Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este tutorial se usa Azure Machine Learning Designer para crear un modelo de aprendizaje automático predictivo. El modelo se basa en los datos almacenados en Azure Synapse. El escenario del tutorial es predecir la probabilidad de que un cliente compre una bicicleta y su finalidad es que Adventure Works, la tienda de bicicletas, pueda crear una campaña de marketing dirigida.
Requisitos previos
Para realizar este tutorial, necesita:
- Un grupo de SQL con la base de datos de ejemplo AdventureWorksDW previamente cargada. Para aprovisionar este grupo de SQL, consulte Creación de un grupo de SQL y cargue los datos de ejemplo. Si ya tiene un almacenamiento de datos pero no tiene datos de ejemplo, puede cargar manualmente los datos de ejemplo.
- Un área de trabajo de Azure Machine Learning. Siga este tutorial para crear una nueva.
Obtener los datos
Los datos usados están en la vista dbo.vTargetMail en AdventureWorksDW. Para usar el almacén de datos en este tutorial, los datos se exportan primero a la cuenta de Azure Data Lake Storage, ya que en la actualidad Azure Synapse no admite conjuntos de datos. Azure Data Factory se puede usar para exportar datos desde el almacenamiento de datos a Azure Data Lake Storage mediante la actividad de copia. Use la siguiente consulta para la importación:
SELECT [CustomerKey]
,[GeographyKey]
,[CustomerAlternateKey]
,[MaritalStatus]
,[Gender]
,cast ([YearlyIncome] as int) as SalaryYear
,[TotalChildren]
,[NumberChildrenAtHome]
,[EnglishEducation]
,[EnglishOccupation]
,[HouseOwnerFlag]
,[NumberCarsOwned]
,[CommuteDistance]
,[Region]
,[Age]
,[BikeBuyer]
FROM [dbo].[vTargetMail]
Una vez que los datos están disponibles en Azure Data Lake Storage, los almacenes de datos de Azure Machine Learning se utilizan para conectarse a los servicios de almacenamiento de Azure. Siga los pasos que se indican a continuación para crear un almacén de datos y el correspondiente conjunto de datos:
Inicie Azure Machine Learning Studio desde Azure Portal o inicie sesión en Estudio de Azure Machine Learning.
Haga clic en Almacenes de datos en el panel izquierdo de la sección Administrar y, a continuación, haga clic en New Datastore (Nuevo almacén de datos).
Proporcione un nombre para el almacén de datos, seleccione el tipo como "Azure Blob Storage", facilite la ubicación y las credenciales. A continuación, haga clic en Crear.
A continuación, haga clic en Conjuntos de datos en el panel izquierdo en la sección Recursos. Seleccione Crear conjunto de datos con la opción De almacén de datos.
Especifique el nombre del conjunto de datos y seleccione el tipo para que sea Tabular. A continuación, haga clic en Siguiente para avanzar.
En Select or create a datastore section (Seleccionar o crear una sección de almacén de datos), seleccione la opción Previously created datastore (Almacén de datos creado anteriormente). Seleccione el almacén de datos que se creó anteriormente. Haga clic en Siguiente y especifique la ruta de acceso y la configuración del archivo. Asegúrese de especificar el encabezado de columna, si los archivos contienen uno.
Por último, haga clic en Crear para crear el conjunto de datos.
Configuración del experimento del diseñador
Después, siga los pasos que aparecen a continuación para configurar el diseñador:
Haga clic en la pestaña Designer en el panel izquierdo en la sección Autor.
Seleccione Componentes creados previamente fáciles de usar para crear una nueva canalización.
En el panel de valores de la derecha, especifique el nombre de la canalización.
Seleccione también un clúster aprovisionado previamente como clúster de proceso de destino para todo el experimento. Cierre la ventana Configuración.
