Pruebas comparativas de rendimiento de Azure AI Search
Importante
Estos puntos de referencia se aplican a los servicios de búsqueda creados antes del 3 de abril de 2024 en implementaciones que se ejecutan en una infraestructura anterior. Las pruebas comparativas también se aplican solo a las cargas de trabajo no vectoriales. Las actualizaciones están pendientes para los servicios y las cargas de trabajo en los nuevos límites.
Las pruebas comparativas de rendimiento son útiles para estimar el rendimiento potencial en configuraciones similares. El rendimiento real depende de una variedad de factores, incluido el tamaño del servicio de búsqueda y los tipos de consultas que va a enviar.
Para ayudarle a calcular el tamaño del servicio de búsqueda necesario para la carga de trabajo, hemos realizado varios puntos de referencia para documentar el rendimiento de diferentes servicios de búsqueda y configuraciones.
Para cubrir una variedad de casos de uso diferentes, hemos realizado puntos de referencia para dos escenarios principales:
- Búsqueda de comercio electrónico: este punto de referencia emula un escenario real de comercio electrónico y se basa en la empresa de comercio electrónico escandinava CDON.
- Búsqueda de documentos: este escenario se compone de una búsqueda de palabras clave en documentos de texto completo de Semantic Scholar. Esto emula una solución de búsqueda de documentos típica.
Aunque estos escenarios reflejan distintos casos de uso, cada escenario es diferente, por lo que siempre se recomienda realizar pruebas de rendimiento de la carga de trabajo individual. Publicamos una solución de pruebas de rendimiento con JMeter para que pueda ejecutar pruebas similares en su propio servicio.
Metodología de prueba
Para realizar puntos de referencia del rendimiento de Azure AI Search, llevamos a cabo pruebas para dos escenarios diferentes con distintos niveles y combinaciones réplica-partición.
Para crear estos puntos de referencia, se usó la siguiente metodología:
- La prueba comienza en
Xconsultas por segundo (QPS) durante 180 segundos. Normalmente, la cifra es de 5 o 10 QPS. - A continuación, las QPS se aumentan en
Xy se ejecutan durante otros 180 segundos. - Cada 180 segundos, la prueba aumenta en
XQPS hasta que la latencia media supera los 1000 ms o menos del 99 % de las consultas son correctas.
En el siguiente grafo se muestra el aspecto de la carga de consulta de la prueba:
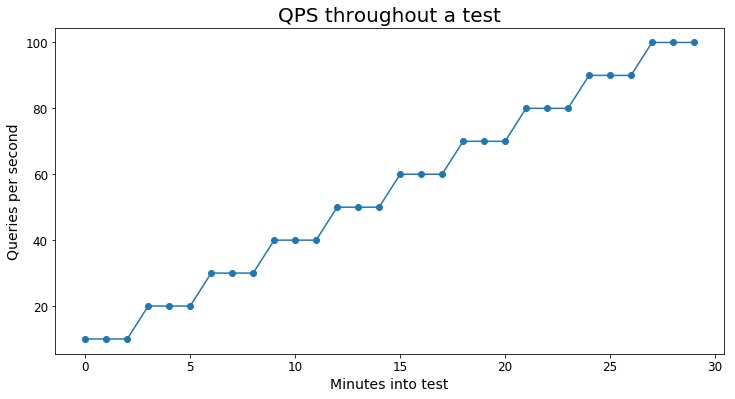
Cada escenario usó al menos 10 000 consultas únicas para evitar que las pruebas resultaran demasiado asimétricas por el almacenamiento en caché.
Importante
Estas pruebas solo incluyen cargas de trabajo de consulta. Si espera tener un gran volumen de operaciones de indexación, asegúrese de tenerlo en cuenta en las pruebas de estimación y rendimiento. Puede encontrar código de ejemplo para simular la indexación en este tutorial.
Definiciones
QPS máximo: los números máximos de QPS se basan en el QPS más alto obtenido en una prueba en la que el 99 % de las consultas se completaron correctamente sin limitación y la latencia media se quedó por debajo de 1000 ms.
Porcentaje de QPS máximo: porcentaje de QPS máximo obtenido para una prueba determinada. Por ejemplo, si una prueba determinada alcanzó un máximo de 100 QPS, el 20 % de QPS máximo sería 20 QPS.
Latencia: latencia del servidor para una consulta; estos números no incluyen el tiempo de ida y vuelta (RTT). Los valores se expresan en milisegundos (ms).
Declinación de responsabilidades de pruebas
El código que usamos para ejecutar estas pruebas comparativas está disponible en el repositorio azure-search-performance-testing. Cabe señalar que observamos niveles de QPS ligeramente inferiores con la solución de pruebas de rendimiento de JMeter que con los puntos de referencia. Esta distinción se puede atribuir a diferencias en el estilo de las pruebas. Esto confirma la importancia de hacer que las pruebas de rendimiento se asemejen lo más posible a su carga de trabajo de producción.
Importante
Estos puntos de referencia de ninguna manera garantizan un cierto nivel de rendimiento del servicio, pero pueden darle una idea del rendimiento que puede esperar en función de su escenario.
Si tiene comentarios o preguntas, póngase en contacto con nosotros en azuresearch_contact@microsoft.com.
Punto de referencia 1: búsqueda de comercio electrónico
![]()
Este punto de referencia se creó en colaboración con la empresa de comercio electrónico CDON, el marketplace en línea más grande de la región nórdica, con operaciones en Suecia, Finlandia, Noruega y Dinamarca. A través de sus 1500 comerciantes, CDON ofrece un amplio catálogo que incluye más de 8 millones de productos. En 2020, CDON tuvo más de 120 millones de visitantes y dos millones de clientes activos. Puede obtener más información acerca de cómo CDON usa Azure AI Search en este artículo.
