Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
SE APLICA A: ![]() NoSQL
NoSQL
Importante
Las sugerencias de rendimiento de este artículo son solo para la versión 4 del SDK de Java de Azure Cosmos DB. Consulte las notas de la versión del SDK de Java v4 de Azure Cosmos DB, el repositorio de Maven y la guía de solución de problemas del SDK de Java v4 de Azure Cosmos DB para más información. Si actualmente usa una versión anterior a la v4, consulte la guía Migración al SDK de Java de Azure Cosmos DB v4 para obtener ayuda con la actualización a la versión 4.
Azure Cosmos DB es una base de datos distribuida rápida y flexible que se escala sin problemas con una latencia y un rendimiento garantizados. No es necesario realizar cambios de arquitectura importantes ni escribir el código complejo para escalar la base de datos con Azure Cosmos DB. Escalar y reducir verticalmente es tan sencillo como realizar una única llamada API o una llamada al método SDK. Sin embargo, como el acceso a Azure Cosmos DB se realiza mediante llamadas de red, puede realizar optimizaciones en el lado cliente para conseguir un rendimiento máximo al usar la versión 4 del SDK de Java de Azure Cosmos DB.
Por lo tanto, si se pregunta "¿Cómo puedo mejorar el rendimiento de mi base de datos?", considere las siguientes opciones:
Redes
Colocación de los clientes en la misma región de Azure para aumentar el rendimiento
Cuando sea posible, coloque las aplicaciones que llaman a Azure Cosmos DB en la misma región que la base de datos de Azure Cosmos DB. Para obtener una comparación aproximada, las llamadas a Azure Cosmos DB en la misma región se realizan en menos de 1 o 2 ms, pero la latencia entre las costas este y oeste de Estados Unidos es >50 ms. Esta latencia podría variar de una solicitud a otra, según la ruta tomada por la solicitud cuando pasa del cliente al límite del centro de datos de Azure. Para conseguir la menor latencia posible, asegúrese de que la aplicación que llama se encuentra en la misma región de Azure que el punto de conexión de Azure Cosmos DB aprovisionado. Para obtener una lista de regiones disponibles, consulte Regiones de Azure.
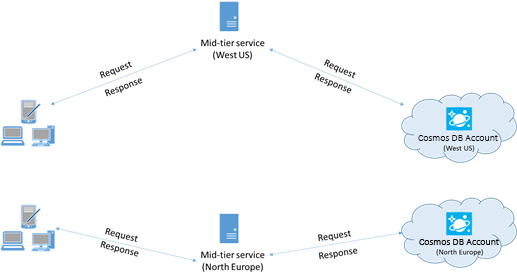
Una aplicación que interactúa con una cuenta de Azure Cosmos DB de varias regiones debe configurar ubicaciones preferidas para asegurarse de que las solicitudes vayan a una región colocalizada.
Habilite las redes aceleradas para reducir la latencia y la inestabilidad de la CPU
Se recomienda seguir las instrucciones para habilitar Redes Aceleradas en su máquina virtual Windows (seleccione para obtener instrucciones) o Linux (seleccione para obtener instrucciones) de Azure, con el fin de maximizar el rendimiento (reducir la latencia y la fluctuación de la CPU).
Sin las redes aceleradas, la E/S que pasa entre su máquina virtual de Azure y otros recursos de Azure puede enrutarse a través de un host y un conmutador virtual situado entre la máquina virtual y su tarjeta de red. Si el host y el conmutador virtual están alineados en la ruta de datos no solo se aumenta la latencia y la vibración en el canal de comunicación, sino que también se roban ciclos de la CPU de la máquina virtual. Con las redes aceleradas, la máquina virtual interactúa directamente con la NIC sin intermediarios. Todos los detalles de la directiva de red se controlan en el hardware de la NIC, pasando el host y el conmutador virtual. Por lo general, al habilitar las redes aceleradas puede esperar una menor latencia y un mayor rendimiento, así como una latencia más uniforme y una disminución del uso de la CPU.
Limitaciones: las redes aceleradas deben ser compatibles con el sistema operativo de la máquina virtual y solo se pueden habilitar cuando la máquina virtual se ha detenido y se ha desasignado. No se puede implementar la máquina virtual con Azure Resource Manager. App Service no tiene habilitada la red acelerada.
Para más información, consulte las instrucciones de Windows y Linux.
Alta disponibilidad
Para obtener instrucciones generales sobre cómo configurar la alta disponibilidad en Azure Cosmos DB, consulte Alta disponibilidad en Azure Cosmos DB.
