Estrategias de recuperación ante desastres para aplicaciones que usan grupos elásticos de Azure SQL Database
Se aplica a:![]() Azure SQL Database
Azure SQL Database
Azure SQL Database proporciona una serie de funciones para garantizar la continuidad empresarial de la aplicación cuando se producen incidentes graves. Los grupos elásticos y las bases de datos únicas admiten el mismo tipo de funcionalidades de recuperación ante desastres (DR). En este artículo se describen varias estrategias de recuperación ante desastres para grupos elásticos que sacan partido a esas características de continuidad empresarial de Azure SQL Database.
En este artículo se usa el modelo de aplicaciones de ISV de SaaS canónico siguiente:
Una aplicación web moderna basada en la nube aprovisiona una instancia base de datos para cada usuario final. El ISV tiene muchos clientes y, por tanto, utiliza muchas bases de datos, conocidas como bases de datos de inquilino. Dado que las bases de datos de inquilino normalmente tienen patrones de actividad impredecibles, el ISV usa un grupo elástico para que el costo de la base de datos sea muy predecible durante prolongados períodos. El grupo elástico también simplifica la administración del rendimiento cuando aumenta la actividad del usuario. Además de las bases de datos de inquilinos, la aplicación también usa varias bases de datos para administrar perfiles de usuario, seguridad, recopilar patrones de uso, etc. La disponibilidad de los inquilinos individuales no afecta a la disponibilidad de la aplicación en su conjunto. Sin embargo, la disponibilidad y el rendimiento de las bases de datos de administración son fundamentales para el funcionamiento de la aplicación y, si las bases de datos de administración están sin conexión, pasará lo mismo con toda la aplicación.
En este artículo se describen las estrategias de recuperación ante desastres que abarcan una variedad de escenarios que va desde las aplicaciones de inicio sensibles al costo a aquellas con requisitos estrictos de disponibilidad.
Nota:
Si usa bases de datos y grupos elásticos de nivel Premium o Crítico para la empresa, puede hacerlos resistentes a las interrupciones regionales mediante su conversión a una configuración de implementación con redundancia de zona. Consulte Bases de datos con redundancia de zona.
Escenario 1. Inicio sensible al costo
Acabo de crear una startup y me preocupan sobremanera los costos. Quiero simplificar la implementación y administración de la aplicación y puedo tener un Acuerdo de Nivel de Servicio limitado para clientes individuales. Sin embargo, quiero garantizar que nunca se quede sin conexión toda la aplicación.
Para satisfacer el requisito de simplicidad, implemente todas las bases de datos de inquilino en un grupo elástico de la región de Azure de su elección e implemente las bases de datos de administración como bases de datos únicas de replicación geográfica. Para la recuperación ante desastres de los inquilinos, use la restauración geográfica, que se incluye sin costo adicional. Para garantizar la disponibilidad de las bases de datos de administración, replícalas geográficamente en otra región con un grupo de conmutación por error (paso 1). El costo en curso de la configuración de recuperación ante desastres en este escenario es igual al costo total de las bases de datos secundarias. En el siguiente diagrama se ilustra esta configuración.
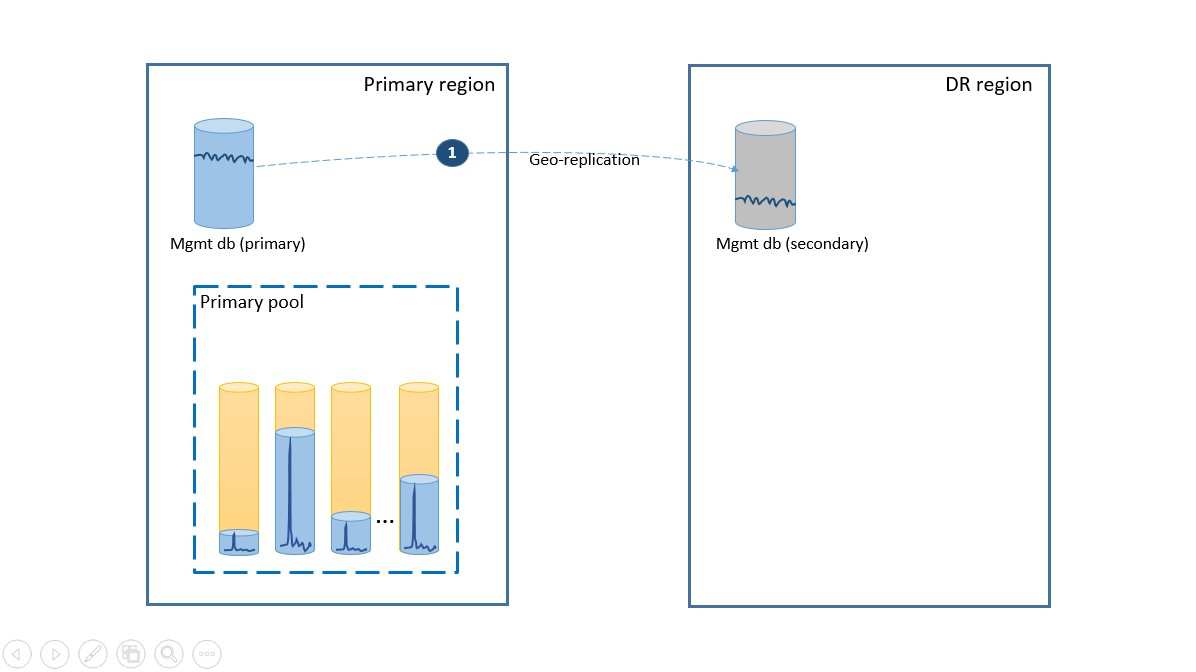
En el caso de una interrupción en la región primaria, en el diagrama siguiente se muestran los pasos de recuperación para volver a conectar la aplicación.
- El grupo de conmutación por error inicia la conmutación por error automática de la base de datos de administración a la región de recuperación ante desastres. La aplicación se volverá a conectar automáticamente a la nueva base de datos principal y todas las nuevas cuentas y bases de datos de inquilino se crearán en la región de recuperación ante desastres. Los clientes existentes verán que sus datos no están disponibles temporalmente.
- Cree el grupo elástico con la misma configuración que el grupo original (2).
