Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Con la federación de consultas, las consultas se delegan a la base de datos ajena mediante las APIs JDBC. La consulta se ejecuta tanto en Databricks como mediante cálculo remoto. La federación de consultas se usa para orígenes como MySQL, PostgreSQL, Redshift, Teradata, etc.
¿Por qué usar la federación de Lakehouse?
Lakehouse destaca el almacenamiento central de datos para reducir la redundancia y el aislamiento de los datos. Su organización puede tener numerosos sistemas de datos en producción y es posible que desee consultar datos en sistemas conectados por varias razones:
- Informes a petición.
- Trabajo de prueba de concepto.
- Fase exploratoria de nuevas canalizaciones o informes de ETL.
- Soporte con cargas de trabajo durante la migración incremental.
En cada uno de estos escenarios, la federación de consultas le permite obtener información más rápida, ya que puede consultar los datos en su lugar y evitar un procesamiento ETL complejo y lento.
La federación de consultas está pensada para casos de uso cuando:
- No desea ingerir datos en Azure Databricks.
- Quiere que las consultas aprovechen el proceso en el sistema de base de datos externo.
- Quiere las ventajas de las interfaces de Unity Catalog y la gobernanza de datos, incluido el control de acceso específico, el linaje de datos y la búsqueda.
Comparación entre la federación de consultas y Lakeflow Connect
La federación de consultas permite consultar orígenes de datos externos sin mover los datos. Databricks recomienda la ingesta mediante conectores administrados de Lakeflow Connect, ya que se escalan para dar cabida a grandes volúmenes de datos y a una menor latencia de consulta. Sin embargo, es posible que quiera consultar los datos sin moverlos. Cuando tenga una opción entre los conectores de ingestión administrados y la federación de consultas, elija la federación de consultas para informes ad hoc o trabajo de prueba de concepto en las canalizaciones de ETL.
Si el origen lo admite, los conectores de ingesta basados en consultas son una alternativa ligera de Lakeflow Connect a los conectores CDC. Consultan el origen directamente según una programación mediante una columna de cursor, sin necesidad de una puerta de enlace o almacenamiento provisional. Use conectores de ingesta basados en consultas cuando necesite ingesta periódica, pero no tenga disponible la infraestructura CDC.
Información general sobre la configuración de federación de consultas
Para que un conjunto de datos esté disponible para consultas de solo lectura mediante la federación de Lakehouse, cree lo siguiente:
- Una conexión, un objeto protegible en el catálogo de Unity que especifica una ruta de acceso y credenciales para acceder a un sistema de base de datos externo.
- Un catálogo externo, un objeto protegible en el catálogo de Unity que refleja una base de datos en un sistema de datos externo, lo que le permite realizar consultas de solo lectura en ese sistema de datos en el área de trabajo de Azure Databricks, administrando el acceso mediante el catálogo de Unity.
Orígenes de datos compatibles
La federación de consultas admite conexiones con los siguientes orígenes:
- MySQL
- PostgreSQL
- Teradata
- Oracle
- Amazon Redshift
- Datos de Salesforce 360
- Snowflake
- Microsoft SQL Server
- Azure Synapse (SQL Data Warehouse)
- Google BigQuery
- Databricks
Requisitos de conexión
Requisitos del área de trabajo:
- Área de trabajo habilitada para Unity Catalog. Las áreas de trabajo creadas después del 9 de noviembre de 2023 están habilitadas automáticamente para el Catálogo de Unity, incluido el aprovisionamiento automático de metastores. No es necesario crear manualmente una tienda de metadatos a menos que su área de trabajo sea anterior a la habilitación automática y no se haya habilitado para Unity Catalog. Consulte Habilitación automática de Unity Catalog.
Requisitos de proceso:
- Conectividad de red desde su recurso de computación a los sistemas de bases de datos de destino. Consulte Recomendaciones de redes para Lakehouse Federation.
