Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo, obtendrá información sobre cómo configurar un indizador de archivos de OneLake para extraer datos y metadatos que se pueden buscar desde un almacén de lago encima de OneLake.
Para configurar y ejecutar el indexador, puede usar:
- API REST 2024-05-01-preview o una API REST en versión preliminar más reciente.
- Un paquete beta del SDK de Azure que proporciona la característica.
- Asistente para importar datos en Azure Portal.
- Asistente para importar y vectorizar datos en Azure Portal.
En este artículo se usan las API de REST para ilustrar cada paso.
Requisitos previos
Un área de trabajo de Fabric. Siga este tutorial para crear un área de trabajo de Fabric.
Un almacén de lago en un área de trabajo de Fabric. Siga este tutorial para crear un almacén de lago.
Datos textuales. Si tiene datos binarios, puede usar el análisis de imágenes de enriquecimiento con IA para extraer texto o generar descripciones de imágenes. El contenido del archivo no puede superar los límites del indizador para el nivel de servicio de búsqueda.
Contenido en la ubicación Archivos del almacén de lago. Puede agregar datos mediante:
- Carga directa en un almacén de lago
- Uso de canalizaciones de datos desde Microsoft Fabric
- Adición de accesos directos desde orígenes de datos externos, como Amazon S3 o Google Cloud Storage.
Un servicio Search AI configurado para una identidad administrada por el sistema o una identidad administrada asignada por el usuario. El servicio Search AI debe residir en el mismo inquilino que el área de trabajo de Microsoft Fabric.
Asignación del rol Colaborador en el área de trabajo de Microsoft Fabric donde se encuentra el almacén de lago. Los pasos se describen en la sección Conceder permisos de este artículo.
Un cliente de REST para formular llamadas REST similares a las que se muestran en este artículo.
Tareas admitidas
Puede usar este indexador para las siguientes tareas:
- Indexación de datos e indexación incremental: el indizador puede indexar archivos y metadatos asociados desde rutas de acceso de datos dentro de un almacén de lago. Detecta archivos y metadatos nuevos y actualizados a través de la detección de cambios integrada. Puede configurar la actualización de datos según una programación o a petición.
- Detección de eliminación: el indizador puede detectar eliminaciones a través de metadatos personalizados para la mayoría de los archivos y accesos directos. Esto requiere agregar metadatos a los archivos para indicar que se han "eliminado temporalmente", lo que permite su eliminación del índice de búsqueda. Actualmente, no es posible detectar eliminaciones en Google Cloud Storage o archivos de acceso directo de Amazon S3 porque no se admiten metadatos personalizados para esos orígenes de datos.
- Inteligencia artificial aplicada mediante conjuntos de aptitudes: los Conjuntos de aptitudes son totalmente compatibles con el indexador de archivos de OneLake. Aquí se incluyen características clave como la vectorización integrada que agrega los pasos de fragmentación e inserción de datos.
- Modos de análisis: el indizador admite modos de análisis JSON si desea analizar matrices o líneas JSON en documentos de búsqueda individuales. También admite el modo de análisis de Markdown.
- Compatibilidad con otras características: el indizador de OneLake está diseñado para funcionar sin problemas con otras características del indizador, como sesiones de depuración, caché del indizador para enriquecimientos incrementales y almacén de conocimiento.
Formatos de documento admitidos
El indizador de archivos de OneLake puede extraer texto de los siguientes formatos de documento:
- CSV (consulte Indexación de blobs CSV)
- EML
- EPUB
- GZ
- HTML
- JSON (vea Indexación de blobs JSON)
- KML (XML para representaciones geográficas)
- Formatos de Microsoft Office: DOCX/DOC/DOCM, XLSX/XLS/XLSM, PPTX/PPT/PPTM, MSG (correos electrónicos de Outlook), XML (WORD XML 2003 y 2006)
- Formatos de Open Document: ODT, ODS, ODP
- Archivos de texto sin formato (vea también Indexing plain text (Indexación de texto sin formato))
- RTF
- XML
- archivo ZIP / código postal
Accesos directos admitidos
Los siguientes accesos directos de OneLake son compatibles con el indizador de archivos de OneLake:
Acceso directo de OneLake (un acceso directo a otra instancia de OneLake)
Limitaciones de esta versión preliminar
Actualmente no se admiten tipos de archivo Parquet (incluido delta parquet).
No se admite la eliminación de archivos para los accesos directos de Amazon S3 y Google Cloud Storage.
Este indizador no admite el contenido de la ubicación de la tabla del área de trabajo de OneLake.
Este indizador no admite consultas SQL, pero la consulta que se usa en la configuración del origen de datos es exclusivamente para agregar de manera opcional la carpeta o el acceso directo al acceso.
No hay compatibilidad con la ingesta de archivos del área de trabajo de Mi área de trabajo en OneLake, ya que se trata de un repositorio personal por usuario.
Preparación de los datos para la indexación
Antes de configurar la indexación, revise los datos de origen para determinar si los cambios deben realizarse por adelantado. Un indexador puede indexar el contenido de un contenedor cada vez. De manera predeterminada, se procesan todos los archivos del contenedor. Tiene varias opciones para un procesamiento más selectivo:
Coloque los archivos en una carpeta virtual. Una definición de origen de datos del indizador incluye un parámetro "query" que puede ser una subcarpeta o un acceso directo del almacén de lago. Si se especifica este valor, solo se indexan los archivos de la subcarpeta o el acceso directo dentro del almacén de lago.
