habilitar Algoritmos bloqueados Algoritmos que desea excluir del trabajo de entrenamiento. Árboles aleatorios extremos Configuración adicional de la previsión Esta configuración ayuda a mejorar la precisión del modelo.
Forecast target lags (Retrasos de objetivo de previsión): cuánto quiere retroceder en el tiempo para construir los retrasos de la variable de destino.
Periodos acumulados de destino: especifica la duración de los periodos acumulados en la que se generan características como max, min (máx., mín.) y sum (suma).
Retrasos de objetivo de previsión: Ninguno
Tamaño de la ventana con desplazamiento de objetivo: NingunoCriterios de exclusión Si se cumplen los criterios, se detiene el trabajo de entrenamiento. Tiempo de trabajo de entrenamiento (horas): 3
Umbral de puntuación de métrica: NingunoSimultaneidad Número máximo de iteraciones paralelas ejecutadas por iteración Número máximo de iteraciones simultáneas: 6 Seleccione Guardar.
Seleccione Next (Siguiente).
En el formulario [Opcional] Validar y probar,
- Seleccione la validación cruzada de k iteraciones como tipo de validación.
- Seleccione 5 como su número de validaciones cruzadas.
Ejecutar experimento
Para ejecutar el experimento, seleccione Finish (Finalizar). Se abre la pantalla Detalles del trabajo con el Estado del trabajo en la parte superior junto al número de trabajo. Este estado se actualiza a medida que el experimento progresa. También aparecen notificaciones en la esquina superior derecha de Studio, para informarle del estado de su experimento.
Importante
La preparación del trabajo del experimento requiere de 10 a 15 minutos.
