Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
En este artículo se dirige a profesionales de TI y administradores de TI. Obtendrá información sobre la arquitectura de la solución de BI en el COE y las distintas tecnologías empleadas. Las tecnologías incluyen Azure, Power BI y Excel. Juntos, se pueden aprovechar para ofrecer una plataforma de BI en la nube escalable y controlada por datos.
Diseñar una plataforma de BI sólida es algo parecido a crear un puente; un puente que conecta los datos de origen transformados y enriquecidos a los consumidores de datos. El diseño de una estructura tan compleja requiere una mentalidad de ingeniería, aunque puede ser una de las arquitecturas de TI más creativas y gratificantes que podría diseñar. En una organización grande, una arquitectura de solución de BI puede constar de:
- Orígenes de datos
- Ingesta de datos
- Preparación de macrodatos y datos
- Almacenamiento de datos
- Modelos semánticos de BI
- Informes
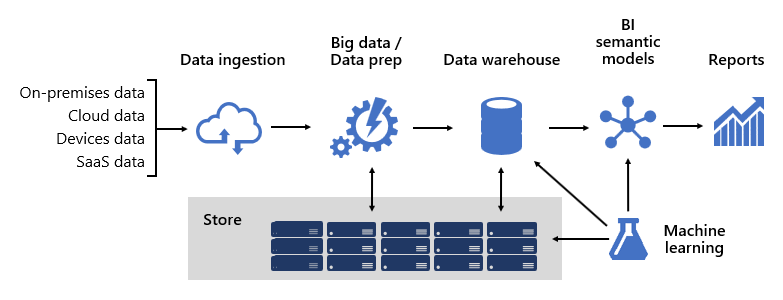
La plataforma debe admitir demandas específicas. En concreto, debe escalar y realizar para satisfacer las expectativas de los servicios empresariales y los consumidores de datos. Al mismo tiempo, debe estar seguro desde la base. Y, debe ser lo suficientemente resistente para adaptarse al cambio, ya que es una certeza de que en el tiempo se deben poner en línea nuevos datos y áreas temáticas.
Marcos de trabajo
En Microsoft, desde el principio adoptamos un enfoque similar a sistemas al invertir en el desarrollo del marco. Los marcos de procesos técnicos y empresariales aumentan la reutilización del diseño y la lógica y proporcionan un resultado coherente. También ofrecen flexibilidad en la arquitectura aprovechando muchas tecnologías y simplifican y reducen la sobrecarga de ingeniería a través de procesos repetibles.
Hemos aprendido que los marcos bien diseñados aumentan la visibilidad del linaje de datos, el análisis de impacto, el mantenimiento de la lógica empresarial, la administración de la taxonomía y la simplificación de la gobernanza. Además, el desarrollo se volvió más rápido y la colaboración entre equipos grandes se volvió más dinámico y eficaz.
Describiremos varios de nuestros marcos en este artículo.
Modelos de datos
Los modelos de datos proporcionan control sobre cómo se estructuran y acceden a los datos. Para los servicios empresariales y los consumidores de datos, los modelos de datos son su interfaz con la plataforma de BI.
Una plataforma de BI puede ofrecer tres tipos diferentes de modelos:
- Modelos empresariales
- Modelos semánticos de BI
- Modelos de Machine Learning (ML)
Modelos empresariales
Los arquitectos de TI crean y mantienen los modelos empresariales. A veces se conocen como modelos dimensionales o data marts. Normalmente, los datos se almacenan en formato relacional como tablas de dimensiones y hechos. Estas tablas almacenan datos limpios y enriquecidos consolidados de muchos sistemas y representan un origen autoritativo para informes y análisis.
Los modelos empresariales proporcionan un origen coherente y único de datos para informes y BI. Se crean una vez y se comparten como estándar corporativo. Las directivas de gobernanza garantizan que los datos son seguros, por lo que el acceso a conjuntos de datos confidenciales (como la información del cliente o las finanzas) está restringido por necesidades. Adoptan convenciones de nomenclatura que garantizan la coherencia, con lo que se establece la credibilidad de los datos y la calidad.
En una plataforma de BI en la nube, los modelos empresariales se pueden implementar en un grupo de SQL de Synapse en Azure Synapse. A continuación, el grupo de SQL de Synapse se convierte en la única versión de verdad en la que la organización puede confiar para obtener información rápida y confiable.