Importación de los datos
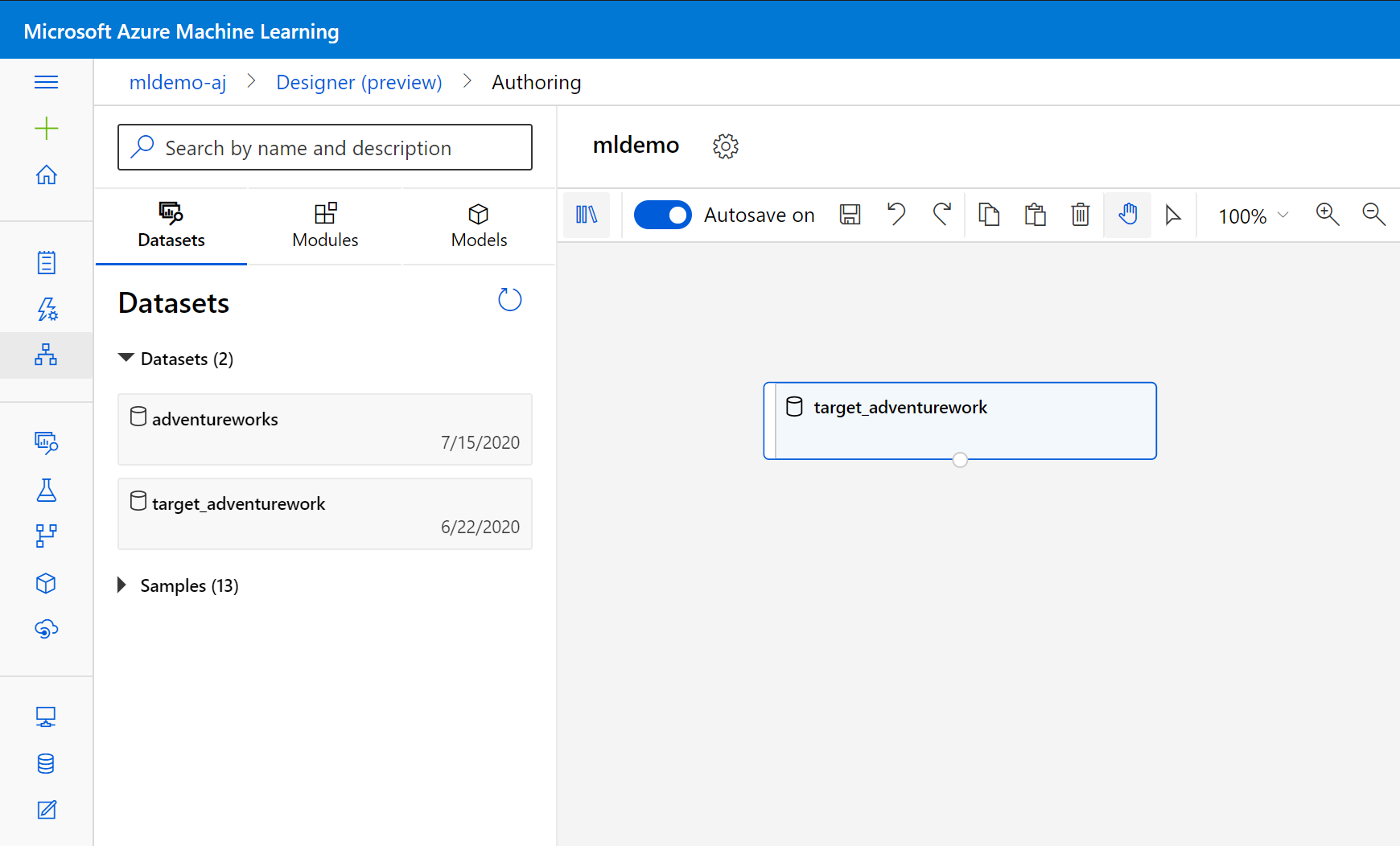
Seleccione la subpestaña Conjuntos de datos en el panel izquierdo, debajo del cuadro de búsqueda.
Arrastre el conjunto de datos que creó anteriormente al lienzo.
Limpiar los datos
Para limpiar los datos, anule las columnas que no sean pertinentes para el modelo. Para hacerlo, siga estos pasos:
Seleccione la subpestaña Componentes en el panel izquierdo.
Arrastre el componente Seleccionar columnas en el conjunto de datos en la opción Transformación de datos < Manipulación en el lienzo. Conecte este componente al componente Conjunto de datos.