Incluir o excluir archivos por tipo de archivo. La lista de formatos de documento admitidos puede ayudarle a determinar qué archivos excluir. Por ejemplo, es posible que quiera excluir archivos de imagen o audio que no proporcionen texto que permite búsquedas. Esta funcionalidad se controla a través de los valores de configuración del indexador.
Incluya o excluya archivos arbitrarios. Si desea omitir un archivo específico por cualquier motivo, puede agregar propiedades y valores de metadatos a los archivos del almacén de lago de OneLake. Cuando un indizador encuentra esta propiedad, omite el archivo o su contenido en la ejecución de la indexación.
La inclusión y la exclusión de archivos se tratan en el paso de configuración del indizador. Si no establece criterios, el indizador notifica un archivo no válido como un error y se mueve hacia adelante. Si se producen errores suficientes, el procesamiento podría detenerse. Puede especificar tolerancia a errores en las opciones de configuración del indexador.
Normalmente, un indizador crea un documento de búsqueda por archivo, donde el contenido de texto y los metadatos se capturan como campos que admiten búsquedas en un índice. Si los archivos son archivos enteros, puede analizarlos en varios documentos de búsqueda. Por ejemplo, puede analizar las filas de un archivo CSV para crear un documento de búsqueda por fila. Si necesita fragmentar un único documento en pasajes más pequeños para vectorizar datos, considere la posibilidad de usar la vectorización integrada.
Indexación de metadatos de archivos
Los metadatos de archivo también se pueden indexar. Esto es útil si considera que cualquiera de las propiedades de metadatos estándar o personalizadas puede resultar útil para los filtros y las consultas.
Las propiedades de metadatos especificadas por el usuario se extraen textualmente. Para recibir los valores, debe definir el campo en el índice de búsqueda de tipo Edm.String con el mismo nombre que la clave de metadatos del blob. Por ejemplo, si un blob tiene una clave de metadatos de Priority con el valor High, debe definir un campo denominado Priority en el índice de búsqueda y se rellenará con el valor High.
Las propiedades de metadatos de archivo estándar se pueden extraer en campos con nombres y tipos similares, como se muestra a continuación. El indizador de archivos de OneLake crea automáticamente asignaciones de campos internas para estas propiedades de metadatos; para ello, convierte el nombre con guion original ("nombre-almacenamiento-metadatos") en un nombre equivalente con guiones bajos ("nombre_almacenamiento_metadatos").
Aún así, tendrá que agregar los campos con guiones bajos a la definición de índice, pero puede omitir las asignaciones de campos de indizador porque el indizador hará la asociación de manera automática.
metadata_storage_name (
Edm.String): nombre del archivo. Por ejemplo, si tiene un archivo /mydatalake/my-folder/subfolder/resume.pdf, el valor de este campo esresume.pdf.metadata_storage_path (
Edm.String): URI completo del blob, incluida la cuenta de almacenamiento. Por ejemplo:https://myaccount.blob.core.windows.net/my-container/my-folder/subfolder/resume.pdfmetadata_storage_content_type (
Edm.String): tipo de contenido tal como especifica el código que usó para cargar el blob. Por ejemplo,application/octet-stream.metadata_storage_last_modified (
Edm.DateTimeOffset): última marca de tiempo modificada del blob. Azure AI Search usa esta marca de tiempo para identificar los blobs modificados para evitar volver a indexar todo después de la indexación inicial.metadata_storage_size (
Edm.Int64): tamaño del blob en bytes.metadata_storage_content_md5 (
Edm.String): hash MD5 del contenido del blob, si está disponible.
Por último, las propiedades de metadatos específicas del formato de documento de los archivos que está indexando también se pueden representar en el esquema de índice. Para obtener más información sobre los metadatos específicos de contenido, vea Propiedades de metadatos de contenido.
Es importante señalar que no es necesario definir campos para todas las propiedades anteriores en el índice de búsqueda, capture solo las propiedades que necesita para la aplicación.
Concesión de permisos
El indizador de OneLake usa la autenticación de tokens y el acceso basado en roles para las conexiones a OneLake. Los permisos se asignan en OneLake. No hay requisitos de permisos en los almacenes de datos físicos que respaldan los accesos directos. Por ejemplo, si va a indexar desde AWS, no es necesario conceder permisos de servicio de búsqueda en AWS.
La asignación de roles mínima para la identidad de servicio de búsqueda es Colaborador.
Configure un sistema o una identidad administrada por el usuario para el servicio Search de IA.
En la captura de pantalla siguiente se muestra una identidad administrada por el sistema para un servicio de búsqueda denominado "onelake-demo".
