Diagnóstico de escenarios comunes con Service Fabric
En este artículo se muestran escenarios comunes que los usuarios se encuentran en el área de supervisión y diagnóstico con Service Fabric. Los escenarios presentados cubren los 3 niveles de Service Fabric: aplicación, clúster e infraestructura. Cada solución utiliza Application Insights y los registros de Azure Monitor —las herramientas de supervisión de Azure— para completar cada escenario. Los pasos en cada solución proporcionan a los usuarios una introducción sobre cómo usar Application Insights y los registros de Azure Monitor en el contexto de Service Fabric.
Nota:
Este artículo se ha actualizado recientemente para usar el término registros de Azure Monitor en lugar de Log Analytics. Los datos de registro siguen almacenándose en un área de trabajo de Log Analytics y siguen recopilándose y analizándose por el mismo servicio de Log Analytics. Estamos actualizando la terminología para reflejar mejor el rol de los registros de Azure Monitor. Consulte Azure Monitor terminology changes (Cambios en la terminología de Azure Monitor) para obtener más información.
Requisitos previos y recomendaciones
Las soluciones en este artículo utilizan las siguientes herramientas. Se recomienda tenerlas instaladas y configuradas:
- Application Insights con Service Fabric
- Habilitar Azure Diagnostics en un clúster
- Configurar un área de trabajo de Log Analytics
- Agente de Log Analytics para realizar el seguimiento de los contadores de rendimiento
¿Cómo puedo ver las excepciones no controladas en mi aplicación?
Vaya al recurso de Application Insights con el que la aplicación está configurada.
Haga clic en Buscar en la parte superior izquierda. Después, haga clic en Filtrar en el panel siguiente.
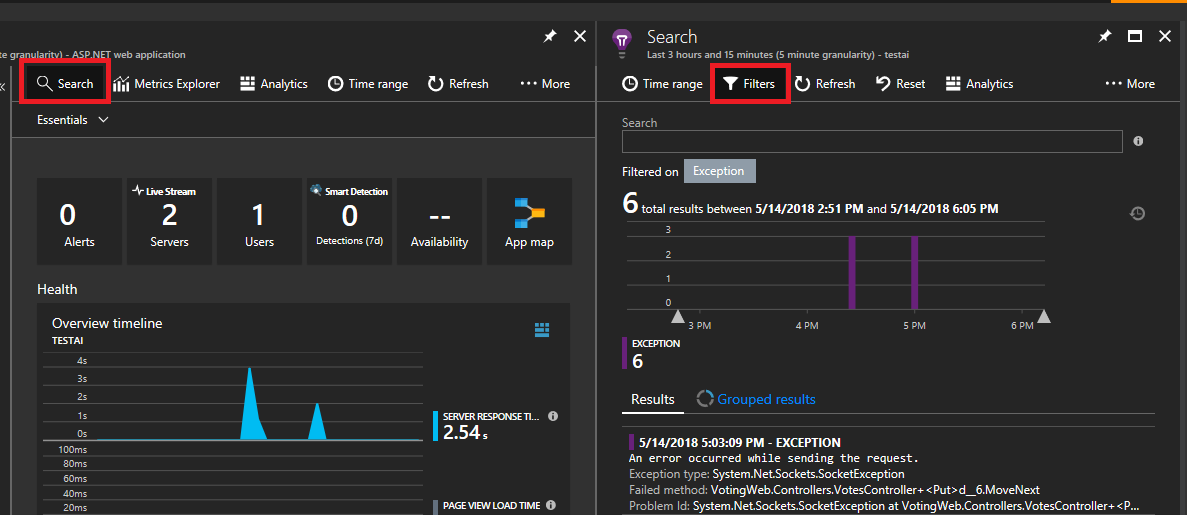
Verá una gran cantidad de tipos de eventos (seguimientos, solicitudes, eventos personalizados). Elija "Excepción" como filtro.