- Azure Databricks debe usar el Databricks Runtime 13.3 LTS o superior y en modo de acceso Standard o Dedicated.
- Los almacenes de SQL deben ser pro o sin servidor y deben usar 2023.40 o superior.
Permisos necesarios:
- Para crear una conexión, debe ser administrador del metastore o usuario con el privilegio
CREATE CONNECTIONen el metastore de Unity Catalog adjunto al área de trabajo. En las áreas de trabajo habilitadas para el catálogo de Unity automáticamente, los administradores del área de trabajo tienen elCREATE CONNECTIONprivilegio de forma predeterminada. - Para crear un catálogo externo, debe tener el permiso
CREATE CATALOGen el metastore, y ser el propietario de la conexión o tener el privilegioCREATE FOREIGN CATALOGen la conexión. En las áreas de trabajo habilitadas para el catálogo de Unity automáticamente, los administradores del área de trabajo tienen elCREATE CATALOGprivilegio de forma predeterminada.
Los requisitos de permisos adicionales se especifican en cada sección basada en tareas que se indica a continuación.
Creación de una conexión
Una conexión especifica una ruta de acceso y credenciales para acceder a un sistema de base de datos externo. Para crear una conexión, puede usar el Explorador de catálogos o el comando /CREATE CONNECTION SQL en un cuaderno de Azure Databricks o en el editor de consultas SQL de Databricks.
Note
También puede usar la API REST de Databricks o la CLI de Databricks para crear una conexión. Vea POST/api/2.1/unity-catalog/connections y Comandos de Unity Catalog.
Permisos necesarios: administrador del metastore o usuario con el privilegio CREATE CONNECTION.
Explorador de catálogos
En el área de trabajo de Azure Databricks, haga clic en
 Catalog.
Catalog.En la parte superior del panel Catálogo , haga clic en el
 Agregar y seleccione Crear una conexión en el menú.
Agregar y seleccione Crear una conexión en el menú.Escriba un nombre de conexión fácil de usar .
Seleccione el tipo de conexión (proveedor de base de datos, como MySQL o PostgreSQL).
(Opcional) Agregue un comentario.
Haga clic en Siguiente.
Escriba las propiedades de conexión (como la información del host, la ruta de acceso y las credenciales de acceso).
Cada tipo de conexión requiere información de conexión diferente. Consulte el artículo sobre el tipo de conexión, que aparece en la tabla de contenido a la izquierda.
Haga clic en Crear conexión.
Escribe un nombre para el catálogo externo.
(Opcional) Haga clic en Probar conexión para confirmar que funciona.
Haga clic en Crear catálogo.
Seleccione las áreas de trabajo en las que los usuarios pueden acceder al catálogo que creó. Puedes seleccionar Todas las áreas de trabajo tienen acceso, o hacer clic en Asignar a áreas de trabajo, seleccionar las áreas de trabajo y luego hacer clic en Asignar.
Cambia el Propietario que podrá administrar el acceso a todos los objetos del catálogo. Comienza a escribir una entidad de seguridad en el cuadro de texto y, después, haz clic en la entidad de seguridad dentro de los resultados devueltos.
Concede Privilegios en el catálogo. Haga clic en Conceder:
- Especifica las Entidades de seguridad que tendrán acceso a los objetos del catálogo. Comienza a escribir una entidad de seguridad en el cuadro de texto y, después, haz clic en la entidad de seguridad dentro de los resultados devueltos.
- Selecciona los Preajustes de privilegios que vas a conceder a cada entidad de seguridad. A todos los usuarios de la cuenta se les concede
BROWSEde forma predeterminada.- Seleccione Data Reader en el menú desplegable para conceder privilegios
readsobre objetos en el catálogo. - Seleccione Editor de datos en el menú desplegable para conceder los privilegios
readymodifyen objetos del catálogo. - Seleccione manualmente los privilegios que se van a conceder.
- Seleccione Data Reader en el menú desplegable para conceder privilegios
- Haga clic en Conceder.
