Conceptos de la recuperación ante desastres de Azure Virtual Desktop
Azure Virtual Desktop ha crecido enormemente como una solución de trabajo remoto e híbrido en los últimos años. Dado que muchos usuarios ahora trabajan de forma remota, las organizaciones requieren soluciones con alta velocidad de implementación y costos reducidos. Los usuarios también deben tener un entorno de trabajo remoto con disponibilidad garantizada y resistencia que les permita acceder a sus máquinas virtuales incluso durante desastres. En este documento se describen los planes de recuperación ante desastres que se recomiendan para mantener su organización en funcionamiento.
Para evitar interrupciones del sistema o tiempo de inactividad, todos los sistemas y componentes de la implementación de Azure Virtual Desktop deben ser tolerantes a errores. La tolerancia a errores se produce cuando tiene una configuración o un sistema duplicados en otra región de Azure que se encarga de la configuración principal durante una interrupción. Esta configuración secundaria o sistema reduce el impacto de una interrupción localizada. Hay muchas maneras de configurar la tolerancia a errores, pero este artículo se centrará en los métodos disponibles actualmente en Azure.
Infraestructura de Azure Virtual Desktop
Para averiguar qué áreas deben ser tolerantes a errores, primero debe saber quién es responsable de mantener cada área. Puede dividir la responsabilidad en el servicio Azure Virtual Desktop en dos áreas: las que administra Microsoft y las que administra el cliente. Microsoft controla los metadatos como los grupos de hosts, los grupos de aplicaciones y las áreas de trabajo. Los metadatos siempre están disponibles y el cliente no requiere una configuración adicional para replicar los datos o configuraciones del grupo de hosts. Hemos diseñado la infraestructura de puerta de enlace que conecta a los usuarios a sus hosts de sesión para que sean un servicio global y altamente resistente administrado por Microsoft. Mientras tanto, las áreas administradas por el cliente implican las máquinas virtuales (VM) que se usan en Azure Virtual Desktop y las configuraciones únicas para la implementación del cliente. En la tabla siguiente se proporciona una idea más clara de qué parte administra qué áreas.
| Administrada por Microsoft | Administrado por el cliente |
|---|---|
| Equilibrador de carga | Red |
| Agente de sesiones | Hosts de sesión |
| Puerta de enlace | Almacenamiento |
| Diagnóstico | Datos de perfil de usuario |
| Plataforma de identidades en la nube | Identidad |
En este artículo, nos centraremos en los componentes administrados por el cliente, ya que estos son los valores que puede configurar usted mismo.
Conceptos básicos de recuperación ante desastres
En esta sección, analizaremos las acciones y los principios de diseño que pueden proteger los datos y evitaremos que se realicen grandes esfuerzos de recuperación de datos después de sufrir interrupciones pequeñas o desastres completos. En el caso de interrupciones más pequeñas, puede seguir algunos pasos más sencillos para evitar que se produzcan desastres más grandes. Veamos algunos términos básicos que le ayudarán a empezar a configurar el plan de recuperación ante desastres.
Al diseñar un plan de recuperación ante desastres, debe tener en cuenta estas tres cosas:
- Alta disponibilidad: distribución de la infraestructura para que las interrupciones más pequeñas y localizadas no interrumpan toda la implementación. Si tiene en mente un diseño con alta disponibilidad, minimizará el impacto en la interrupción y evitará la necesidad de realizar una recuperación ante desastres completa.
- Continuidad empresarial: aquí se explica cómo una organización puede seguir funcionando durante interrupciones de cualquier tamaño.
- Recuperación ante desastres: es el proceso para volver a funcionar después de una interrupción completa.
Azure tiene muchas características integradas y gratuitas que pueden ofrecer una alta disponibilidad en muchos niveles. La primera característica son los conjuntos de disponibilidad, que distribuyen las VM entre distintos dominios de error y actualización en Azure. A continuación, hay zonas de disponibilidad que están físicamente aisladas y distribuidas geográficamente en centros de datos que pueden reducir el impacto de una interrupción. Por último, la distribución de hosts de sesión en varias regiones de Azure proporciona una distribución aún más geográfica, lo que reduce aún más el impacto de la interrupción. Las tres características proporcionan un determinado nivel de protección en Azure Virtual Desktop y debe considerarlas cuidadosamente junto con cualquier implicación en los costos.
Básicamente, la estrategia de recuperación ante desastres que se recomienda para Azure Virtual Desktop es implementar recursos en varias zonas de disponibilidad dentro de una región. Si necesita más protección, también puede implementar recursos en varias regiones de Azure emparejadas.
