Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Los vectores son incrustaciones multidimensionales que representan texto, imágenes y otro contenido matemáticamente. Búsqueda de Azure AI almacena vectores en el nivel de campo, lo que permite que el contenido vectorial y no vector coexista dentro del mismo índice search.
Un índice de búsqueda se convierte en un índice vectorial al definir campos vectoriales y una configuración de vector. Para rellenar los campos vectoriales, puede insertar incrustaciones precalculadas en ellas o usar vectorización integrada, una funcionalidad de Búsqueda de Azure AI integrada que genera incrustaciones durante la indexación.
En el momento de la consulta, los campos vectoriales del índice permiten la búsqueda de similitud, donde el sistema recupera documentos cuyos vectores son más similares a la consulta vectorial. Puede usar la búsqueda de vectores para buscar coincidencias de similitud solas o híbridas para una combinación de similitud y coincidencia de palabras clave.
En este artículo se describen los conceptos clave para crear y administrar un índice vectorial, entre los que se incluyen:
- Patrones de recuperación de vectores
- Contenido (campos vectoriales y configuración)
- Estructura de datos físicos
- Operaciones Básico
Sugerencia
¿Quieres empezar de inmediato? Consulte Creación de un índice vectorial.
Patrones de recuperación de vectores
Búsqueda de Azure AI admite dos patrones para la recuperación de vectores:
Búsqueda clásica. Este patrón usa una barra de búsqueda, una entrada de consulta y resultados representados. Durante la ejecución de la consulta, el motor de búsqueda o el código de la aplicación vectoriza la entrada del usuario. A continuación, el motor de búsqueda realiza la búsqueda vectorial sobre los campos vectoriales del índice y formula una respuesta que se representa en una aplicación cliente.
En Búsqueda de Azure AI, los resultados se devuelven como un conjunto de filas aplanado y puede elegir qué campos incluir en la respuesta. Aunque el motor de búsqueda funciona con vectores, el índice debe tener contenido no vectorial y legible para poblar los resultados de la búsqueda. La búsqueda clásica admite consultas vectoriales y consultas híbridas.
Búsqueda generativa. Los modelos de lenguaje usan datos de Búsqueda de Azure AI para responder a las consultas de usuario. Normalmente, una capa de orquestación coordina los mensajes y mantiene el contexto, lo que alimenta los resultados de búsqueda en modelos de chat como GPT. Este patrón se basa en la arquitectura de generación aumentada de recuperación (RAG), donde el índice de búsqueda proporciona datos de base.
Esquema de un índice vectorial
El esquema de un índice vectorial requiere lo siguiente:
- Nombre
- Campo de clave (cadena)
- Uno o varios campos vectoriales
- Configuración de vectores
Los campos no vectores no son obligatorios, pero se recomienda incluirlos para consultas híbridas o para devolver contenido textual que no pasa por un modelo de lenguaje. Para obtener más información, consulte Creación de un índice de vectores.
El esquema de índice debe reflejar el patrón de recuperación de vectores. En esta sección se trata principalmente la composición de campos para la búsqueda clásica, pero también proporciona instrucciones de esquema para la búsqueda generativa.
Configuración Básico de campos vectoriales
Los campos vectoriales tienen propiedades y tipos de datos únicos. Este es el aspecto de un campo vectorial en una colección de campos:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
Solo se admiten determinados tipos de datos para los campos vectoriales. El tipo más común es Collection(Edm.Single), pero el uso de tipos estrechos puede ahorrar en el almacenamiento.
Los campos vectoriales deben ser buscables y recuperables, pero no pueden filtrarse, ser facetables ni ordenar. Tampoco pueden tener analizadores, normalizadores ni asignaciones de mapa de sinónimos.
La dimensions propiedad debe establecerse en el número de incrustaciones generadas por el modelo de inserción. Por ejemplo, text-embedding-ada-002 genera 1 536 incrustaciones para cada fragmento de texto.