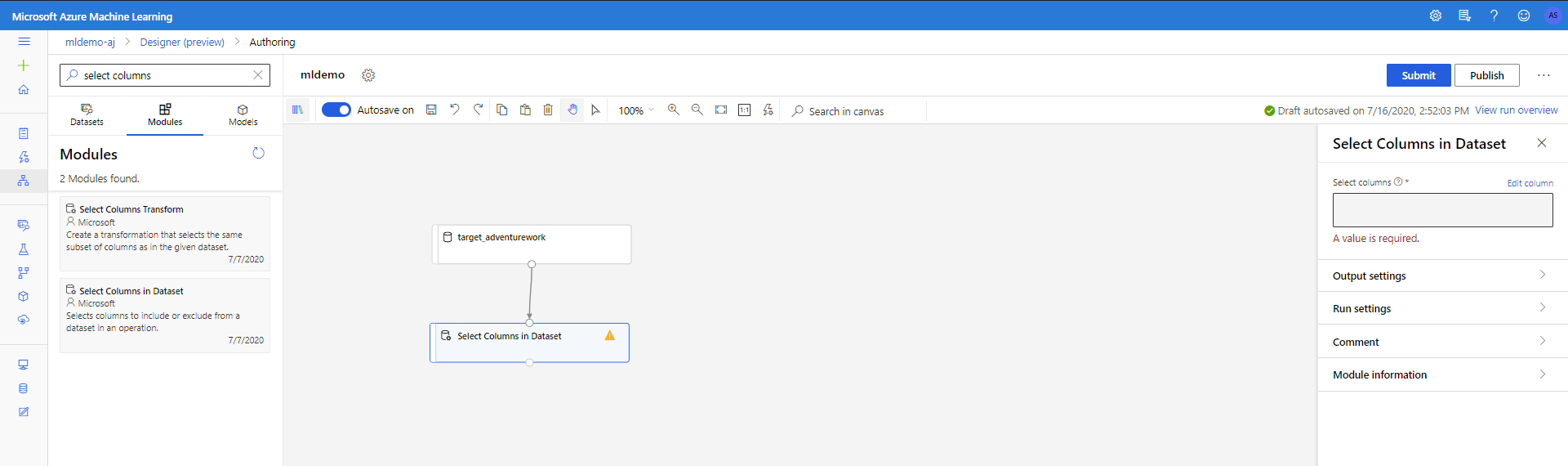
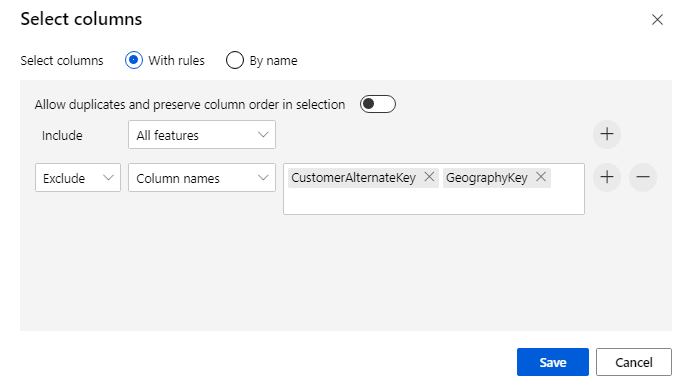
Haga clic en el componente para abrir el panel de propiedades. Haga clic en Editar columna para especificar cuáles son las columnas que desea anular.
Excluya dos columnas: CustomerAlternateKey y GeographyKey. Haga clic en Guardar

Generar el modelo
Los datos se dividen en 80-20: 80 % para entrenar un modelo de aprendizaje automático y un 20 % para probar el modelo. En este problema de clasificación binaria se usan los algoritmos de "dos clases".
