Ingesta de datos con Azure Data Factory
En este artículo, obtendrá información sobre las opciones disponibles para crear una canalización de ingesta de datos con Azure Data Factory. Esta canalización de Azure Data Factory se utiliza para ingerir datos para su uso con Azure Machine Learning. Data Factory permite extraer, transformar y cargar (ETL) datos fácilmente. Una vez que los datos se han transformado y cargado en el almacenamiento, se pueden usar para entrenar los modelos de Machine Learning en Azure Machine Learning.
La transformación de datos simple se puede controlar con actividades e instrumentos nativos de Data Factory, como el flujo de datos. Cuando se trata de escenarios más complicados, los datos se pueden procesar con código personalizado. Por ejemplo, código de Python o R.
Comparación de canalizaciones de ingesta de datos de Azure Data Factory
Hay varias técnicas comunes de uso de Data Factory para transformar datos durante la ingesta. Cada técnica tiene ventajas e inconvenientes que ayudan a determinar si es una buena opción para un caso de uso específico:
| Técnica | Ventajas | Inconvenientes |
|---|---|---|
| Data Factory + Azure Functions | Solo adecuado para el procesamiento de ejecución breve. | |
| Data Factory + componente personalizado | ||
| Data Factory + cuaderno de Azure Databricks |
Azure Data Factory con Azure Functions
Azure Functions permite ejecutar pequeños fragmentos de código (denominados "funciones") sin preocuparse por la infraestructura de la aplicación. En esta opción, los datos se procesan con código Python personalizado encapsulado en una función de Azure Functions.
La función se invoca con la actividad de la función de Azure en Azure Data Factory. Este enfoque es una buena opción para las transformaciones de datos ligeros.
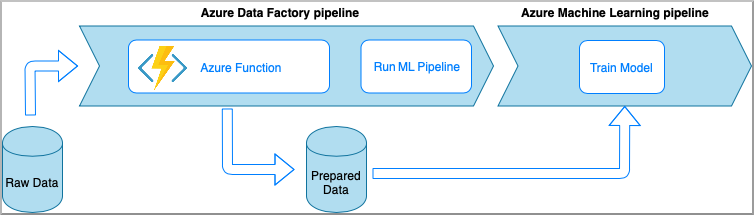
- Ventajas:
- Los datos se procesan en un proceso sin servidor con una latencia relativamente baja.
- La canalización de Data Factory puede invocar una función Durable Functions de Azure que puede implementar un flujo de transformación de datos sofisticado.
- Los detalles de la transformación de datos se abstraen mediante la función de Azure que se puede reutilizar e invocar desde otros lugares.
- Desventajas:
- Las funciones de Azure Functions deben crearse antes de usarse con ADF.
- Azure Functions es adecuado solo para el procesamiento de datos de ejecución breve.
Azure Data Factory con actividad de componentes personalizados
En esta opción, los datos se procesan con código Python personalizado encapsulado en un archivo ejecutable. Se invoca con una actividad de componente personalizado de Azure Data Factory. Este enfoque es más adecuado para los datos de gran tamaño que la técnica anterior.
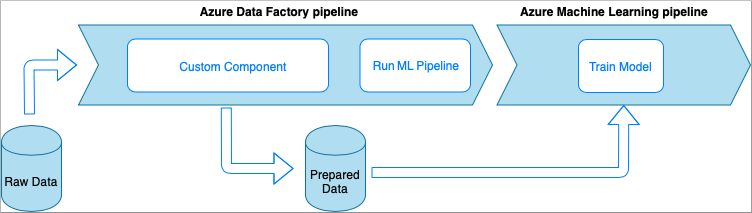
- Ventajas:
- Los datos se procesan en un grupo de Azure Batch, lo que proporciona un procesamiento de alto rendimiento y paralelo a gran escala.
- Se puede usar para ejecutar algoritmos pesados y procesar grandes cantidades de datos.
- Desventajas:
- Se debe crear el grupo de Azure Batch antes de usarse con Data Factory.
- Sobre ingeniería relacionada con el encapsulado de código de Python en un archivo ejecutable. Complejidad de la administración de dependencias y parámetros de entrada y salida.
Azure Data Factory con cuadernos de Python de Azure Databricks
Azure Databricks es una plataforma de análisis basada en Apache Spark y optimizada para Azure.
En esta técnica, un cuaderno de Python, que se ejecuta en un clúster de Azure Databricks, realiza la transformación de datos. Probablemente, el enfoque más común que usa toda la eficacia de un servicio de Azure Databricks. Está diseñado para el procesamiento de datos distribuidos a escala.