Modelos semánticos de BI
Los modelos semánticos de BI representan una capa semántica sobre los modelos empresariales. Están compiladas y mantenidas por desarrolladores de BI y usuarios empresariales. Los desarrolladores de BI crean modelos semánticos principales de BI que generan datos de modelos empresariales. Los usuarios empresariales pueden crear modelos independientes o a escala más pequeños, o bien, pueden ampliar los modelos semánticos principales de BI con orígenes departamentales o externos. Los modelos semánticos de BI suelen centrarse en una sola área de asunto y suelen compartirse ampliamente.
Las funcionalidades empresariales están habilitadas no solo por datos, sino por modelos semánticos de BI que describen conceptos, relaciones, reglas y estándares. De este modo, representan estructuras intuitivas y fáciles de entender que definen relaciones de datos y encapsulan reglas de negocio como cálculos. También pueden aplicar permisos de datos específicos, lo que garantiza que las personas adecuadas tengan acceso a los datos adecuados. Lo importante es que aceleran el rendimiento de las consultas, lo que proporciona análisis interactivos extremadamente dinámicos, incluso más de terabytes de datos. Al igual que los modelos empresariales, los modelos semánticos de BI adoptan convenciones de nomenclatura que garantizan la coherencia.
En una plataforma de BI en la nube, los desarrolladores de BI pueden implementar modelos semánticos de BI en Azure Analysis Services, en las capacidades de Power BI Premium o en las capacidades de Microsoft Fabric.
Importante
En este artículo se hace referencia a Power BI Premium o a sus suscripciones de capacidad (SKU P). Actualmente, Microsoft está consolidando las opciones de compra y retirando las SKU de Power BI Premium por capacidad. Los clientes nuevos y existentes deben considerar la posibilidad de comprar suscripciones de capacidad de Fabric (SKU F) en su lugar.
Para obtener más información, consulte Actualización importante sobre las licencias de Power BI Premium y Preguntas más frecuentes sobre Power BI Premium.
Se recomienda implementar en Power BI cuando se usa como capa de informes y análisis. Estos productos admiten diferentes modos de almacenamiento, lo que permite que las tablas del modelo de datos almacenen en caché sus datos o usen DirectQuery, que es una tecnología que pasa consultas al origen de datos subyacente. DirectQuery es un modo de almacenamiento ideal cuando las tablas del modelo representan grandes volúmenes de datos o es necesario proporcionar resultados casi en tiempo real. Los dos modos de almacenamiento se pueden combinar: los modelos compuestos combinan tablas que usan diferentes modos de almacenamiento en un único modelo.
Para los modelos muy consultados, Azure Load Balancer se puede usar para distribuir uniformemente la carga de consultas entre réplicas del modelo. También permite escalar las aplicaciones y crear modelos semánticos de BI de alta disponibilidad.
Modelos de Machine Learning
Los científicos de datos crean y mantienen los modelos de Machine Learning (ML). Se desarrollan principalmente a partir de orígenes sin procesar en el lago de datos.
Los modelos de aprendizaje automático entrenados pueden revelar patrones dentro de sus datos. En muchas circunstancias, esos patrones se pueden usar para realizar predicciones que se pueden usar para enriquecer los datos. Por ejemplo, el comportamiento de compra se puede usar para predecir la renovación de clientes o segmentar clientes. Los resultados de predicción se pueden agregar a los modelos empresariales para permitir el análisis por segmento de cliente.
En una plataforma de BI en la nube, puede usar Azure Machine Learning para entrenar, implementar, automatizar, administrar y realizar un seguimiento de los modelos de ML.
Almacenamiento de datos
En el corazón de una plataforma de BI está el almacén de datos, que hospeda los modelos empresariales. Es una fuente de datos autorizada, actuando como un sistema de registro y como un centro, que proporciona servicios a los modelos empresariales para informes, inteligencia empresarial y ciencia de datos.
Muchos servicios empresariales, incluidas las aplicaciones de línea de negocio (LOB), pueden confiar en el almacenamiento de datos como una fuente autoritativa y regulada de conocimientos empresariales.
En Microsoft, nuestro almacenamiento de datos se hospeda en Azure Data Lake Storage Gen2 (ADLS Gen2) y Azure Synapse Analytics.