Los campos vectoriales se indexan mediante algoritmos especificados en un perfil de búsqueda vectorial, que se define en otra parte del índice y no se muestra en este ejemplo. Para obtener más información, vea Agregar una configuración de búsqueda vectorial.
Colección de campos para cargas de trabajo vectoriales básicas
Los índices vectoriales requieren más que solo campos vectoriales. Por ejemplo, todos los índices deben tener un campo de clave, que se encuentra id en el ejemplo siguiente:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
Otros campos, como el content campo, proporcionan el equivalente legible del content_vector campo. Si usa modelos de lenguaje exclusivamente para la formulación de respuestas, puede omitir campos de contenido no vector, pero las soluciones que insertan resultados de búsqueda directamente en las aplicaciones cliente deben tener contenido no vector.
Los campos de metadatos son útiles para los filtros, especialmente si incluyen información de origen sobre el documento de origen. Aunque no puede filtrar directamente en un campo vectorial, puede establecer los modos de prefiltro, postfiltro o postfiltro estricto (vista previa) para filtrar antes o después de la ejecución de la consulta vectorial.
Esquema generado por el asistente de importación
Le recomendamos que use el asistente Importar datos para la evaluación y las pruebas de concepto. El asistente genera el esquema de ejemplo en esta sección.
El asistente fragmenta el contenido en documentos de búsqueda más pequeños, lo que beneficia a las aplicaciones RAG que usan modelos de lenguaje para formular respuestas. La fragmentación le ayuda a mantenerse dentro de los límites de entrada de los modelos de lenguaje y los límites de token del clasificador semántico. También mejora la precisión en la búsqueda de similitud mediante la coincidencia de consultas con fragmentos extraídos de varios documentos primarios. Para obtener más información, consulte Dividir documentos grandes para soluciones de búsqueda de vectores.
Para cada documento de búsqueda del ejemplo siguiente, hay un identificador de fragmento, un identificador primario, un fragmento, un título y un campo vectorial. El asistente:
Rellena los campos
chunk_idyparent_idcon metadatos de blob codificados en base64 (ruta de acceso).Extrae los campos
chunkdel contenido del blob ytitledel nombre del blob, respectivamente.Crea el campo
vectorllamando a un modelo de incrustación de Azure OpenAI que usted proporciona para vectorizar el campochunk. Solo se genera completamente el campo vectorial durante este proceso.
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
Esquema para la búsqueda generativa
Si va a diseñar el almacenamiento de vectores para aplicaciones RAG y de estilo de chat, puede crear dos índices:
- Uno para el contenido estático que indexó y vectorizó.
- Una para las conversaciones que se pueden usar en los flujos de indicaciones.
Para fines ilustrativos, en esta sección se usa el chat-with-your-data-solution-accelerator para crear los índices chat-index y conversations.
Los campos siguientes de chat-index admiten experiencias de búsqueda generativas:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
Los siguientes campos de conversations admiten la orquestación y el historial de chat:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
En la captura de pantalla siguiente se muestran los resultados de búsqueda de conversations en el Explorador de búsqueda:
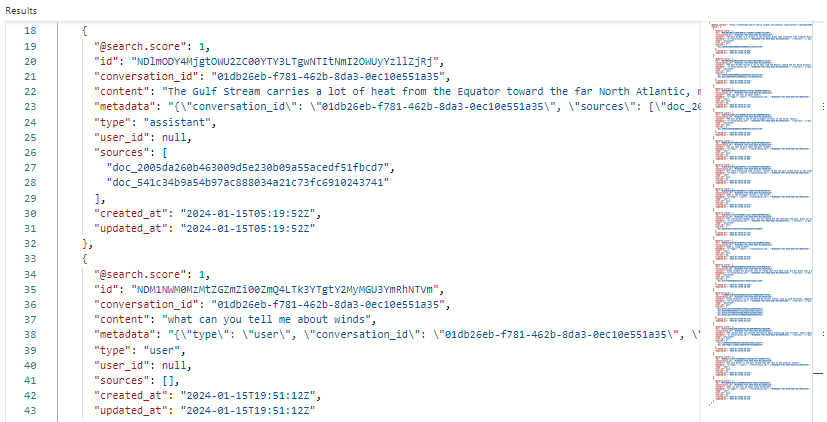
En nuestro ejemplo, la puntuación de búsqueda es 1.00 porque la búsqueda no está calificada. Varios campos admiten la orquestación y los flujos de mensajes:
-
conversation_ididentifica cada sesión de chat. -
typeindica si el contenido procede del usuario o del asistente. -
created_atyupdated_atse agota la edad de los chats de la historia.