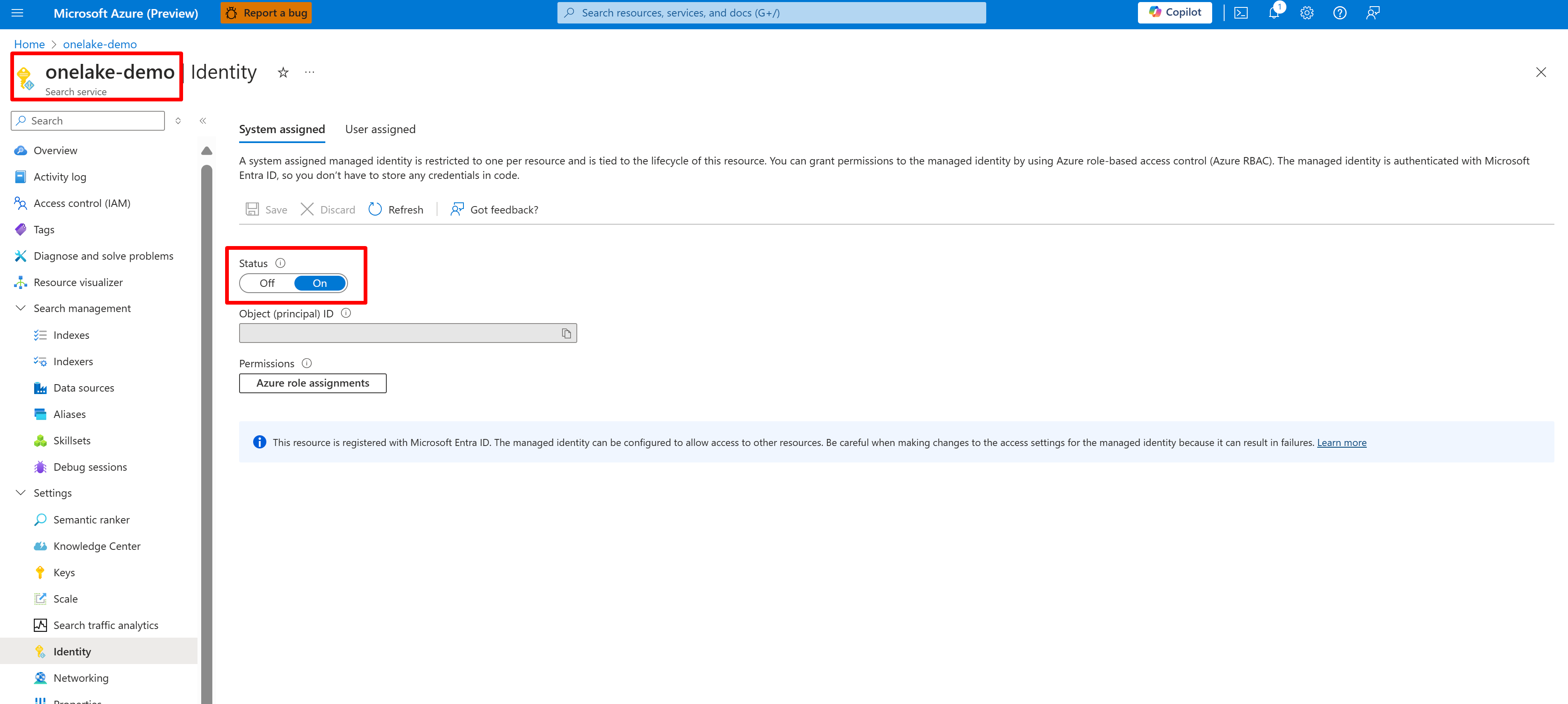
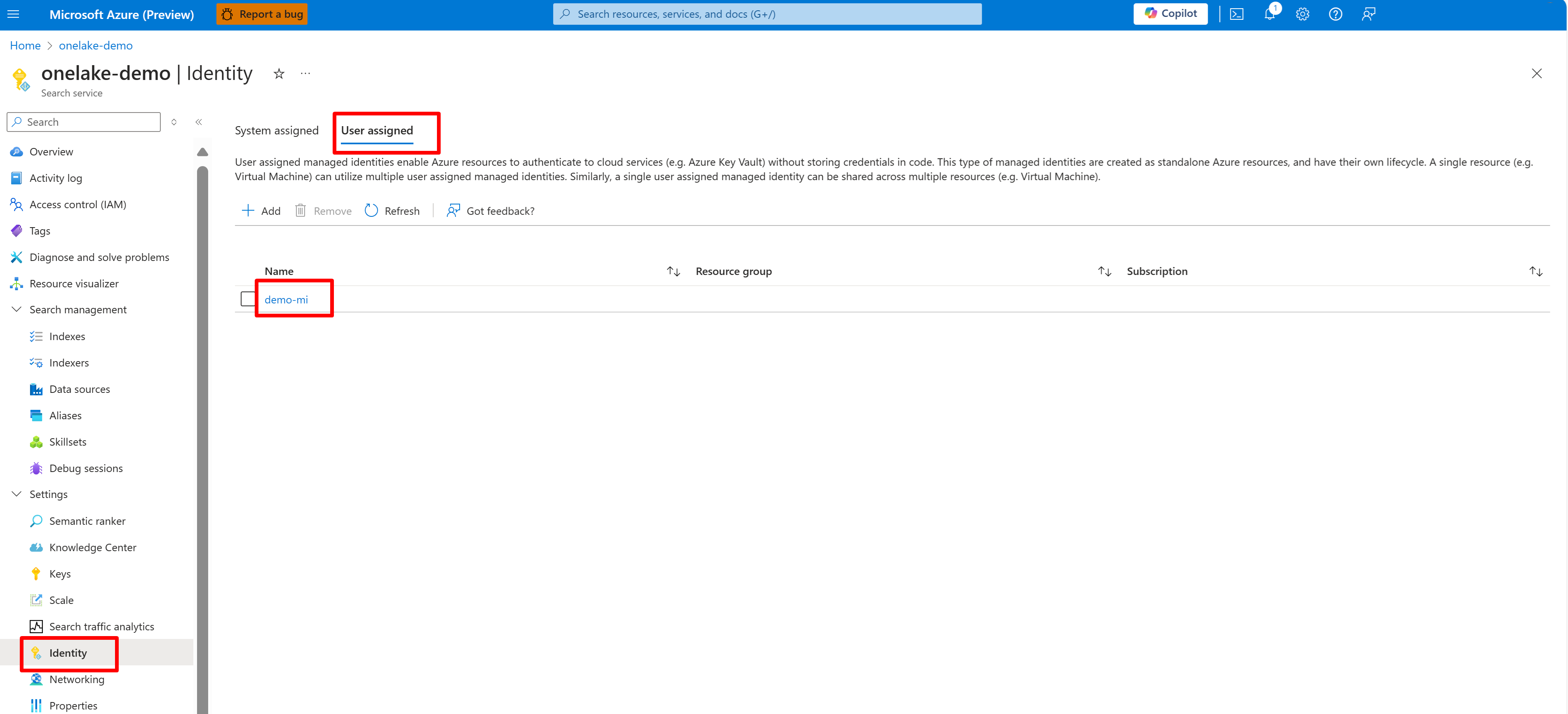
En esta captura de pantalla se muestra una identidad administrada por el usuario para el mismo servicio de búsqueda.
