Guía de arquitectura de subprocesos y tareas
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Programación de tareas del sistema operativo
Los subprocesos son las unidades de procesamiento más pequeñas que ejecuta un sistema operativo y permiten que la lógica de la aplicación se separe en varias rutas de acceso de ejecución simultáneas. Los subprocesos son útiles cuando se trabaja con aplicaciones complejas que tienen muchas tareas que pueden ejecutarse a la vez.
Cuando un sistema operativo ejecuta una instancia de una aplicación, crea una unidad llamada proceso para administrar la instancia. El proceso contiene un subproceso de ejecución. Se trata de una serie de instrucciones de programación que lleva a cabo el código de la aplicación. Por ejemplo, si una aplicación simple tiene un solo conjunto de instrucciones que se pueden ejecutar en serie, ese conjunto de instrucciones se administra como una tarea única y solo hay una ruta de ejecución (o subproceso) en la aplicación. Las aplicaciones más complejas pueden tener varias tareas que se podrían realizar de manera simultánea y no en serie. Para hacer esto, una aplicación puede iniciar procesos independientes para cada tarea, que es una operación que consume muchos recursos, o iniciar subprocesos independientes, que requieren menos recursos. Además, cada subproceso puede programarse para ejecutarse independientemente de los demás subprocesos asociados a un proceso.
Los subprocesos permiten a las aplicaciones complejas hacer más eficaz el uso de un procesador (CPU), incluso en los equipos con una única CPU. Con una CPU solo puede ejecutarse un subproceso cada vez. Si un subproceso ejecuta una operación de larga duración que no utilice la CPU, como la lectura o la escritura en disco, otro de los subprocesos puede ejecutarse mientras termina la primera operación. La capacidad de ejecutar unos subprocesos mientras otros esperan a que una operación finalice permite a las aplicaciones maximizar su uso de la CPU. Esto es especialmente cierto para las aplicaciones multiusuario y las que realizan numerosas E/S de disco, como un servidor de base de datos. Los equipos con varias CPU pueden ejecutar un subproceso en cada CPU al mismo tiempo. Por ejemplo, si un equipo dispone de ocho CPU, podrá ejecutar ocho subprocesos simultáneamente.
Programación de tareas de SQL Server
En el ámbito de SQL Server, una solicitud es la representación lógica de una consulta o lote. Una solicitud también representa las operaciones requeridas por los subprocesos del sistema, como el punto de control o el escritor de registros. Las solicitudes existen en varios estados a lo largo de su duración y pueden acumular esperas cuando no están disponibles los recursos necesarios para ejecutar la solicitud, como bloqueos o bloqueos temporales. Para más información sobre los estados de la solicitud, consulte sys.dm_exec_requests.
Tareas
Una tarea representa la unidad de trabajo que se debe completar para satisfacer la solicitud. Se pueden asignar una o varias tareas a una solicitud única.
- Las solicitudes paralelas tienen varias tareas activas que se ejecutan simultáneamente en lugar de ejecutarse en serie, con una tarea primaria (o una tarea de coordinación) y varias tareas secundarias. Un plan de ejecución para una solicitud paralela puede tener áreas o ramas en serie del plan con operadores que no se ejecutan en paralelo. La tarea primaria también es responsable de ejecutar esos operadores en serie.
- Las solicitudes en serie solo tienen una tarea activa en cualquier momento dado durante la ejecución. Las tareas existen en varios estados a lo largo de su duración. Para más información sobre los estados de la tarea, consulte sys.dm_os_tasks. Las tareas con un estado SUSPENDED están a la espera de que los recursos necesarios para ejecutar la tarea estén disponibles. Para obtener más información sobre las tareas en espera, consulte sys.dm_os_waiting_tasks.