Estructura física y tamaño
En Búsqueda de Azure AI, la estructura física de un índice es en gran medida una implementación interna. Puede acceder a su esquema, cargar y consultar su contenido, supervisar su tamaño y administrar su capacidad. Sin embargo, Microsoft administra la infraestructura y las estructuras de datos físicas almacenadas con el servicio de búsqueda.
El tamaño y la sustancia de un índice están determinados por:
Cantidad y composición de los documentos.
Atributos en campos individuales. Por ejemplo, se requiere más almacenamiento para los campos que se pueden filtrar.
Configuración del índice, incluida la configuración de vector que especifica cómo se crean las estructuras de navegación internas. Puede elegir HNSW o KNN exhaustivo para la búsqueda de similitud.
Búsqueda de Azure AI impone límites en el almacenamiento vectorial, lo que ayuda a mantener un sistema equilibrado y estable para todas las cargas de trabajo. Para ayudarle a mantenerse dentro de los límites, se supervisa el uso de vectores y se informa por separado en el portal de Azure y programáticamente a través de estadísticas de servicio e índice.
En el recorte de pantalla siguiente se muestra un servicio S1 configurado con una partición y una réplica. Este servicio tiene 24 índices pequeños, cada uno con un promedio de un campo vectorial que consta de 1536 incrustaciones. En el segundo icono se muestra la cuota y el uso de los índices vectoriales. Dado que un índice vectorial es una estructura de datos interna creada para cada campo vectorial, el almacenamiento de los índices vectoriales siempre es una fracción del almacenamiento general utilizado por el índice. Los campos no vectores y otras estructuras de datos consumen el resto.
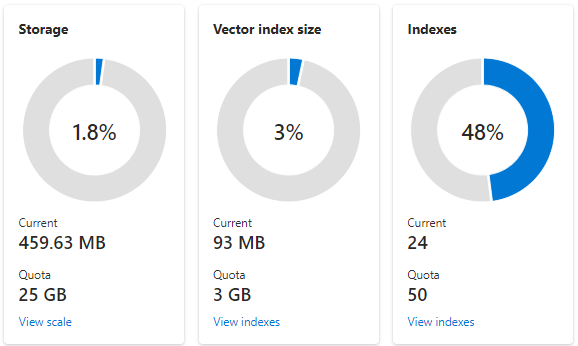
Los límites y estimaciones del índice de vectores se tratan en otro artículo, pero dos puntos a destacar son que el almacenamiento máximo depende de la fecha de creación y el plan de tarifa del servicio de búsqueda. Los servicios de mismo nivel más recientes tienen bastante más capacidad para los índices vectoriales. Por estos motivos, usted debe:
Compruebe la fecha de creación del servicio de búsqueda. Si se creó antes del 3 de abril de 2024, es posible que pueda actualizar el servicio para mayor capacidad.
Elegir un nivel escalable si prevé fluctuaciones en los requisitos de almacenamiento vectorial. En el caso de los servicios de búsqueda más antiguos, el nivel Básico se fija en una partición. Considere el estándar 1 (S1) y versiones posteriores para obtener más flexibilidad y un rendimiento más rápido. También puede cambiar entre los niveles Básico y Estándar (S1, S2 y S3).
Operaciones básicas e interacción
En esta sección se presentan las operaciones de tiempo de ejecución de vectores, incluida la conexión a y la protección de un único índice.
