Introducción al rendimiento aprovisionado en Azure Cosmos DB
SE APLICA A: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Table
Table
Azure Cosmos DB le permite establecer el rendimiento aprovisionado en las bases de datos y contenedores. Hay dos tipos de rendimiento aprovisionado, estándar (manual) o de escalabilidad automática. En este artículo se proporciona información general sobre cómo funciona el rendimiento aprovisionado.
Una base de datos de Azure Cosmos DB es una unidad de administración de un conjunto de contenedores. Una base de datos consta de un conjunto de contenedores independiente del esquema. Un contenedor de Azure Cosmos DB es la unidad de escalabilidad de rendimiento y almacenamiento. Un contenedor se divide horizontalmente en un conjunto de máquinas dentro de una región de Azure y se distribuye en todas las regiones de Azure asociadas a su cuenta de Azure Cosmos DB.
En Azure Cosmos DB, puede aprovisionar el rendimiento en dos granularidades:
- Contenedores de Azure Cosmos DB
- Bases de datos de Azure Cosmos DB
Establecimiento del rendimiento en un contenedor
El rendimiento aprovisionado en un contenedor de Azure Cosmos DB se reserva exclusivamente para ese contenedor. El contenedor recibe el rendimiento aprovisionado todo el tiempo. El rendimiento aprovisionado en un contenedor está respaldado financieramente por los contratos de nivel de servicio. Para información sobre cómo configurar el rendimiento estándar (manual) en un contenedor, consulte Aprovisionamiento del rendimiento en un contenedor de Azure Cosmos DB. Para obtener información sobre cómo configurar el rendimiento de escalabilidad automática en un contenedor, consulte Aprovisionamiento del rendimiento de escalabilidad automática.
La configuración del rendimiento aprovisionado en un contenedor es la opción más utilizada. Puede escalar elásticamente el rendimiento de un contenedor con el aprovisionamiento de cualquier cantidad de rendimiento mediante el uso de Unidades de solicitud (RU).
El rendimiento aprovisionado de un contenedor se distribuye uniformemente entre las particiones físicas y, suponiendo una buena clave de partición que distribuye las particiones lógicas uniformemente entre las particiones físicas, el rendimiento también se distribuye uniformemente entre todas las particiones lógicas del contenedor. No puede especificar de forma selectiva el rendimiento de las particiones lógicas. Puesto que una o varias particiones lógicas de un contenedor se hospedan en una partición física, las particiones físicas pertenecen exclusivamente al contenedor y admiten el rendimiento aprovisionado en dicho contenedor.
Si la carga de trabajo que se ejecuta en una partición lógica consume más que el rendimiento que se asignó a la partición física subyacente, es posible que las operaciones tengan una velocidad limitada. Lo que se conoce como partición activa ocurre cuando una partición lógica tiene de manera desproporcionada más solicitudes que otros valores de clave de partición.
Cuando se produce una limitación de velocidad, puede aumentar el rendimiento aprovisionado de todo el contenedor o volver a intentar las operaciones. También debe asegurarse de elegir una clave de partición que distribuya de manera uniforme el volumen de la solicitud y el almacenamiento. Para más información sobre la creación de particiones, consulte Creación de particiones y escalado horizontal en Azure Cosmos DB.
Se recomienda configurar el rendimiento en la granularidad del contenedor cuando se quiere un rendimiento predecible para dicho contenedor.