Trabajadores
Un subproceso de trabajo de SQL Server, también conocido como trabajo o subproceso, es una representación lógica de un subproceso de sistema operativo. Cuando se ejecutan solicitudes en serie, el motor de base de datos de SQL Server genera un trabajo para ejecutar la tarea activa (1:1). Cuando se ejecutan solicitudes en paralelo en modo de fila, el motor de base de datos de SQL Server asigna un trabajo para coordinar los trabajos secundarios responsables de completar las tareas que tienen asignadas (también 1:1), denominado subproceso primario (o subproceso de coordinación). El subproceso primario tiene una tarea primaria asociada. El subproceso primario es el punto de entrada de la solicitud y existe incluso antes de que el motor analice una consulta. Las principales responsabilidades del subproceso principal son las siguientes:
- Coordinar un examen en paralelo.
- Iniciar trabajos secundarios en paralelo.
- Recopilar filas de subprocesos en paralelo y enviarlas al cliente.
- Realizar agregaciones locales y globales.
Nota:
Si un plan de consulta tiene ramas en serie y en paralelo, una de las tareas en paralelo se encargará de ejecutar la rama en serie.
El número de subprocesos de trabajo generados para cada tarea depende de:
Si la solicitud es válida para el paralelismo según lo determinado por el optimizador de consultas.
El grado de paralelismo (DOP) disponible real en el sistema en función de la carga actual. Esto puede diferir del DOP estimado, que está basado en la configuración del servidor para alcanzar el grado máximo de paralelismo (MAXDOP). Por ejemplo, la configuración de servidor para MAXDOP puede ser 8, pero el DOP disponible en tiempo de ejecución solo puede ser 2, lo que impacta en el rendimiento de la consulta. La presión de memoria y la falta de trabajadores son dos condiciones que reducen el DOP disponible en tiempo de ejecución.
Nota:
El límite del grado máximo de paralelismo (MAXDOP) se establece por tarea, no por solicitud. Esto significa que durante una ejecución de consulta en paralelo, una solicitud única puede generar varias tareas hasta alcanzar el límite MAXDOP, y que cada tarea usará un trabajo. Para más información sobre MAXDOP, consulte Establecer la opción de configuración del servidor Grado máximo de paralelismo.
Programadores
Un programador, conocido también como programador de SOS, administra los subprocesos de trabajo que requieren tiempo de procesamiento para hacer el trabajo en nombre de las tareas. Cada programador está asignado a un procesador individual (CPU). El tiempo que un trabajo puede permanecer activo en un programador se es el denominado cuanto del SO, con un máximo de 4 ms. Una vez que expira el tiempo de cuanto, un trabajo suspende su tiempo en favor de otros trabajos que necesitan acceder a los recursos de la CPU y cambia su estado. Esta cooperación entre los trabajos para maximizar el acceso a los recursos de la CPU se denomina programación cooperativa, también conocida como programación no preferente. A su vez, el cambio en el estado del trabajo se propaga a la tarea asociada con ese trabajo y a la solicitud asociada con la tarea. Para más información sobre los estados del trabajo, consulte sys.dm_os_workers. Para más información sobre los programadores, consulte sys.dm_os_schedulers.
En resumen, una solicitud puede generar una o varias tareas para llevar a cabo las unidades de trabajo. Cada tarea se asigna a un subproceso de trabajo responsable de completar la tarea. Cada subproceso de trabajo debe estar programado (ubicado en un programador) para la ejecución activa de la tarea.
Considere el caso siguiente:
- El trabajo 1 es una tarea de ejecución prolongada; por ejemplo, una consulta de lectura con lectura previa en tablas basadas en disco. El trabajo 1 determina si las páginas de datos necesarias están ya en el grupo de búferes, por lo que no tiene que esperar a que se produzcan las operaciones de E/S y puede consumir su cuanto completo antes de la suspensión.
- El trabajo 2 está realizando tareas por debajo de milisegundos más cortas y, por lo tanto, es necesario esperar antes de que se agote su cuanto completo.
En este escenario y hasta SQL Server 2014 (12.x), se permite que el trabajo 1 monopolice el programador porque tiene más tiempo de cuanto en general.
A partir de SQL Server 2016 (13.x), la programación cooperativa incluye la programación de tipo Déficit grande primero (LDF). Con la programación de LDF, se supervisan los patrones de uso del cuanto y un subproceso de trabajo no monopoliza un programador. En el mismo escenario, se permite que el trabajo 2 consuma repetidos cuantos antes de que el trabajo 1 tenga más cuanto, por lo que se evita que el trabajo 1 monopolice el programador de forma no deseada.
