La herramienta Mapa de datos es un proceso guiado para ayudar a los usuarios a crear asignaciones de extracción, transformación y carga de datos y flujos de datos de asignación desde sus datos de origen a tablas de base de datos de lago de Synapse sin escribir código. El inicio de este proceso es que el usuario elige las tablas de destino en las bases de datos de lago de Synapse y, después, asigna sus datos de origen a estas tablas.
Mapa de datos proporciona una experiencia guiada en la que el usuario puede generar un flujo de datos de asignación sin necesidad de empezar con un lienzo en blanco. Después, puede generar rápidamente un flujo de datos de asignación escalable que se puede ejecutar en las canalizaciones de Synapse.
Introducción
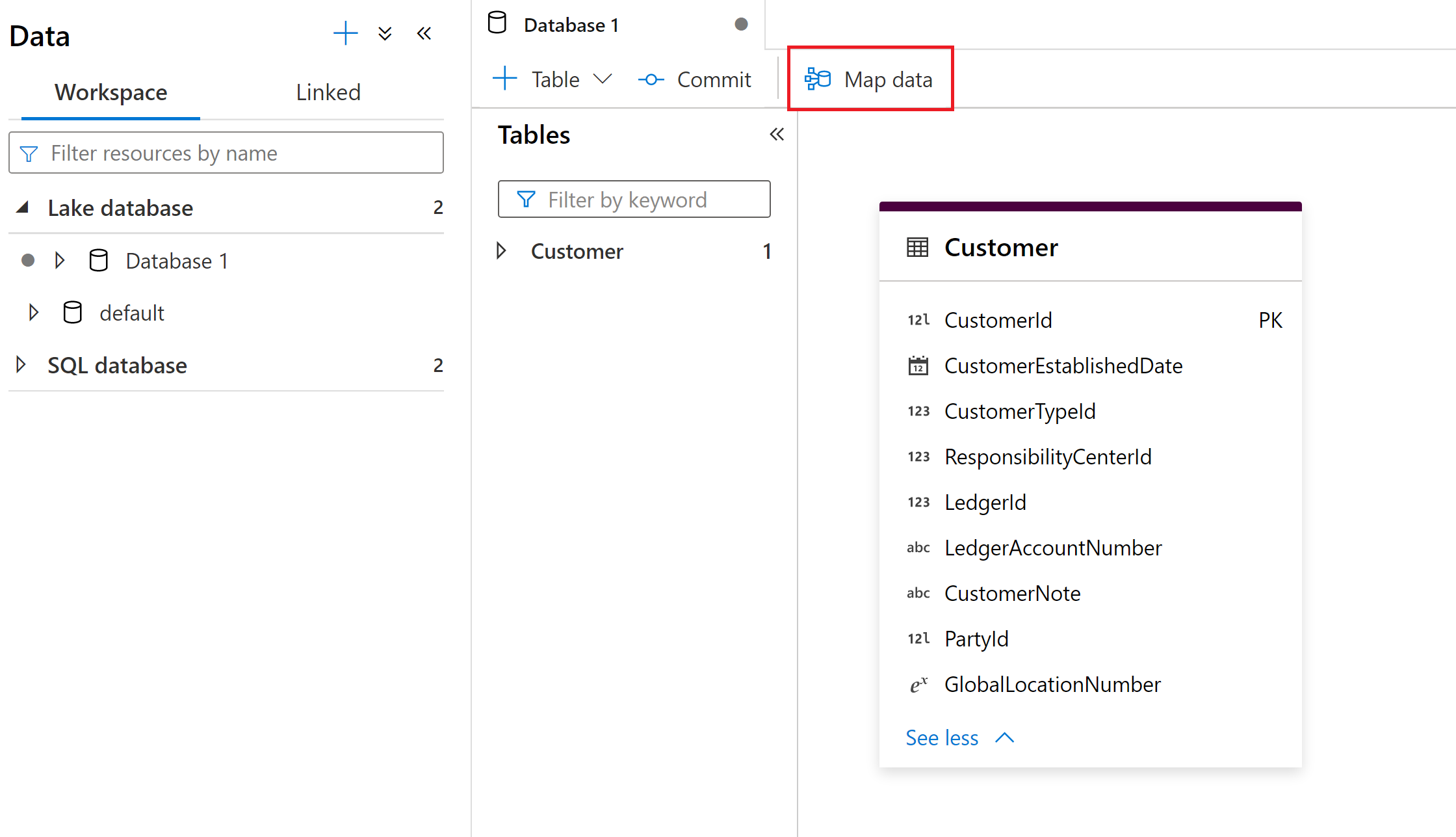
La herramienta Mapa de datos se inicia desde la experiencia de base de datos de lago de Synapse. Ahí puede seleccionar la herramienta Mapa de datos para comenzar el proceso.