En la imagen siguiente se muestra cómo una partición física hospeda una o varias particiones lógicas de un contenedor:
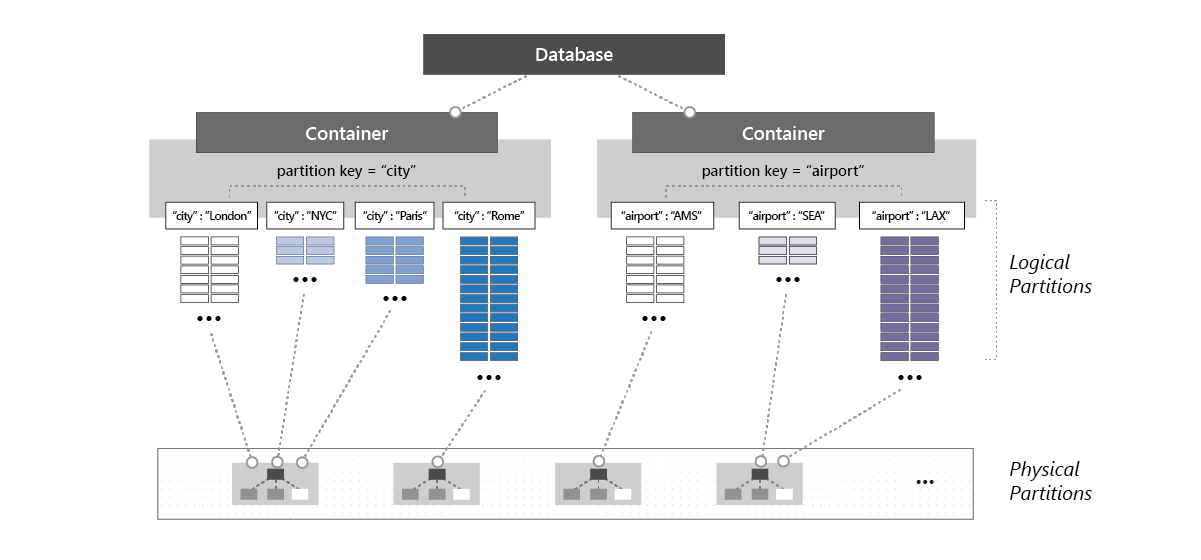
Establecimiento del rendimiento en una base de datos
Al aprovisionar el rendimiento en una base de datos de Azure Cosmos DB, este se comparte entre todos los contenedores (denominados contenedores de base de datos compartidos) de la base de datos. Una excepción es si ha especificado un rendimiento aprovisionado en determinados contenedores de la base de datos. Compartir el rendimiento aprovisionado de nivel de base de datos entre sus contenedores equivale a hospedar una base de datos en un clúster de máquinas. Dado que todos los contenedores de una base de datos comparten los recursos disponibles en una máquina, no obtendrá un rendimiento predecible en ningún contenedor específico. Para información sobre cómo configurar el rendimiento aprovisionado en una base de datos, consulte Aprovisionamiento del rendimiento en una base de datos de Azure Cosmos DB. Para obtener información sobre cómo configurar el rendimiento de escalabilidad automática en una base de datos, consulte Aprovisionamiento del rendimiento de escalabilidad automática.
Dado que todos los contenedores de la base de datos comparten el rendimiento aprovisionado, Azure Cosmos DB no proporciona ninguna garantía de rendimiento predecible para un contenedor determinado de dicha base de datos. La parte del rendimiento que puede recibir un contenedor específico depende de los siguientes factores:
- El número de contenedores.
- La elección de las claves de partición de varios contenedores.
- La distribución de la carga de trabajo en varias particiones lógicas de los contenedores.
Se recomienda configurar el rendimiento en una base de datos si quiere compartir el rendimiento entre varios contenedores, pero no dedicarlo a ningún contenedor específico.
En los siguientes ejemplos se muestra dónde es preferible aprovisionar el rendimiento en el nivel de base de datos:
El uso compartido del rendimiento aprovisionado de una base de datos a través de un conjunto de contenedores es útil para una aplicación de varios inquilinos. Cada usuario puede representarse mediante un contenedor de Azure Cosmos DB diferente.
El uso compartido del rendimiento aprovisionado de una base de datos a través de un conjunto de contenedores es útil al migrar una base de datos de NoSQL, como MongoDB o Cassandra, hospedada en un clúster de VM o desde servidores físicos locales a Azure Cosmos DB. Puede considerar el rendimiento aprovisionado configurado en la base de datos de Azure Cosmos DB como un equivalente lógico, pero más rentable y flexible, de la capacidad de proceso del clúster de MongoDB o Cassandra.
Todos los contenedores creados en una base de datos con rendimiento aprovisionado deben crearse con una clave de partición. En cualquier momento, el rendimiento asignado a un contenedor de una base de datos se distribuye entre todas las particiones lógicas de dicho contenedor. Cuando hay contenedores que comparten el rendimiento aprovisionado configurado en una base de datos, el rendimiento no se puede aplicar de forma selectiva a un contenedor específico o a una partición lógica.
