Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se describe el rol de las puertas T y las factorías de T en la computación cuántica tolerante a errores. Dado un algoritmo cuántico, la estimación de los recursos necesarios para ejecutar las puertas T y las factorías de T es fundamental para determinar la viabilidad del algoritmo. El estimador de recursos de Azure Quantum calcula el número de estados T necesarios para ejecutar el algoritmo, el número de cúbits físicos para una única factoría de T y el tiempo de ejecución de la factoría de T.
Conjunto universal de puertas cuánticas
Según los criterios de DiVincenzo, un equipo cuántico escalable debe ser capaz de implementar un conjunto universal de puertas cuánticas. Un conjunto universal contiene todas las puertas necesarias para realizar cualquier cálculo cuántico, es decir, cualquier cálculo debe volver a descomponerse en una secuencia finita de puertas universales. Como mínimo, un equipo cuántico debe poder mover cúbits únicos a cualquier posición de la esfera bloch (mediante puertas de un solo cúbit), así como introducir entrelazamiento en el sistema, lo que requiere una puerta de varios cúbits.
Solo hay cuatro funciones que asignan un bit a un bit en un equipo clásico. En cambio, hay un número infinito de transformaciones unitarias en un solo cúbit en un equipo cuántico. Por lo tanto, ningún conjunto finito de operaciones cuánticas primitivas o puertas, puede replicar exactamente el conjunto infinito de transformaciones unitarias permitidas en la computación cuántica. Esto significa que, a diferencia de la computación clásica, es imposible que un equipo cuántico implemente exactamente todos los programas cuánticos posibles utilizando un número finito de puertas. Por tanto, los equipos cuánticos no pueden ser universales en el mismo sentido que los equipos clásicos. Como resultado, cuando decimos que un conjunto de puertas es universal para la computación cuántica, nos referimos en realidad a algo ligeramente más débil de lo que significa en la computación clásica.
Para la universalidad, es necesario que un equipo cuántico solo aproxima cada matriz unitaria dentro de un error finito mediante una secuencia de puerta de longitud finita.
En otras palabras, un conjunto de puertas es un conjunto de puertas universal si cualquier transformación unitaria puede escribirse aproximadamente como un producto de puertas de este conjunto. Es necesario que para cualquier límite de error prescrito, existen puertas $G_, G_{2}, \ldots, G_N$ del conjunto de{1} puertas de modo que
$$ G_N G_{N-1}\cdots G_2 G_1 \approx U. $$
Dado que la convención para la multiplicación de matriz es multiplicar de derecha a izquierda la primera operación de puerta en esta secuencia, $G_N$, es realmente la última aplicada al vector de estado cuántico. Más formalmente, decimos que un conjunto de puertas es universal si para cada tolerancia de error $\epsilon>0$ existe $G_1,\ldots, G_N$ de forma que la distancia entre $G_N\ldots G_1$ y $U$ sea como máximo $\epsilon$. Idealmente, el valor de $N$ necesario para alcanzar esta distancia de $\epsilon$ debería escalarse polilogarítmicamente con $1/\epsilon$.
Por ejemplo, el conjunto formado por puertas Hadamard, CNOT y T es un conjunto universal, desde el que se puede generar cualquier cálculo cuántico (en cualquier número de cúbits). El hadamard y el conjunto de puertas T generan cualquier puerta de un solo cúbit:
$$H=\frac{1}{\sqrt{ 1 amp; 1 \\ 1 &-1 \end{bmatrix}, \qquad T=\begin{bmatrix} 1 & 0 0 \\ & e^{i\pi/4}\end{bmatrix}.&{2}}\begin{bmatrix} $$
En un equipo cuántico, las puertas cuánticas se pueden clasificar en dos categorías: puertas clifford y puertas que no son clifford, en este caso, la puerta T. Los programas cuánticos creados solo a partir de puertas de Clifford se pueden simular de forma eficaz mediante un equipo clásico y, por lo tanto, se requieren puertas que no sean Clifford para obtener la ventaja cuántica. En muchos esquemas de corrección de errores cuánticos (QEC), las llamadas puertas Clifford son fáciles de implementar, es decir, requieren muy pocos recursos en términos de operaciones y cúbits para implementar tolerancia a errores, mientras que las puertas que no son Clifford son bastante costosas al requerir tolerancia a errores. En un conjunto de puertas cuánticas universales, la puerta T se usa normalmente como puerta que no es Clifford.