Una vez que se ejecuta, se tarda de 2 a 3 minutos más para cada iteración.
En producción, probablemente puede descansar un poco, ya que el proceso tarda. Mientras espera, se recomienda empezar por explorar los algoritmos probados de la pestaña Models (Modelos) que se van completando.
Exploración de modelos
Vaya a la pestaña Models (Modelos) para ver los algoritmos (modelos) probados. De forma predeterminada, los modelos se ordenan por puntuación de las métricas a medida que se completan. De manera predeterminada, el modelo con la mayor puntuación según la métrica Error cuadrático medio normalizado elegida aparece en la parte superior de la lista.
Mientras espera a que terminen todos los modelos del experimento, seleccione Algorithm name (Nombre de algoritmo) de un modelo completado para explorar los detalles de rendimiento.
En el ejemplo siguiente se navega para seleccionar un modelo en la lista de modelos que creó el trabajo. A continuación, seleccione las pestañas Información general y Métricas para ver las propiedades, las métricas y los gráficos de rendimiento del modelo seleccionado.
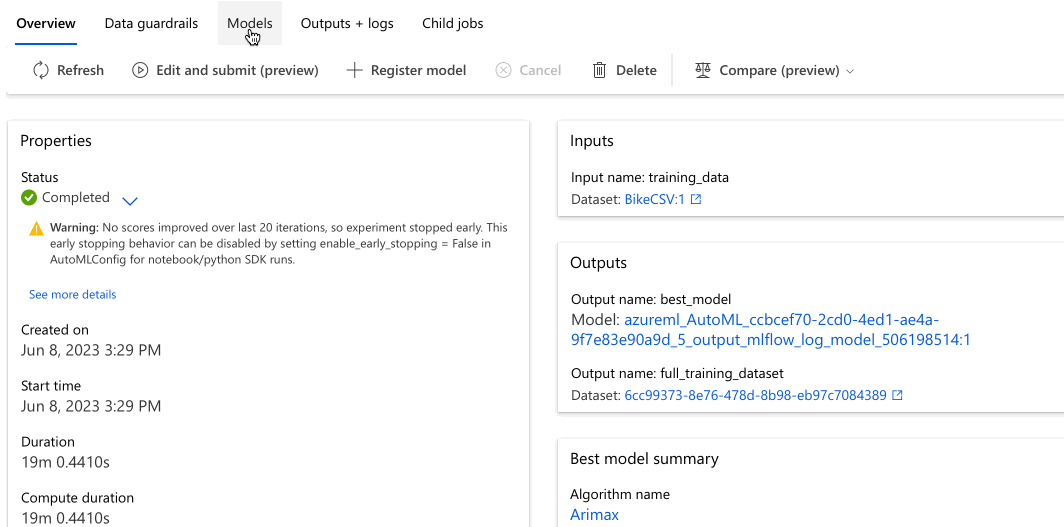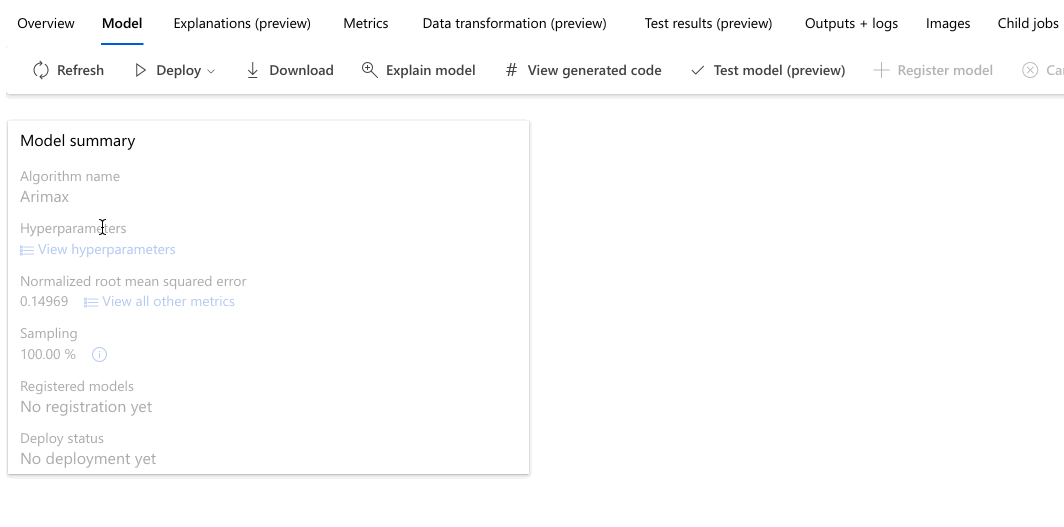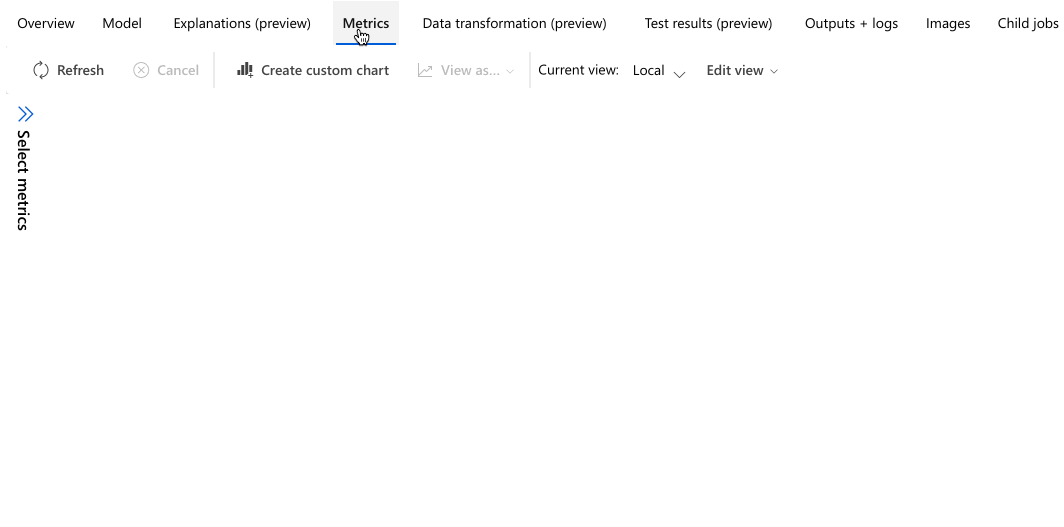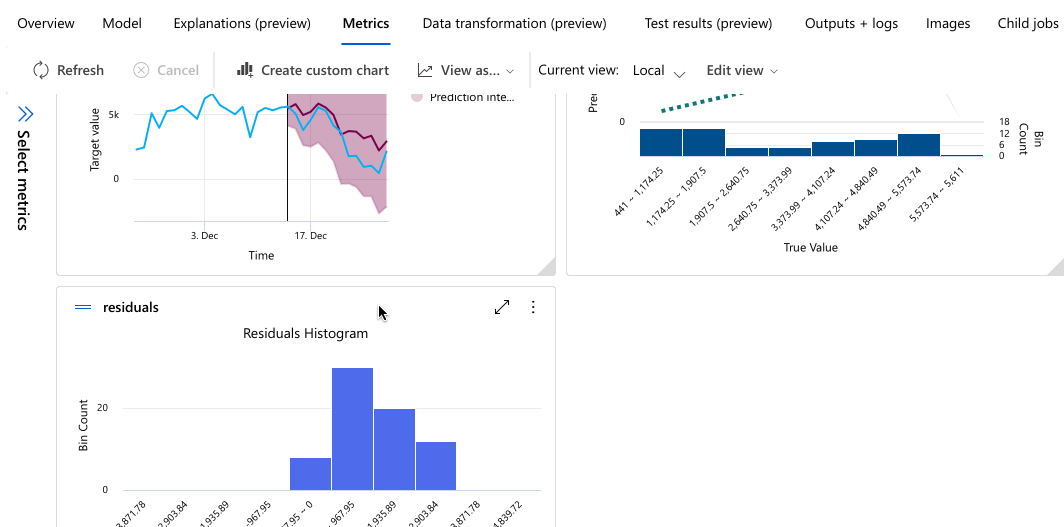
Implementación del modelo
El aprendizaje automático automatizado en Azure Machine Learning Studio permite implementar el mejor modelo como servicio web en pocos pasos. La implementación es la integración del modelo para que pueda predecir datos nuevos e identificar posibles áreas de oportunidad.