- Use la restauración geográfica para crear copias de las bases de datos de inquilino (3). Considere desencadenar las restauraciones individuales por las conexiones de los usuarios finales o utilizar algún otro esquema de prioridad específica de la aplicación.
En este momento, la aplicación vuelve a estar conectada en la región de recuperación ante desastres, pero algunos clientes experimentarán una demora al tener acceso a sus datos.
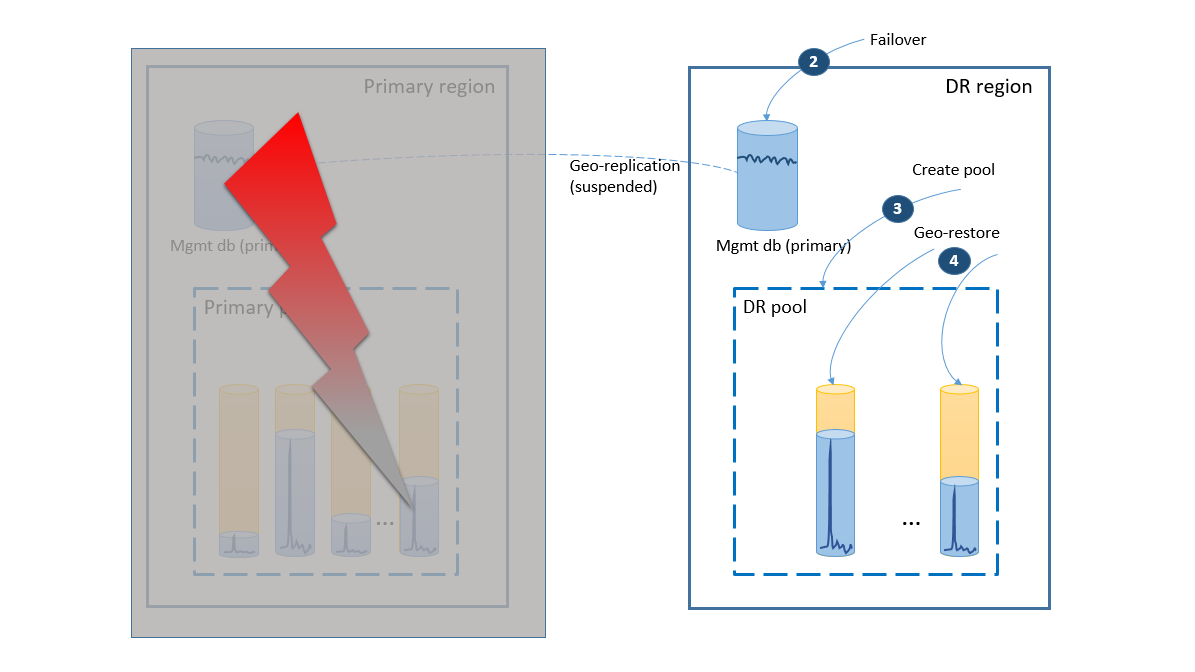
Si la interrupción fue temporal, es posible que Azure recupere la región primaria antes de que todas las restauraciones de bases de datos se completen en la región de recuperación ante desastres. En este caso, organice el regreso de la aplicación a la región primaria. El proceso realizará los pasos que se muestran en el diagrama siguiente.
- Cancele todas las solicitudes de restauración geográfica pendientes.
- Realice la conmutación por error de las bases de datos de administración a la región primaria (5). Nota: Después de la recuperación de la región, las primarias anteriores se convierten automáticamente en secundarias. Ahora vuelven a cambiar los roles.
- Cambie la cadena de conexión de la aplicación para que vuelva a apuntar a la región primaria. Ahora todas las cuentas nuevas y las bases de datos de inquilino se crean en la región primaria. Algunos clientes existentes verán que sus datos no están disponibles temporalmente.
- Establezca todas las bases de datos en el grupo de recuperación ante desastres de solo lectura para asegurarse de que no se puede modificar en la región de recuperación ante desastres (6).
- Para las bases de datos del grupo de recuperación ante desastres que hayan cambiado desde la recuperación, cambie el nombre o elimine las bases de datos correspondientes en el grupo principal (7).
- Copie las bases de datos actualizadas desde el grupo de recuperación ante desastres al grupo principal (8).
- Elimine el grupo de recuperación ante desastres (9).
En este momento la aplicación estará en línea en la región primaria con todas las bases de datos de inquilino disponibles en el grupo principal.

Ventaja
La principal ventaja de esta estrategia es el bajo costo continuo de la redundancia de nivel de datos. Azure SQL Database realiza automáticamente una copia de seguridad de las bases de datos sin necesidad de reescribir ninguna aplicación y sin costo adicional. El costo se contrae solo cuando se restauran las bases de datos elásticas.
Inconveniente
El inconveniente es que la recuperación completa de todas las bases de datos de inquilino tarda mucho tiempo. El tiempo dependerá del número total de restauraciones que se inicien en la región de recuperación ante desastres y del tamaño general de las bases de datos de inquilino. Aunque si se priorizan algunas restauraciones de inquilinos sobre otras, estará compitiendo con todas las demás restauraciones que se inicien en la misma región, ya que el servicio arbitrará y se limitará para minimizar la repercusión global en las bases de datos de los clientes existentes. Además, la recuperación de las bases de datos de inquilino no podrá iniciarse hasta que se cree el nuevo grupo elástico en la región de recuperación ante desastres.
Escenario 2. Aplicación madura con servicio en capas
Tengo una aplicación de SaaS desarrollada con ofertas de servicio en capas y distintos Acuerdos de Nivel de Servicio para clientes de versiones de prueba y de pago. Para los clientes de versiones de prueba, tengo que reducir el costo tanto como sea posible. Los clientes de versiones de prueba pueden asumir el tiempo de inactividad, pero quiero reducir su probabilidad. Para los clientes de versiones de pago, los tiempos de inactividad es un riesgo de vuelo. Por lo tanto, quiero asegurarme de que los clientes con versiones de pago siempre tengan acceso a sus datos.