Implementaciones activas-pasivas y activas-activas
Otra cosa que debe tener en cuenta es la diferencia entre los planes de tipo activo-pasivo y activo-activo. Los planes de tipo activo-pasivo se usan cuando tiene una región con un conjunto de recursos que está activo y otro que está desactivado hasta que sea necesario (pasivo). Si la región activa se desconecta por una emergencia, la organización puede cambiar a la región pasiva activándola y moviendo a todos sus usuarios allí.
Otra opción es una implementación "activa-activa", donde se usan los dos conjuntos de infraestructura al mismo tiempo. Aunque algunos usuarios pueden verse afectados por interrupciones, el impacto se limita a los usuarios de la región que ha dejado de funcionar. Los usuarios de la otra región que todavía están en línea no se verán afectados, y la recuperación se limita a los usuarios de la región afectada que se vuelven a conectar a la región activa en funcionamiento. Las implementaciones activa-activa pueden adoptar muchas formas, entre las que se incluyen:
- La infraestructura de aprovisionamiento excesivo en cada región para dar cabida a los usuarios afectados en caso de que una de las regiones deje de funcionar. Un posible inconveniente de este método es que el mantenimiento de los recursos adicionales cuesta más.
- Tenga hosts de sesión adicionales en ambas regiones activas, pero desasígnelos cuando no sean necesarios, lo que reduce los costos.
- Aprovisione solo la nueva infraestructura durante la recuperación ante desastres y permita a los usuarios afectados conectarse a los hosts de sesión recién aprovisionados. Este método requiere pruebas periódicas con herramientas de infraestructura como código para que pueda implementar la nueva infraestructura lo antes posible durante un desastre.
Métodos de recuperación ante desastres recomendados
Los métodos de recuperación ante desastres que se recomiendan son:
Configurar e implementar recursos de Azure en varias zonas de disponibilidad.
Configurar e implementar recursos de Azure en varias regiones en configuraciones de tipo activo-activo o activo-pasivo. Normalmente, estas configuraciones se encuentran en grupos de hosts compartidos.
En el caso de los grupos de hosts personales con VM dedicadas, replique las VM mediante Azure Site Recovery en otra región.
Configure un grupo de hosts de "recuperación ante desastres" independiente en la región secundaria. Durante un desastre, puede cambiar los usuarios a la región secundaria.
En las secciones siguientes se detallan más los dos métodos principales con los que puede lograr estos pasos para grupos de hosts compartidos y personales.
Recuperación ante desastres para grupos de hosts compartidos
En esta sección, analizaremos los grupos de hosts compartidos (o "agrupados") mediante un enfoque activo-pasivo. El enfoque activo-pasivo se usa cuando se dividen los recursos existentes en una región primaria y secundaria. Normalmente, la organización hace todo su trabajo en la región principal (o "activa"), pero durante un desastre, puede cambiar enseguida a la región secundaria (o "pasiva") desactivando los recursos de la región principal (si puede hacerlo, dependiendo de la extensión de la interrupción) y activando los de la secundaria.
En el diagrama siguiente se muestra un ejemplo de una implementación con infraestructura redundante en una región secundaria. "Redundante" significa que existe una copia de la infraestructura original en la otra región y que es estándar en las implementaciones, para así poder proporcionar resistencia a todos los componentes. En una sola instancia de Microsoft Entra ID, hay dos regiones: Oeste de EE. UU. y Este de EE. UU. Cada región tiene dos hosts de sesión que ejecutan un sistema operativo (SO) de varias sesiones, un servidor que ejecuta Microsoft Entra Connect, un controlador de Dominio de Active Directory, un recurso compartido de archivos de Azure Files Premium para perfiles de FSLogix, una cuenta de almacenamiento y una red virtual (VNET). En la región primaria (Oeste de EE. UU.), todos los recursos están activados. En la región secundaria (Este de EE. UU.), los hosts de sesión del grupo de hosts están desactivados o en modo de purga, y el servidor de Microsoft Entra Connect está en modo de almacenamiento provisional. Las dos redes virtuales de ambas regiones están conectadas mediante el emparejamiento.