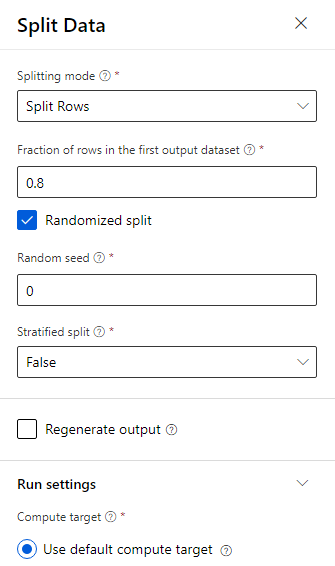
Arrastre el módulo Dividir datoshasta el lienzo.
En el panel de propiedades, escriba 0,8 en Fraction of rows in the first output dataset (Fracción de filas del primer conjunto de datos de salida).
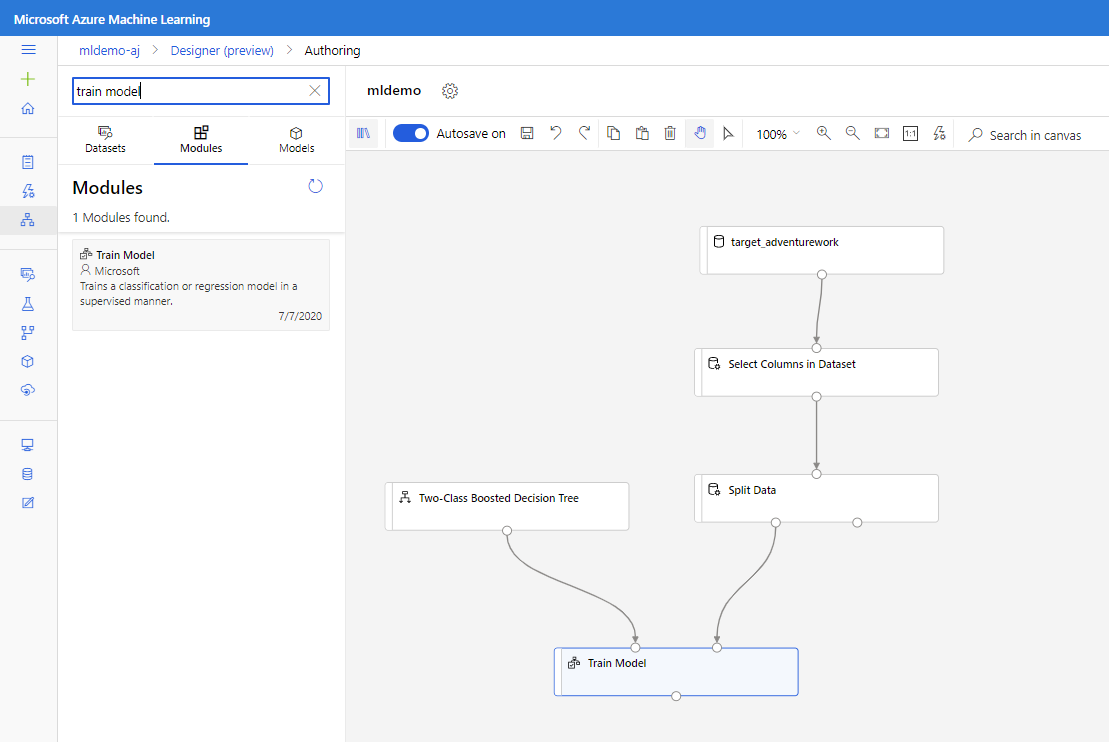
Arrastre el componente Árbol de decisión aumentado de dos clases al lienzo.
Arrastre el módulo Entrenar modelo hasta el lienzo. Especifique las entradas conectándolo a los componentes Árbol de decisión promovido por dos clases que es un algoritmo de ML, y Dividir datos, que son los datos para entrenar el algoritmo.