Nota
No hay compatibilidad con el portal ni la API para mover o copiar un índice. Normalmente, apuntas la implementación de la aplicación a un servicio de búsqueda diferente (usando el mismo nombre de índice) o modificas el nombre para crear una copia en el servicio de búsqueda actual y, a continuación, construirla.
Aislamiento de índice
En Búsqueda de Azure AI, trabajas con un índice a la vez. Todas las operaciones relacionadas con el índice tienen como destino un único índice. No hay ningún concepto de índices relacionados ni unión de índices independientes para la indexación o la consulta.
Disponibilidad continua
Un índice está disponible inmediatamente para las consultas en cuanto se indexa el primer documento, pero no está totalmente operativo hasta que se indexan todos los documentos. Internamente, un índice se distribuye entre las particiones y se ejecuta en las réplicas. El índice físico se administra internamente. Tú administras el índice lógico.
Un índice está disponible continuamente y no se puede pausar ni desconectar. Dado que está diseñado para la operación continua, las actualizaciones de su contenido y las adiciones al propio índice se producen en tiempo real. Si una solicitud coincide con una actualización del documento, las consultas podrían devolver temporalmente resultados incompletos.
La continuidad de las consultas existe para las operaciones de documento, como actualizar o eliminar, y para las modificaciones que no afectan a la estructura o integridad existentes de un índice, como agregar nuevos campos. Las actualizaciones estructurales, como cambiar los campos existentes, normalmente se administran mediante un flujo de trabajo de eliminación y recompilación en un entorno de desarrollo o mediante la creación de una nueva versión del índice en el servicio de producción.
Para evitar una reconstrucción del índice, algunos usuarios que realizan pequeños cambios actualizan un campo creando una nueva versión que coexiste con una versión anterior. Con el tiempo, esto conduce a contenido huérfano mediante campos obsoletos y definiciones de analizador personalizadas obsoletas, especialmente en un índice de producción que es costoso de replicar. Puede solucionar estos problemas durante las actualizaciones planeadas en el índice como parte de la administración del ciclo de vida del índice.
Conexión de punto de conexión
Todas las solicitudes de indexación y consulta de vectores tienen como destino un índice. Los puntos de conexión suelen ser uno de los siguientes:
| Punto de conexión | Conexión y control de acceso |
|---|---|
<your-service>.search.windows.net/indexes |
Tiene como destino la colección de índices. Se usa al crear, mostrar o eliminar un índice. Los derechos de administrador son necesarios para estas operaciones y están disponibles a través de claves de API de administrador o un rol colaborador de búsqueda. |
<your-service>.search.windows.net/indexes/<your-index>/docs |
Tiene como destino la colección de documentos de un mismo índice. Se usa al consultar un índice o una actualización de datos. En el caso de las consultas, los derechos de lectura son suficientes y están disponibles mediante claves de API de consulta o un rol de lector de datos. Para la actualización de datos, se requieren derechos de administrador. |
Conexión a Búsqueda de Azure AI
Asegúrese de que tiene permisos o una clave de acceso de API. A menos que esté consultando un índice existente, necesita permisos de administrador o una asignación de rol de colaborador para administrar y ver contenido en un servicio de búsqueda.
Empieza con el portal de Azure. La persona que creó el servicio de búsqueda puede verlo y administrarlo, incluida la concesión de acceso a otros usuarios en la página Control de acceso (IAM).
Pase a otros clientes para el acceso mediante programación. Para los primeros pasos, se recomienda Quickstart: Búsqueda de vectores mediante REST y el repositorio azure-search-vector-samples.
Administrar almacenes de vectores
Azure proporciona una plataforma monitoring que incluye el registro de diagnóstico y las alertas. Le recomendamos que:
- Habilite el registro de diagnóstico.
- Configuración de alertas.
- Analice el rendimiento de las consultas e índices.
Acceso seguro a datos vectoriales
Búsqueda de Azure AI implementa el cifrado de datos, las conexiones privadas para escenarios sin Internet y las asignaciones de roles para el acceso seguro a través de Microsoft Entra ID. Para obtener más información sobre las características de seguridad empresarial, consulte Protección integrada, privacidad y datos.