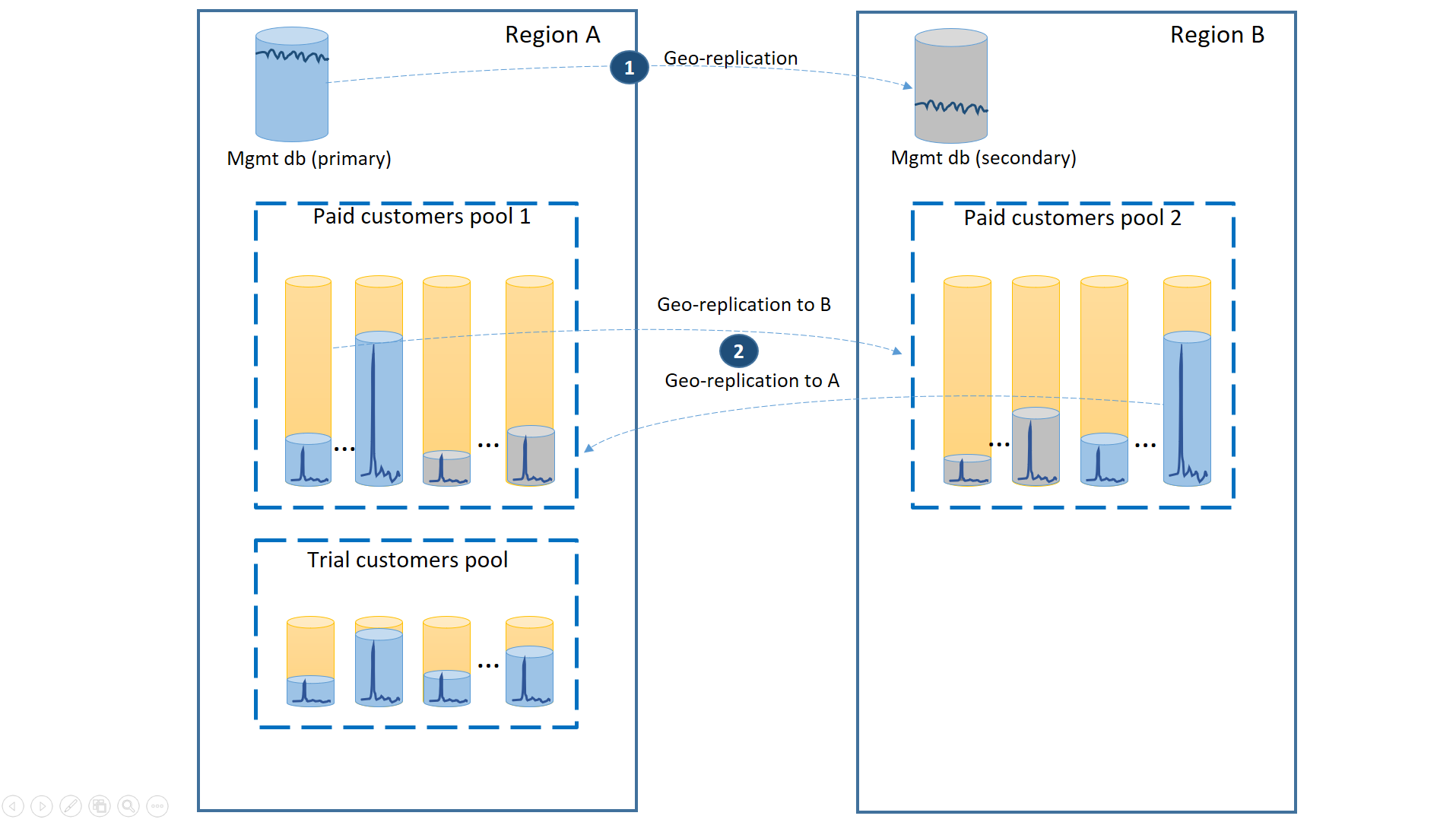
Para admitir este escenario, separe los inquilinos de versiones de prueba de los inquilinos de versiones de pago, colocándolos en grupos elásticos independientes. Los clientes de versiones de prueba tienen menos eDTU o núcleos virtuales por inquilino y un Acuerdo de Nivel de Servicio menor con un tiempo de recuperación mayor. Los clientes de versiones de pago se encuentran en un grupo con más eDTU o núcleos virtuales por inquilino y un Acuerdo de Nivel de Servicio superior. Para garantizar el menor tiempo de recuperación, las bases de datos de inquilino de los clientes de versiones de pago deben replicarse geográficamente. En el siguiente diagrama se ilustra esta configuración.
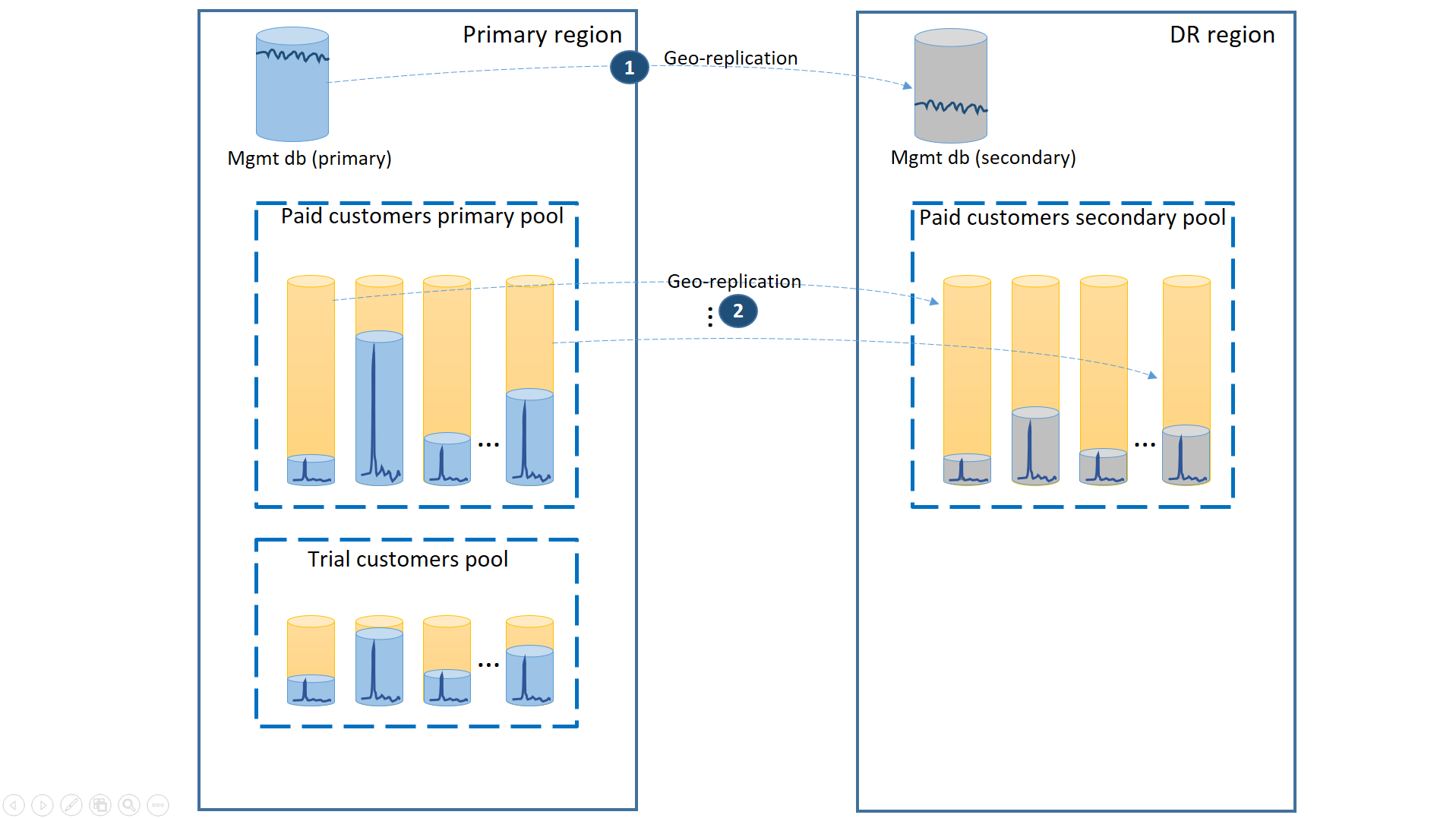
Al igual que en el primer escenario, las bases de datos de administración estarán bastante activas, por tanto puede utilizar una base de datos única de replicación geográfica para ello (1). Esto garantiza un rendimiento predecible para las nuevas suscripciones de cliente, actualizaciones del