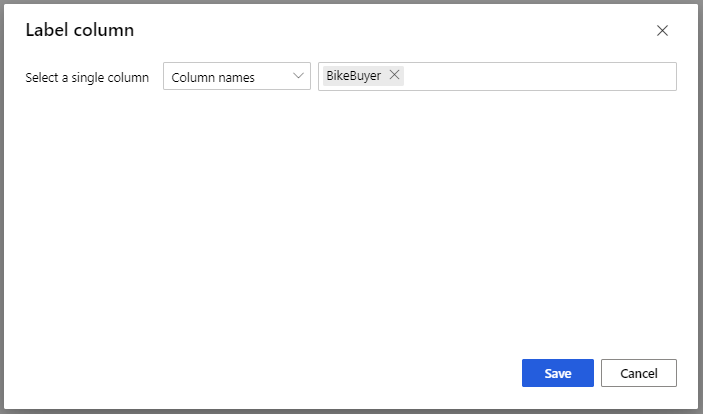
En el caso del modelo Train Model, en la opción Label column de la pestaña Propiedades, seleccione la opción Edición de columnas. Seleccione la columna BikeBuyer como columna de predicción y haga clic en Guardar.
Puntuación del modelo
Ahora pruebe cómo funciona el modelo con datos de prueba. Se compararán dos algoritmos distintos para ver cuál funciona mejor. Para hacerlo, siga estos pasos:
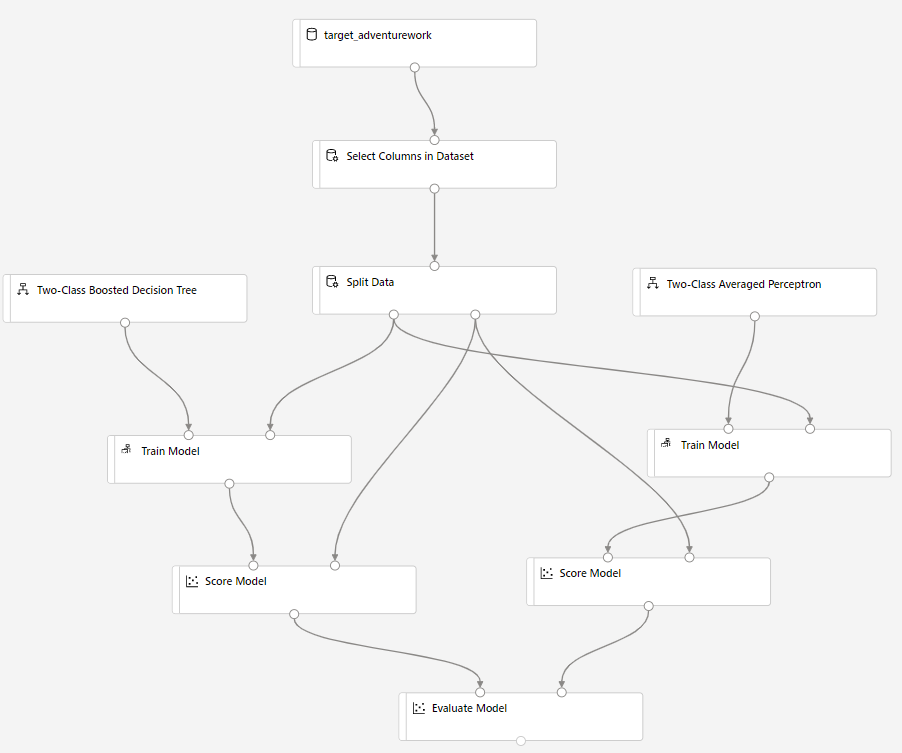
Arrastre el módulo Modelo de puntuación al lienzo y conéctelo a los módulos Entrenar modelo y Datos divididos.
Arrastre Two-Class Bayes Averaged Perceptron (Perceptrón promedio de Bayes de dos clases) al lienzo del experimento. Comparará cómo se desempeña este algoritmo en comparación con el Árbol de Decisión Aumentado de Dos Clases.
Copie y pegue los componentes Entrenar modelo y Puntuar modelo en el lienzo.
Arrastre el componenteEvaluar modelo al lienzo para comparar los dos algoritmos.
Haga clic en Iniciar para configurar la ejecución del pipeline.
Una vez finalizada la ejecución, haga clic con el botón derecho en el módulo Evaluar modelo y haga clic en Visualizar resultados de evaluación.