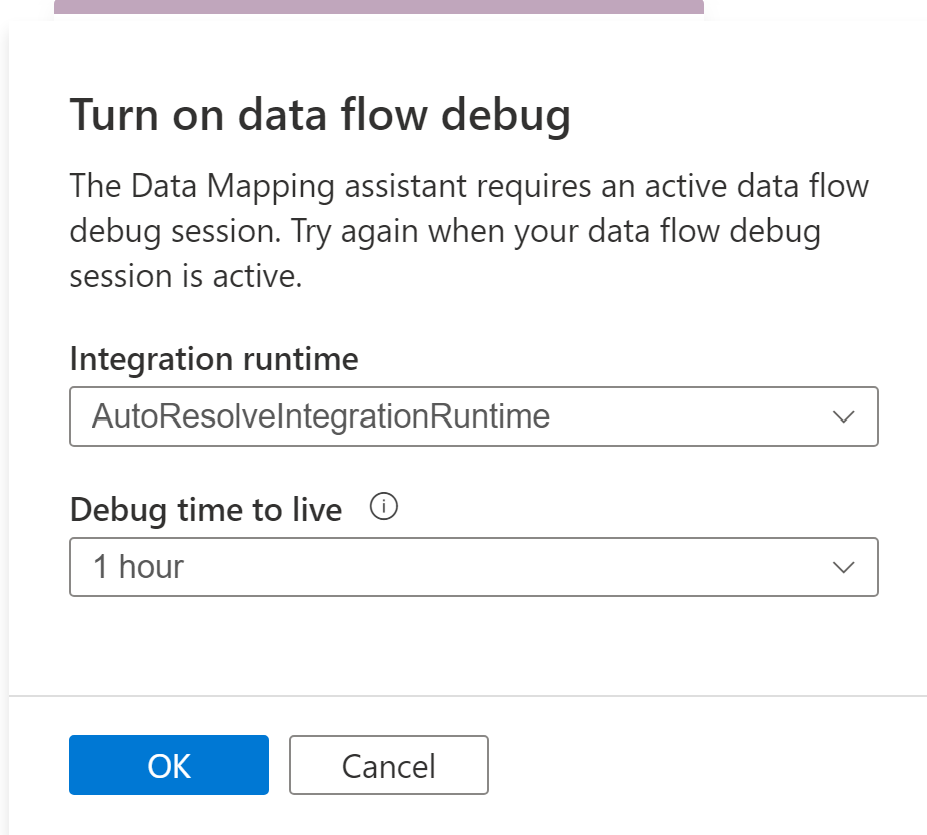
Mapa de datos necesita proceso disponible para ayudar a los usuarios a obtener una vista previa de los datos y a leer el esquema de sus archivos de origen. Después de usar Mapa de datos por primera vez en una sesión, tendrá que preparar un clúster.