Además de una buena configuración básica en la plataforma de base de datos, hay técnicas específicas que se pueden implementar en el propio SDK de Java, lo que puede ayudar en escenarios de interrupción. Dos estrategias importantes son la estrategia de disponibilidad basada en umbrales y el disyuntor de nivel de partición.
Estas técnicas proporcionan mecanismos avanzados para abordar desafíos específicos de latencia y disponibilidad, pasando por encima y más allá de las funcionalidades de reintento entre las regiones integradas en el SDK de forma predeterminada. Mediante la administración proactiva de posibles problemas en los niveles de solicitud y partición, estas estrategias pueden mejorar significativamente la resistencia y el rendimiento de la aplicación, especialmente en condiciones de carga alta o degradadas.
Estrategia de disponibilidad basada en umbrales
La estrategia de disponibilidad basada en umbrales puede mejorar la latencia final y la disponibilidad enviando solicitudes de lectura paralelas a regiones secundarias (como se define en preferredRegions) y aceptando la respuesta más rápida. Este enfoque puede reducir drásticamente el impacto de interrupciones regionales o condiciones de alta latencia en el rendimiento de la aplicación. Además, la administración proactiva de conexiones se puede emplear para mejorar aún más el rendimiento al calentar las conexiones y las memorias caché en la región de lectura actual y en las regiones remotas preferidas.
Configuración de ejemplo:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("East US", "East US 2", "West US"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Funcionamiento:
Solicitud inicial: en el momento T1, se realiza una solicitud de lectura en la región primaria (por ejemplo, Este de EE. UU.). El SDK espera una respuesta de hasta 500 milisegundos (el valor
threshold).Segunda solicitud: si no hay respuesta de la región primaria en 500 milisegundos, se envía una solicitud paralela a la siguiente región preferida (por ejemplo, Este de EE. UU. 2).
Tercera solicitud: Si ni la región principal ni la secundaria responden en un plazo de 600 milisegundos (500 ms + 100 ms, el valor), el
thresholdStepSDK envía otra solicitud paralela a la tercera región preferida (por ejemplo, Oeste de EE. UU.).La respuesta más rápida gana: sea cual sea la región que responda primero, esa respuesta se acepta y se omiten las demás solicitudes paralelas.
La administración proactiva de conexiones ayuda a calentar las conexiones y las memorias caché de los contenedores en las regiones preferidas, lo que reduce la latencia de arranque en frío para escenarios de conmutación por error o escrituras en configuraciones de varias regiones.
Esta estrategia puede mejorar significativamente la latencia en escenarios en los que una región determinada es lenta o está temporalmente no disponible, pero puede suponer un mayor costo en términos de unidades de solicitud cuando se requieren solicitudes paralelas entre regiones.
Nota:
Si la primera región preferida devuelve un código de estado de error no transitorio (por ejemplo, documento no encontrado, error de autorización, conflicto, etc.), la propia operación producirá un error rápido, ya que la estrategia de disponibilidad no tendría ninguna ventaja en este escenario.
Disyuntor de nivel de partición
El disyuntor de nivel de partición mejora la latencia de cola y la disponibilidad de escritura mediante el seguimiento y el cortocircuito de las solicitudes a particiones físicas incorrectas. Esto mejora el rendimiento evitando particiones problemáticas conocidas y redirigiendo solicitudes a regiones en mejor estado.
Configuración de ejemplo:
Para habilitar el disyuntor de nivel de partición:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Para establecer la frecuencia del proceso en segundo plano con el fin de comprobar las regiones no disponibles:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Para establecer la duración durante la que una partición puede permanecer no disponible:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Funcionamiento:
Errores de seguimiento: El SDK realiza un seguimiento de los errores de terminal (por ejemplo, 503s, 500s, tiempos de espera) para particiones individuales en regiones específicas.
Marcar como no disponible: Si una partición de una región supera un umbral configurado de errores, se marca como "No disponible". Las solicitudes posteriores a esta partición se cortocircuitan y se redirigen a otras regiones más saludables.
Recuperación automatizada: un subproceso en segundo plano comprueba periódicamente las particiones no disponibles. Después de una duración determinada, estas particiones se marcan provisionalmente como "HealthyTentative" y están sujetas a solicitudes de prueba para validar la recuperación.
Promoción o degradación del estado: en función del éxito o error de estas solicitudes de prueba, el estado de la partición se promueve a "Correcto" o se degrada una vez más a "No disponible".