El conjunto estándar de puertas clifford de un solo cúbit, incluido de forma predeterminada en Q#, include
$$H=\frac{{1}{\sqrt{{2}}\begin{bmatrix} 1 & 1 \\ 1 &-1 \end{bmatrix} , \qquad S =\begin{bmatrix} 1 & 0 0 &\\ amp; i \end{bmatrix}= T^2, \qquad X=\begin{bmatrix} 0 & 1 1 \\& 0 \end{bmatrix}= HT^4H,$$
$$Y =0 amp; -i &\\ amp; 0 \end{bmatrix}=T^2HT^4 HT^6, \qquad Z=\begin{bmatrix}1&&\begin{bmatrix} 0 0\\& amp;1 \end{bmatrix}=T^4. $$
Junto con la puerta que no es Clifford (la puerta T), estas operaciones se pueden componer para aproximar cualquier transformación unitaria en un solo cúbit.
Generadores de T en el estimador de recursos de Azure Quantum
La preparación de la puerta T que no es Clifford es fundamental porque las otras puertas cuánticas no son suficientes para el cálculo cuántico universal. Para implementar operaciones que no sean Clifford para algoritmos a escala práctica, se requieren puertas T de baja tasa de errores (o estados T). Sin embargo, pueden ser difíciles de implementar directamente en cúbits lógicos y también pueden ser difíciles para algunos cúbits físicos.
En un equipo cuántico tolerante a errores, los estados T de baja tasa de errores necesarios se producen mediante una fábrica de destilación de estado T o una factoría de T para abreviar. Estas fábricas de T suelen implicar una secuencia de rondas de destilación, donde cada ronda toma muchos estados T ruidosos codificados en un código de distancia menor, los procesa mediante una unidad de destilación y genera menos estados T ruidosos codificados en un código de distancia mayor, con el número de rondas, unidades de destilación y distancias que todos los parámetros pueden variar. Este procedimiento se itera, donde los estados T de salida de una ronda se introducen en la siguiente ronda como entradas.
En función de la duración de la factoría de T, el estimador de recursos de Azure Quantum determina la frecuencia con la que se puede invocar una factoría de T antes de que supere el tiempo de ejecución total del algoritmo y, por tanto, cuántos estados T se pueden generar durante el tiempo de ejecución del algoritmo. Normalmente, se requieren más estados T que lo que se puede producir dentro de las invocaciones de un único generador de T durante el tiempo de ejecución del algoritmo. Para generar más estados de T, el estimador de recursos usa copias de las factorías de T.
Estimación física de fábrica de T
El estimador de recursos calcula el número total de estados de T necesarios para ejecutar el algoritmo y el número de cúbits físicos para un único generador de T y su tiempo de ejecución.
El objetivo es generar todos los estados de T dentro del entorno de ejecución del algoritmo con lo menos copias de fábrica de T posibles. En el diagrama siguiente se muestra un ejemplo del tiempo de ejecución del algoritmo y el tiempo de ejecución de una factoría de T. Puede ver que el tiempo de ejecución de la factoría de T es más corto que el tiempo de ejecución del algoritmo. En este ejemplo, una fábrica de T puede destilar un estado T. Surgen dos preguntas:
- ¿Con qué frecuencia se puede invocar el generador de T antes del final del algoritmo?
- ¿Cuántas copias de la ronda de destilación de fábrica de T son necesarias para crear el número de estados T necesarios durante el tiempo de ejecución del algoritmo?