Para este experimento, la implementación en un servicio web significa que la empresa de uso compartido de bicicletas ahora tiene una solución web iterativa y escalable para prever la demanda de alquiler de la cuota de bicicletas.
Una vez finalizado el trabajo, vuelva a la página del trabajo principal seleccionando Trabajo 1 en la parte superior de la pantalla.
En la sección Best model summary, se considera el mejor modelo en el contexto de este experimento según la métrica Normalized root mean squared error.
Se implementa este modelo, pero se recomienda que la implementación tarda unos 20 minutos en completarse. El proceso de implementación conlleva varios pasos, como el registro del modelo, la generación de recursos y su configuración para el servicio web.
Seleccione el mejor modelo para abrir la página específica del modelo.
Seleccione el botón Deploy (Implementar) situado en el área superior izquierda de la pantalla.
Rellene el panel Deploy Model (Implementar modelo) como se indica a continuación:
Campo Value Nombre de implementación bikeshare-deploy Descripción de implementación implementación de la demanda de uso compartido de bicicletas Compute type (Tipo de proceso) Seleccione Azure Compute Instance (ACI) (Instancia de proceso de Azure [ACI]) Enable authentication (Habilitar autenticación) Deshabilitar. Use custom deployment assets (Usar recursos de implementación personalizados) Deshabilitar. La deshabilitación permite que se generen automáticamente el archivo de controlador predeterminado (script de puntuación) y el archivo de entorno. En este ejemplo, usamos los valores predeterminados que se proporcionan en el menú Advanced (Avanzada).
Seleccione Implementar.
Aparece un mensaje en verde en la parte superior de la pantalla Trabajo que indica que la implementación se ha iniciado correctamente. El progreso de la implementación se puede encontrar en el panel Model summary (Resumen de modelo), en Deploy status (Estado de implementación).
Una vez finalizada la implementación correctamente, tendrá un servicio web operativo para generar predicciones.
Continúe con Pasos siguientes para más información sobre el consumo del nuevo servicio web y para probar las predicciones con la compatibilidad con Azure Machine Learning incorporada en Power BI.
Limpieza de recursos
Los archivos de implementación son mayores que los archivos de datos y del experimento, por lo que cuesta más almacenarlos. Elimine solo los archivos de implementación para minimizar costos en su cuenta y si desea conservar el área de trabajo y los archivos del experimento. Elimine todo el grupo de recursos completo si no planea usar ninguno de los archivos.
Eliminación de la instancia de implementación
Elimine solo la instancia de implementación de Azure Machine Learning Studio, si desea mantener el área de trabajo y el grupo de recursos para otros tutoriales y para explorarlos.
Vaya a Azure Machine Learning Studio. Vaya al área de trabajo y, a la izquierda, en el panel Assets (Recursos), seleccione Endpoints (Puntos de conexión).
Seleccione la implementación que desea eliminar y seleccione Eliminar.
Seleccione Continuar.
Eliminar el grupo de recursos
Importante
Los recursos que creó pueden usarse como requisitos previos para otros tutoriales y artículos de procedimientos de Azure Machine Learning.
Si no va a usar ninguno de los recursos que ha creado, elimínelos para no incurrir en cargos:
En Azure Portal, en el cuadro de búsqueda, escriba Grupos de recursos y selecciónelo en los resultados.
En la lista, seleccione el grupo de recursos que creó.
En la página Información general, seleccione Eliminar grupo de recursos.