perfil y otras operaciones de administración. La región en la que residen los principales de las bases de datos de administración será la región primaria y la región en la que residen los secundarios de las bases de datos de administración será la región de recuperación ante desastres.
Las bases de datos de inquilino de los clientes con versiones de pago tienen bases de datos activas en el grupo aprovisionado de pago de la región primaria. Aprovisione un grupo secundario con el mismo nombre en la región de recuperación ante desastres. Cada inquilino está replicado geográficamente en el grupo secundario (2). Esto permite una recuperación rápida de todas las bases de datos de inquilino mediante la conmutación por error.
En el caso de una interrupción en la región principal, en el diagrama siguiente se muestran los pasos de recuperación para volver a conectar la aplicación.
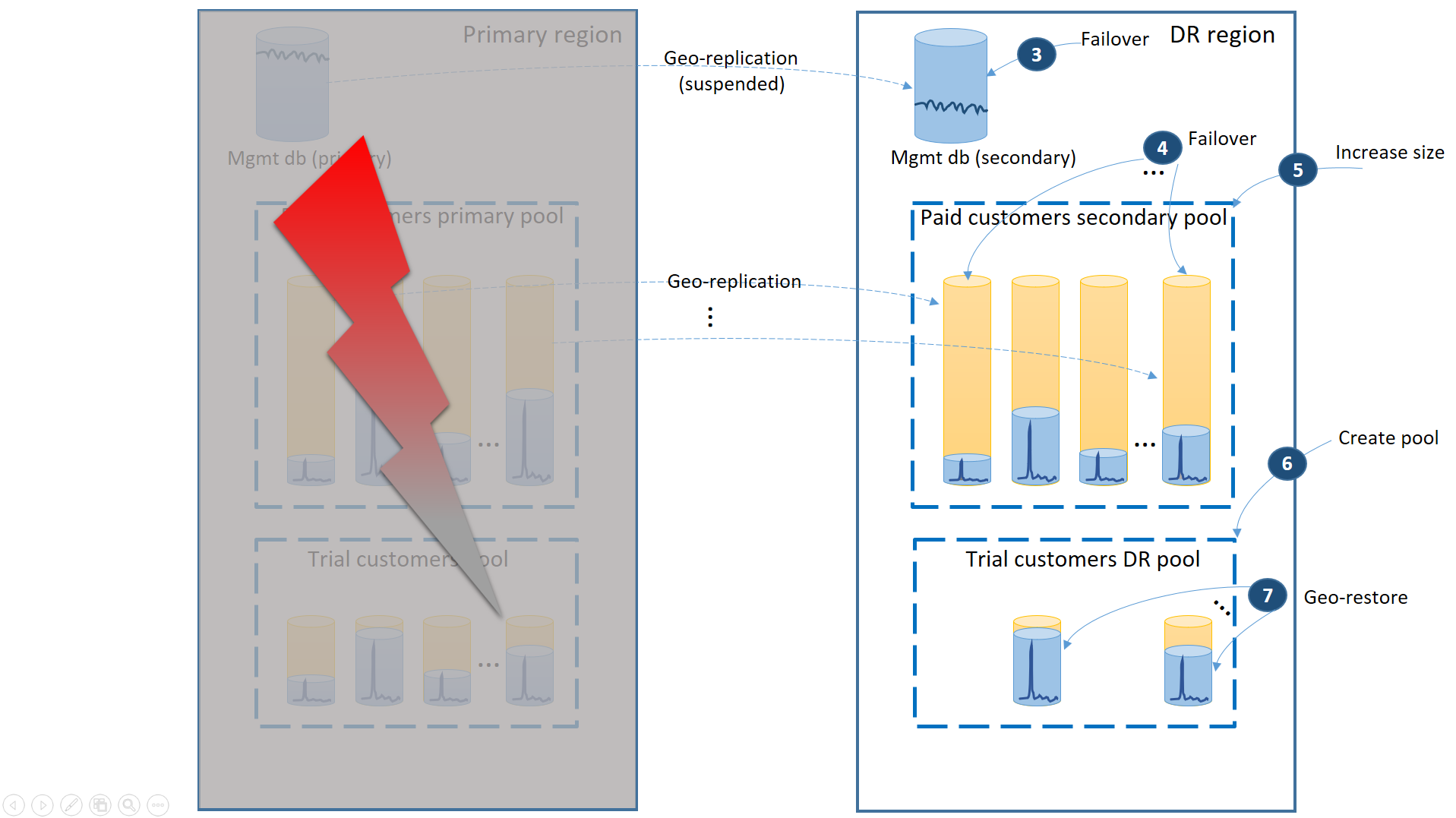
- Realice inmediatamente una conmutación por error en las bases de datos de administración en la región de recuperación ante desastres (3).