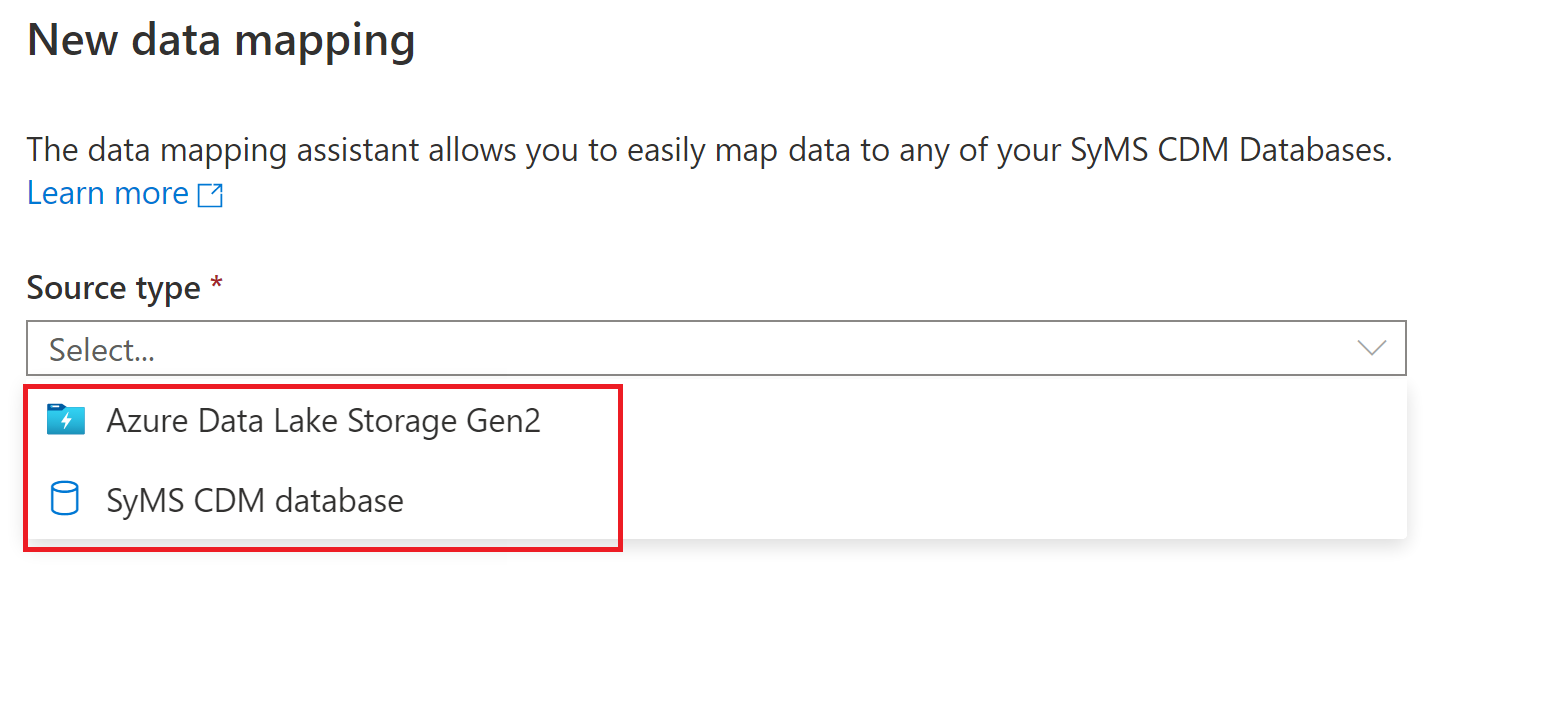
Para empezar, elija el origen de datos que desea asignar a las tablas de la base de datos de lago. Los orígenes de datos admitidos actualmente son las bases de datos de lago de Azure Data Lake Storage Gen 2 y Synapse.
Opciones de tipo de archivo
Al elegir un almacén de archivos como Azure Data Lake Storage Gen 2, se admiten los siguientes tipos de archivo:
Common Data Model
Texto delimitado
Parquet
Creación de una asignación de datos
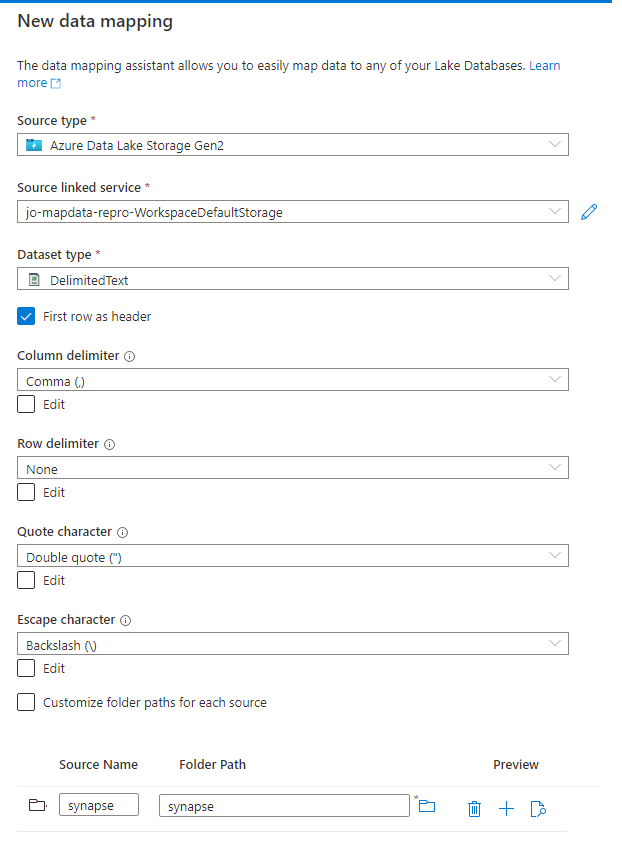
Configure la asignación de datos con el tipo de origen seleccionado.
