Uso de la API de datos del sector como motor de extracción, transformación y carga (ETL) (versión preliminar)
Importante
Las API de la versión /beta de Microsoft Graph están sujetas a cambios. No se admite el uso de estas API en aplicaciones de producción. Para determinar si una API está disponible en la versión 1.0, use el selector de Versión.
La API de datos del sector es una plataforma ETL (Extract-Transform-Load) centrada en el sector educativo que combina datos de varios orígenes en un único almacén de datos de Azure Data Lake, normaliza los datos y los exporta en flujos salientes. La API proporciona recursos que puede usar para obtener estadísticas después de procesar los datos y ayudar con la supervisión y la solución de problemas.
La API de datos del sector se define en el subnombre de OData.microsoft.graph.industryData
Api de datos del sector y educación
La API de datos del sector impulsa la plataforma de Microsoft School Data Sync (SDS) para ayudar a automatizar el proceso de importación de datos y sincronización de organizaciones, asociaciones de usuarios y usuarios, y grupos con Microsoft Entra ID y Microsoft 365 desde sistemas de información de estudiantes (SIS) y sistemas de administración de estudiantes (SMS). Después de normalizar los datos, la API utiliza los datos a través de varios flujos de aprovisionamiento salientes para administrar usuarios, grupos de clases, unidades administrativas y grupos de seguridad.
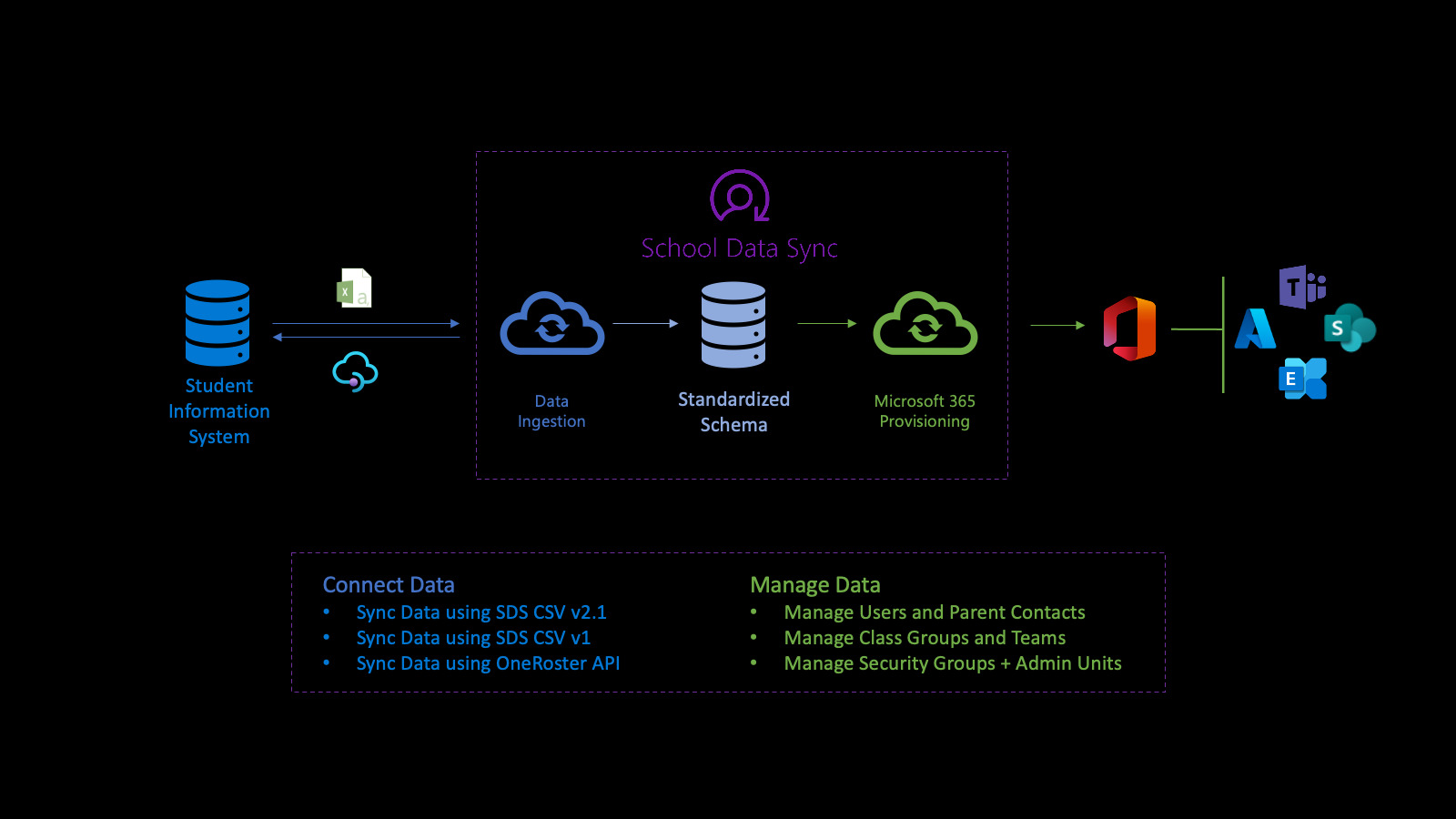
En primer lugar, se conecta a los datos de la institución. Para definir un flujo de entrada, cree un sourceSystemDefinition, dataConnector y yearTimePeriodDefinition. De forma predeterminada, el flujo de entrada se activa dos veces (2 veces) al día (denominada ejecución).