- Cambie la cadena de conexión de la aplicación para que apunte a la región de recuperación ante desastres. Ahora todas las cuentas nuevas y las bases de datos de inquilino se crean en la región de recuperación ante desastres. Los clientes de versiones de prueba existentes verán que sus datos no están disponibles temporalmente.
- Realice una conmutación por error en las bases de datos de inquilino de versiones de pago, en el grupo de la región de recuperación ante desastres, para restaurar inmediatamente su disponibilidad (4). Dado que la conmutación por error es un rápido cambio de nivel de metadatos, se puede considerar una optimización cuando se desencadenan las conmutaciones por error individuales a petición de las conexiones del usuario final.
- Si el tamaño de eDTU o el valor de núcleo virtual del grupo secundario eran menores que en el principal porque las bases de datos secundarias solo requerían la capacidad para procesar los registros de cambio mientras eran secundarias, aumente inmediatamente la capacidad del grupo para acomodar la carga de trabajo completa de todos los inquilinos (5).
- Cree el nuevo grupo elástico con el mismo nombre y la misma configuración en la región de recuperación ante desastres para bases de datos de los clientes de versiones de prueba (6).
- Una vez creado el grupo de clientes de versiones de prueba, puede usar la restauración geográfica para restaurar las bases de datos de inquilino de versiones de prueba individuales en el nuevo grupo (7). Considere desencadenar las restauraciones individuales por las conexiones de los usuarios finales o utilizar algún otro esquema de prioridad específica de la aplicación.
En este momento la aplicación vuelve a estar en línea en la región de recuperación ante desastres. Todos los clientes de versiones de pago tienen acceso a los datos, mientras que los clientes de versiones de prueba experimentan una demora al acceder a los suyos.
Cuando Azure recupera la región primaria después de haber restaurado la aplicación en la región de recuperación ante desastres, puede continuar ejecutando la aplicación en dicha región, o bien decidir realizar una conmutación por recuperación en la región principal. Si se recupera la región primaria antes de que se complete el proceso de conmutación por error, debe plantearse utilizar la conmutación por recuperación inmediatamente. La conmutación por recuperación realiza los pasos que se muestran en el diagrama siguiente:
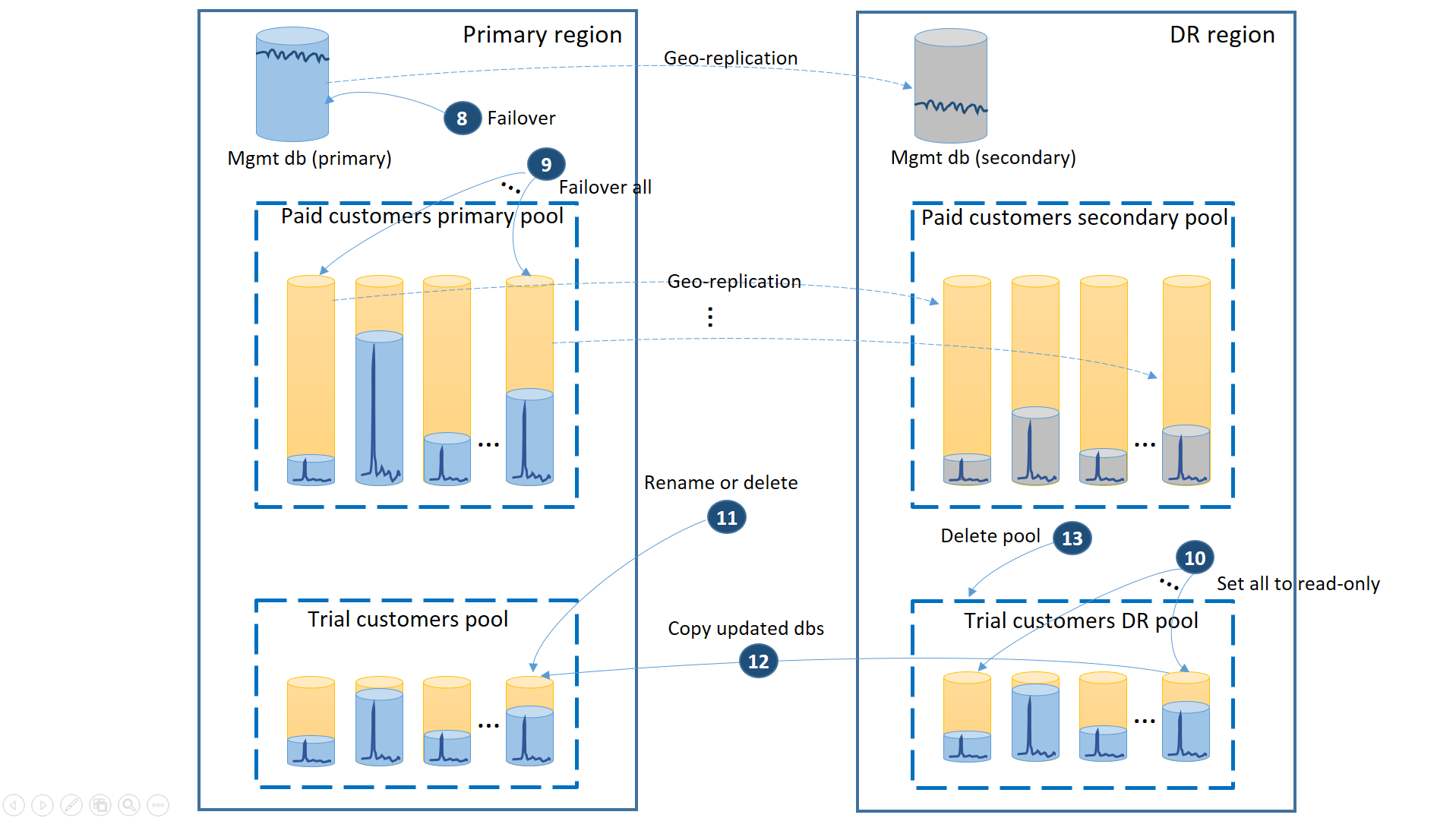
- Cancele todas las solicitudes de restauración geográfica pendientes.