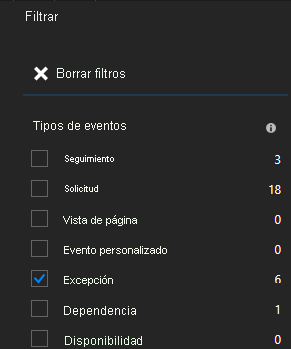
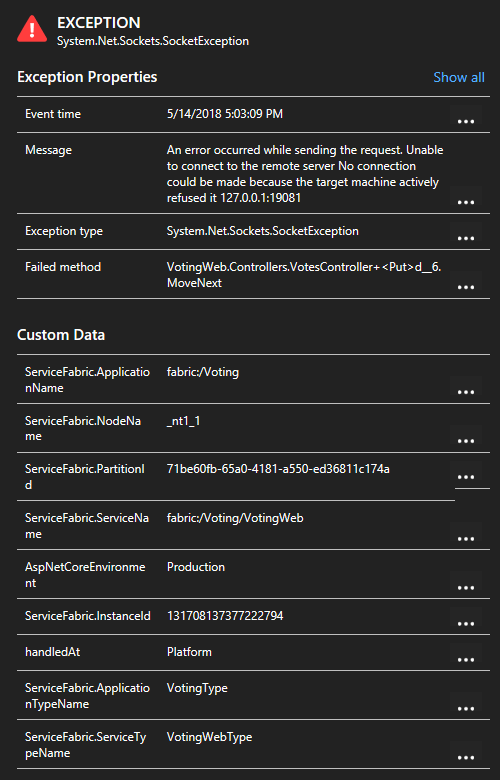
Al hacer clic en una excepción de la lista, puede consultar más detalles, incluido el contexto de servicio si usa el SDK de Application Insights para Service Fabric.
¿Cómo puedo ver qué llamadas HTTP se usan en mis servicios?
En el mismo recurso de Application Insights, puede filtrar por "solicitudes" en lugar de excepciones para ver todas las solicitudes realizadas.
Si usa el SDK de Application Insights para Service Fabric, verá una representación visual de los servicios conectados entre sí, y el número de solicitudes correctas e incorrectas. En la izquierda, haga clic en "Mapa de aplicación"
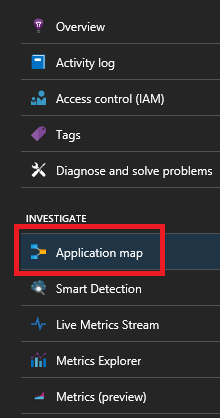
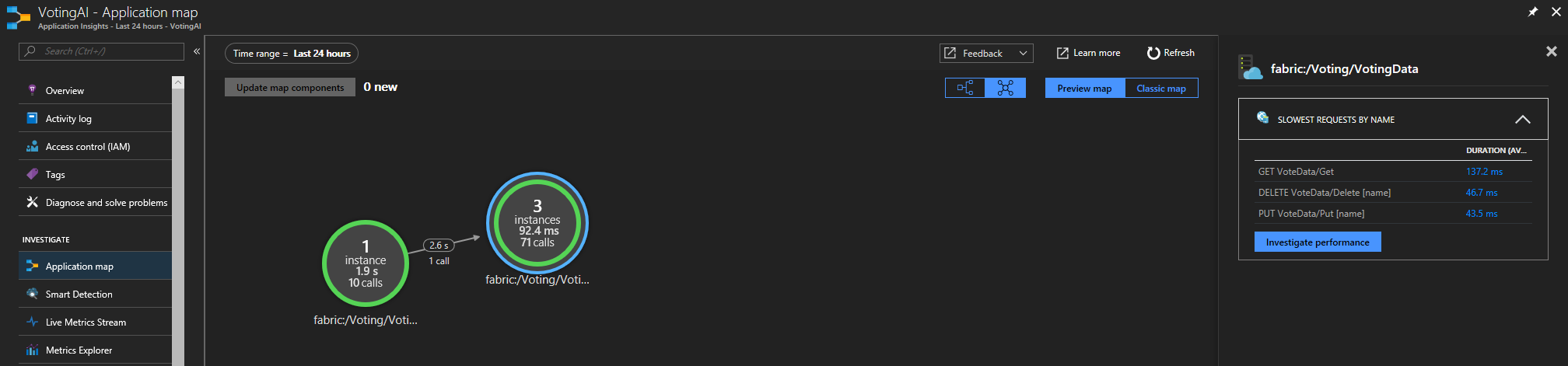
Para más información sobre el mapa de aplicación, consulte la documentación de Mapa de aplicación
Cómo puedo crear una alerta cuando un nodo deja de funcionar
El clúster de Service Fabric registra los eventos de nodo. Vaya al recurso de solución de Service Fabric Analytics llamado ServiceFabric(nombreGrupoRecursos)
Haga clic en el gráfico situado en la parte inferior de la hoja "Resumen"