Este mecanismo ayuda a supervisar continuamente el estado de las particiones y garantiza que las solicitudes se atienden con una latencia mínima y una disponibilidad máxima, sin verse obstaculizadas por las particiones problemáticas.
Nota:
El disyuntor solo se aplica a las cuentas de escritura de varias regiones, como cuando una partición está marcada como Unavailable, las lecturas y las escrituras se mueven a la siguiente región preferida. Esto es para evitar que las lecturas y escrituras de diferentes regiones se sirvan desde la misma instancia de cliente, ya que sería un antipatrón.
Importante
Debe usar la versión 4.63.0 del SDK de Java o una versión superior para activar el disyuntor de nivel de partición.
Comparación de optimizaciones de disponibilidad
Estrategia de disponibilidad basada en umbrales:
- Ventaja: reduce la latencia de cola mediante el envío de solicitudes de lectura paralelas a regiones secundarias y mejora la disponibilidad al reemplazar las solicitudes que dan lugar a tiempos de espera de red.
- Ventajas: incurre en costos adicionales de RU (unidades de solicitud) en comparación con el disyuntor, debido a otras solicitudes paralelas entre regiones (aunque solo durante períodos en los que se infringen los umbrales).
- Caso de uso: óptimo para cargas de trabajo con mucha lectura en las que la reducción de la latencia es crítica y un costo adicional (tanto en términos de carga de RU como de presión de CPU del cliente) es aceptable. Las operaciones de escritura también pueden beneficiarse si se opta por una directiva de reintento de escritura no idempotente y la cuenta tiene escrituras en varias regiones.
Disyuntor de nivel de partición:
- Ventaja: mejora la disponibilidad y la latencia evitando particiones incorrectas, lo que garantiza que las solicitudes se enrutan a regiones en mejor estado.
- Ventajas: no genera más costes de RU, pero puede provocar una pérdida inicial de disponibilidad para las solicitudes que den lugar a tiempos de espera de red.
- Caso de uso: ideal para cargas de trabajo de escritura intensivas o mixtas en las que un rendimiento coherente es esencial, especialmente cuando se trabaja con particiones que pueden volverse intermitentemente incorrectas.
Ambas estrategias se pueden usar conjuntamente para mejorar la disponibilidad de lectura y escritura y reducir la latencia del final. El disyuntor a nivel de partición puede gestionar varios escenarios de fallos transitorios, incluyendo aquellos que podrían dar lugar a réplicas con rendimiento lento, sin tener que ejecutar solicitudes en paralelo. Además, agregar la estrategia de disponibilidad basada en umbral minimizará aún más la latencia del final y eliminará la pérdida de disponibilidad, si el costo adicional de RU es aceptable.
Al implementar estas estrategias, los desarrolladores pueden garantizar que sus aplicaciones sigan siendo resistentes, mantener un alto rendimiento y proporcionar una mejor experiencia de usuario incluso durante interrupciones regionales o condiciones de alta latencia.
Coherencia de sesión con ámbito de región
Información general
Para más información sobre la configuración de coherencia en general, consulte Niveles de coherencia en Azure Cosmos DB. El SDK de Java proporciona una optimización para la coherencia de sesión para las cuentas de escritura en varias regiones, ya que permite tener un ámbito de región. Esto mejora el rendimiento mediante la mitigación de la latencia de replicación entre regiones por medio de la minimización de los reintentos del lado cliente. Esto se logra mediante la administración de tokens de sesión en el nivel de región en lugar de globalmente. Si tu aplicación solo necesita coherencia en unas pocas regiones, el uso de la coherencia de sesión con ámbito regional puede mejorar el rendimiento y la confiabilidad de las lecturas y escrituras en cuentas de multi-escritura, al reducir los retrasos y reintentos de replicación entre regiones.
Ventajas
- Latencia reducida: al localizar la validación de tokens de sesión en el nivel de región, se reducen las posibilidades de costosos reintentos entre regiones.
- Rendimiento mejorado: minimiza el impacto de la conmutación por error regional y el retraso de la replicación, lo que ofrece una mayor coherencia de lectura y escritura y un menor uso de la CPU.
- Uso optimizado de recursos: reduce la sobrecarga de CPU y red en las aplicaciones cliente limitando la necesidad de reintentos y llamadas entre regiones, lo que optimiza el uso de recursos.
- Alta disponibilidad: al mantener tokens de sesión con ámbito de región, las aplicaciones pueden seguir funcionando sin problemas incluso si ciertas regiones experimentan una mayor latencia o errores temporales.