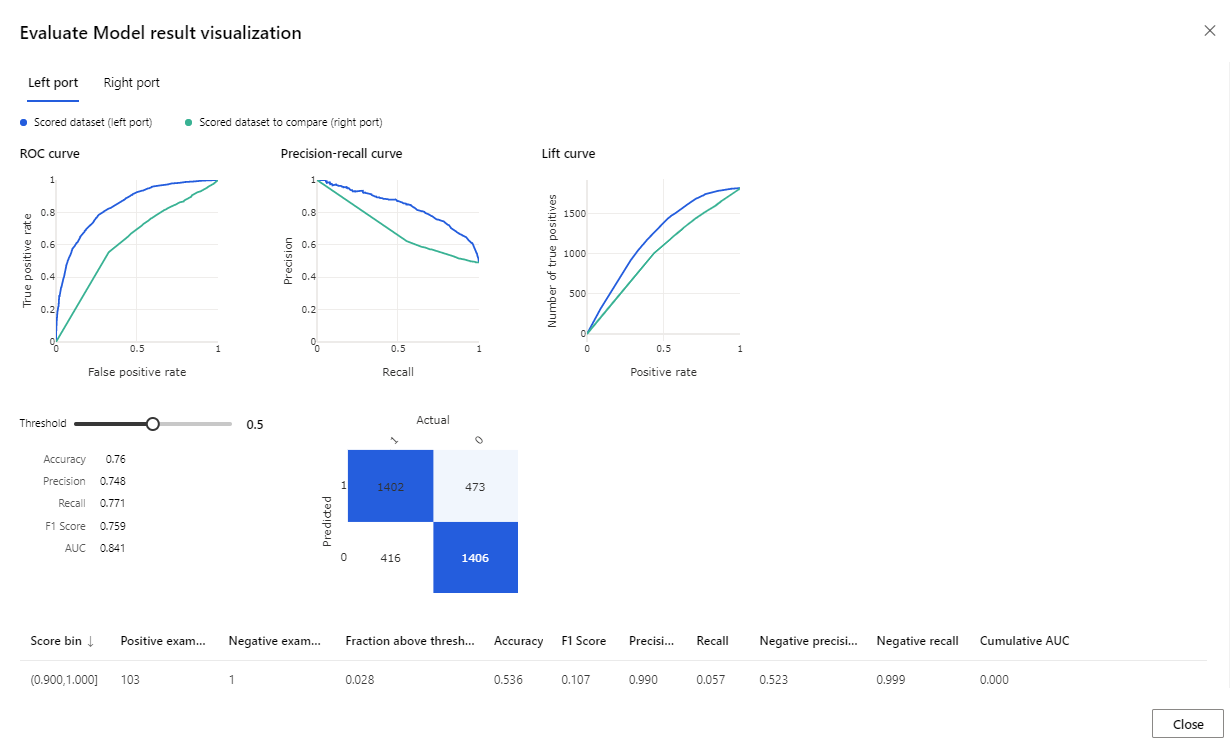

Las métricas proporcionadas son la curva ROC, el gráfico de precisión-revocación y la curva de elevación. Al mirar estas métricas, se puede observar que el primer modelo funciona mejor que el segundo. Para ver lo que predijo el primer modelo, haga clic derecho en el componente de Evaluación del Modelo y seleccione Visualizar el conjunto de datos evaluado para ver los resultados previstos.
Verá dos columnas más agregadas al conjunto de datos de prueba.
- Probabilidades puntuadas: la probabilidad de que un cliente sea comprador de bicicletas.
- Etiquetas puntuadas: la clasificación realizada por el modelo – comprador de bicicletas (1) o no (0). Este umbral de probabilidad para etiquetar se establece en 50% y se puede ajustar.
Para ver cómo ha funcionado el modelo compare la columna BikeBuyer (real) con la columna de predicción Scored Labels (Etiquetas puntuadas). A continuación, puede utilizar este modelo para hacer predicciones para nuevos clientes. Puede publicar este modelo como un servicio web o escribir los resultados en Azure Synapse.
Pasos siguientes
Para más información sobre Azure Machine Learning, consulte Introducción a Machine Learning en Azure.
Obtenga aquí información acerca de la puntuación integrada en el almacenamiento de datos.