- Haga clic en Siguiente.
- En la página Metadatos, especifica pares clave-valor de etiquetas. Para obtener más información, consulte Aplicar etiquetas a los objetos securitizables de Unity Catalog.
- (Opcional) Agregue un comentario.
- Haz clic en Guardar.
SQL
Ejecute el siguiente comando en un cuaderno o en el editor de consultas SQL. Este ejemplo es para las conexiones a una base de datos PostgreSQL. Las opciones difieren según el tipo de conexión. Consulte el artículo sobre el tipo de conexión, que aparece en la tabla de contenido a la izquierda.
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user '<user>',
password '<password>'
);
Se recomienda usar Azure Databricks secrets en lugar de cadenas de texto no cifrado para valores confidenciales como credenciales. Por ejemplo:
CREATE CONNECTION <connection-name> TYPE postgresql
OPTIONS (
host '<hostname>',
port '<port>',
user secret ('<secret-scope>','<secret-key-user>'),
password secret ('<secret-scope>','<secret-key-password>')
)
Para obtener más información sobre la configuración de secretos, consulte Administración de secretos.
Para obtener información sobre cómo administrar las conexiones existentes, consulte Administración de conexiones para la federación de Lakehouse.
Creación de un catálogo externo
Note
Si usa la interfaz de usuario para crear una conexión con el origen de datos, se incluye la creación de catálogos externos y puede omitir este paso.
Un catálogo externo refleja una base de datos en un sistema de datos externo para poder consultar y administrar el acceso a los datos de esa base de datos mediante Azure Databricks y catálogo de Unity. Para crear un catálogo externo, use una conexión al origen de datos que ya se ha definido.
Para crear un catálogo externo, puede usar el Explorador de catálogos o el comando CREATE FOREIGN CATALOG SQL en un cuaderno de Azure Databricks o en el editor de consultas SQL. También puede usar la API de Unity Catalog. Consulte Azure Databricks documentación de referencia.
Los metadatos del catálogo externo se sincronizan con Unity Catalog en cada interacción con el catálogo. Para la asignación de tipos de datos entre unity Catalog y el origen de datos, consulte la sección Asignaciones de tipos de datos de la documentación de cada origen de datos.
Permisos necesarios:CREATE CATALOG permiso en el metastore y la propiedad de la conexión o el privilegio CREATE FOREIGN CATALOG en la conexión.
Explorador de catálogos
En el área de trabajo de Azure Databricks, haga clic en
Catalog para abrir el Explorador de catálogos.En la parte superior del panel Catálogo , haga clic en el
Agregar datos y seleccione Crear un catálogo en el menú.Como alternativa, en la página Acceso rápido, haga clic en el botón Catálogos y, a continuación, haga clic en el botón Crear catálogo.
Siga las instrucciones para crear catálogos externos en Crear catálogos.
SQL
Ejecute el siguiente comando SQL en un cuaderno o en un editor de consultas SQL. Los elementos entre corchetes son opcionales. Reemplace los valores de marcador de posición:
-
<catalog-name>: nombre del catálogo en Azure Databricks. -
<connection-name>: el objeto de conexión que especifica el origen de datos, la ruta de acceso y las credenciales de acceso. -
<database-name>: nombre de la base de datos que desea reflejar como catálogo en Azure Databricks. No es necesario para MySQL, que usa un espacio de nombres de dos capas. -
<external-catalog-name>: solo Databricks a Databricks: nombre del catálogo en el área de trabajo de Databricks externa que va a reflejar. Consulte Creación de un catálogo externo.
CREATE FOREIGN CATALOG [IF NOT EXISTS] <catalog-name> USING CONNECTION <connection-name>
OPTIONS (database '<database-name>');
Para obtener información sobre cómo administrar y trabajar con catálogos externos, vea Administrar y trabajar con catálogos externos.