Si la carga de trabajo en una partición lógica consume más que el rendimiento que se asignó a una partición lógica específica, las operaciones tendrán una velocidad limitada. Cuando se produce una limitación de velocidad, puede aumentar el rendimiento de toda la base de datos o volver a intentar las operaciones. Para más información sobre las particiones, consulte Particiones lógicas.
Los contenedores de una base de datos de rendimiento compartido comparten el rendimiento (RU/s) asignado a dicha base de datos. Con el rendimiento aprovisionado (manual) estándar, puede tener hasta 25 contenedores con un mínimo de 400 RU/s en la base de datos. Con el rendimiento aprovisionado de escalabilidad automática, puede tener hasta 25 contenedores en una base de datos con 1000 RU/s como mínimo de escalabilidad automática (escalas entre 100 y 1000 RU/s).
Nota:
En febrero de 2020, se presentó un cambio que permite tener un máximo de 25 contenedores en una base de datos de rendimiento compartida, lo que permite el uso compartido del rendimiento entre los contenedores. Después de los primeros 25 contenedores, solo puede agregar más a la base de datos si están aprovisionados con un rendimiento dedicado, que es independiente del rendimiento compartido de la base de datos.
Si la cuenta de Azure Cosmos DB ya contiene una base de datos de rendimiento compartida con >= 25 contenedores, la cuenta y todas las demás cuentas de la misma suscripción de Azure están exentas de este cambio. Póngase en contacto con el servicio de soporte técnico si tiene comentarios o preguntas.
Si las cargas de trabajo implican eliminar y volver a crear todas las colecciones de una base de datos, se recomienda quitar la base de datos vacía y volver a crear una nueva base de datos antes de la creación de la colección. En la siguiente imagen se muestra cómo una partición física puede hospedar una o varias particiones lógicas que pertenecen a distintos contenedores dentro de una base de datos:
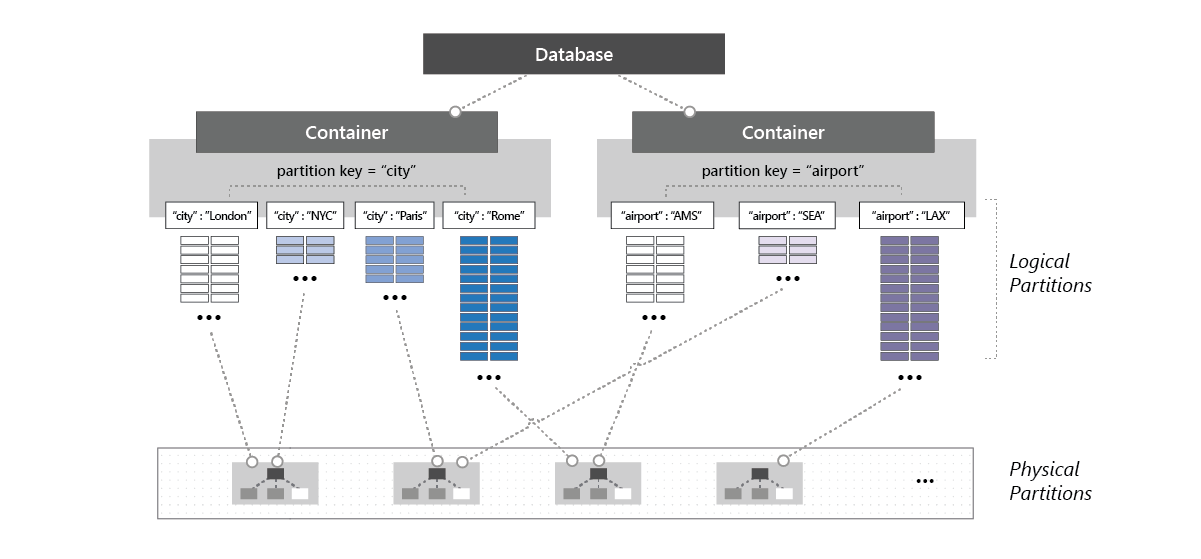
Establecimiento del rendimiento en un contenedor y una base de datos
Puede combinar los dos modelos. Se permite el aprovisionamiento del rendimiento tanto en la base de datos como en el contenedor. En el ejemplo siguiente se muestra cómo aprovisionar el rendimiento aprovisionado estándar (manual) en un contenedor y una base de datos de Azure Cosmos DB:
Puede crear una base de datos de Azure Cosmos DB llamada Z con rendimiento aprovisionado estándar (manual) de "K" RU.