Conceda permiso para el acceso al servicio de búsqueda al área de trabajo de Fabric. El servicio de búsqueda realiza la conexión en nombre del indizador.
Si usa una identidad administrada asignada por el sistema, busque el nombre del servicio Search de IA. Para una identidad administrada asignada por el usuario, busque el nombre del recurso de identidad.
En la captura de pantalla siguiente se muestra una asignación de rol de Colaborador mediante una identidad administrada por el sistema.
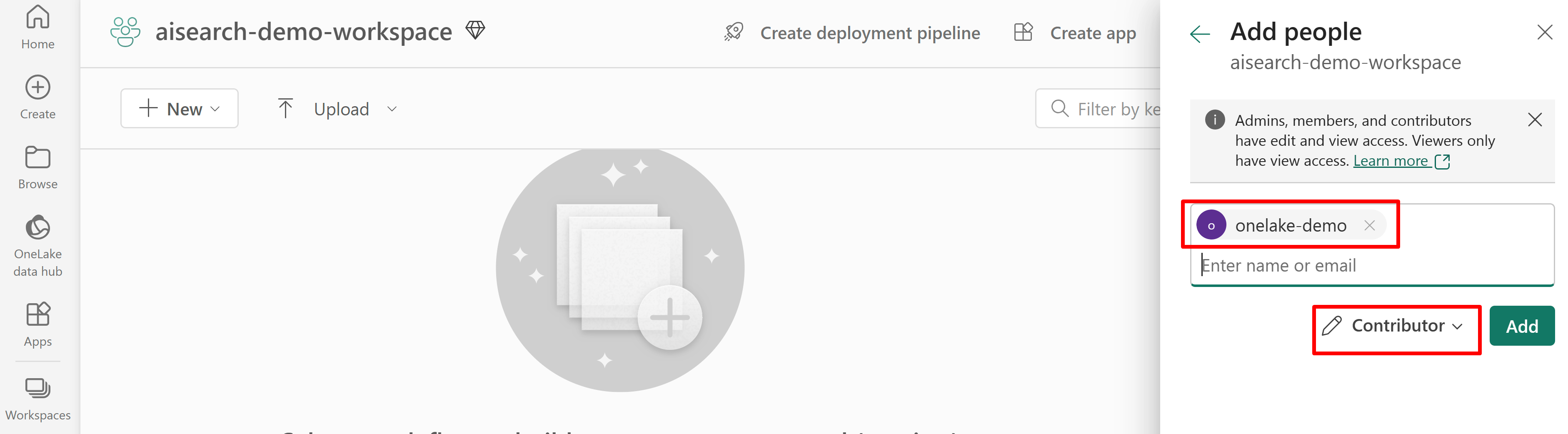
En esta captura de pantalla se muestra una asignación de roles de colaborador mediante una identidad administrada asignada por el usuario:





Definición del origen de datos
Un origen de datos se define como un recurso independiente de forma que puedan usarlo varios indexadores. Debe usar la API de REST 2024-05-01-preview para crear el origen de datos.
Use la API de REST Crear o actualizar un origen de datos para establecer su definición. Estos son los pasos más significativos de la definición.