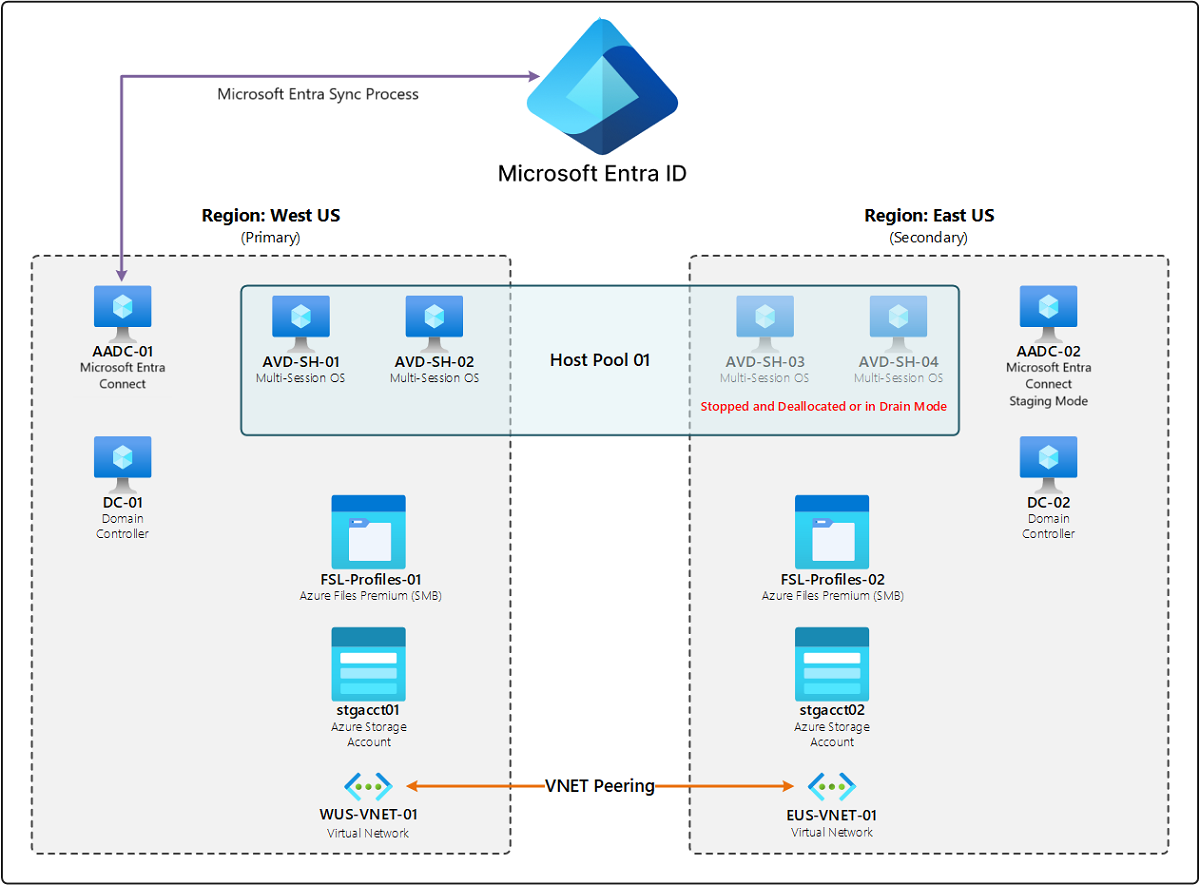
En la mayoría de los casos, si se produce un error en un componente o la región primaria no está disponible, la única acción que debe realizar el cliente es activar los hosts o quitar el modo de purga en la región secundaria para habilitar las conexiones del usuario final. Este escenario se centra en reducir el tiempo de inactividad. Sin embargo, un plan de recuperación ante desastres basado en la redundancia puede costar más, ya que tiene que mantener esos componentes adicionales en la región secundaria.
Las posibles ventajas de este plan son las siguientes:
- Menos tiempo dedicado a la recuperación ante desastres. Por ejemplo, dedicará menos tiempo al aprovisionamiento o a configurar, integrar y validar los recursos recién implementados.
- No es necesario usar procedimientos complicados.
- Es fácil probar la conmutación por error sin tener en cuenta los desastres.
Los posibles inconvenientes son los siguientes:
- Puede costar más, ya que tiene más infraestructura para mantener, como cuentas de almacenamiento, hosts, etc.
- Tendrá que dedicar más tiempo a configurar la implementación para dar cabida a este plan.
- Debe mantener la infraestructura adicional que configure, incluso cuando no lo necesite.
Información importante para la recuperación del grupo de hosts compartido
Al usar esta estrategia de recuperación ante desastres, es importante tener en cuenta lo siguiente:
Tener varios hosts de sesión en línea entre muchas regiones puede afectar a la experiencia del usuario. El equilibrador de carga de red administrada no tiene en cuenta la proximidad geográfica, sino que trata todos los hosts de un grupo de hosts de forma equitativa.