Cuando se inicia la ejecución, se conecta a sourceSystemDefinition y dataConnector del flujo de entrada y realiza la validación básica. La validación básica garantiza que la conexión es correcta, cuando la API de OneRoster es el origen o los nombres de archivo y encabezados son correctos, cuando un CSV es el origen.
A continuación, el sistema transforma los datos para importarlos como preparación para la validación avanzada. Como parte de la transformación de datos, los datos se asocian en función de la yearTimePeriodDefinition configurada.
El sistema almacena la copia más reciente de la Microsoft Entra ID del inquilino en Azure Data Lake. La copia del Microsoft Entra ayuda a que el usuario coincida entre sourceSystemDefinition y el objeto de usuario Microsoft Entra. En esta fase, el vínculo de coincidencia solo se escribe en Azure Data Lake.
A continuación, el flujo de entrada realiza una validación avanzada para determinar el estado de los datos. La validación se centra en la identificación de errores y advertencias para asegurarse de que entran datos buenos y que los datos incorrectos permanecen fuera. Los errores indican que un registro no superó la validación y se quitó del procesamiento adicional. Las advertencias indican que el valor de un campo opcional de un registro no se ha superado. El valor se quita del registro, pero se incluye para su posterior procesamiento.
Los errores y advertencias le ayudan a comprender mejor el estado de los datos.
Para los datos que pasaron la validación, el proceso usa yearTimePeriodDefinition configurado para determinar su asociación para el almacenamiento longitudinal, como se indica a continuación:
- A medida que los datos se almacenan la representación interna en Azure Data Lake del inquilino, identifica cuándo los han visto por primera vez los datos del sector.
- En el caso de los datos vinculados con una organización de usuario, una asociación de roles y una asociación de grupo, también identifica los datos como activos en la sesión según yearTimePeriodDefinition.
- En ejecuciones futuras, para el mismo flujo de entrada, sourceSystemDefinition y yearTimePeriodDefinition, los datos del sector identifican si el registro se sigue viendo.
- En función de la presencia o ausencia de registro, el registro se mantiene activo o marcado como no activo en la sesión para el yearTimePeriodDefinition configurado. Este proceso determina la naturaleza histórica y longitudinal de los datos entre días, meses y años.
Al final de cada ejecución, industryDataRunStatistics está disponible para determinar el estado de los datos.
Se generan errores y advertencias relacionados con industryDataRunStatistics para ayudar a proporcionar una comprensión inicial del estado de los datos. Al investigar el estado de los datos, los datos del sector proporcionan la capacidad de descargar un archivo de registro que contiene información basada en los errores y advertencias encontrados para iniciar el proceso de investigación de datos para corregir los datos en el sistema de origen.
Después de investigar y solucionar los errores o advertencias de datos, cuando se sienta cómodo con el estado actual del estado de los datos, puede habilitar los escenarios con los datos. Al habilitar un escenario para usar estos datos, el escenario crea un flujo de aprovisionamiento saliente.
La administración de datos a través de flujos de aprovisionamiento saliente simplifica la administración de usuarios y clases. Solo los usuarios activos y coincidentes se incluyen en los datos que se usan para escribir el vínculo en el objeto de usuario Microsoft Entra. Este vínculo facilita la integración entre el SIS/SMS y sus secciones para grupos y clases de Microsoft Teams.
Para obtener más información, consulte las secciones Sincronización de datos escolares, requisitos previos de SDS y conceptos básicos de SDS de la introducción a School Data Sync.
Registro, permisos y autorización
Puede integrar las API de datos del sector con aplicaciones de terceros. Para obtener más información sobre cómo hacerlo, consulte los artículos siguientes:
- Conceptos básicos de autenticación y autorización.
- Registre una aplicación con el Plataforma de identidad de Microsoft.
- Obtenga acceso en nombre de un usuario.
- Referencia de permisos de Microsoft Graph.
- Resolución de errores de autorización de Microsoft Graph.