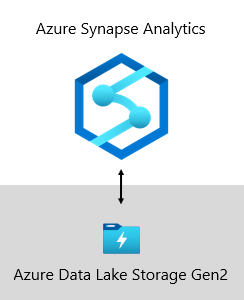
- ADLS Gen2 hace de Azure Storage la base para crear lagos de datos empresariales en Azure. Está diseñado para proporcionar varios petabytes de información, al mismo tiempo que mantiene un rendimiento de cientos de gigabits. Además, ofrece capacidad de almacenamiento y transacciones de bajo costo. Además, admite el acceso compatible con Hadoop, lo que le permite administrar y acceder a datos como lo haría con un sistema de archivos distribuido de Hadoop (HDFS). De hecho, Azure HDInsight, Azure Databricks y Azure Synapse Analytics pueden acceder a los datos almacenados en ADLS Gen2. Por lo tanto, en una plataforma de BI, es una buena opción almacenar datos de origen sin procesar, datos semiprocesados o almacenados provisionalmente, y datos listos para producción. Lo usamos para almacenar todos nuestros datos empresariales.
- Azure Synapse Analytics es un servicio de análisis que reúne el almacenamiento de datos empresariales y el análisis de macrodatos. Ofrece la libertad de consultar datos en sus términos, usando recursos a demanda sin servidor o aprovisionados, a escala. Synapse SQL, un componente de Azure Synapse Analytics, admite análisis completos basados en T-SQL, por lo que es ideal hospedar modelos empresariales que comprenden las tablas de dimensiones y hechos. Las tablas se pueden cargar eficazmente desde ADLS Gen2 mediante consultas simples de T-SQL de Polybase . A continuación, tiene la potencia de MPP para ejecutar análisis de alto rendimiento.
Marco del motor de reglas de negocios
Hemos desarrollado un marco de motor de reglas de negocios (BRE) para catalogar cualquier lógica de negocios que se pueda implementar en la capa de almacenamiento de datos. Un BRE puede significar muchas cosas, pero en el contexto de un almacenamiento de datos resulta útil para crear columnas calculadas en tablas relacionales. Estas columnas calculadas normalmente se representan como cálculos matemáticos o expresiones mediante instrucciones condicionales.
La intención es dividir la lógica de negocios del código de BI principal. Tradicionalmente, las reglas de negocio se codifican de forma rígida en procedimientos almacenados de SQL, por lo que a menudo resulta mucho esfuerzo para mantenerlas cuando cambian las necesidades empresariales. En un BRE, las reglas de negocio se definen una vez y se usan varias veces cuando se aplican a diferentes entidades de almacenamiento de datos. Si la lógica de cálculo necesita cambiar, solo debe actualizarse en un solo lugar y no en numerosos procedimientos almacenados. También hay una ventaja lateral: un marco de BRE impulsa la transparencia y la visibilidad de la lógica de negocios implementada, que se puede exponer a través de un conjunto de informes que crean documentación de actualización automática.
Orígenes de datos
Un almacenamiento de datos puede consolidar datos desde prácticamente cualquier origen de datos. Se basa principalmente en orígenes de datos LOB, que suelen ser bases de datos relacionales que almacenan datos específicos del sujeto para ventas, marketing, finanzas, etc. Estas bases de datos se pueden hospedar en la nube o pueden residir en el entorno local. Otros orígenes de datos pueden basarse en archivos, especialmente registros web o datos IOT procedentes de dispositivos. Además, los datos se pueden obtener de proveedores de software como servicio (SaaS).
En Microsoft, algunos de nuestros sistemas internos transmiten datos operativos directamente a ADLS Gen2 usando formatos de archivo raw. Además de nuestro lago de datos, otros sistemas de origen incluyen aplicaciones LOB relacionales, libros de Excel, otros orígenes basados en archivos, Gestión de Datos Maestros (MDM) y repositorios de datos a medida. Los repositorios mdm nos permiten administrar nuestros datos maestros para garantizar versiones autoritativas, estandarizadas y validadas de datos.