Programación de tareas paralelas
Imagine una instancia de SQL Server configurada con MaxDOP 8 y que la afinidad de CPU se ha configurado para 24 CPU (programadores) en los nodos NUMA 0 y 1. Los programadores del 0 al 11 pertenecen al nodo NUMA 0, y los programadores del 12 al 23 pertenecen al nodo NUMA 1. Una aplicación envía la siguiente consulta (solicitud) al motor de base de datos:
SELECT h.SalesOrderID,
h.OrderDate,
h.DueDate,
h.ShipDate
FROM Sales.SalesOrderHeaderBulk AS h
INNER JOIN Sales.SalesOrderDetailBulk AS d
ON h.SalesOrderID = d.SalesOrderID
WHERE (h.OrderDate >= '2014-3-28 00:00:00');
Sugerencia
La consulta de ejemplo se puede ejecutar con la base de datos de ejemplo AdventureWorks2016_EXT. Las tablas Sales.SalesOrderHeader y Sales.SalesOrderDetail se han agrandado 50 veces y se les ha cambiado el nombre a Sales.SalesOrderHeaderBulk y Sales.SalesOrderDetailBulk.
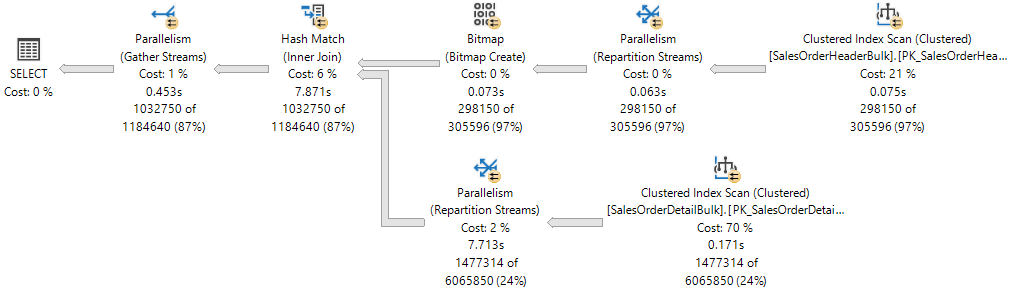
El plan de ejecución muestra una combinación hash entre dos tablas, y cada uno de los operadores se ejecutan en paralelo, tal y como se indica mediante el círculo amarillo con dos flechas. Cada operador de paralelismo es una rama diferente del plan. Por lo tanto, hay tres ramas en el plan de ejecución siguiente.
Nota:
Si considera un plan de ejecución como un árbol, una rama es un área del plan que agrupa uno o más operadores entre operadores de paralelismo, también denominados iteradores de Exchange. Para obtener más información sobre los operadores de plan, consulte Referencia de operadores lógicos y físicos del plan de presentación.
Aunque hay tres ramas en el plan de ejecución, en todo momento de la ejecución solo se pueden ejecutar de forma simultánea dos ramas de dicho plan:
- La rama en la que se utiliza un Examen de índice agrupado en
Sales.SalesOrderHeaderBulk(entrada de compilación de la combinación) se ejecuta sola. - Posteriormente, la rama en la que se utiliza un Examen de índice agrupado en
Sales.SalesOrderDetailBulk(entrada de sondeo de la combinación) se ejecuta simultáneamente con la rama en la que se ha creado el mapa de bits y en la que actualmente se ejecuta la coincidencia de hash.
El XML del plan de presentación muestra que en el nodo NUMA 0 se han reservado y usado 16 subprocesos de trabajo:
<ThreadStat Branches="2" UsedThreads="16">
<ThreadReservation NodeId="0" ReservedThreads="16" />
</ThreadStat>
La reserva de subprocesos garantiza que el motor de base de datos tenga suficientes subprocesos de trabajo para llevar a cabo todas las tareas necesarias para la solicitud. Los subprocesos se pueden reservar en varios nodos NUMA o en uno solo. La reserva de subprocesos se realiza en tiempo de ejecución antes de que se inicie la ejecución y depende de la carga del programador. El número de subprocesos de trabajo reservados se deriva genéricamente a partir de la fórmula ramas concurrent branches * runtime DOP y excluye el subproceso de trabajo primario. Cada rama está limitada a la cantidad de subprocesos de trabajo equivalente a MaxDOP. En este ejemplo hay dos ramas simultáneas y MaxDOP se establece en 8, por lo que 2 * 8 = 16.