Establezca
"type"en"onelake"(obligatorio).Obtenga el GUID del área de trabajo de Microsoft Fabric y el GUID del almacén de lago:
Vaya al almacén de lago desde el que le gustaría importar datos desde su dirección URL. Debe tener un aspecto similar a este ejemplo: "https://msit.powerbi.com/groups/00000000-0000-0000-0000-000000000000/lakehouses/11111111-1111-1111-1111-111111111111?experience=power-bi". Copie los siguientes valores que se usan en la definición del origen de datos:
Copie el GUID del área de trabajo, al que llamaremos
{FabricWorkspaceGuid}, que aparece justo después de "grupos" en la dirección URL. En este ejemplo, sería 00000000-0000-0000-0000-000000000000.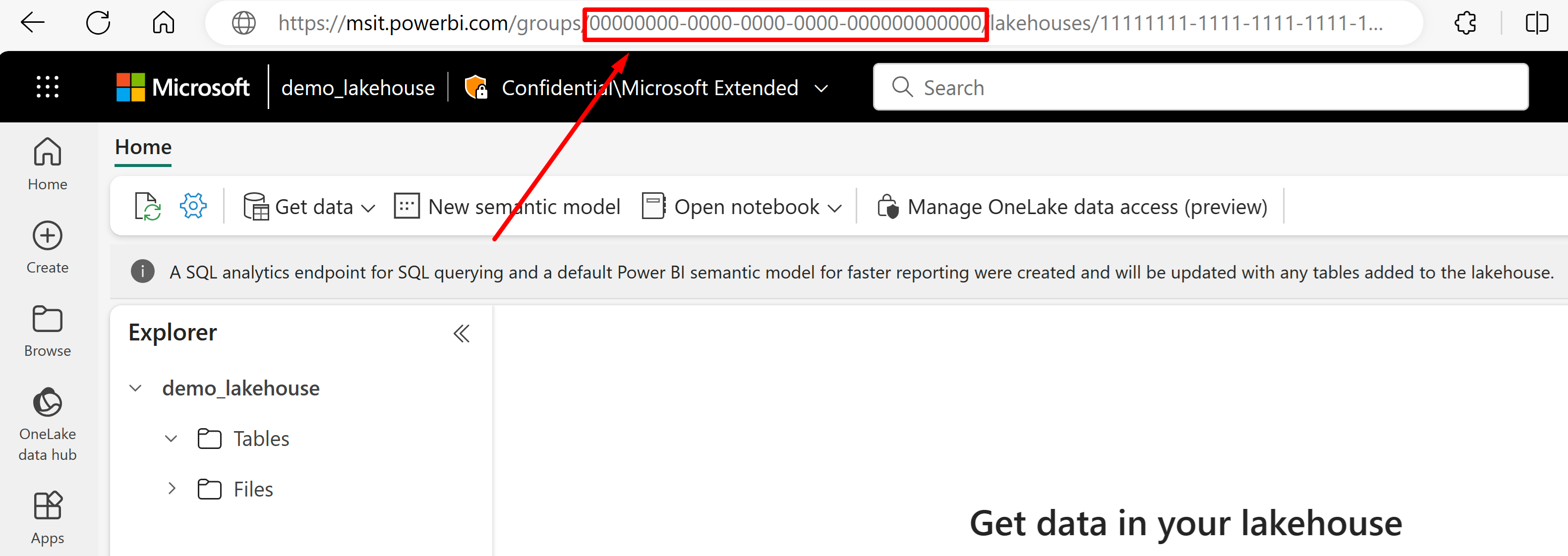
Copie el GUID del almacén de lago al que llamaremos
{lakehouseGuid}, que aparece justo después de "almacenes de lago" en la dirección URL. En este ejemplo, sería 11111111-1111-1111-1111-111111111111.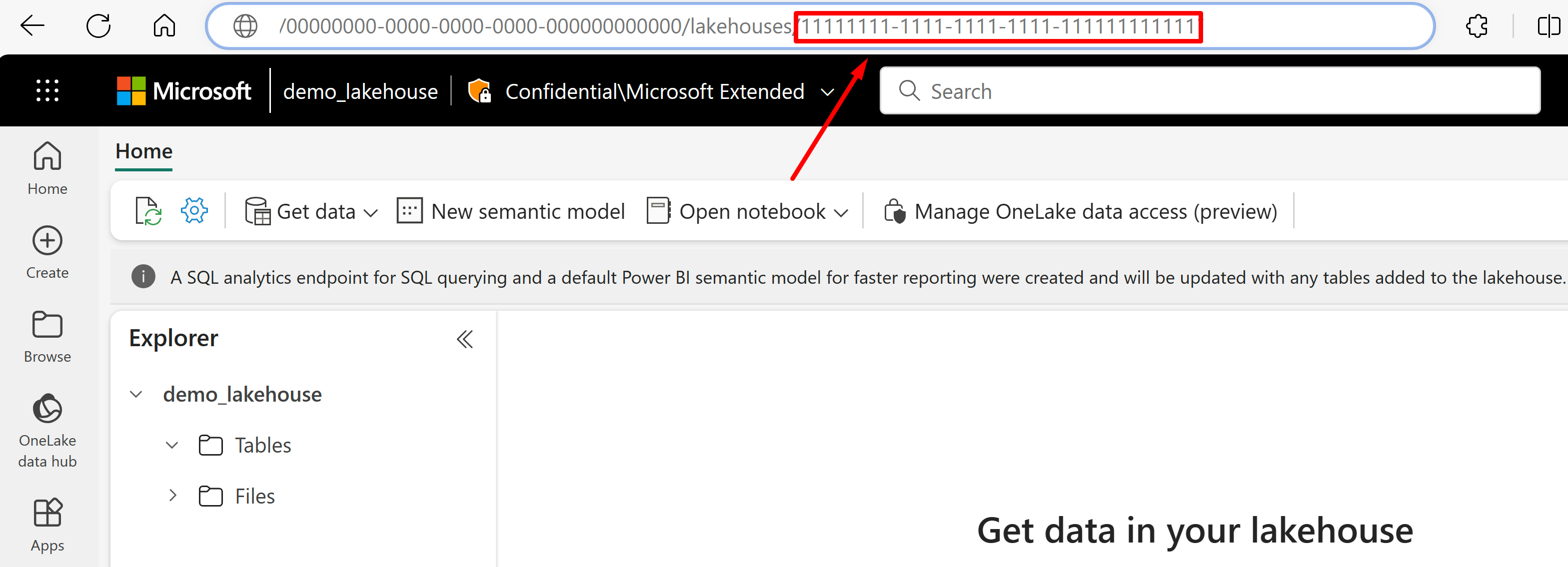
Establezca
"credentials"en el GUID del área de trabajo de Microsoft Fabric reemplazando{FabricWorkspaceGuid}por el valor que copió en el paso anterior. Esta es la instancia de OneLake a la que accederá con la identidad administrada que configurará más adelante en esta guía."credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }Establezca
"container.name"en el GUID del almacén de lago, reemplazando{lakehouseGuid}por el valor que copió en el paso anterior. Use"query"para especificar de manera opcional una subcarpeta o un acceso directo al almacén de lago."container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }Establezca el método de autenticación mediante la identidad administrada asignada por el usuario o vaya al paso siguiente para la identidad administrada por el sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "{userAssignedManagedIdentity}" } }El valor