- Realice una conmutación por error en las bases de datos de administración (8). Después de la recuperación de la región, la primaria anterior se convierte automáticamente en secundaria. Ahora vuelve a convertir en principal.
- Realice una conmutación por error en las bases de datos de inquilino de versiones de pago (9). De igual forma, después de la recuperación de la región, las principales anteriores se convierten automáticamente en secundarias. Ahora volverán a ser primarias.
- Establezca las bases de datos de versiones de prueba restauradas que han cambiado en la región de recuperación ante desastres en solo lectura (10).
- Para las bases de datos del grupo de recuperación ante desastres de los clientes de versiones de prueba que hayan cambiado desde la recuperación, cambie el nombre o elimine la base de datos correspondiente en el grupo principal (11).
- Copie las bases de datos actualizadas desde el grupo de recuperación ante desastres al grupo principal (12).
- Elimine el grupo de recuperación ante desastres (13).
Nota
La operación de conmutación por error es asincrónica. Para minimizar el tiempo de recuperación, es importante ejecutar comando de conmutación por error de las bases de datos de inquilino en lotes de al menos 20 bases de datos.
Ventaja
La principal ventaja de esta estrategia es que proporciona el Acuerdo de Nivel de Servicio superior para los clientes de versiones de pago. También garantiza que las nuevas versiones de prueba se desbloquean en cuanto se crea el grupo de recuperación ante desastres de versiones de prueba.
Inconveniente
El inconveniente es que esta configuración aumenta el costo total de las bases de datos de inquilino debido al costo del grupo de recuperación ante desastres secundario para los clientes de versiones de pago. Además, si el grupo secundario tiene un tamaño diferente, los clientes de versiones de pago experimentarán un rendimiento menor después de la conmutación por error hasta que se complete la actualización del grupo en la región de recuperación ante desastres.
Escenario 3. Aplicación distribuida geográficamente con servicio en capas
Tengo una aplicación de SaaS desarrollada con ofertas de servicio en capas. Deseo ofrecer un contrato de nivel de servicio muy agresivo a mis clientes de versiones de pago y minimizar el riesgo de impacto cuando se produzcan interrupciones, porque incluso una breve interrupción puede causar la insatisfacción del cliente. Es fundamental que los clientes de versiones de pago siempre puedan acceder a sus datos. Las versiones de prueba son gratuitas y no se ofrece ningún Acuerdo de Nivel de Servicio durante el periodo de prueba.
Para este escenario, use tres grupos elásticos independientes. Aprovisione dos grupos de igual tamaño con un número mayor de eDTU o núcleos virtuales por base de datos en dos regiones diferentes para que contengan las bases de datos de inquilino de los clientes de versiones de pago. El tercer grupo que contiene los inquilinos de versiones de evaluación puede tener menos eDTU o núcleos virtuales por base de datos y se aprovisionará en una de las dos regiones.
Para garantizar el menor tiempo de recuperación durante las interrupciones en las bases de datos de inquilino de los clientes de versiones de pago, deben replicarse geográficamente con el 50 % de las bases de datos principales en cada una de las dos regiones. De forma similar, cada región tiene el 50 % de las bases de datos secundarias. De este modo si una región está sin conexión, solo el 50 % de las bases de datos de los clientes de versiones de pago se ven afectados y tienen que realizar la conmutación por error. Las otras bases de datos permanecen intactas. Esta configuración se ilustra en el diagrama siguiente:
Al igual que en los escenarios anteriores, las bases de datos de administración están bastante activas, por tanto debe configurarlas como bases de datos únicas de replicación geográfica (1). Esto garantiza un rendimiento predecible para las nuevas suscripciones de cliente, actualizaciones del perfil y otras operaciones de administración. La región A es la región primaria de las bases de datos de administración y la región B se usa para la recuperación de las bases de datos de administración.
Las bases de datos de inquilino de los clientes de versiones de pago también se replicarán geográficamente, pero las principales y secundarias se dividen entre la región A y la región B (2). De este modo, las bases de datos principales de inquilino afectadas por la interrupción pueden conmutar por error a otra región y estar disponibles. La otra mitad de las bases de datos de inquilino no se ve afectada.
El siguiente diagrama ilustra los pasos de recuperación que hay que llevar a cabo si se produce una interrupción en la región A.