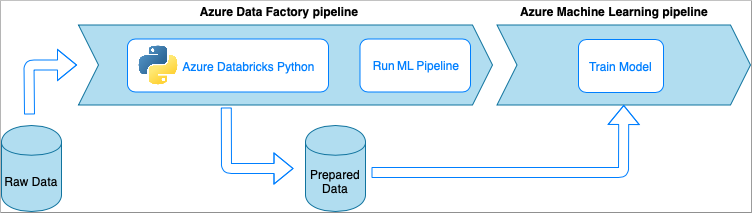
- Ventajas:
- Los datos se transforman en el servicio de Azure de procesamiento de datos más eficaz, del que se realiza una copia de seguridad en un entorno de Apache Spark.
- Compatibilidad nativa con Python junto con los marcos de ciencia de datos y las bibliotecas, como TensorFlow, PyTorch y scikit-learn.
- No es necesario incluir el código de Python en funciones o módulos ejecutables. El código funciona tal cual.
- Desventajas:
- Se debe crear la infraestructura de Azure Databricks antes de usarse con Azure Databricks.
- Puede ser costoso en función de la configuración de Azure Databricks.
- La rotación de los clústeres de proceso desde el modo "frío" tarda un tiempo que agrega una latencia alta a la solución.
Consumo de datos en Azure Machine Learning
La canalización de Data Factory guarda los datos preparados en el almacenamiento en la nube (como Azure Blob o Azure Data Lake).
Para consumir los datos preparados en Azure Machine Learning puede:
- Invocar una canalización de Azure Machine Learning desde la canalización de Data Factory.
OR - Crear un almacén de datos de Azure Machine Learning.
Invocación de una canalización de Azure Machine Learning desde Data Factory
Este método se recomienda para los flujos de trabajo de Machine Learning Operations (MLOps). Si no quiere configurar una canalización de Azure Machine Learning, consulte Lectura de datos directamente desde el almacenamiento.
Cada vez que se ejecuta la canalización de Data Factory:
- Los datos se guardan en una ubicación diferente en el almacenamiento.
- Para pasar la ubicación a Azure Machine Learning, la canalización de Data Factory llama a una canalización Azure Machine Learning. Al llamar a la canalización de ML, la ubicación de los datos y el id. de trabajo se envían como parámetros.
- La canalización de ML puede crear un almacén de datos y un conjunto de datos de Azure Machine Learning con la ubicación de los datos. Obtenga más información en Ejecución de canalizaciones de Azure Machine Learning en Data Factory.
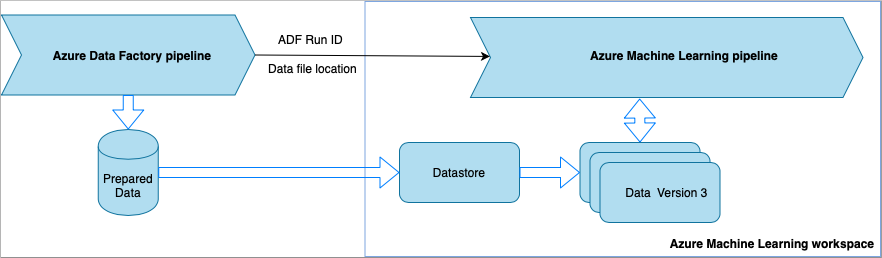
Sugerencia
Los conjuntos de datos admiten el control de versiones, por lo que la canalización de ML puede registrar una nueva versión del conjunto de datos que apunte a los datos más recientes de la canalización de ADF.
Una vez que se pueda acceder a los datos a través de un almacén de datos o un conjunto de datos, puede usarlos para entrenar un modelo de ML. El proceso de entrenamiento podría formar parte de la misma canalización de ML a la que se llama desde ADF. También puede ser un proceso independiente como experimentación en un cuaderno de Jupyter Notebook.
Dado que los conjuntos de datos admiten el control de versiones y cada trabajo de la canalización crea una nueva versión, es fácil entender qué versión de los datos se usó para entrenar un modelo.
Lectura de datos directamente desde el almacenamiento
Si no desea crear una canalización de ML, puede acceder a los datos directamente desde la cuenta de almacenamiento donde se guardan los datos preparados con un almacén de datos y un conjunto de datos de Azure Machine Learning.
En el siguiente código de Python se muestra cómo crear un almacén de datos que se conecta al almacenamiento de Azure Data Lake Generation 2. Obtenga más información sobre los almacenes de datos y dónde encontrar los permisos de la entidad de servicio.
SE APLICA A: Azure ML del SDK de Python v1
Azure ML del SDK de Python v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
A continuación, cree un conjunto de datos para hacer referencia a los archivos que quiere usar en la tarea de aprendizaje automático.
En el código siguiente se crea un objeto TabularDataset a partir de un archivo CSV, prepared-data.csv. Obtenga más información sobre los tipos de conjunto de datos y los formatos de archivo aceptados.
SE APLICA A:Azure ML del SDK de Python v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
A partir de aquí, use prepared_dataset para hacer referencia a los datos preparados, como en los scripts de entrenamiento. Obtenga información sobre el Entrenamiento de modelos con conjuntos de datos en Azure Machine Learning.