Nota
Puede elegir una carpeta o un único archivo. Si elige una carpeta, podrá asignar varios archivos a las tablas de base de datos del lago. Si elige una carpeta, después de seleccionar Continuar, también se le pedirá que incluya solo archivos específicos, si quiere.
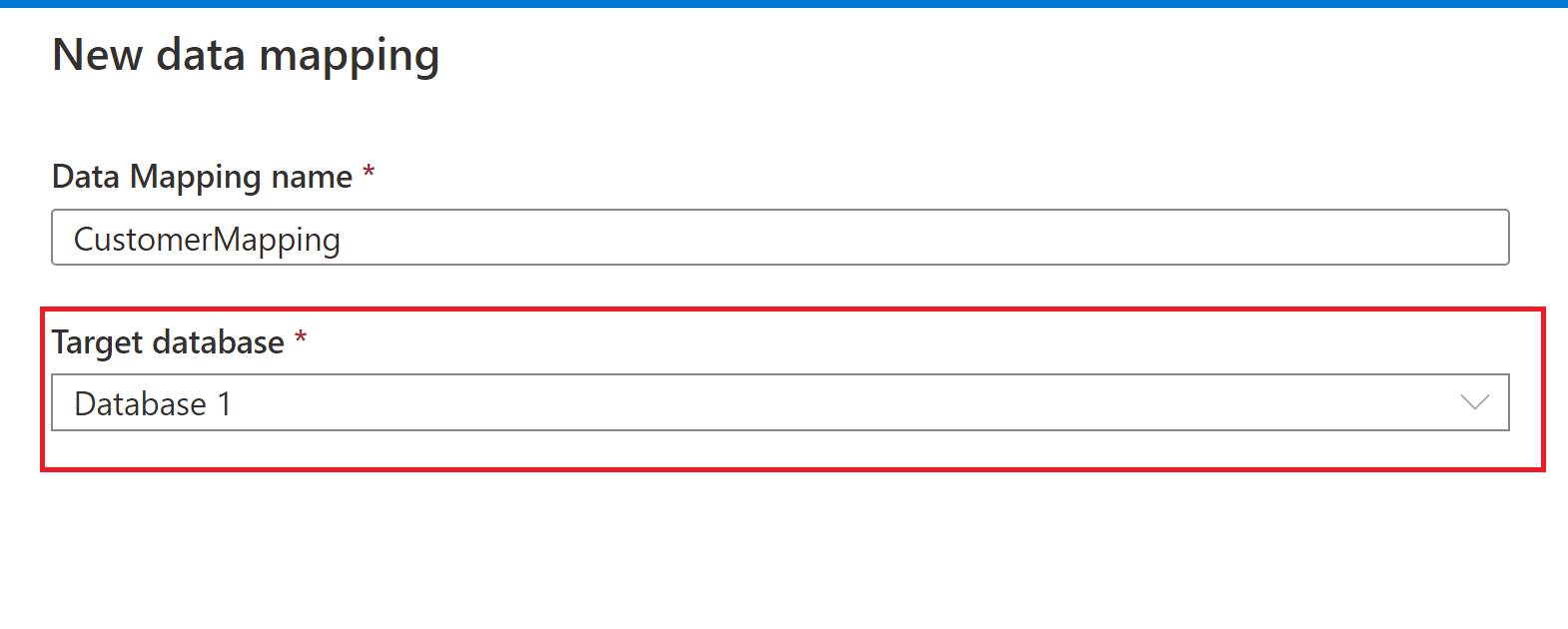
Asigne un nombre a la asignación de datos y seleccione el destino de la base de datos de lago de Synapse.