- Garantías de coherencia: garantiza que las garantías de coherencia de sesión (lectura de la escritura, lectura monotónica) se cumplan de forma más confiable sin reintentos innecesarios.
- Rentabilidad: reduce el número de llamadas entre regiones, lo que podría reducir los costos asociados a las transferencias de datos entre regiones.
- Escalabilidad: permite que las aplicaciones se escalen de forma más eficaz reduciendo la contención y la sobrecarga asociadas con el mantenimiento de un token de sesión global, especialmente en las configuraciones de varias regiones.
Ventajas y desventajas
- Aumento del uso de memoria: El filtro bloom y el almacenamiento de tokens de sesión específicos de la región requieren más memoria, lo que puede ser una consideración para las aplicaciones con recursos limitados.
- Complejidad de la configuración: ajustar el recuento de inserción esperado y la tasa de falsos positivos para el filtro de Bloom agrega una capa de complejidad al proceso de configuración.
- Potencial de falsos positivos: Aunque el filtro bloom minimiza los reintentos entre regiones, todavía hay una ligera probabilidad de falsos positivos que afectan a la validación del token de sesión, aunque se puede controlar la tasa. Un falso positivo significa que se resuelve el token de sesión global, lo que aumenta la posibilidad de reintentos entre regiones si la región local no se ha detectado en esta sesión global. Las garantías de sesión se cumplen incluso en presencia de falsos positivos.
- Aplicabilidad: esta característica es más beneficiosa para las aplicaciones con una alta cardinalidad de particiones lógicas y reinicios normales. Es posible que las aplicaciones con menos particiones lógicas o reinicios poco frecuentes no vean ventajas significativas.
Funcionamiento
Establecimiento del token de sesión
- Finalización de la solicitud: una vez completada una solicitud, el SDK captura el token de sesión y lo asocia a la región y la clave de partición.
-
Almacenamiento de nivel de región: los tokens de sesión se almacenan en un
ConcurrentHashMapanidado que mantiene asignaciones entre intervalos de claves de partición y progreso de nivel de región. - Filtro de Bloom: un filtro de Bloom realiza un seguimiento de las regiones a las que cada partición lógica ha accedido, lo que ayuda a localizar la validación de tokens de sesión.
Resolución del token de sesión
- Inicialización de solicitudes: antes de enviar una solicitud, el SDK intenta resolver el token de sesión de la región adecuada.
- Comprobación de tokens: el token se comprueba con los datos específicos de la región para asegurarse de que la solicitud se enruta a la réplica más actualizada.
- Lógica de reintento: Si el token de sesión no se valida en la región actual, el SDK reintenta con otras regiones, pero dado el almacenamiento localizado, esto es menos frecuente.
Uso del SDK
A continuación se muestra cómo inicializar CosmosClient con coherencia de sesión con ámbito de región:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Habilitación de la coherencia de sesión con ámbito de región
Para habilitar la captura de sesión con ámbito de región en la aplicación, establezca la siguiente propiedad del sistema:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Configuración del filtro de Bloom
Ajuste el rendimiento configurando las inserciones esperadas y la tasa de falsos positivos para el filtro de Bloom:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implicaciones de memoria
A continuación se muestra el tamaño retenido (tamaño del objeto y de lo que depende) del contenedor de sesión interno (administrado por el SDK) con las inserciones variables esperadas en el filtro de Bloom.
| Inserciones esperadas | Tasa de falsos positivos | Tamaño retenido |
|---|---|---|
| 10 000 | 0,001 | 21 KB |
| 100 000 | 0,001 | 183 KB |
| 1 millón | 0,001 | 1.8 MB |
| 10 millones | 0,001 | 17,9 MB |
| 100 millones | 0,001 | 179 MB |
| Mil millones | 0,001 | 1,8 GB |
Importante
Debe usar la versión 4.60.0 del SDK de Java o superior para activar la coherencia de la sesión con ámbito de región.
Regiones excluidas
La característica regiones excluidas permite un control específico sobre el enrutamiento de solicitudes, ya que permite excluir regiones específicas de las ubicaciones preferidas por solicitud. Esta característica está disponible en la versión 4.47.0 del SDK de Java de Azure Cosmos DB y versiones posteriores.
Ventajas clave:
- Controlar la limitación de velocidad: al encontrar respuestas 429 (demasiadas solicitudes), enruta automáticamente las solicitudes a regiones alternativas con rendimiento disponible.
- Enrutamiento dirigido: asegúrese de que las solicitudes se atienden desde regiones específicas excluyendo a todos los demás.