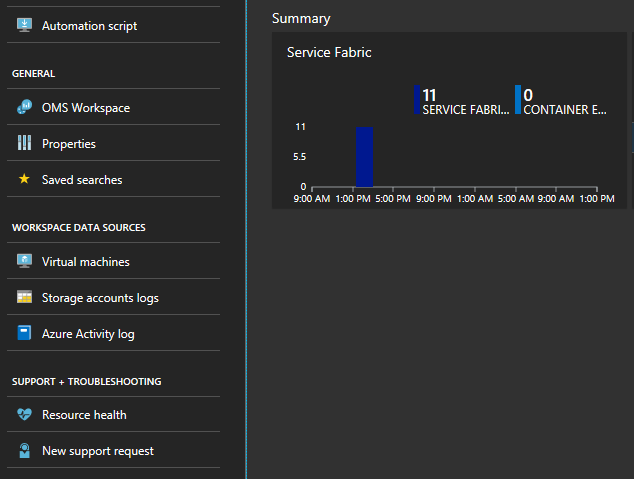
Aquí tiene muchos gráficos e iconos que muestran varias métricas. Haga clic en uno de los gráficos y le llevará a la búsqueda de registros. Aquí puede consultar los eventos de clúster o los contadores de rendimiento.
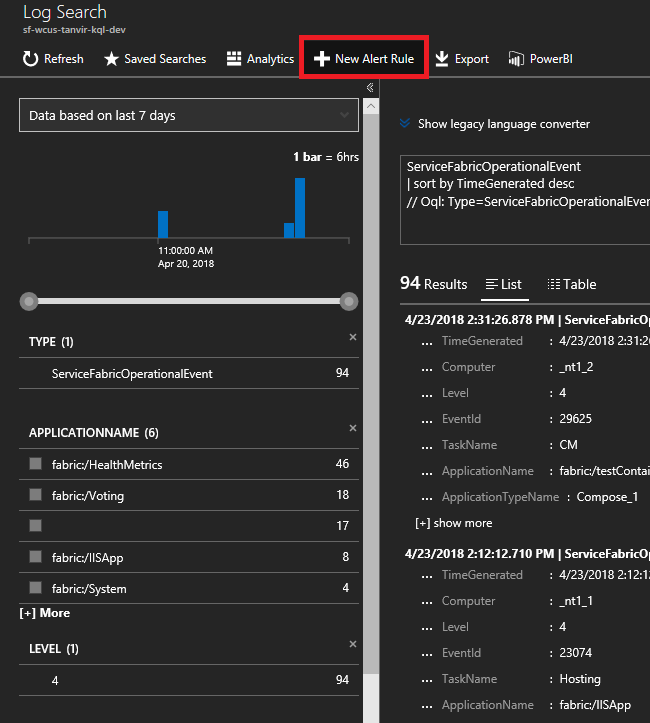
Escriba la siguiente consulta. Estos identificadores de evento se encuentran en la referencia de eventos de nodo.
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Haga clic en "Nueva regla de alertas" en la parte superior y, ahora, cada vez que llegue un evento basado en esta consulta, recibirá una alerta por el método de comunicación elegido.
¿Cómo puedo recibir notificaciones de reversiones de actualizaciones de la aplicación?
En la misma ventana de búsqueda de registros, escriba la siguiente consulta para buscar reversiones de actualizaciones. Estos identificadores de evento se encuentran en la referencia de eventos de aplicación.
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Haga clic en "Nueva regla de alertas" en la parte superior y, ahora, cada vez que llegue un evento basado en esta consulta, recibirá una alerta.