Después, cree cinco contenedores llamados A, B, C, D y E en la base de datos. Al crear el contenedor B, asegúrese de habilitar la opción Provision dedicated throughput for this container (Aprovisionar el rendimiento dedicado para este contenedor) y configurar de forma explícita las Unidades de solicitud "P" del rendimiento aprovisionado en este contenedor. Puede configurar el rendimiento compartido y dedicado solamente al crear la base de datos y el contenedor.
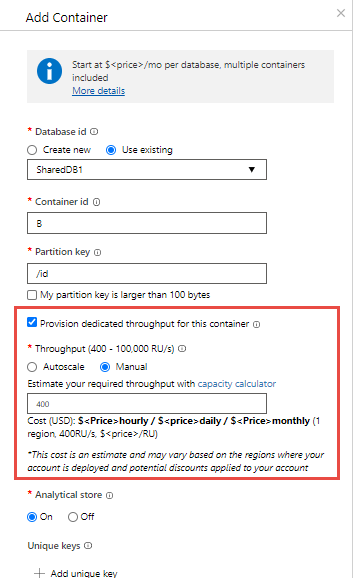
El rendimiento de las Unidades de solicitud "K" se comparte entre los cuatro contenedores A, C, D y E. La cantidad exacta de rendimiento disponible en A, C, D o E varía. No hay ningún acuerdo de nivel de servicio para el rendimiento de cada contenedor individual.
Se garantiza que el contenedor llamado B obtendrá el rendimiento de las Unidades de solicitud de "P" todo el tiempo. Estará respaldado por los Acuerdos de Nivel de Servicio.
Nota:
No se puede convertir un contenedor con rendimiento aprovisionado en un contenedor de base de datos compartido. A la inversa, un contenedor de base de datos compartido no se puede convertir para tener un rendimiento dedicado. Deberá mover los datos a un contenedor con la configuración de rendimiento que quiera. (Los trabajos de copia de contenedores para las API de NoSQL, MongoDB y Cassandra ayudan en este proceso).
Actualización del rendimiento en un contenedor o una base de datos
Después de crear un contenedor o una base de datos de Azure Cosmos DB se puede actualizar el rendimiento aprovisionado. No existen límites para el rendimiento aprovisionado máximo que se puede configurar en la base de datos o el contenedor.
Rendimiento aprovisionado actual
Puede recuperar el rendimiento aprovisionado de un contenedor o una base de datos en Azure Portal o mediante los SDK:
- Container.ReadThroughputAsync en el SDK de .NET.
- CosmosContainer.readThroughput en el SDK para Java.
La respuesta de estos métodos también contiene el rendimiento mínimo aprovisionado para el contenedor o la base de datos:
- ThroughputResponse.MinThroughput en el SDK de .NET.
- ThroughputResponse.getMinThroughput() en el SDK para Java.
El valor mínimo real de RU/s puede variar en función de la configuración de la cuenta. Para obtener más información, consulte Preguntas frecuentes sobre la escalabilidad automática.
Cambio del rendimiento aprovisionado
Puede escalar el rendimiento aprovisionado de un contenedor o una base de datos mediante Azure Portal o los SDK:
- Container.ReplaceThroughputAsync en el SDK de .NET.
- CosmosContainer.replaceThroughput en el SDK para Java.
Si reduce el rendimiento aprovisionado, podrá hacerlo hasta el mínimo.
Si aumenta el rendimiento aprovisionado, la operación es instantánea en la mayor parte del tiempo. Sin embargo, hay casos en los que la operación puede tardar más tiempo debido a las tareas del sistema destinadas a aprovisionar los recursos necesarios. En este caso, si se intenta modificar el rendimiento aprovisionado mientras esta operación está en curso, se produce una respuesta HTTP 423 con un mensaje de error que explica que hay otra operación de escalado en curso.