Como referencia, observe el plan de ejecución activo de Estadísticas de consultas activas, donde se ha completado una rama y se están ejecutando dos ramas simultáneamente.
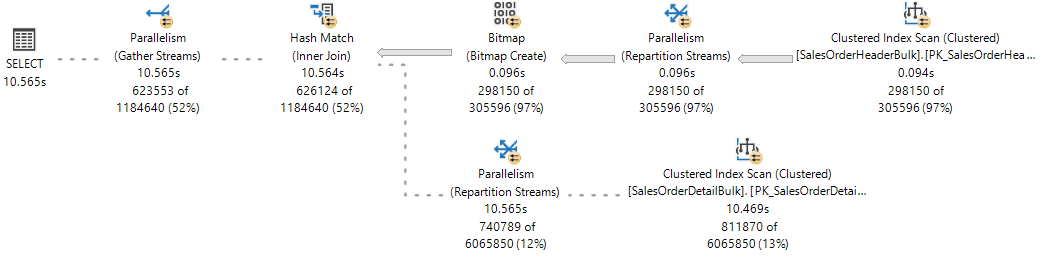
El motor de base de datos de SQL Server asigna un subproceso de trabajo para ejecutar una tarea activa (1:1), que se puede observar durante la ejecución de la consulta consultando la DMV sys.dm_os_tasks, como se observa en el ejemplo siguiente:
SELECT parent_task_address, task_address,
task_state, scheduler_id, worker_address
FROM sys.dm_os_tasks
WHERE session_id = <insert_session_id>
ORDER BY parent_task_address, scheduler_id;
Sugerencia
La columna parent_task_address siempre es NULL para la tarea primaria.
Sugerencia
En un motor de base de datos de SQL Server muy ocupado, es posible ver una cantidad de tareas activas superior al límite establecido por los subprocesos reservados. Estas tareas pueden pertenecer a una rama que ya no se está usando y que se encuentra en un estado transitorio, esperando la limpieza.
Este es el conjunto de resultados. Observe que hay 17 tareas activas para las ramas que se están ejecutando actualmente: 16 tareas secundarias correspondientes a los subprocesos reservados, además de la tarea primaria o la tarea de coordinación.
| parent_task_address | task_address | task_state | scheduler_id | worker_address |
|---|---|---|---|---|
| NULL | 0x000001EF4758ACA8 |
SUSPENDED | 3 | 0x000001EFE6CB6160 |
| 0x000001EF4758ACA8 | 0x000001EFE43F3468 | SUSPENDED | 0 | 0x000001EF6DB70160 |
| 0x000001EF4758ACA8 | 0x000001EEB243A4E8 | SUSPENDED | 0 | 0x000001EF6DB7A160 |
| 0x000001EF4758ACA8 | 0x000001EC86251468 | SUSPENDED | 5 | 0x000001EEC05E8160 |
| 0x000001EF4758ACA8 | 0x000001EFE3023468 | SUSPENDED | 5 | 0x000001EF6B46A160 |
| 0x000001EF4758ACA8 | 0x000001EFE3AF1468 | SUSPENDED | 6 | 0x000001EF6BD38160 |
| 0x000001EF4758ACA8 | 0x000001EFE4AFCCA8 | SUSPENDED | 6 | 0x000001EF6ACB4160 |
| 0x000001EF4758ACA8 | 0x000001EFDE043848 | SUSPENDED | 7 | 0x000001EEA18C2160 |
| 0x000001EF4758ACA8 | 0x000001EF69038108 | SUSPENDED | 7 | 0x000001EF6AEBA160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD8CA8 | SUSPENDED | 8 | 0x000001EFCB6F0160 |
| 0x000001EF4758ACA8 | 0x000001EFCFDD88C8 | SUSPENDED | 8 | 0x000001EF6DC46160 |
| 0x000001EF4758ACA8 | 0x000001EFBCC54108 | SUSPENDED | 9 | 0x000001EFCB886160 |
| 0x000001EF4758ACA8 | 0x000001EC86279468 | SUSPENDED | 9 | 0x000001EF6DE08160 |
| 0x000001EF4758ACA8 | 0x000001EFDE901848 | SUSPENDED | 10 | 0x000001EFF56E0160 |
| 0x000001EF4758ACA8 | 0x000001EF6DB32108 | SUSPENDED | 10 | 0x000001EFCC3D0160 |
| 0x000001EF4758ACA8 | 0x000001EC8628D468 | SUSPENDED | 11 | 0x000001EFBFA4A160 |
| 0x000001EF4758ACA8 | 0x000001EFBD3A1C28 | SUSPENDED | 11 | 0x000001EF6BD72160 |