Ingesta de datos
De forma periódica, y según los ritmos de la empresa, los datos se ingieren de los sistemas de origen y se cargan en el almacenamiento de datos. Podría ser una vez al día o a intervalos más frecuentes. La ingesta de datos se refiere a la extracción, transformación y carga de datos. O bien, quizás el orden inverso: extraer, cargar y luego transformar datos. La diferencia se reduce a dónde se lleva a cabo la transformación. Las transformaciones se aplican para limpiar, cumplir, integrar y estandarizar los datos. Para obtener más información, consulte Extracción, transformación y carga (ETL).
En última instancia, el objetivo es cargar los datos correctos en el modelo empresarial lo más rápido y eficaz posible.
En Microsoft, usamos Azure Data Factory (ADF). Los servicios se usan para programar y orquestar validaciones de datos, transformaciones y cargas masivas de sistemas de origen externos en nuestro lago de datos. Se administra mediante marcos personalizados para procesar datos en paralelo y a escala. Además, se lleva a cabo un registro completo para admitir la solución de problemas, la supervisión del rendimiento y desencadenar notificaciones de alerta cuando se cumplen condiciones específicas.
Mientras tanto, Azure Databricks(plataformas de análisis basadas en Apache Spark optimizadas para la plataforma de servicios en la nube de Azure) realiza transformaciones específicamente para la ciencia de datos. También compila y ejecuta modelos de ML mediante cuadernos de Python. Las puntuaciones de estos modelos de ML se cargan en el almacenamiento de datos para integrar predicciones con informes y aplicaciones empresariales. Dado que Azure Databricks accede directamente a los archivos del lago de datos, elimina o minimiza la necesidad de copiar o adquirir datos.
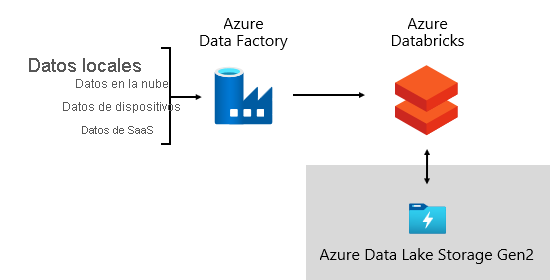
Marco de ingestión
Hemos desarrollado un framework de ingestión como un conjunto de tablas y procedimientos de configuración. Admite un enfoque controlado por datos para adquirir grandes volúmenes de datos a alta velocidad y con código mínimo. En resumen, este marco simplifica el proceso de adquisición de datos para cargar el almacenamiento de datos.
El marco depende de las tablas de configuración que almacenan información relacionada con el origen de datos y el destino de datos, como el tipo de origen, el servidor, la base de datos, el esquema y los detalles relacionados con la tabla. Este enfoque de diseño significa que no es necesario desarrollar canalizaciones de ADF específicas ni paquetes de SQL Server Integration Services (SSIS). En su lugar, los procedimientos se escriben en el lenguaje de nuestra elección para crear canalizaciones de ADF que se generan y ejecutan dinámicamente en tiempo de ejecución. Por lo tanto, la adquisición de datos se convierte en un ejercicio de configuración que se operacionaliza fácilmente. Tradicionalmente, requeriría recursos de desarrollo extensos para crear paquetes ADF o SSIS codificados de forma rígida.
El marco de ingesta se diseñó para simplificar también el proceso de gestión de los cambios de esquema de fuente aguas arriba. Es fácil actualizar los datos de configuración, manual o automáticamente, cuando se detectan cambios de esquema para adquirir atributos recién agregados en el sistema de origen.
Marco de orquestación
Hemos desarrollado un marco de orquestación para operacionalizar y organizar nuestras canalizaciones de datos. El marco de orquestación usa un diseño controlado por datos que depende de un conjunto de tablas de configuración. Estas tablas almacenan metadatos que describen las dependencias de canalización y cómo asignar datos de origen a estructuras de datos de destino. La inversión en el desarrollo de este marco adaptable ha pagado por sí misma; ya no es necesario codificar de forma rígida cada movimiento de datos.
Almacenamiento de datos
Un lago de datos puede almacenar grandes volúmenes de datos sin procesar para su uso posterior junto con transformaciones de preparación de datos.
En Microsoft, usamos ADLS Gen2 como nuestra única fuente de verdad. Almacena datos sin procesar junto con datos preconfigurados y datos listos para producción. Proporciona una solución de lago de datos altamente escalable y rentable para el análisis de macrodatos. Combinando la potencia de un sistema de archivos de alto rendimiento con una escala masiva, está optimizado para cargas de trabajo de análisis de datos, lo que acelera el tiempo para obtener información valiosa.