userAssignedIdentityse puede encontrar accediendo al recurso{userAssignedManagedIdentity}en Propiedades y se denominaId.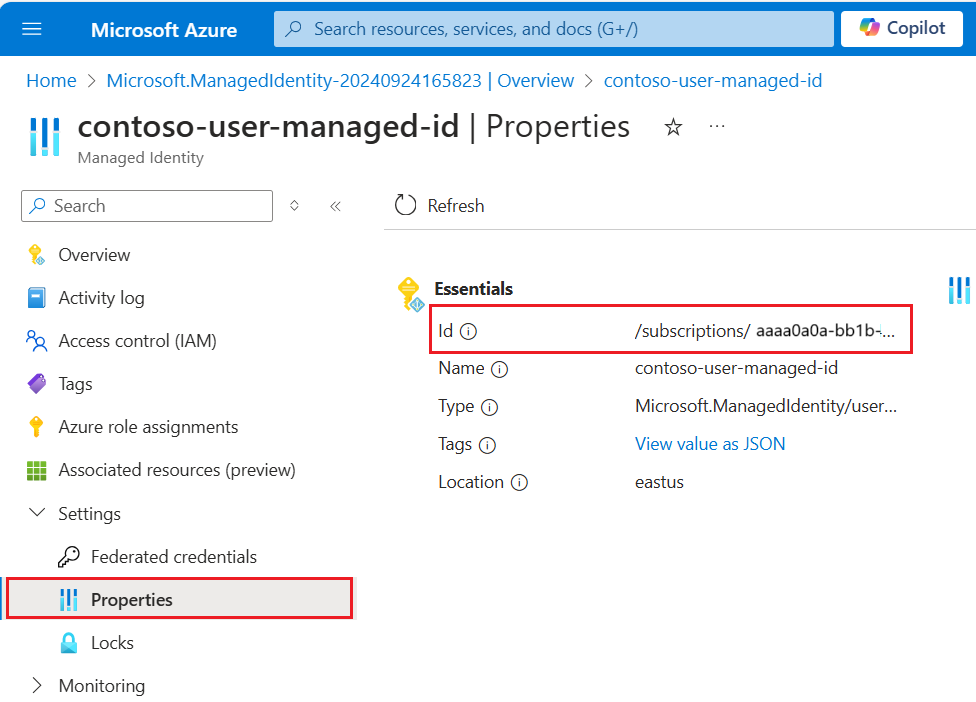
Ejemplo:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" }, "identity": { "@odata.type": "Microsoft.Azure.Search.DataUserAssignedIdentity", "userAssignedIdentity": "/subscriptions/333333-3333-3333-3333-33333333/resourcegroups/myresourcegroup/providers/Microsoft.ManagedIdentity/userAssignedIdentities/demo-mi" } }De manera opcional, use una identidad administrada asignada por el sistema en su lugar. La "identidad" se quita de la definición si se usa la identidad administrada asignada por el sistema.
{ "name": "{dataSourceName}", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" } }Ejemplo:
{ "name": "mydatasource", "description": "description", "type": "onelake", "credentials": { "connectionString": "ResourceId=a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1" }, "container": { "name": "11111111-1111-1111-1111-111111111111", "query": "folder_name" } }



Detección de eliminaciones mediante metadatos personalizados
La definición del origen de datos del indizador de archivos de OneLake puede incluir una directiva de eliminación temporal si quiere que el indizador elimine un documento de búsqueda cuando el documento de origen esté marcado para su eliminación.
Para habilitar la eliminación automática de archivos, use metadatos personalizados para indicar si se debe quitar un documento de búsqueda del índice.