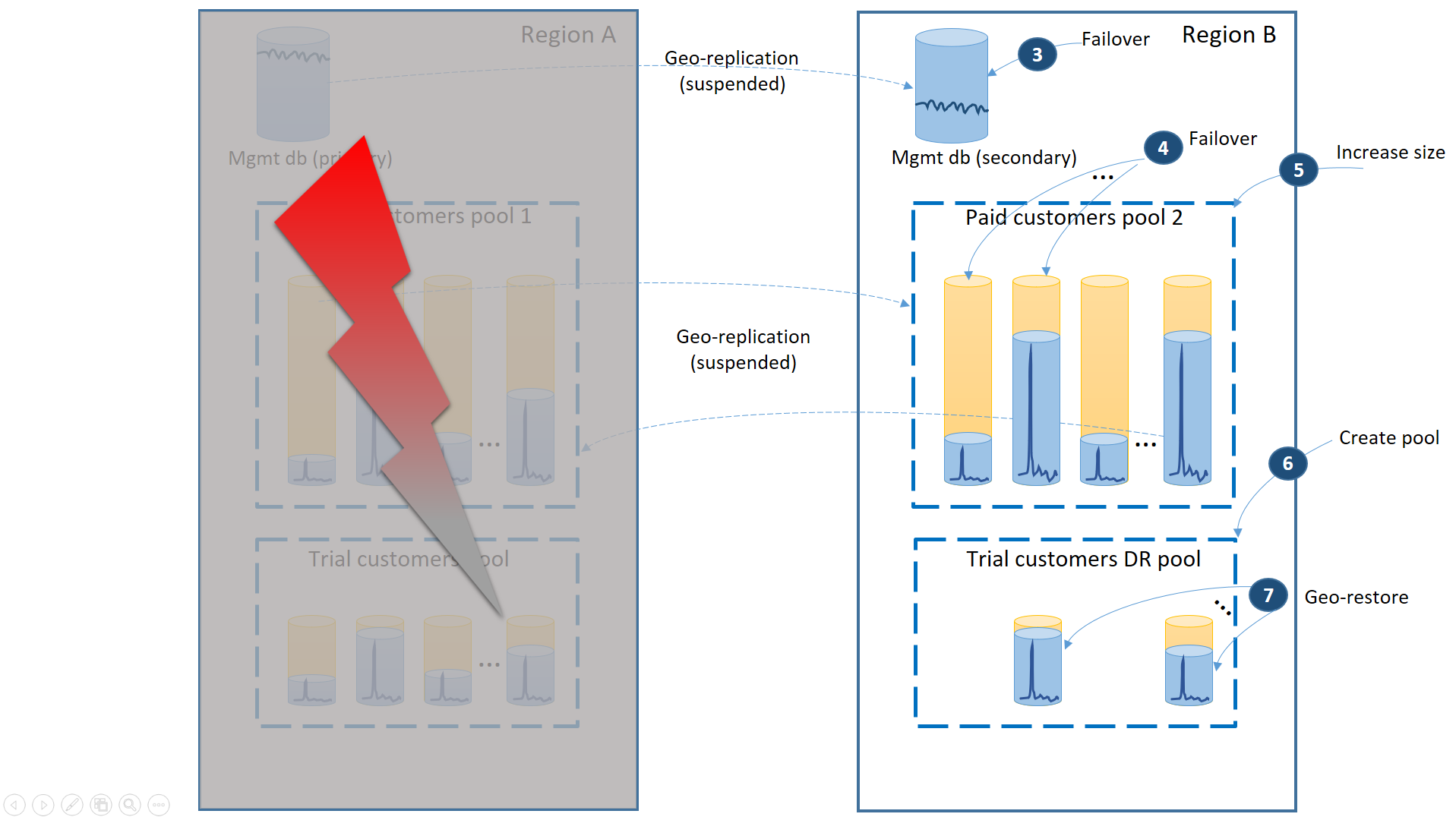
- Realice inmediatamente una conmutación por error en las bases de datos de administración en la región B (3).
- Cambie la cadena de conexión de la aplicación para que señale a las bases de datos de administración de la región B. Modifique las bases de datos de administración para asegurarse de que las nuevas cuentas y bases de datos de inquilino se crearán en la región B y que las bases de datos de inquilino existentes se encontrarán allí también. Los clientes de versiones de prueba existentes verán que sus datos no están disponibles temporalmente.
- Realice una conmutación por error en las bases de datos de inquilino de versiones de pago en el grupo 2 de la región B, para restaurar inmediatamente su disponibilidad (4). Dado que la conmutación por error es un rápido cambio de nivel de metadatos, se puede considerar una optimización cuando se desencadenan las conmutaciones por error individuales a petición de las conexiones del usuario final.
- Como ahora el grupo 2 contiene solo bases de datos principales, aumenta la carga de trabajo total del grupo, por lo que puede aumentar de inmediato su tamaño de eDTU (5) o número de núcleos virtuales.
- Cree el nuevo grupo elástico con el mismo nombre y la misma configuración en la región B para bases de datos de los clientes de versiones de prueba (6).
- Una vez creado el grupo, puede usar la restauración geográfica para restaurar las bases de datos de inquilino de versiones de prueba individuales en el grupo (7). Considere desencadenar las restauraciones individuales por las conexiones de los usuarios finales o utilizar algún otro esquema de prioridad específica de la aplicación.
Nota
La operación de conmutación por error es asincrónica. Para minimizar el tiempo de recuperación, es importante ejecutar el comando de conmutación por error de las bases de datos de inquilino en lotes de al menos 20 bases de datos.
En este punto, la aplicación vuelve a estar en línea en la región B. Todos los clientes de versiones de pago tienen acceso a sus datos, mientras que los clientes de versiones de prueba experimentan una demora al acceder a los suyos.
Cuando se recupera la región A, debe decidir si quiere usar la región B para clientes de versiones prueba o realizar una conmutación por recuperación mediante el grupo de clientes de versiones de prueba en la región A. Un criterio podría ser el porcentaje de bases de datos de inquilino de versiones de prueba modificadas desde la recuperación. Con independencia de esta decisión, debe volver a equilibrar los inquilinos de versiones de pago entre los dos grupos. En el siguiente diagrama se muestra el proceso de la conmutación por recuperación de las bases de datos de inquilino de versiones de prueba en la región A.