Observe que cada una de las 16 tareas secundarias tiene un subproceso de trabajo diferente asignado (indicado en la columna worker_address), pero que todos los trabajos están asignados al mismo grupo de ocho programadores (0, 5, 6, 7, 8, 9, 10, 11) y que la tarea primaria está asignada a un programador fuera de este grupo (3).
Importante
Una vez que se programa el primer conjunto de tareas paralelas en una rama determinada, el motor de base de datos usará el mismo grupo de programadores para cualquier tarea adicional en otras ramas. Esto significa que se utilizará el mismo conjunto de programadores para todas las tareas paralelas en todo el plan de ejecución, limitado únicamente por MaxDOP.
El motor de base de datos de SQL Server siempre intentará asignar programadores desde el mismo nodo NUMA para la ejecución de la tarea y los asignará secuencialmente (en modo de distribución equilibrada) si hay programadores disponibles. Sin embargo, el subproceso de trabajo asignado a la tarea primaria se puede ubicar en otro nodo NUMA desde otras tareas.
Un subproceso de trabajo solo puede permanecer activo en el programador durante su cuanto (4 ms) y debe ceder su programador después de que haya transcurrido ese cuanto, de modo que un subproceso de trabajo asignado a otra tarea se pueda activar. Cuando el cuanto de un trabajo expira y ya no está activo, la tarea correspondiente se coloca en una cola FIFO en estado EJECUTABLE hasta pasar de nuevo al estado EN EJECUCIÓN, suponiendo que la tarea no requiera acceso a recursos que no están disponibles en ese momento, como un bloqueo temporal o un bloqueo, en cuyo caso la tarea se colocaría en estado SUSPENDIDO en lugar de EJECUTABLE, hasta que dichos recursos estén disponibles.
Sugerencia
Para la salida de la DMV anterior, todas las tareas activas están en estado SUSPENDIDO. Para obtener más información sobre las tareas en espera, consulte la DMV sys. dm_os_waiting_tasks.
En resumen, una solicitud paralela genera varias tareas. Cada tarea debe estar asignada a un único subproceso de trabajo. Cada subproceso de trabajo debe estar asignado a un único programador. Por lo tanto, el número de programadores en uso no puede superar el número de tareas paralelas por rama, establecido por la configuración de MaxDOP o la sugerencia de consulta. El subproceso de coordinación no contribuye al límite de MaxDOP.
Asignación de subprocesos a CPU
De manera predeterminada, cada instancia de SQL Server inicia cada subproceso, y el sistema operativo distribuye los subprocesos de las instancias de SQL Server entre los procesadores (las CPU) de un equipo en función de la carga. Si se ha habilitado la afinidad de proceso en el nivel de sistema operativo, el sistema operativo asigna cada subproceso a una CPU concreta. Por el contrario, el motor de base de datos de SQL Server asigna los subprocesos de trabajo de SQL Server a los programadores que distribuyen los subprocesos de manera uniforme entre las CPU, en modo de distribución equilibrada.