- Omitir orden preferido: invalide la lista de regiones preferidas predeterminada para solicitudes individuales sin crear clientes independientes.
Configuración:
Las regiones excluidas se pueden configurar en el nivel de cliente y en el nivel de solicitud:
CosmosExcludedRegions excludedRegions = new CosmosExcludedRegions(Set.of("East US"));
// Using AtomicReference to simulate dynamic changes to excluded regions. Excluded regions can be set at the
// client level
AtomicReference<CosmosExcludedRegions> excludedRegionsAtomicReference = new AtomicReference<>(excludedRegions);
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint("")
.key("")
.preferredRegions(List.of(new String[]{"West US", "East US"}))
.excludedRegionsSupplier(excludedRegionsAtomicReference::get)
.buildAsyncClient();
CosmosAsyncDatabase cosmosAsyncDatabase = client.getDatabase("Test");
CosmosAsyncContainer cosmosAsyncContainer = cosmosAsyncDatabase.getContainer("TestItems");
// Excluded regions can also be set at the request level
CosmosItemRequestOptions cosmosItemRequestOptions = new CosmosItemRequestOptions().setExcludedRegions(List.of("East US"));
TestObject testItem = TestObject.create("mypkValue");
cosmosAsyncContainer.createItem(testItem, cosmosItemRequestOptions).block();
Ajuste de la coherencia frente a disponibilidad
La característica regiones excluidas proporciona un mecanismo adicional para equilibrar la coherencia y las ventajas de disponibilidad en la aplicación. Esta funcionalidad es valiosa en escenarios dinámicos en los que los requisitos pueden cambiar en función de las condiciones operativas:
Control de interrupciones dinámicas: cuando una región primaria experimenta una interrupción y los umbrales de disyuntor de nivel de partición resultan insuficientes, las regiones excluidas permiten la conmutación por error inmediata sin cambios de código ni reinicios de la aplicación. Esto proporciona una respuesta más rápida a los problemas regionales en comparación con la espera de activación automática del interruptor.
Preferencias de coherencia condicional: las aplicaciones pueden implementar diferentes estrategias de coherencia basadas en el estado operativo:
- Estado estable: priorice las lecturas coherentes excluyendo todas las regiones excepto la principal, lo que garantiza la coherencia de los datos con el costo potencial de disponibilidad.
- Escenarios de interrupción: favorece la disponibilidad sobre la coherencia estricta al permitir el enrutamiento entre regiones, aceptando posibles retrasos en los datos a cambio de la disponibilidad continua del servicio.
Este enfoque permite que los mecanismos externos (como administradores de tráfico o equilibradores de carga) organicen las decisiones de conmutación por error mientras la aplicación mantiene el control sobre los requisitos de coherencia a través de patrones de exclusión de regiones.
Cuando se excluyen todas las regiones, las solicitudes se enrutan a la región principal o central. Esta característica funciona con todos los tipos de solicitud, incluidas las consultas, y es útil para mantener instancias de cliente singleton al lograr un comportamiento de enrutamiento flexible.
Ajuste de la configuración de conexión directa y de puerta de enlace
Para optimizar las configuraciones de conexión de modo directo y de puerta de enlace, consulte cómo optimizar las configuraciones de conexión para el SDK de Java v4.
Uso del SDK
- Instalación del SDK más reciente
Los SDK de Azure Cosmos DB se mejoran constantemente para proporcionar el mejor rendimiento. Para determinar las mejoras más recientes del SDK, visite el SDK de Azure Cosmos DB.
Cada instancia de Azure Cosmos DB está protegida frente a amenazas y realiza de manera eficiente la administración de las conexiones y el almacenamiento en caché de las direcciones. Para permitir una administración de conexiones eficaz y un mejor rendimiento por parte del cliente de Azure Cosmos DB, se recomienda usar una única instancia del cliente de Azure Cosmos DB durante la vigencia de la aplicación.
Cuando se crea una instancia de CosmosClient, la coherencia predeterminada utilizada si no se establece explícitamente es Sesión. Si la lógica de la aplicación no requiere coherencia en el nivel Sesión, establezca el valor de Coherencia en Ocasional. Nota: Se recomienda usar al menos la coherencia en el nivel Sesión en las aplicaciones que emplean el procesador de fuente de cambios de Azure Cosmos DB.