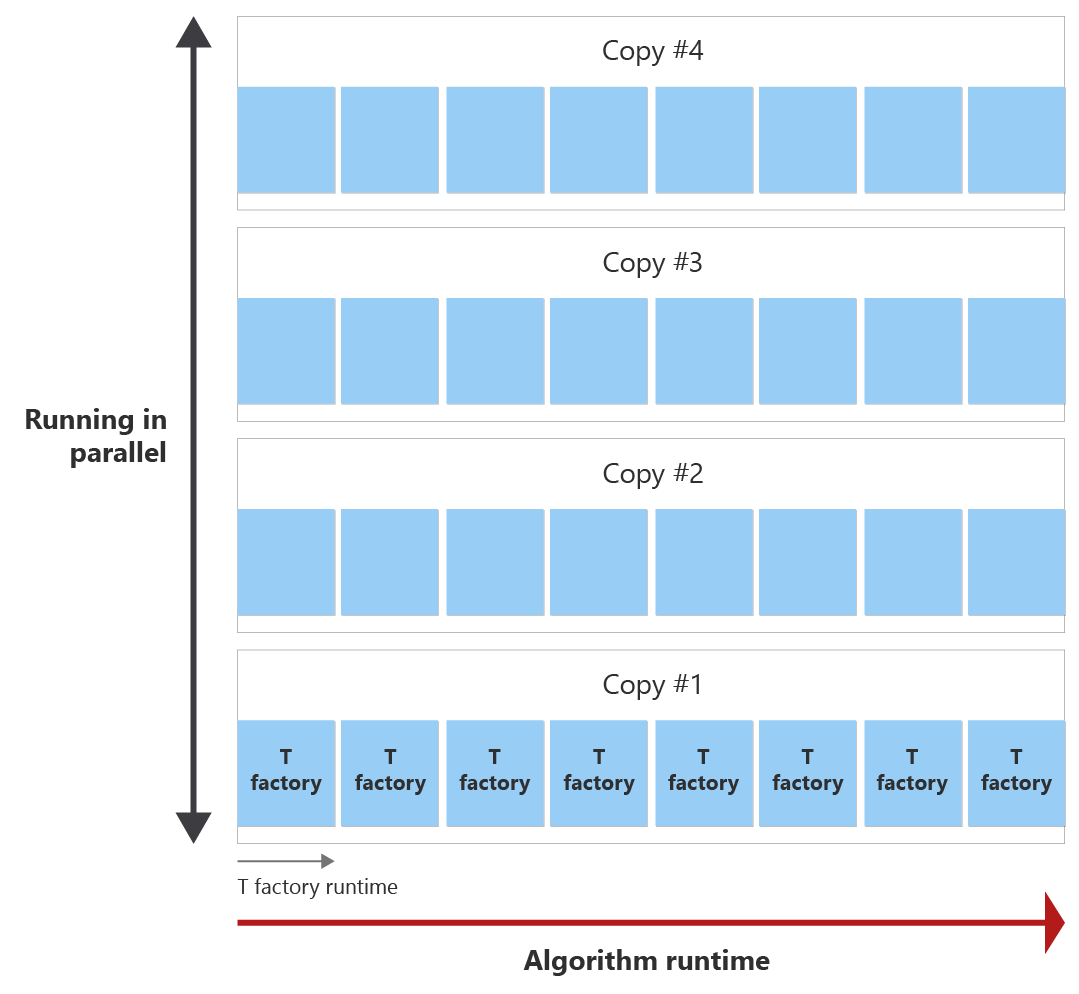
Antes del final del algoritmo, se puede invocar la factoría T ocho veces, que se denomina ronda de destilación. Por ejemplo, si necesita 30 estados T, se invoca una única factoría de T ocho veces durante el tiempo de ejecución del algoritmo y, por tanto, crea ocho estados T. A continuación, necesita cuatro copias de la ronda de destilación de fábrica T en paralelo para destilar los 30 estados T necesarios.
Nota:
Tenga en cuenta que las copias de fábrica de T y las invocaciones de fábrica de T no son las mismas.
Las fábricas de destilación de estado T se implementan en una secuencia de rondas, donde cada ronda consta de un conjunto de copias de unidades de destilación que se ejecutan en paralelo. El estimador de recursos calcula cuántos cúbits físicos se necesitan para ejecutar un generador de T y durante cuánto tiempo se ejecuta la factoría de T, entre otros parámetros necesarios.
Solo puede realizar invocaciones completas de un generador de T. Por lo tanto, puede haber situaciones en las que el tiempo de ejecución acumulado de todas las invocaciones de generador de T sea menor que el tiempo de ejecución del algoritmo. Dado que los cúbits se reutilizan por diferentes rondas, el número de cúbits físicos para un generador de T es el número máximo de cúbits físicos usados para una ronda. El tiempo de ejecución de la factoría de T es la suma del tiempo de ejecución en todas las rondas.
Nota:
Si la tasa de errores de puerta de T física es inferior a la tasa de errores de estado T lógico necesaria, el estimador de recursos no puede realizar una buena estimación de recursos. Al enviar un trabajo de estimación de recursos, es posible que encuentre que no se encuentra el generador de T porque la tasa de errores de estado T lógica necesaria es demasiado baja o demasiado alta.
Para obtener más información, vea apéndice C de evaluación de los requisitos para escalar a ventaja cuántica práctica.