Para llevar a cabo la multitarea, por ejemplo cuando varias aplicaciones acceden el mismo conjunto de CPU, en ocasiones el sistema operativo mueve los subprocesos de trabajo del entre diferentes CPU. Aunque es eficaz desde el punto de vista del sistema operativo, esta actividad puede reducir el rendimiento de SQL Server en casos de elevadas cargas, ya que cada caché de procesador se vuelve a cargar repetidamente con los datos. La asignación de CPU a subprocesos específicos puede mejorar el rendimiento en estas condiciones al eliminar las operaciones de repetición de carga del procesador y reducir la migración de subprocesos entre CPU (con lo que se reduce el cambio de contexto); dicha asociación entre un subproceso y un procesador se denomina afinidad del procesador. Si se ha habilitado la afinidad, el sistema operativo asigna cada subproceso a una CPU concreta.
La opción de máscara de afinidad se establece mediante ALTER SERVER CONFIGURATION. Cuando no se establece la máscara de afinidad, la instancia de SQL Server asigna los subprocesos de trabajo de forma uniforme entre los programadores que no se han enmascarado.
Precaución
No configure la afinidad de CPU en el sistema operativo y la máscara de afinidad en SQL Server. Esta configuración intenta lograr el mismo resultado y, si las configuraciones no son coherentes, puede obtener resultados impredecibles. Para obtener más información, vea affinity mask (opción de configuración del servidor).
La agrupación de subprocesos permite optimizar el rendimiento cuando un gran número de clientes se conecta al servidor. Normalmente, se crea un subproceso del sistema operativo independiente para cada solicitud de la consulta. Sin embargo, cuando hay cientos de conexiones al servidor, el uso de un subproceso por solicitud de consulta puede consumir grandes cantidades de recursos del sistema. La opción de máximo de subprocesos de trabajo permite que SQL Server cree un grupo de subprocesos de trabajo para atender un gran número de solicitudes de consulta, lo que mejora el rendimiento.
Uso de la opción agrupación ligera
Es posible que la sobrecarga que supone el cambio de contexto de los subprocesos no sea excesiva. La mayoría de las instancias de SQL Server no registran diferencias de rendimiento entre la activación o desactivación de la agrupación ligera en 0 o 1. Las únicas instancias de SQL Server que podrían beneficiarse de la agrupación ligera son las que se ejecutan en un equipo que tiene las características siguientes:
- Un servidor de gran tamaño con varias CPU.
- Todas las CPU se ejecutan casi al máximo de su capacidad.
- Hay un nivel elevado de cambios de contexto.
Estos sistemas pueden notar un pequeño incremento en el rendimiento si el valor de agrupación ligera se establece en 1.
Importante
No use la programación en modo de fibra para un funcionamiento habitual. Esto puede reducir el rendimiento al impedir las ventajas normales del cambio de contexto, y que algunos componentes de SQL Server no funcionen correctamente en el modo de fibra. Para obtener más información, vea lightweight pooling (opción de configuración del servidor).
Ejecución de subprocesos y fibras
Microsoft Windows utiliza un sistema de prioridad numérica con intervalos de 1 a 31 para programar subprocesos para su ejecución. El cero está reservado para el uso del sistema operativo. Cuando varios subprocesos esperan su ejecución, Windows genera el que tiene mayor prioridad.
De manera predeterminada, cada instancia de SQL Server tiene la prioridad 7, que se denomina prioridad normal. Esto proporciona a los subprocesos de SQL Server una prioridad lo suficientemente alta como para obtener los recursos adecuados de la CPU sin afectar negativamente a otras aplicaciones.
Importante
Esta característica se quitará en una versión futura de SQL Server. Evite utilizar esta característica en nuevos trabajos de desarrollo y tenga previsto modificar las aplicaciones que actualmente la utilizan.