Durante un desastre, los usuarios crearán nuevos perfiles en la región secundaria. Debe almacenar los datos empresariales o críticos en OneDrive (mediante el redireccionamiento de carpetas conocidas) o Sharepoint. El almacenamiento de datos aquí proporcionará a los usuarios acceso rápido a sus aplicaciones con una interrupción menor en la experiencia del usuario.
Asegúrese de configurar las máquinas virtuales (VM) de la misma manera en el grupo de hosts. Además, asegúrese de que todas las VM del grupo de hosts tienen el mismo tamaño. Si las VM no son las mismas, el equilibrador de carga de red administrada distribuirá las conexiones de usuario uniformemente entre todas las VM disponibles. Las VM más pequeñas se pueden restringir antes de lo esperado en comparación con las VM más grandes, lo que da lugar a una experiencia de usuario negativa.
La disponibilidad de la región afecta a los datos o a la supervisión del área de trabajo. Si una región no está disponible, el servicio puede perder todos los datos históricos de supervisión durante un desastre. Se recomienda usar una exportación personalizada o un volcado de datos de supervisión históricos.
Se recomienda actualizar los hosts de sesión al menos una vez al mes. Esta recomendación se aplica a los hosts de sesión que se mantienen desactivados durante largos períodos de tiempo.
Para probar la implementación, ejecute una conmutación por error controlada al menos una vez cada seis meses. Parte de la conmutación por error controlada podría significar que la ubicación secundaria se convierte en principal hasta la siguiente conmutación por error controlada. Cambiar la ubicación secundaria a principal permite a los usuarios tener perfiles casi idénticos durante un desastre real.
En la tabla siguiente se enumeran las recomendaciones de implementación para las estrategias de recuperación ante desastres del grupo de hosts:
| Tecnología | Recomendaciones |
|---|---|
| Red | Cree e implemente una red virtual secundaria en otra región y configure el emparejamiento de Azure con la red virtual principal. |
| Hosts de sesión | Cree e implemente un grupo de hosts compartidos de Azure Virtual Desktop con SKU de sistema operativo de varias sesiones e incluya VM de otras zonas de disponibilidad y otra región. |
| Almacenamiento | Cree cuentas de almacenamiento en varias regiones mediante cuentas de nivel Premium. |
| Datos de perfil de usuario | Cree ubicaciones de almacenamiento SMB en varias regiones. |
| Identidad | Controladores de dominio de Active Directory del mismo directorio. |
Recuperación ante desastres para grupos de hosts personales
En el caso de los grupos de hosts personales, la estrategia de recuperación ante desastres debe implicar la replicación de los recursos en una región secundaria mediante el almacén de Azure Site Recovery Services. Si la región primaria deja de funcionar durante un desastre, Azure Site Recovery puede conmutar por error y activar los recursos de la región secundaria.
Por ejemplo, supongamos que tiene que hacer una implementación con una región primaria en el Oeste de EE. UU. y una región secundaria en el Este de EE. UU. La región primaria tiene un grupo de hosts personal con dos hosts de sesión cada uno. Cada host de sesión tiene su propio disco local que contiene los datos del perfil de usuario y su propia red virtual que no está emparejada con nada. Si se produce un desastre, puede usar Azure Site Recovery para conmutar por error a la región secundaria del Este de EE. UU. (o a una zona de disponibilidad diferente en la misma región). A diferencia de la región primaria, la región secundaria no tiene máquinas ni discos locales. Durante la conmutación por error, Azure Site Recovery toma los datos replicados del almacén de recuperación del sitio de Azure y los usa para crear dos VM nuevas que son copias de los hosts de sesión originales, incluidos los datos del disco local y del perfil de usuario. La región secundaria tiene su propia red virtual independiente, por lo que la red virtual que se queda sin conexión en la región primaria no afectará a la funcionalidad.
En el diagrama siguiente se muestra la implementación de ejemplo que acabamos de describir.