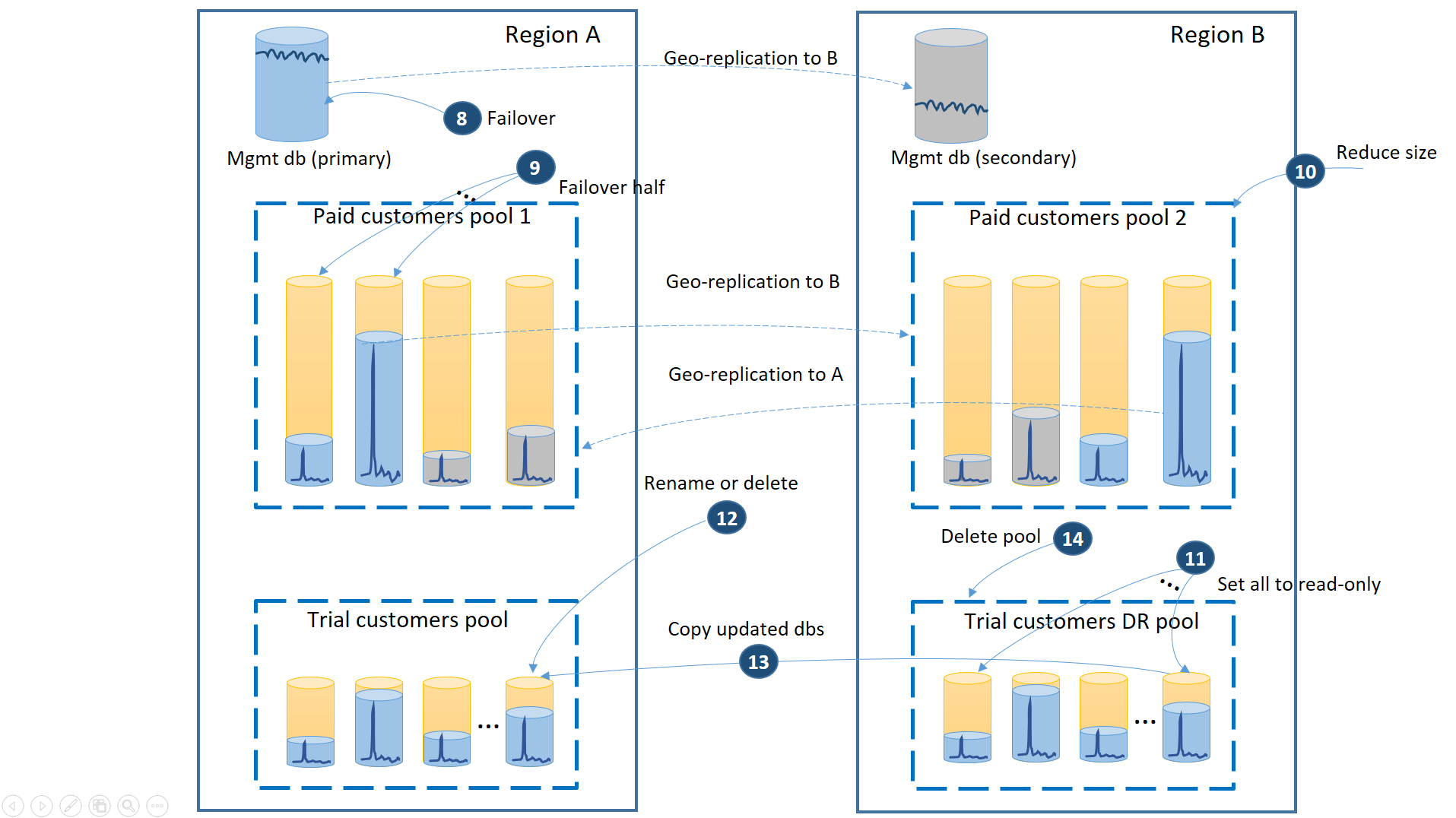
- Cancele todas las solicitudes de restauración geográfica pendientes en el grupo de recuperación ante desastres de versiones de prueba.
- Realice una conmutación por error en la base de datos de administración (8). Después de la recuperación de la región, la región primaria anterior se convierte automáticamente en secundaria. Ahora vuelve a convertir en principal.
- Seleccione qué bases de datos de inquilino de versiones de pago producen una conmutación por recuperación en el grupo 1 e inicie la conmutación por error en sus secundarias (9). Después de la recuperación de la región, todas las bases de datos del grupo 1 se convertirán automáticamente en secundarias. Ahora el 50 % volverán a ser principales.
- Reduzca el tamaño del grupo 2 a la cantidad original de eDTU (10) o núcleos virtuales.
- Establezca todas las bases de datos de versiones de prueba restauradas de la región B en solo lectura (11).
- Para las bases de datos del grupo de recuperación ante desastres de versiones de prueba que hayan cambiado desde la recuperación, cambie el nombre o elimine las bases de datos correspondientes del grupo principal (12).
- Copie las bases de datos actualizadas desde el grupo de recuperación ante desastres al grupo principal (13).
- Elimine el grupo de recuperación ante desastres (14).
Ventaja
Las principales ventajas de esta estrategia son las siguientes:
- Admite el contrato de nivel de servicio más agresivo para los clientes de versiones de pago porque garantiza que una interrupción no puede afectar a más del 50 % de las bases de datos de inquilino.
- También garantiza que las nuevas versiones de prueba se desbloquean tan pronto se cree el grupo de recuperación ante desastres de versiones de prueba durante la recuperación.
- Permite un uso más eficaz de la capacidad del grupo, ya que se garantiza que el 50 % de las bases de datos secundarias de los grupos 1 y 2 sean menos activas que las bases de datos principales.
Ventajas y desventajas
Las principales desventajas son las siguientes:
- Las operaciones de CRUD en las bases de datos de administración tienen una latencia menor para los usuarios finales conectados a la región A que para los usuarios finales conectados a la región B, ya que se ejecutan en la principal de las bases de datos de administración.
- Requiere un diseño más complejo de la base de datos de administración. Por ejemplo, cada registro de inquilinos tiene una etiqueta de ubicación que debe cambiarse durante la conmutación por error y la conmutación por recuperación.
- Los clientes de versiones de pago pueden experimentar un rendimiento inferior al normal hasta que se complete la actualización de los grupos en la región B.
Resumen
Este artículo se centra en las estrategias de recuperación ante desastres para el nivel de base de datos utilizado por una aplicación multiinquilino ISV de SaaS. La estrategia que seleccione debe basarse en las necesidades de la aplicación, como el modelo de negocio, el contrato de nivel de servicio que desea ofrecer a sus clientes, la restricción del presupuesto, entre otras. Cada estrategia descrita describe las ventajas y los inconvenientes para que pueda tomar una decisión informada. Además, la aplicación específica probablemente incluya otros componentes de Azure. Debe revisar las instrucciones de continuidad de negocio de los mismos y coordinar la recuperación de la capa de base de datos con ellos. Para más información sobre la administración de la recuperación de aplicaciones de base de datos en Azure, consulte Diseño de soluciones en la nube para la recuperación ante desastres.
Pasos siguientes
- Para saber en qué consisten las copias de seguridad automatizadas de Azure SQL Database, vea Copias de seguridad automatizadas de Azure SQL Database.
- Para obtener una descripción general y los escenarios de la continuidad empresarial, consulte Información general sobre la continuidad empresarial.
- Si quiere saber cómo utilizar las copias de seguridad automatizadas para procesos de recuperación, consulte Recover an Azure SQL database using automated database backups(Recuperación de una base de datos SQL de Azure mediante copias de seguridad de base de datos automatizadas).
- Para conocer las opciones de recuperación más rápidas, consulta Replicación geográfica activa y grupos de conmutación por error.
- Si quiere aprender a utilizar las copias de seguridad automatizadas para procesos de archivado, consulte el procedimiento para copiar una base de datos.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de