- Uso de la API asincrónica para maximizar el rendimiento aprovisionado
La versión 4 del SDK de Java de Azure Cosmos DB agrupa dos API: sincrónica y asincrónica. En términos generales, la API asincrónica implementa la funcionalidad del SDK, mientras que la API sincrónica es un contenedor fino que realiza llamadas de bloqueo a la API asincrónica. Esto se opone a la anterior versión 2 del SDK de Java asincrónico de Azure Cosmos DB y a la anterior versión 2 del SDK de Java sincrónico de Azure Cosmos DB, que era solo de sincronización y tenía una implementación completamente independiente.
La elección de la API se determina durante la inicialización del cliente; CosmosAsyncClient admite la API asincrónica, mientras que CosmosClient admite la API sincrónica.
La API asincrónica implementa E/S sin bloqueo y es la opción óptima si el objetivo es maximizar el rendimiento al emitir solicitudes para Azure Cosmos DB.
El uso de la API sincrónica puede ser la opción correcta si quiere o necesita una API que bloquee la respuesta a cada solicitud, o si la operación sincrónica es el paradigma dominante en la aplicación. Por ejemplo, es posible que desee la API sincrónica al guardar los datos en Azure Cosmos DB en una aplicación de microservicios, siempre que el rendimiento no sea crítico.
Tenga en cuenta que el rendimiento de la API sincrónica se degrada con un tiempo de respuesta de solicitud creciente, mientras que la API asincrónica puede saturar todas las capacidades de ancho de banda del hardware.
La colocación geográfica puede brindarle un rendimiento más alto y más uniforme cuando se usa la API sincrónica (consulte Colocación de los clientes en la misma región de Azure para aumentar el rendimiento) pero aún no se espera que exceda el rendimiento que puede alcanzar la API asincrónica.
Algunos usuarios también pueden no estar familiarizados con Project Reactor, el marco de Reactive Streams utilizado para implementar la API asincrónica de la versión 4 del SDK de Java de Azure Cosmos DB. Si esto supone un problema, le recomendamos que lea nuestra guía de Reactor Pattern introductoria y, después, eche un vistazo a esta introducción a la programación reactiva con el fin de familiarizarse con estos conceptos. Si ya ha usado Azure Cosmos DB con una interfaz asincrónica y el SDK que usó era la versión 2 del SDK de Java asincrónico de Azure Cosmos DB, es posible que conozca ReactiveX/RxJava pero no esté al corriente de los cambios en Project Reactor. En ese caso, eche un vistazo a nuestra Guía Reactor vs. RxJava para familiarizarse con el tema.
En los fragmentos de código siguientes se muestra cómo inicializar el cliente de Azure Cosmos DB para la operación de API asincrónica o API sincrónica, respectivamente:
API asincrónica del SDK para Java V4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Escalado horizontal de la carga de trabajo de cliente
Si va a realizar pruebas en niveles de alto rendimiento, la aplicación cliente puede crear cuellos de botella, debido a que la máquina limita el uso de CPU o de la red. Si llega a este punto, puede seguir insertando la cuenta de Azure Cosmos DB mediante la escala horizontal de las aplicaciones cliente en varios servidores.
Una buena regla general es no superar un uso de la CPU >50 % en cualquier servidor para mantener baja la latencia.
- Use el programador adecuado (evite el robo de subprocesos de E/S Eventloop de Netty)
La funcionalidad asincrónica del SDK de Java de Azure Cosmos DB se basa en la E/S sin bloqueo de netty. El SDK usa un número fijo de subprocesos de E/S Eventloop de Netty (tantos como núcleos de CPU tenga su máquina) para ejecutar operaciones de E/S. El elemento Flux que devuelve la API emite el resultado en uno de los subprocesos de E/S Eventloop de Netty compartidos. Así que es importante no bloquear dichos subprocesos. Realizar trabajos que hacen un uso elevado de CPU o bloquear operaciones en el subproceso de E/S Eventloop de Netty puede provocar un interbloqueo o reducir el rendimiento del SDK de manera considerable.
Por ejemplo, el código siguiente ejecuta un trabajo que hace un uso elevado de CPU en el subproceso de E/S Eventloop de Netty:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Tras recibir el resultado, debe evitar realizar cualquier trabajo que haga un uso intensivo de CPU sobre un subproceso de Netty de E/S del bucle de eventos. En su lugar, proporcione su propio programador a fin de suministrar su propio subproceso para ejecutar su trabajo, como se muestra a continuación (requiere import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Según el tipo del trabajo, debe usar el programador de Reactor existente adecuado para su trabajo. Obtenga más información aquí Schedulers.
Para comprender aún más el modelo de subprocesos y programación de Project Reactor, consulte esta entrada de blog de Project Reactor.