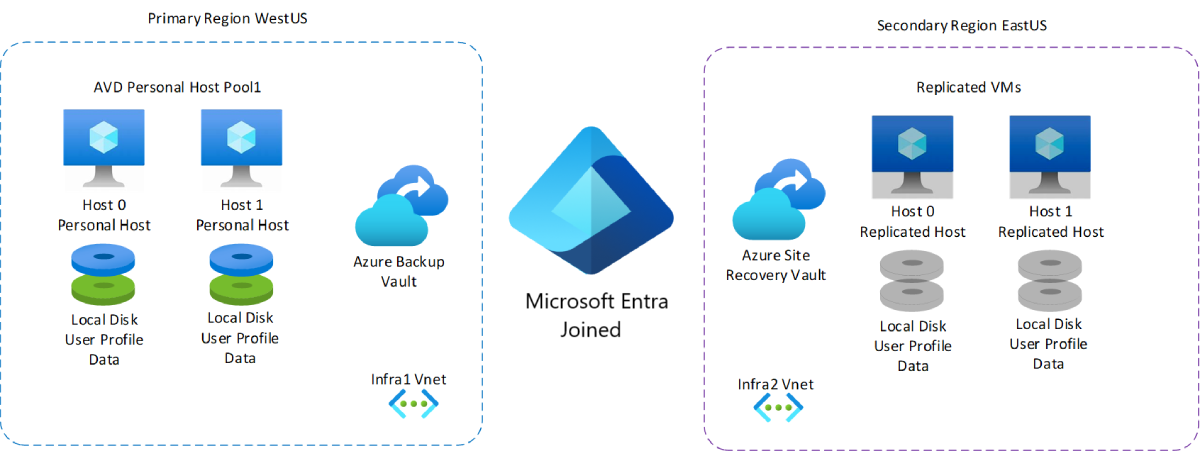
Las ventajas de este plan incluyen un costo general menor y no requieren mantenimiento para aplicar revisiones o actualizaciones debido a que los recursos solo se aprovisionan cuando los necesita. Sin embargo, un posible inconveniente es que tendrá que dedicar más tiempo a aprovisionar, integrar y validar la infraestructura de conmutación por error, al contrario de lo que sucede con una configuración de recuperación ante desastres del grupo de hosts compartido.
Información importante sobre la recuperación del grupo de hosts personal
Al usar esta estrategia de recuperación ante desastres, es importante tener en cuenta lo siguiente:
Puede haber requisitos que soliciten que las VM del grupo de hosts deben funcionar en el sitio secundario, como redes virtuales, subredes, seguridad de red o VPN para acceder a un directorio como Active Directory local.
Nota:
Si usa una máquina virtual unida a Microsoft Entra, algunos de estos requisitos se cumplirán automáticamente.
Puede experimentar problemas de integración, rendimiento o contención de recursos si un desastre a gran escala afecta a varios clientes o inquilinos.
Los grupos de hosts personales usan VM dedicadas a un usuario, lo que significa que las reglas de equilibrio de carga de afinidad dirigen todas las sesiones de usuario a una VM específica. Esta asignación de tipo individual entre el usuario y la VM significa que, si una VM está inactiva, el usuario no podrá iniciar sesión hasta que esta vuelva a estar en línea o se recupere una vez finalizada la recuperación ante desastres.
Las VM de un grupo de hosts personal almacenan el perfil de usuario en la unidad C, lo que significa que FSLogix no es necesario.
La disponibilidad de la región afecta a los datos o a la supervisión del área de trabajo. Si una región no está disponible, el servicio puede perder todos los datos históricos de supervisión durante un desastre. Se recomienda usar una exportación personalizada o un volcado de datos de supervisión históricos.
Se recomienda evitar el uso de FSLogix al usar una configuración de grupo de hosts personal.
El aprovisionamiento de máquinas virtuales no está garantizado en la región de conmutación por error.
Ejecute pruebas de conmutación por error y de conmutación por recuperación controladas al menos una vez cada seis meses.
En la tabla siguiente se enumeran las recomendaciones de implementación para las estrategias de recuperación ante desastres del grupo de hosts:
| Tecnología | Recomendaciones |
|---|---|
| Red | Cree e implemente una red virtual secundaria en otra región para seguir las convenciones de nomenclatura personalizadas o los requisitos de seguridad fuera del esquema de nomenclatura predeterminado de Azure Site Recovery. |
| Hosts de sesión | Habilite y configure Azure Site Recovery para VM. Opcionalmente, puede preconfigurar una imagen de forma manual o usar el servicio Azure Image Builder para el aprovisionamiento continuo. |
| Almacenamiento | La creación de una cuenta de Azure Storage es opcional para almacenar perfiles. |
| Datos de perfil de usuario | Los datos del perfil del usuario se almacenan localmente en la unidad C. |
| Identidad | Controladores de dominio de Active Directory del mismo directorio en varias regiones. |
Pasos siguientes
Para obtener más información detallada sobre la recuperación ante desastres en Azure, consulte estos artículos:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de