La opción de configuración aumento de prioridad se puede utilizar para aumentar la prioridad de los subprocesos de una instancia de SQL Server a 13. Se denomina prioridad alta. Esta configuración da a los subprocesos de SQL Server una prioridad más alta que la del resto de las aplicaciones. De esta forma, se tenderá a generar los subprocesos de SQL Server en cuanto estén listos para ejecutarse y no habrá subprocesos de otras aplicaciones con mayor prioridad. Esto puede mejorar el rendimiento cuando un servidor ejecuta únicamente instancias de SQL Server y ninguna otra aplicación. Sin embargo, si se produce en SQL Server una operación que consume mucha memoria, probablemente las demás aplicaciones no tendrán suficiente prioridad para tener preferencia ante el subproceso de SQL Server.
Si está ejecutando varias instancias de SQL Server en un equipo y activa la opción aumento de prioridad solo para algunas instancias, se puede ver afectado el rendimiento de las instancias que se ejecutan con prioridad normal. También se puede ver afectado el rendimiento de otras aplicaciones y componentes del servidor si se activa aumento de prioridad. Por tanto, debe utilizarse bajo condiciones rigurosamente controladas.
CPU instalada en caliente
Agregar CPU sin interrupción es la capacidad para agregar CPU de forma dinámica a un sistema en funcionamiento. Las CPU se pueden agregar físicamente, mediante la instalación de nuevo hardware; lógicamente, haciendo particiones de hardware en línea, o bien virtualmente a través de un nivel de virtualización. SQL Server admite la adición activa de CPU.
Requisitos para agregar CPU sin interrupción:
- Se requiere hardware compatible con la función de agregar CPU sin interrupción.
- Requiere una versión compatible de Windows Server Datacenter o Enterprise Edition. A partir de Windows Server 2012, se admite la adición activa en la edición Standard.
- Requiere la edición SQL Server Enterprise.
- SQL Server no puede configurarse para el uso de NUMA de software. Para obtener más información sobre NUMA de software, consulte Soft-NUMA (SQL Server).
SQL Server no empieza a utilizar automáticamente las CPU una vez agregadas. Se evita así que SQL Server utilice CPUs que podrían haberse agregado con cualquier otro propósito. Una vez haya finalizado la agregación de CPUs, ejecute la instrucción RECONFIGURE , a fin de que SQL Server reconozca las nuevas CPUs como recursos disponibles.
Nota:
Si la máscara affinity64 estuviera configurada, es preciso modificarla para poder utilizar las nuevas CPUs.
Procedimientos recomendados para ejecutar SQL Server en equipos que tienen más de 64 CPU
Asignación de subprocesos de hardware a CPU
No utilice las opciones de configuración del servidor Máscara de afinidad y Máscara de afinidad de 64 bits para enlazar procesadores a subprocesos específicos. Estas opciones están limitadas a 64 CPU. En su lugar, use la opción SET PROCESS AFFINITY de ALTER SERVER CONFIGURATION.
Administración del tamaño de archivo de registro de transacciones
El crecimiento automático no es un método fidedigno para aumentar el tamaño del archivo de registro de transacciones. El aumento del registro de transacciones debe ser un proceso en serie. La ampliación del registro puede hacer que las operaciones de escritura de transacciones no continúen hasta que finalice esta ampliación. En su lugar, asigne espacio previamente para los archivos de registro estableciendo el tamaño de archivo en un valor lo suficientemente alto para admitir la carga de trabajo habitual del entorno.
Configuración del grado máximo de paralelismo para las operaciones de índice
El rendimiento de las operaciones de índice como crear o volver a generar índices puede mejorarse en los equipos con muchas CPU estableciendo temporalmente el modelo de recuperación de la base de datos en el modelo de recuperación optimizado para cargas masivas de registros o en el modelo de recuperación simple. Estas operaciones de índice pueden generar actividad de registro significativa, y la contención del registro puede afectar a la elección del mejor grado de paralelismo (DOP) realizada por SQL Server.
Además de ajustar la opción de configuración del servidor del grado máximo de paralelismo (MAXDOP), considere ajustar el paralelismo para las operaciones de índice con la opción MAXDOP. Para obtener más información, vea Configurar operaciones de índice en paralelo. Para más información e instrucciones sobre cómo ajustar la opción de configuración del servidor de grado máximo de paralelismo, consulte Establecer la opción de configuración del servidor Grado máximo de paralelismo.