Para más información sobre la versión 4 del SDK de Java de Azure Cosmos DB, consulte el repositorio único del directorio Azure Cosmos DB del SDK de Azure para Java en GitHub.
- Optimización de la configuración de registro en la aplicación
Por varias razones, debe agregar el registro en un subproceso que genera un alto rendimiento de solicitudes. Si su objetivo es saturar completamente el rendimiento aprovisionado de un contenedor con las solicitudes generadas por este subproceso, las optimizaciones de registro pueden mejorar considerablemente el rendimiento.
- Configuración de un registrador asincrónico
La latencia de un registrador sincrónico necesariamente tiene en cuenta el cálculo de la latencia general de su subproceso generador de solicitudes. Se recomienda un registrador asincrónico como log4j2 para desacoplar la sobrecarga de registro de los subprocesos de la aplicación de alto rendimiento.
- Deshabilitación del registro de Netty
El registro de la biblioteca Netty es muy activo y debe desactivarse (puede que no baste con suprimir el inicio de sesión en la configuración) para evitar costes adicionales de CPU. Si no está en modo de depuración, deshabilite por completo el registro de Netty. De modo que, si va a usar Log4j para eliminar los costos de CPU adicionales que se producen debido al uso de org.apache.log4j.Category.callAppenders() desde Netty, agregue la siguiente línea al código base:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Límite de recursos de archivos abiertos del sistema operativo
Algunos sistemas Linux (como Red Hat) tienen un límite superior sobre el número de archivos abiertos y, por tanto, sobre el número total de conexiones. Ejecute el siguiente código para ver los límites actuales:
ulimit -a
El número de archivos abiertos (nofile) debe ofrecer el espacio suficiente para el tamaño configurado del grupo de conexiones y otros archivos abiertos por el sistema operativo. Se puede modificar para permitir un tamaño mayor del grupo de conexiones.
Abra el archivo limits.conf:
vim /etc/security/limits.conf
Agregue o modifique las siguientes líneas:
* - nofile 100000
- Especificación de la clave de partición en escrituras puntuales
Para mejorar el rendimiento de las escrituras puntuales, especifique la clave de partición del elemento en la llamada API de escritura puntual, como se muestra a continuación:
API asincrónica del SDK para Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
en lugar de proporcionar solo la instancia del elemento, como se muestra a continuación:
API asincrónica del SDK para Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Esta última es compatible, pero agregará latencia a la aplicación; el SDK debe analizar el elemento y extraer la clave de partición.
Operaciones de consulta
Para las operaciones de consulta, consulte las sugerencias de rendimiento para las consultas.
Directiva de indexación
- Exclusión de rutas de acceso sin utilizar de la indexación para acelerar las escrituras
La directiva de indexación de Azure Cosmos DB le permite especificar las rutas de acceso de documentos que se incluirán en la indexación o se excluirán de esta mediante el aprovechamiento de las rutas de acceso de indexación (setIncludedPaths y setExcludedPaths). El uso de rutas de acceso de indexación puede ofrecer un rendimiento de escritura mejorado y un almacenamiento de índices reducido en escenarios en los que los patrones de consulta se conocen de antemano, dado que los costos de indexación están directamente correlacionados con el número de rutas de acceso únicas indexadas. Por ejemplo, en el código siguiente se muestra cómo incluir y excluir secciones completas de los documentos (que también se conocen como subárbol) de la indexación mediante el comodín "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Para más información, consulte Directivas de indexación de Azure Cosmos DB.
Throughput
- Medición y optimización del uso menor de unidades de solicitud por segundo
Azure Cosmos DB ofrece un amplio conjunto de operaciones de base de datos, incluidas consultas relacionales y jerárquicas con funciones definidas por el usuario, procedimientos almacenados y desencadenadores. Todo funciona con los documentos dentro de una colección de base de datos. El costo asociado a cada una de estas operaciones variará en función de la CPU, la E/S y la memoria necesarias para completar la operación. En lugar de administrar y pensar sobre los recursos de hardware, puede pensar en una unidad de solicitud (RU) como una medida única para los recursos necesarios para realizar varias operaciones de la base de datos y dar servicio a una solicitud de la aplicación.
El rendimiento se aprovisiona en función del número de unidades de solicitud establecido para cada contenedor. El consumo de la unidad de solicitud se evalúa como frecuencia por segundo. Las aplicaciones que superan la frecuencia de unidad de solicitud aprovisionada para su contenedor están limitadas hasta que la frecuencia cae por debajo del nivel aprovisionado del contenedor. Si la aplicación requiere un mayor nivel de rendimiento, puede aumentar el rendimiento mediante el aprovisionamiento de unidades de solicitud adicionales.