Actualizar metadatos usando Lakeflow Jobs
El Catálogo de Unity actualiza automáticamente los metadatos de las tablas externas en el momento de la consulta. Si cambia el esquema del catálogo externo, El catálogo de Unity captura los metadatos más recientes cuando se ejecuta la consulta. Este comportamiento mantiene el esquema actualizado y es óptimo para la mayoría de las cargas de trabajo.
Sin embargo, Databricks recomienda actualizar manualmente los metadatos en los casos siguientes:
- Para mantener la coherencia de las tablas externas a las que acceden los motores externos. Las rutas de acceso que omiten Databricks Runtime no desencadenan actualizaciones automáticas, lo que puede dar lugar a metadatos obsoletos.
- Para mejorar el rendimiento de las cargas de trabajo en las que desea evitar la actualización de metadatos durante la ejecución de la consulta. La actualización proactiva de metadatos permite que las consultas se ejecuten más rápido mediante metadatos almacenados en caché. Este enfoque es especialmente útil inmediatamente después de crear un catálogo externo porque la primera consulta desencadena una actualización completa.
En estos casos, programe una actualización periódica de metadatos mediante un trabajo de Lakeflow con el REFRESH FOREIGN comando SQL. Por ejemplo:
-- Refresh an entire catalog
> REFRESH FOREIGN CATALOG some_catalog;
-- Refresh a specific schema
> REFRESH FOREIGN SCHEMA some_catalog.some_schema;
-- Refresh a specific table
> REFRESH FOREIGN TABLE some_catalog.some_schema.some_table;
Configure el trabajo para que se ejecute a intervalos regulares en función de la frecuencia con la que se prevén cambios en el esquema externo.
Cargar datos desde tablas externas con vistas materializadas
Databricks recomienda cargar datos externos mediante la federación de consultas al crear vistas materializadas. Consulte Vistas materializadas.
Al usar la federación de consultas, los usuarios pueden hacer referencia a los datos federados de la siguiente manera:
CREATE MATERIALIZED VIEW xyz AS SELECT * FROM federated_catalog.federated_schema.federated_table;
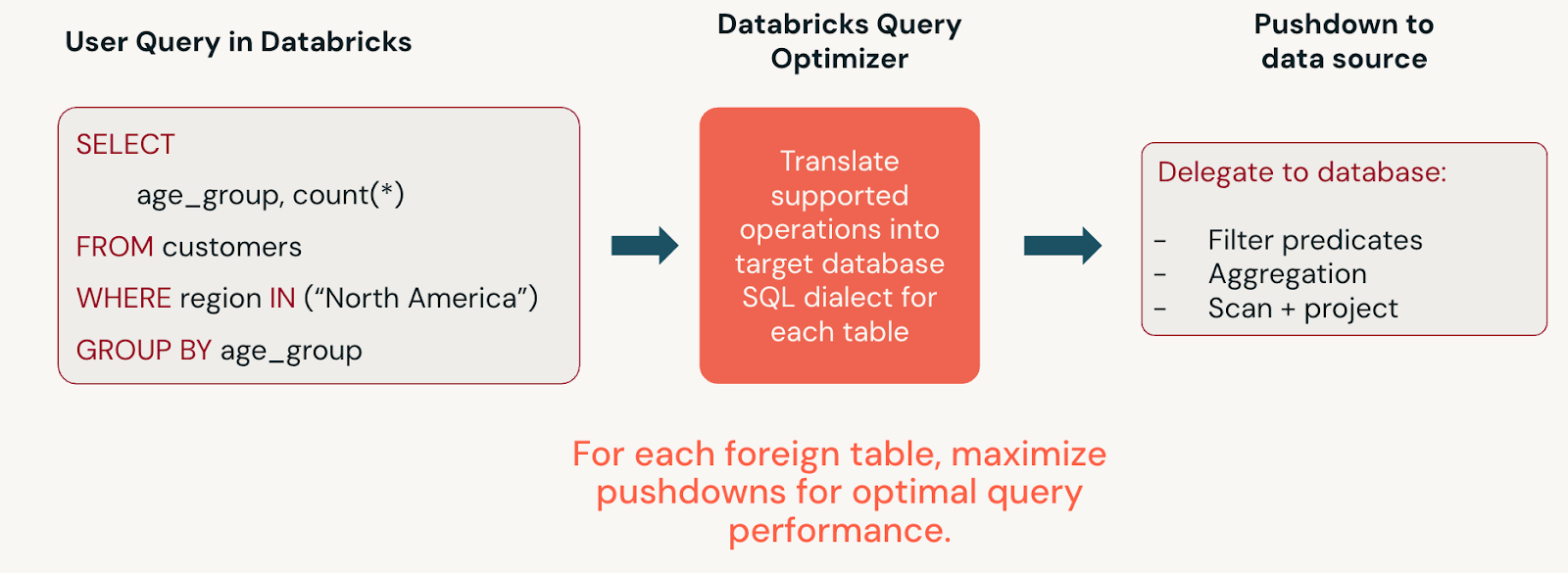
Visualización de consultas federadas generadas por el sistema
La federación de consultas traduce las instrucciones SQL de Databricks en instrucciones que se pueden insertar en el origen de datos federado. Para ver la instrucción SQL generada, haga clic en el nodo de exploración de datos externos en la vista del gráfico del perfil de consulta de , o ejecute la instrucción SQL EXPLAIN FORMATTED. Consulte la sección Pushdown admitido de la documentación de cada origen de datos para obtener información sobre la cobertura.