El flujo de trabajo requiere tres acciones independientes:
- "Eliminación temporal" del archivo en OneLake
- El indizador elimina el documento de búsqueda en el índice
- "Eliminación permanente" del archivo en OneLake
La "eliminación temporal" le indica al indizador qué hacer (eliminar el documento de búsqueda). Si elimina primero el archivo físico en OneLake, no hay nada para que el indizador lea y el documento de búsqueda correspondiente en el índice está huérfano.
Hay pasos que se deben seguir tanto en OneLake como en Búsqueda de Azure AI, pero no hay otras dependencias de características.
En el archivo del almacén de lago, agregue un par clave-valor de metadatos personalizados al archivo para indicar que el archivo está marcado para su eliminación. Por ejemplo, podría asignar un nombre a la propiedad "IsDeleted", establecida en false. Si desea eliminar el archivo, cámbielo a true.

En Azure AI Search, edita la definición del origen de datos para incluir una propiedad "dataDeletionDetectionPolicy". Por ejemplo, la siguiente directiva considera que un archivo se va a eliminar si tiene una propiedad de metadatos "IsDeleted" con el valor true:
PUT https://[service name].search.windows.net/datasources/file-datasource?api-version=2024-05-01-preview { "name" : "onelake-datasource", "type" : "onelake", "credentials": { "connectionString": "ResourceId={FabricWorkspaceGuid}" }, "container": { "name": "{lakehouseGuid}", "query": "{optionalLakehouseFolderOrShortcut}" }, "dataDeletionDetectionPolicy" : { "@odata.type" :"#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy", "softDeleteColumnName" : "IsDeleted", "softDeleteMarkerValue" : "true" } }

Una vez que el indizador se ejecuta y elimina el documento del índice de búsqueda, puede eliminar el archivo físico en el lago de datos.
Entre los puntos clave se incluyen:
La programación de una ejecución de indizador ayuda a automatizar este proceso. Se recomiendan programaciones para todos los escenarios de indexación incremental.
Si la directiva de detección de eliminación no se estableció en la primera ejecución del indizador, debe restablecer el indizador para que lea la configuración actualizada.
Recuerde que la detección de eliminación no es compatible con los accesos directos de Amazon S3 y Google Cloud Storage debido a la dependencia de metadatos personalizados.
Adición de campos de búsqueda a un índice
En un índice de búsqueda, agregue campos para aceptar el contenido y los metadatos de los archivos de lago de datos de OneLake.
Cree o actualice un índice para definir los campos de búsqueda que almacenan el contenido y los metadatos del archivo:
{ "name" : "my-search-index", "fields": [ { "name": "ID", "type": "Edm.String", "key": true, "searchable": false }, { "name": "content", "type": "Edm.String", "searchable": true, "filterable": false }, { "name": "metadata_storage_name", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_size", "type": "Edm.Int64", "searchable": false, "filterable": true, "sortable": true }, { "name": "metadata_storage_content_type", "type": "Edm.String", "searchable": false, "filterable": true, "sortable": true } ] }Cree un campo de clave de documento ("key": true). Para el contenido del archivo, los mejores candidatos son las propiedades de metadatos.
metadata_storage_path(valor predeterminado) es la ruta de acceso completa al objeto o archivo. El campo de clave ("id." en este ejemplo) se rellena con valores de metadata_storage_path porque es el valor predeterminado.metadata_storage_nameutilizable solo si los nombres son únicos. Si desea que este campo sea la clave, pase"key": truea esta definición de campo.Propiedad de metadatos personalizada que se agrega a los archivos. Esta opción requiere que el proceso de carga de archivos agregue dicha propiedad de metadatos a todos los blobs. Dado que la clave es una propiedad obligatoria, todos los archivos a los que les falte un valor no se indexarán. Si usa una propiedad de metadatos personalizada como clave, evite realizar cambios en esa propiedad. Los indizadores agregan documentos duplicados para el mismo archivo si cambia la propiedad de clave.
Las propiedades de metadatos suelen incluir caracteres, como
/y-, que no son válidos para las claves de documento. Dado que el indexador tiene una propiedad "base64EncodeKeys" (true de manera predeterminada), codifica automáticamente la propiedad de metadatos, sin necesidad de configuración ni asignación de campos.Agregue un campo "content" para almacenar el texto extraído de cada archivo mediante la propiedad "content" del archivo. No es necesario usar este nombre, pero, si lo hace, podrá aprovechar las asignaciones de campos implícitas.
Agregue campos para las propiedades de metadatos estándar. El indexador puede leer propiedades de metadatos personalizadas, propiedades de metadatos estándar y propiedades de metadatos específicos de contenido.
Configuración y ejecución del indizador de archivos de OneLake
Después de crear el origen de datos y el índice, ya puede crear el indizador. La configuración del indexador especifica las entradas, los parámetros y las propiedades que controlan los comportamientos en tiempo de ejecución. También puede especificar qué partes de un blob se indexan.
Cree o actualice un indexador asignándole un nombre y haciendo referencia al origen de datos y al índice de destino:
{ "name" : "my-onelake-indexer", "dataSourceName" : "my-onelake-datasource", "targetIndexName" : "my-search-index", "parameters": { "batchSize": null, "maxFailedItems": null, "maxFailedItemsPerBatch": null, "base64EncodeKeys": null, "configuration": { "indexedFileNameExtensions" : ".pdf,.docx", "excludedFileNameExtensions" : ".png,.jpeg", "dataToExtract": "contentAndMetadata", "parsingMode": "default" } }, "schedule" : { }, "fieldMappings" : [ ] }Establezca "batchSize" si el valor predeterminado (10 documentos) infrautiliza o sobreutiliza los recursos disponibles. Los tamaños de lote predeterminados son específicos para cada origen de datos. La indexación de archivos establece el tamaño de lote en 10 documentos en reconocimiento al tamaño máximo medio de los documentos.