ADLS Gen2 proporciona lo mejor de dos mundos: blob storage y un espacio de nombres de sistema de archivos de alto rendimiento, que configuramos con permisos de acceso específicos.
A continuación, los datos refinados se almacenan en una base de datos relacional para ofrecer un almacén de datos de alto rendimiento y altamente escalable para modelos empresariales, con seguridad, gobernanza y capacidad de administración. Los data marts específicos del tema se almacenan en Azure Synapse Analytics, que se cargan mediante consultas de Azure Databricks, o Polybase T-SQL.
Consumo de datos
En la capa de informes, los servicios empresariales consumen datos empresariales procedentes del almacenamiento de datos. También acceden a los datos directamente en el lago de datos para realizar análisis ad hoc o tareas de ciencia de datos.
Los permisos específicos se aplican en todas las capas: en el lago de datos, los modelos empresariales y los modelos semánticos de BI. Los permisos garantizan que los consumidores de datos solo puedan ver los datos a los que tienen derechos de acceso.
En Microsoft, usamos informes y paneles de Power BI y informes paginados de Power BI. Algunos informes y análisis ad hoc se realizan en Excel, especialmente para los informes financieros.
Publicamos diccionarios de datos, que proporcionan información de referencia sobre nuestros modelos de datos. Están disponibles para nuestros usuarios para que puedan descubrir información sobre nuestra plataforma de BI. Los diccionarios documenten diseños de modelos, proporcionando descripciones sobre entidades, formatos, estructura, linaje de datos, relaciones y cálculos. Usamos Azure Data Catalog para que nuestros orígenes de datos sean fáciles de detectar y comprender.
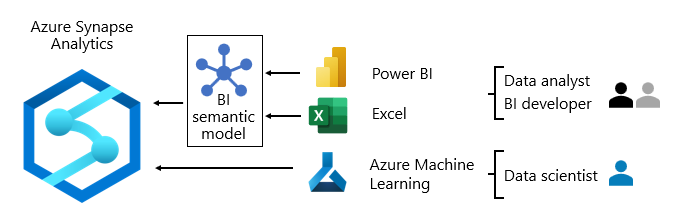
Normalmente, los patrones de consumo de datos difieren en función del rol:
- Los analistas de datos se conectan directamente a los modelos semánticos de BI principales. Cuando los modelos semánticos principales de BI contienen todos los datos y la lógica que necesitan, usan conexiones dinámicas para crear informes y paneles de Power BI. Cuando necesiten ampliar los modelos con datos de departamento, crean modelos compuestos de Power BI. Si hay necesidad de informes de estilo de hoja de cálculo, usan Excel para generar informes basados en modelos semánticos de BI principales o modelos semánticos de BI departamentales.
- Los desarrolladores de BI y los autores de informes operativos se conectan directamente a los modelos empresariales. Usan Power BI Desktop para crear informes analíticos de conexión dinámica. También pueden crear informes de BI de tipo operativo como informes paginados de Power BI, escribir consultas SQL nativas para acceder a los datos de los modelos empresariales de Azure Synapse Analytics mediante T-SQL o modelos semánticos de Power BI mediante DAX o MDX.
- Los científicos de datos se conectan directamente a los datos del lago de datos. Usan Azure Databricks y cuadernos de Python para desarrollar modelos de aprendizaje automático, que suelen ser experimentales y requieren habilidades especializadas para su uso en producción.
Contenido relacionado
Para obtener más información sobre este artículo, consulte los siguientes recursos:
- Hoja de ruta para la adopción de infraestructura: Centro de Excelencia
- BI empresarial en Azure con Azure Synapse Analytics
- ¿Preguntas? Pruebe a preguntar a la comunidad de Fabric
- ¿Sugerencias? Contribuir con ideas para mejorar Fabric
Servicios profesionales
Los asociados certificados de Power BI están disponibles para ayudar a su organización a tener éxito al configurar un COE. Pueden proporcionarle entrenamiento rentable o una auditoría de los datos. Para buscar un asociado de Power BI, visite el portal de asociados de Microsoft Power BI.
También puede interactuar con asociados de consultoría experimentados. Pueden ayudarle a evaluar, evaluar o implementar Power BI.