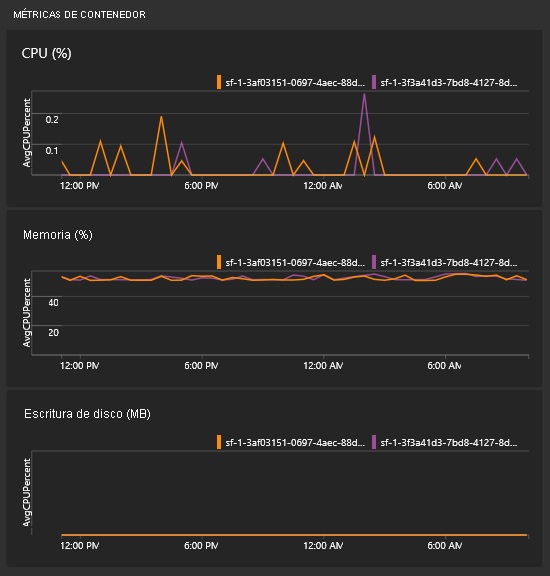
¿Cómo puedo ver las métricas de contenedor?
En la misma vista con todos los gráficos, verá algunos iconos del rendimiento de los contenedores. Necesita el agente de Log Analytics y la solución de supervisión de contenedores para que estos iconos se llenen.
Nota:
Para instrumentar los datos de telemetría desde dentro del contenedor, debe agregar el paquete NuGet de Application Insights para los contenedores.
¿Cómo puedo supervisar los contadores de rendimiento?
Una vez agregado el agente de Log Analytics al clúster, debe agregar los contadores de rendimiento concretos cuyo seguimiento quiere realizar. Navegue a la página del área de trabajo de Log Analytics en el portal; en la página de la solución, la pestaña del área de trabajo está en el menú izquierdo.
Una vez que esté en la página del área de trabajo, haga clic en "Configuración avanzada" en el mismo menú izquierdo.
Haga clic en Datos > Contadores de rendimiento de Windows (Datos > Contadores de rendimiento de Linux, en el caso de las máquinas Linux) para comenzar a recopilar los contadores específicos de los nodos mediante el agente de Log Analytics. Estos son ejemplos del formato de los contadores
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeEn la guía de inicio rápido, VotingData y VotingWeb son los nombres de proceso utilizados, por lo que el seguimiento de estos contadores tendrá el siguiente aspecto:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes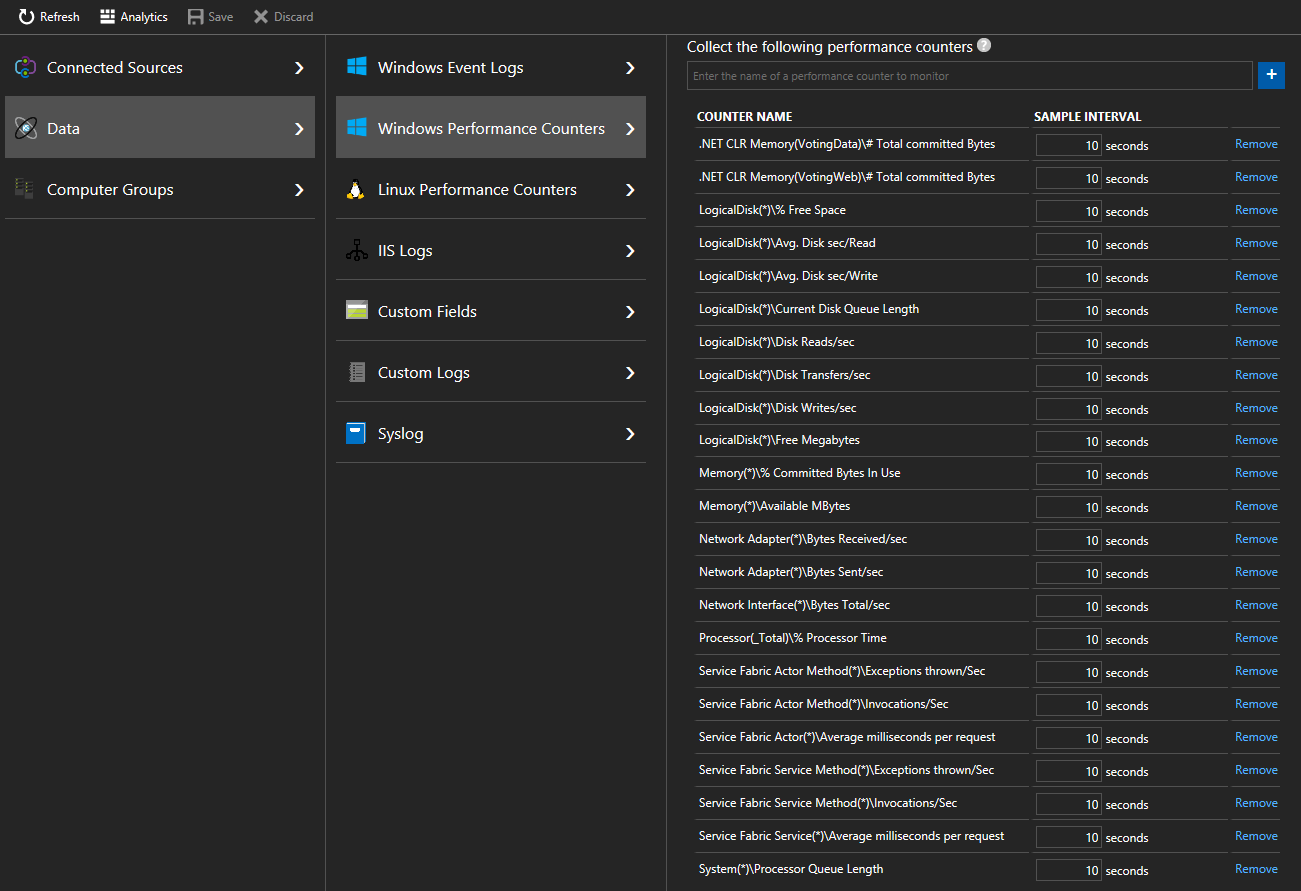
Esto le permitirá ver cómo la infraestructura está tratando las cargas de trabajo, y establecer las alertas correspondientes en función de la utilización de los recursos. Por ejemplo, puede establecer una alerta si el uso total del procesador es superior al 90 % o inferior al 5 %. El nombre del contador que usaría para esto es "Tiempo de procesador %". Para ello, puede crear una regla de alerta para la consulta siguiente:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