En "configuration", controle qué archivos se indexan en función del tipo de archivo o deje sin especificar para recuperar todos los archivos.
En
"indexedFileNameExtensions", proporcione una lista separada por comas de extensiones de archivo (con un punto inicial). Haga lo mismo con"excludedFileNameExtensions"para indicar qué extensiones se deben omitir. Si la misma extensión se encontrase en ambas listas, se excluirá de la indexación.En "configuration", establezca "dataToExtract" para controlar qué partes de los archivos se indexan:
"contentAndMetadata" es el valor predeterminado. Especifica que se indexan todos los metadatos y el contenido textual extraído del archivo.
"storageMetadata" especifica que solamente se indexan las propiedades de archivo estándar y los metadatos especificados por el usuario. Aunque las propiedades se documentan para blobs de Azure, las propiedades del archivo son las mismas para OneLkae, excepto para los metadatos relacionados con SAS.
"allMetadata" especifica que las propiedades de archivo estándar y los metadatos para los tipos de contenido encontrados se extraen del contenido del archivo y se indexan.
En "configuration", establezca "parsingMode" si los archivos deben asignarse a varios documentos de búsqueda o si constan de texto sin formato, documentos JSON o archivos CSV.
Especifique asignaciones de campos si hay diferencias en el nombre o el tipo de campo, o si necesita varias versiones de un campo de origen en el índice de búsqueda.
En la indexación de archivos, a menudo puede omitir las asignaciones de campos porque el indexador tiene compatibilidad integrada para asignar las propiedades "content" y de metadatos a campos con nombre y tipo similares en un índice. En el caso de las propiedades de metadatos, el indizador reemplaza automáticamente los guiones
-por guiones bajos en el índice de búsqueda.
Consulte Creación de un indizador para obtener más información sobre otras propiedades. Para obtener la lista completa de descripciones de parámetros, consulte Crear indexador (REST) en la API de REST. Los parámetros son los mismos para OneLake.
De manera predeterminada, un indizador se ejecuta automáticamente al crearlo. Puede cambiar este comportamiento estableciendo "disabled" en true. Para controlar la ejecución del indexador, ejecute un indexador a petición o prográmelo.
Comprobación del estado del indexador
Obtenga información sobre varios enfoques para supervisar el estado del indizador y el historial de ejecución aquí.
Control de errores
Los errores que suelen producirse durante la indexación incluyen tipos de contenido no admitidos, contenido que falta o archivos demasiado grandes. De manera predeterminada, el indizador de archivos de OneLake se detiene en cuanto encuentra un archivo con un tipo de contenido no admitido. Sin embargo, es posible que quiera realizar la indexación para continuar aunque se produzcan errores y, a continuación, depurar documentos concretos posteriormente.
Los errores transitorios son comunes para las soluciones que implican varias plataformas y productos. Sin embargo, si mantiene el indizador según una programación (por ejemplo, cada 5 minutos), el indizador debería poder recuperarse de esos errores en la ejecución siguiente.
Hay cinco propiedades de indexador que controlan la respuesta de este cuando se producen errores.
{
"parameters" : {
"maxFailedItems" : 10,
"maxFailedItemsPerBatch" : 10,
"configuration" : {
"failOnUnsupportedContentType" : false,
"failOnUnprocessableDocument" : false,
"indexStorageMetadataOnlyForOversizedDocuments": false
}
}
}
| Parámetro | Valores válidos | Descripción |
|---|---|---|
| "maxFailedItems" | -1, nulo o 0, entero positivo | Continue con la indexación si se producen errores en cualquier punto del procesamiento, mientras se analizan blobs o se agregan documentos a un índice. Establezca estas propiedades en el número de errores aceptables. Un valor de -1 permite el procesamiento, independientemente del número de errores que se produzcan. De lo contrario, el valor es un entero positivo. |
| "maxFailedItemsPerBatch" | -1, nulo o 0, entero positivo | Igual que antes, pero se usa para la indexación por lotes. |
| "failOnUnsupportedContentType" | true o false | Si el indexador no puede determinar el tipo de contenido, especifique si quiere continuar o no el trabajo. |
| "failOnUnprocessableDocument" | true o false | Si el indexador no puede procesar un documento de otro tipo de contenido admitido, especifique si quiere continuar o no el trabajo. |
| "indexStorageMetadataOnlyForOversizedDocuments" | true o false | Los blobs demasiado grandes se tratan como errores de forma predeterminada. Si establece este parámetro en true, el indizador intenta indexar sus metadatos aunque el contenido no se pueda indexar. Si quiere obtener información acerca de los límites de tamaño de los blobs, consulte los límites de servicio. |
Pasos siguientes
Revise cómo funciona el Asistente para importar y vectorizar datos y pruébelo para este indizador. Puede usar la vectorización integrada para fragmentar y crear incrustaciones para la búsqueda vectorial o híbrida mediante un esquema predeterminado.