La complejidad de una consulta afecta a la cantidad de unidades de solicitud consumidas para una operación. El número de predicados, la naturaleza de los predicados, el número de UDF y el tamaño del conjunto de datos de origen influyen en el costo de operaciones de consulta.
Para medir la sobrecarga de cualquier operación (crear, actualizar o eliminar), inspeccione el encabezado x-ms-request-charge para medir el número de unidades de solicitud usadas por estas operaciones. También puede examinar la propiedad RequestCharge equivalente en ResourceResponse<T> o FeedResponse<T>.
API asincrónica del SDK para Java V4 (Maven com.azure::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
El cargo de solicitud devuelto en este encabezado es una fracción de la capacidad de proceso aprovisionada. Por ejemplo, si tiene 2000 RU/segundo aprovisionadas, y si la consulta anterior devuelve 1000 documentos de 1 KB, el costo de la operación será 1000. Por lo tanto, al cabo de un segundo, el servidor atenderá solo dos de estas solicitudes antes de limitar la velocidad de las solicitudes posteriores. Para más información, consulte Unidades de solicitud y la calculadora de unidades de solicitud.
- Administración de la limitación de velocidad y la tasa de solicitudes demasiado grande
Cuando un cliente intenta superar la capacidad de proceso reservada para una cuenta, no habrá ninguna degradación del rendimiento en el servidor y no se utilizará ninguna capacidad de proceso más allá del nivel reservado. El servidor finalizará de forma preventiva la solicitud con RequestRateTooLarge (código de estado HTTP 429) y devolverá el encabezado x-ms-retry-after-ms para indicar la cantidad de tiempo, en milisegundos, que el usuario debe esperar antes de volver a intentar realizar la solicitud.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Los SDK capturan implícitamente esta respuesta, respetan el encabezado retry-after especificado por el servidor y reintentan la solicitud. A menos que varios clientes obtengan acceso a la cuenta al mismo tiempo, el siguiente reintento se realizará correctamente.
Si tiene más de un cliente que opera de forma acumulativa y de manera frecuente por encima de la tasa de solicitudes, puede que no baste con el número de reintentos predeterminado, establecido actualmente en 9 de manera interna por el cliente. En este caso, el cliente producirá CosmosClientException con el código de estado 429 para la aplicación. El número predeterminado de reintentos puede cambiarse con setMaxRetryAttemptsOnThrottledRequests() en la instancia ThrottlingRetryOptions. De forma predeterminada, la excepción CosmosClientException con el código de estado 429 se devuelve tras un tiempo de espera acumulativo de 30 segundos si la solicitud sigue funcionando por encima de la tasa de solicitudes. Esto sucede incluso cuando el número de reintentos actual es inferior al número de reintentos máximo de 9, el valor predeterminado, o un valor definido por el usuario.
Aunque el comportamiento de reintento automático ayuda a mejorar la resistencia y la usabilidad en la mayoría de las aplicaciones, podría no resultar ventajoso al realizar comparativas de rendimiento, en especial al medir la latencia. La latencia observada del cliente aumentará si el experimento llega a la limitación del servidor y hace que el SDK del cliente realice reintentos de forma silenciosa. Para evitar aumentos de latencia durante los experimentos de rendimiento, mida el gasto devuelto por cada operación y asegúrese de que las solicitudes funcionan por debajo de la tasa de solicitudes observada. Para más información, consulte Unidades de solicitud.
- Diseño de documentos más pequeños para un mayor rendimiento
El gasto de solicitud (es decir, el costo de procesamiento de solicitudes) de una operación dada está directamente correlacionado con el tamaño del documento. Las operaciones con documentos grandes cuestan más que las operaciones con documentos pequeños. Idealmente, diseñe la aplicación y los flujos de trabajo para que el tamaño del elemento sea ~1 KB, o un orden o una magnitud similares. En el caso de las aplicaciones dependientes de la latencia, deben evitarse los elementos de gran tamaño, ya que los documentos de varios MB ralentizarán la aplicación.
Pasos siguientes
Para más información sobre cómo diseñar la aplicación para escalarla y obtener un alto rendimiento, consulte Partición y escalado en Azure Cosmos DB.
¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Puede usar la información sobre el clúster de bases de datos existente para el planeamiento de capacidad.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, consulte la información sobre el cálculo de unidades de solicitud mediante núcleos virtuales o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.