Limitations
- Las consultas son de solo lectura. La única excepción es cuando Lakehouse Federation se utiliza para federar el metastore de Hive heredado de un área de trabajo (federación de catálogo). Las tablas externas de ese escenario son escribibles. Consulte ¿Qué significa escribir en un catálogo externo en una metastore de Hive federada?.
- La limitación de conexiones se determina mediante el límite de consultas simultáneas de Databricks SQL. No hay ningún límite en los almacenes por conexión. Consulte Lógica de puesta en cola y escalado automático.
- El almacenamiento en caché de consultas de Databricks (caché de resultados y caché de disco) no se admite para las consultas federadas. Esto significa que el
use_cached_resultparámetro no se aplica a las consultas en orígenes federados. - Las tablas y esquemas con nombres que no son válidos en Unity Catalog no se admiten y se omiten en el catálogo de Unity al crear un catálogo externo. Consulte la lista de reglas de nomenclatura y limitaciones en Limitaciones.
- Los nombres de tabla y los nombres de esquema se convierten a minúsculas en el catálogo de Unity. Si esto provoca colisiones de nombres, Databricks no puede garantizar qué objeto se importa en el catálogo externo.
- Para cada tabla externa a la que se hace referencia, Databricks programa una subconsulta en el sistema remoto para devolver un subconjunto de datos de esa tabla y, a continuación, devuelve el resultado a una tarea del ejecutor de Databricks en una sola secuencia. Si el conjunto de resultados es demasiado grande, el ejecutor podría quedarse sin memoria.
- El modo de acceso dedicado (anteriormente modo de acceso de usuario único) solo está disponible para los usuarios que poseen la conexión.
- La federación de Lakehouse no puede manejar tablas externas con identificadores que distinguen entre mayúsculas y minúsculas en conexiones de Azure Synapse o Redshift.
Cuotas de recursos
Azure Databricks aplica cuotas de recursos en todos los objetos protegibles del catálogo de Unity. Estas cuotas se enumeran en Límites de recursos. Los catálogos externos y todos los objetos que contienen se incluyen en el uso total de las cuotas.
Si espera superar estos límites de recursos, póngase en contacto con el equipo de la cuenta de Azure Databricks.
Puede supervisar el uso de la cuota mediante las API de cuotas de recursos de Unity Catalog. Vea Supervisión del uso de cuotas de recursos de Unity Catalog.