¿Cómo puedo supervisar el rendimiento de Reliable Services y Reliable Actors?
Para supervisar el rendimiento de Reliable Services o Reliable Actors en sus aplicaciones, debe recopilar también los contadores Actor, Actor Method, Service y Service Method de Service Fabric. A continuación se incluyen ejemplos de contadores de rendimiento de Reliable Services y Reliable Actors que se pueden recopilar.
Nota:
Actualmente, el agente de Log Analytics no puede recopilar los contadores de rendimiento de Service Fabric, pero se pueden recopilar mediante otras soluciones de diagnóstico.
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Consulte estos vínculos para obtener la lista completa de contadores de rendimiento de Reliable Services y Reliable Actors.
Pasos siguientes
- Búsqueda de errores comunes de activación de paquetes de código
- Definición de alertas en Application Insights para recibir notificaciones sobre los cambios de rendimiento o de uso
- Detección inteligente en Application Insights, donde se realiza un análisis proactivo de la telemetría enviada a AI para avisar de problemas de rendimiento potenciales
- Obtenga más información sobre las alertas de los registros de Azure Monitor como ayuda para la detección y diagnóstico.
- Si se trata de clústeres locales, los registros de Azure Monitor ofrecen una puerta de enlace (proxy de reenvío HTTP) que puede usarse para enviar datos a estos registros. Para más información, vea Conectar equipos sin acceso a Internet a los registros de Azure Monitor a través de la puerta de enlace de Log Analytics.
- Familiarícese con las características de consultas y búsqueda de registros que se ofrecen como parte de los registros de Azure Monitor.
- Lea en ¿Qué son los registros de Azure Monitor? una introducción más detallada de los registros de Azure Monitor y conozca qué ofrecen.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de