Casos de uso comunes
| Caso de uso | Recurso REST | Consulte también |
|---|---|---|
| Creación de una actividad para importar un conjunto de datos delimitado | inboundFileFlow | métodos inboundFileFlow |
| Definición de un origen de datos entrantes | sourceSystemDefinition | métodos sourceSystemDefinition |
| Creación de un conector para publicar datos en Azure Data Lake (si es CSV) | azureDataLakeConnector | métodos azureDataLakeConnector |
Dominio de datos
La propiedad dataDomain define el tipo de datos que se importa y determina el formato de modelo de datos común en el que se va a almacenar. Actualmente, el único dataDomain compatible es educationRostering.
Definiciones de referencia
Un referenceDefinition representa un valor enumerado. Cada dominio del sector admitido recibe una colección distinta de definiciones. Los recursos referenceDefinition se usan ampliamente en todo el sistema, tanto para la configuración como para la transformación, donde los valores potenciales son específicos de un sector determinado. Cada referenceDefinition usa un identificador compuesto de {referenceType}-{code} para proporcionar una experiencia coherente entre los inquilinos del cliente.
Valores de referencia
Los tipos basados en referenceValue proporcionan una experiencia de desarrollador simplificada para enlazar recursos referenceDefinition . Cada tipo referenceValue está enlazado a un único tipo de referencia, lo que permite a los desarrolladores proporcionar solo la parte de código de la definición de referencia como una cadena simple y eliminar la posible confusión en cuanto al tipo de referenceDefinition que se espera de una propiedad determinada.
Ejemplo:
La propiedad userMatchingSettings.sourceIdentifier toma un tipo identifierTypeReferenceValue que se enlaza con referenceTypeRefIdentifierType.
"sourceIdentifier": {
"code": "username"
},
Un referenceDefinition también puede enlazarse directamente mediante la propiedad value .
"sourceIdentifier": {
"value@odata.bind": "external/industryData/referenceDefinitions/RefIdentifierType-username"
},
Grupos de funciones
La transformación de los datos suele estar definida por el rol de cada usuario individual dentro de una organización. Estos roles se definen como definiciones de referencia. Dado el número de roles potenciales, enlazar cada rol individual daría lugar a una experiencia de usuario tediosa. Los grupos de roles son una colección de RefRole códigos.
{
"@odata.type": "#microsoft.graph.industryDataRoleGroup",
"id": "37a9781b-db61-4a3c-a3c1-8cba92c9998e",
"displayName": "Staff",
"roles": [
{ "code": "adjunct" },
{ "code": "administrator" },
{ "code": "advisor" },
{ "code": "affiliate" },
{ "code": "aide" },
{ "code": "alumni" },
{ "code": "assistant" }
]
}
Conectores de datos del sector
Un industryDataConnector actúa como un puente entre un sourceSystemDefinition y un inboundFlow. Es responsable de adquirir datos de un origen externo y proporcionar los datos a los flujos de datos entrantes.
Carga y validación de datos CSV
Para obtener información sobre los datos CSV, consulte:
A continuación se indican los requisitos para el archivo CSV:
- Los nombres de archivo y los encabezados de columna distinguen mayúsculas de minúsculas.
- Los archivos CSV deben estar en formato UTF-8.
- Los datos entrantes no deben tener saltos de línea.
Para revisar y descargar el conjunto de ejemplo de archivos CSV SDS V2.1, consulte el repositorio de GitHub de SDS.
Importante
IndustryDataConnector no acepta cambios diferenciales, por lo que cada sesión de carga debe contener el conjunto de datos completo. Proporcionar solo datos parciales o diferenciales da como resultado la transición de los registros que faltan a un estado inactivo.
Solicitud de una sesión de carga
AzureDataLakeConnector usa archivos CSV cargados en un contenedor seguro. Este contenedor reside en el contexto de un único archivoUploadSession y se destruye automáticamente después de que expire la validación de datos o la sesión de carga de archivos.
La sesión de carga de archivos actual se recupera de azureDataLakeConnector a través de getUploadSession que devuelve la dirección URL de SAS para cargar los archivos CSV.
Validación de archivos cargados
Los archivos de datos cargados deben validarse antes de que un flujo de entrada pueda procesar los datos. El proceso de validación finaliza el archivo actualUploadSession y comprueba que todos los archivos necesarios están presentes y tienen el formato correcto. La validación se inicia llamando a la acción industryDataConnector: validate del recurso azureDataLakeConnector .
La acción validate crea un archivo de ejecución prolongadaValidateOperation. El URI de fileValidateOperation se proporciona en el Location encabezado de la respuesta. Puede usar este URI para realizar un seguimiento del estado de la operación de ejecución prolongada y de los errores o advertencias creados durante la validación.
Pasos siguientes
Use las API de datos del sector de Microsoft Graph como motor de extracción, transformación y carga (ETL). Para obtener más información:
- Explore los recursos y los métodos que son más útiles para su escenario.
- Pruebe la API en el Probador de Graph.
Contenido relacionado
Introducción a la API de datos del sector en Microsoft Graph
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de