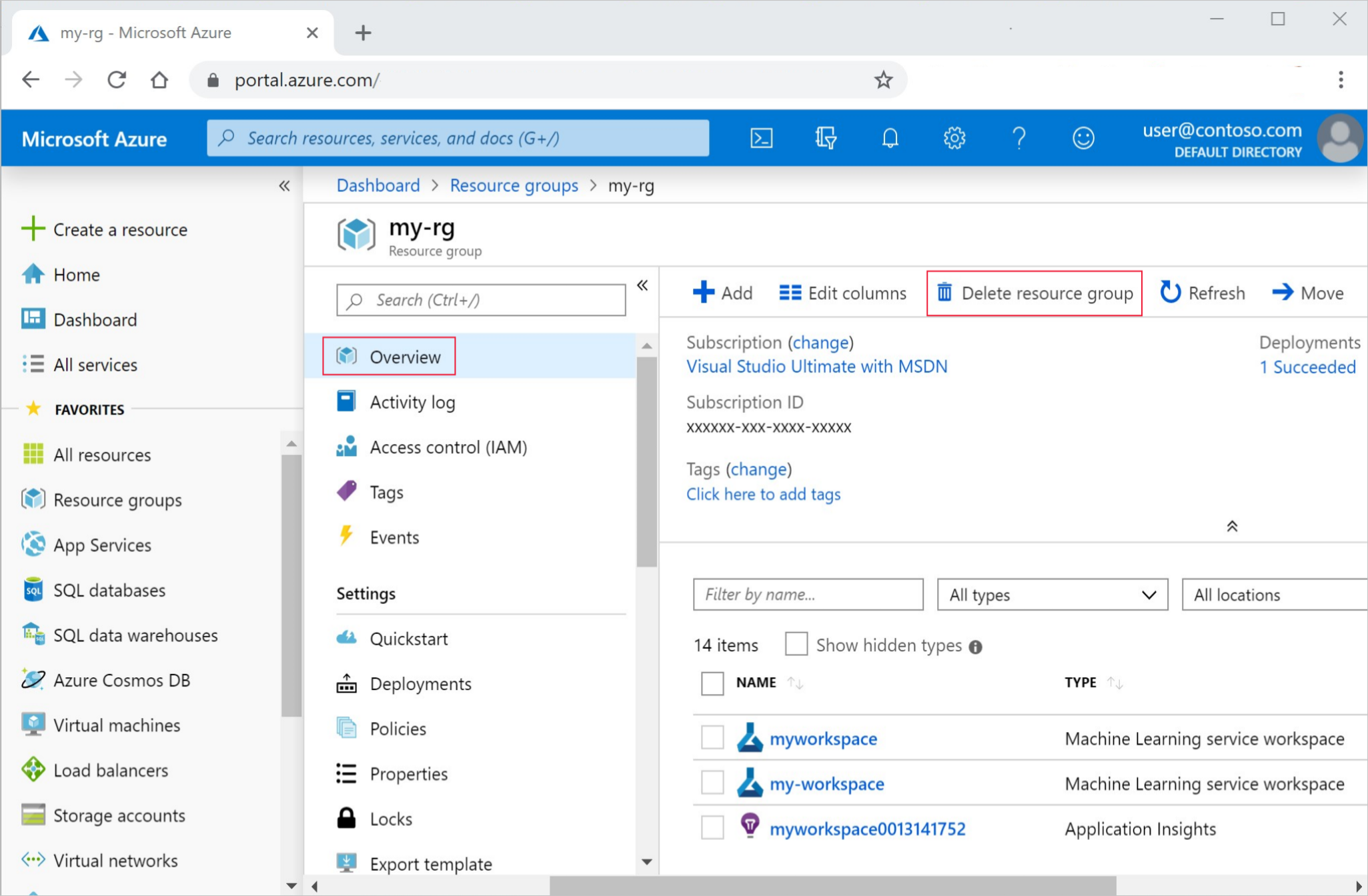
Escriba el nombre del grupo de recursos. A continuación, seleccione Eliminar.
Pasos siguientes
En este tutorial se ha usado ML automatizado en Azure Machine Learning Studio para crear e implementar un modelo de previsión de series temporales que prediga la demanda de alquiler de bicicletas.
- Más información acerca del aprendizaje automático automatizado.
- Para más información sobre las métricas de clasificación y los gráficos, consulte el artículo de descripción de los resultados de aprendizaje automático automatizado.
- Más información sobre las preguntas más frecuentes sobre la previsión.
Nota:
Este conjunto de datos del uso compartido de bicicletas se ha modificado para el tutorial. Este conjunto de datos se puso a disponibilidad como parte de un concurso de Kaggle y estaba accesible originalmente desde Capital Bikeshare. También se puede encontrar en la base de datos UCI de Machine Learning.
Origen: Fanaee-T, Hadi, and Gama, Joao, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): págs. 1-15, Springer Berlin Heidelberg.