Opción de número máximo de subprocesos de trabajo
SQL Server configura dinámicamente la opción de configuración del servidor Número máximo de subprocesos de trabajo en el inicio. SQL Server usa el número de CPU disponibles y la arquitectura del sistema para determinar esta configuración de servidor durante el inicio, con una fórmula documentada.
Esta opción es avanzada y solo debe cambiarla un administrador de base de datos con experiencia o un profesional certificado de SQL Server. Si sospecha que hay un problema de rendimiento, probablemente no se deba a la disponibilidad de subprocesos de trabajo. La causa más probable es que haya alguna E/S que haga que los subprocesos de trabajo esperen. Lo mejor es buscar la causa principal de un problema de rendimiento antes de cambiar el valor de configuración de máximo de subprocesos de trabajo. Sin embargo, si necesita establecer manualmente el número máximo de subprocesos de trabajo, este valor de configuración siempre se debe establecer en un valor de al menos siete veces el número de CPU presentes en el sistema. Para más información, consulte Configurar la opción de máximo de subprocesos de trabajo.
Evitar el uso de Seguimiento de SQL y SQL Server Profiler
No se recomienda usar Seguimiento de SQL y SQL Profiler en un entorno de producción. La sobrecarga para ejecutar estas herramientas también aumenta según lo hace el número de CPU. Si debe utilizar Seguimiento de SQL en un entorno de producción, reduzca al mínimo los eventos de seguimiento. Genere el perfil y pruebe de forma meticulosa cada evento de seguimiento sujeto a carga, y evite por otra parte utilizar combinaciones de eventos que afecten significativamente al rendimiento.
Importante
Seguimiento de SQL y SQL Server Profiler están en desuso. El espacio de nombres Microsoft.SqlServer.Management.Trace que contiene los objetos Trace y Replay de SQL Server también están en desuso.
Esta característica se quitará en una versión futura de SQL Server. Evite utilizar esta característica en nuevos trabajos de desarrollo y tenga previsto modificar las aplicaciones que actualmente la utilizan.
Use eventos extendidos en su lugar. Para más información sobre los eventos extendidos, vea Inicio rápido: Eventos extendidos en SQL Server y Generador de perfiles XEvent de SSMS.
Nota:
SQL Server Profiler para las cargas de trabajo de Analysis Services NO está en desuso y seguirá siendo compatible.
Establecimiento del número de archivos de datos tempdb
El número de archivos depende del número de procesadores (lógicos) de la máquina. Como regla general, si el número de procesadores lógicos es inferior o igual a ocho, use el mismo número de archivos de datos que procesadores lógicos. Si el número de procesadores lógicos es superior a ocho, use ocho archivos de datos y, después, si se mantiene la contención, aumente el número de archivos de datos en múltiplos de 4 hasta que la contención se reduzca a niveles aceptables, o bien modifique el código o la carga de trabajo. Tenga en cuenta también otras recomendaciones para tempdb, disponibles en Optimización del rendimiento de tempdb en SQL Server.
Sin embargo, si considera minuciosamente las necesidades de simultaneidad de tempdb, podrá simplificar la carga administrativa de la base de datos. Por ejemplo, si un sistema tiene 64 CPU y normalmente solo 32 consultas utilizan tempdb, al aumentar el número de archivos tempdb a 64 no se mejorará rendimiento.
Componentes de SQL Server que pueden utilizar más de 64 CPU
La tabla siguiente contiene una lista de los componentes de SQL Server e indica si pueden utilizar más de 64 CPUs.
| Nombre del proceso | Programa ejecutable | Utilizar más de 64 CPU |
|---|---|---|
| Motor de base de datos de SQL Server | Sqlserver.exe | Sí |
| Reporting Services | Rs.exe | No |
| Analysis Services | As.exe | No |
| Integration Services | Is.exe | No |
| Service Broker | Sb.exe | No |
| Búsqueda de texto completo | Fts.exe | No |
| Agente SQL Server | Sqlagent.exe | No |
| SQL Server Management Studio | Ssms.exe | No |
| programa de instalación de SQL Server | Setup o Setup.exe | No |