Obtenga más información en el artículo Procedimientos recomendados para escalar el rendimiento aprovisionado (RU/s).
Nota:
Si planea una carga de trabajo de ingesta muy grande que requerirá un gran aumento en el rendimiento aprovisionado, tenga en cuenta que la operación de escalado no tiene ningún Acuerdo de Nivel de Servicio y, como se mencionó en el párrafo anterior, puede tardar mucho tiempo si el aumento es grande. Tal vez desee planear por anticipado e iniciar el escalado antes de que se inicie la carga de trabajo y usar los métodos siguientes para comprobar el progreso.
Para comprobar el progreso del escalado mediante programación, consulte el rendimiento aprovisionado actual y utilice:
- ThroughputResponse.IsReplacePending en el SDK de .NET.
- ThroughputResponse.isReplacePending() en el SDK para Java.
Puede usar métricas de Azure Monitor para ver el historial de rendimiento aprovisionado (RU/s) y el almacenamiento en un recurso.
Comparación de modelos
En esta tabla se muestra una comparación entre el aprovisionamiento del rendimiento estándar (manual) en una base de datos frente a un contenedor.
| Parámetro | Rendimiento estándar (manual) en una base de datos | Rendimiento estándar (manual) en un contenedor | Rendimiento de escalabilidad automática en una base de datos | Rendimiento de escalabilidad automática en un contenedor |
|---|---|---|---|---|
| Punto de entrada (mínimo de RU/s) | 400 RU/s. Puede tener hasta 25 contenedores sin un mínimo de RU/s por contenedor. | 400 | Escalabilidad automática entre 100 y 1000 RU/s. Puede tener hasta 25 contenedores sin un mínimo de RU/s por contenedor. | Escalabilidad automática entre 100 y 1000 RU/s. |
| Mínimo de RU/s por contenedor | -- | 400 | -- | Escalabilidad automática entre 100 y 1000 RU/s |
| Número máximo de RU | Ilimitado, en la base de datos. | Ilimitado, en el contenedor. | Ilimitado, en la base de datos. | Ilimitado, en el contenedor. |
| RU asignadas o disponibles para un contenedor específico | Sin garantías. Las RU asignadas a un contenedor determinado dependen de las propiedades. Las propiedades pueden ser la elección de las claves de partición de contenedores que comparten el rendimiento, la distribución de la carga de trabajo y el número de contenedores. | Todas las RU configuradas en el contenedor se reservan exclusivamente para el contenedor. | Sin garantías. Las RU asignadas a un contenedor determinado dependen de las propiedades. Las propiedades pueden ser la elección de las claves de partición de contenedores que comparten el rendimiento, la distribución de la carga de trabajo y el número de contenedores. | Todas las RU configuradas en el contenedor se reservan exclusivamente para el contenedor. |
| Almacenamiento máximo de un contenedor | Sin límite. | Sin límite | Sin límite | Sin límite |
| Rendimiento máximo por partición lógica de un contenedor | 10 000 RU/s | 10 000 RU/s | 10 000 RU/s | 10 000 RU/s |
| Almacenamiento máximo (datos + índice) por partición lógica de un contenedor | 20 GB | 20 GB | 20 GB | 20 GB |
Pasos siguientes
- Más información sobre las particiones lógicas.
- Más información sobre el aprovisionamiento del rendimiento estándar (manual) de un contenedor de Azure Cosmos DB.
- Más información sobre el aprovisionamiento del rendimiento estándar (manual) en una base de datos de Azure Cosmos DB.
- Aprenda a aprovisionar el rendimiento de escalabilidad automática en una base de datos o contenedor de Azure Cosmos DB.
- ¿Intenta planear la capacidad de una migración a Azure Cosmos DB? Para ello, puede usar información sobre el clúster de bases de datos existente.
- Si lo único que sabe es el número de núcleos virtuales y servidores del clúster de bases de datos existente, lea sobre el cálculo de unidades de solicitud mediante núcleos o CPU virtuales.
- Si conoce las tasas de solicitudes típicas de la carga de trabajo de la base de datos actual, obtenga información sobre el cálculo de unidades de solicitud mediante la herramienta de planeamiento de capacidad de Azure Cosmos DB.