Asignación de origen a destino
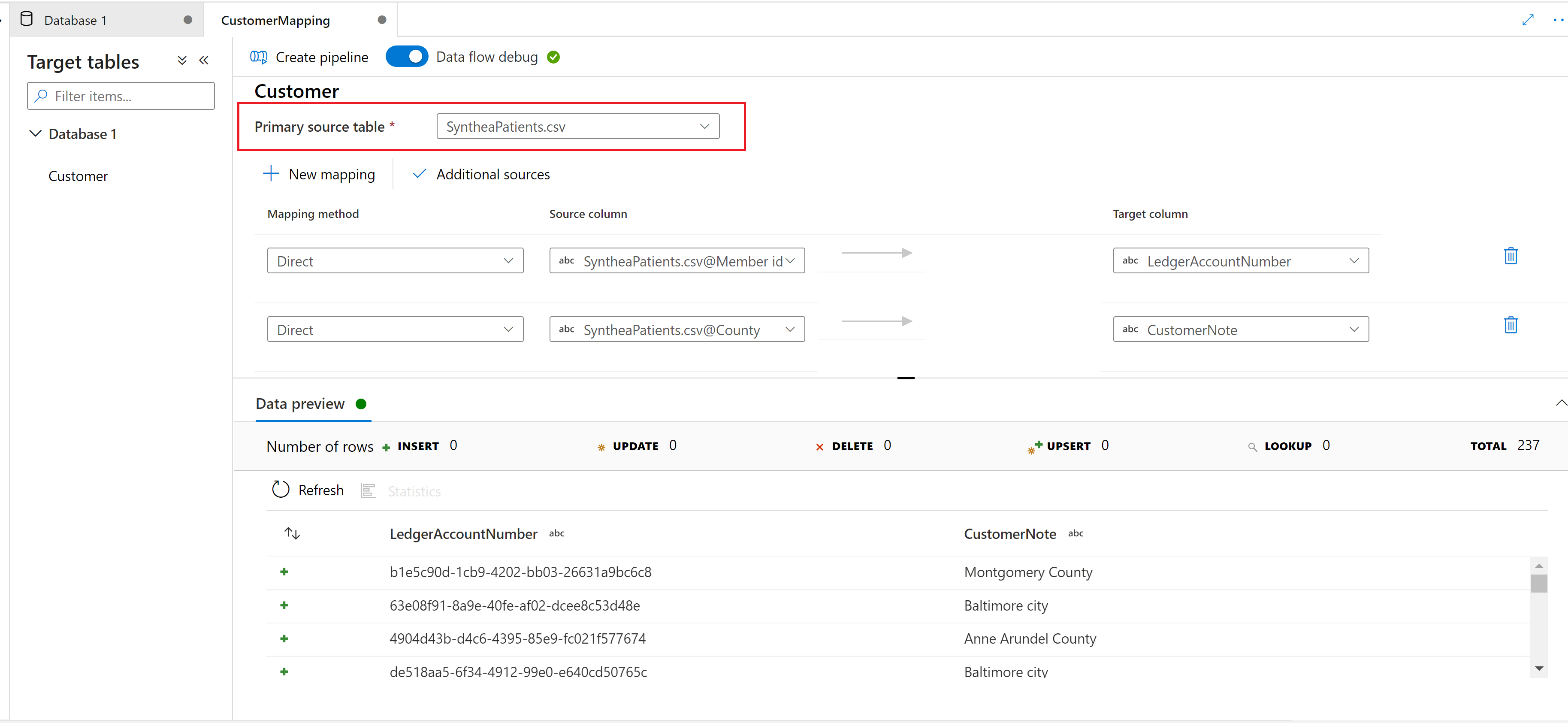
Elija una tabla de origen principal para asignarla a la tabla de destino de la base de datos de lago de Synapse.
Asignación nueva
Use el botón Nueva asignación para agregar un método de asignación para crear una asignación o transformación.
Origen adicional
Use el botón Origen adicional para unirse y agregar otro origen a la asignación.
Vista previa de los datos
La pestaña Vista previa de los datos proporciona una instantánea interactiva de los datos de cada transformación. Para más información, consulte Vista previa de los datos en modo de depuración.
Métodos de asignación
Estos son los métodos de asignación que se admiten:
Una vez que haya terminado con las transformaciones de Mapa de datos, seleccione el botón Crear canalización para generar un flujo de datos de asignación y una canalización para depurar y ejecutar la transformación.
Demostrar la comprensión de las tareas comunes de ingeniería de datos para implementar y administrar cargas de trabajo de ingeniería de datos en Microsoft Azure mediante una serie de servicios de Azure.
Azure Synapse Analytics permite que los diferentes motores de cálculo de áreas de trabajo compartan bases de datos y tablas entre sus grupos de Apache Spark sin servidor y el grupo de SQL sin servidor.