Para ejecutar estas pruebas, hemos usado una instantánea del índice de búsqueda de producción de CDON y miles de consultas únicas de su sitio web.
Detalles del escenario
- Número de documentos: 6 000 000
- Tamaño del índice: 20 GB
- Esquema de índice: índice amplio con 250 campos en total, 25 campos que permiten búsquedas y 200 campos que permiten facetas o filtros.
- Tipos de consulta: consultas de búsqueda de texto completo que incluyen facetas, filtros, ordenación y perfiles de puntuación
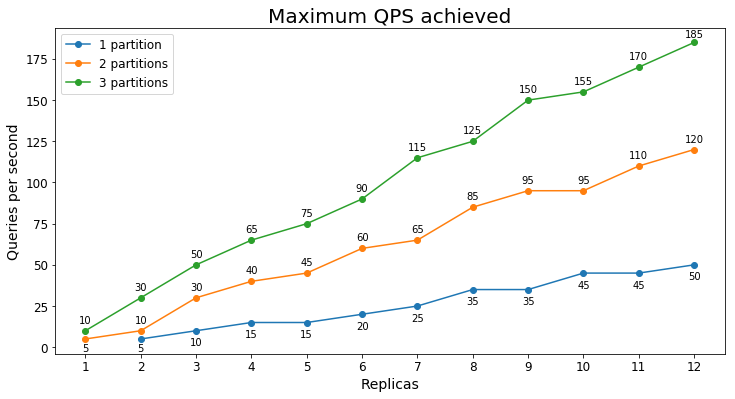
Rendimiento S1
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 104 ms | 35 ms | 115 ms | 177 ms | 257 ms | 738 ms |
| 50 % | 140 ms | 47 ms | 144 ms | 241 ms | 400 ms | 1175 ms |
| 80% | 239 ms | 77 ms | 248 ms | 466 ms | 763 ms | 1752 ms |
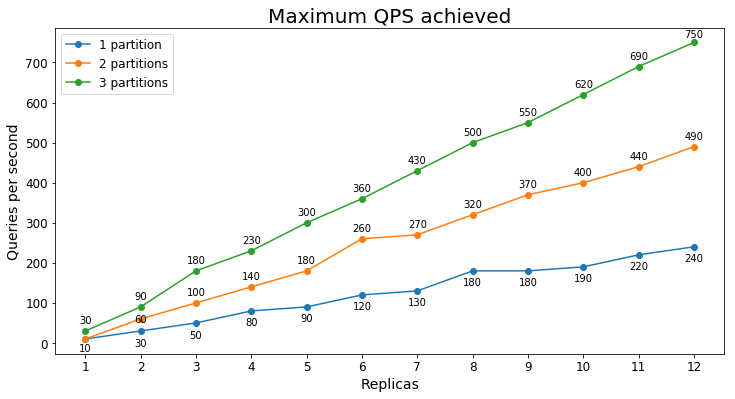
Rendimiento S2
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 56 ms | 21 ms | 68 ms | 106 ms | 132 ms | 210 ms |
| 50 % | 71 ms | 26 ms | 83 ms | 132 ms | 177 ms | 329 ms |
| 80% | 140 ms | 47 ms | 153 ms | 293 ms | 452 ms | 924 ms |
Rendimiento S3
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
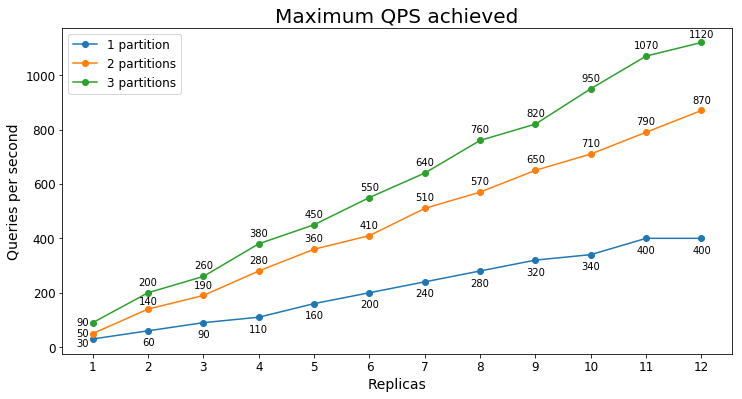
En este caso, vemos que agregar una segunda partición aumenta significativamente el número máximo de QPS, pero agregar una tercera partición disminuye los rendimientos marginales. Es probable que la mejora menor se deba a que todos los datos ya se están incorporando en la memoria activa del nivel S3 con solo dos particiones.
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 50 ms | 20 ms | 64 ms | 83 ms | 98 ms | 160 ms |
| 50 % | 62 ms | 24 ms | 80 ms | 107 ms | 130 ms | 253 ms |
| 80% | 115 ms | 38 ms | 121 ms | 218 ms | 352 ms | 828 ms |
Punto de referencia 2: búsqueda de documentos
Detalles del escenario
- Número de documentos: 7,5 millones
- Tamaño del índice: 22 GB
- Esquema de índice: 23 campos; 8 que permiten búsquedas, 10 que permiten facetas o filtros
- Tipos de consulta: búsquedas de palabras clave con facetas y resaltado de coincidencias
Rendimiento S1
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
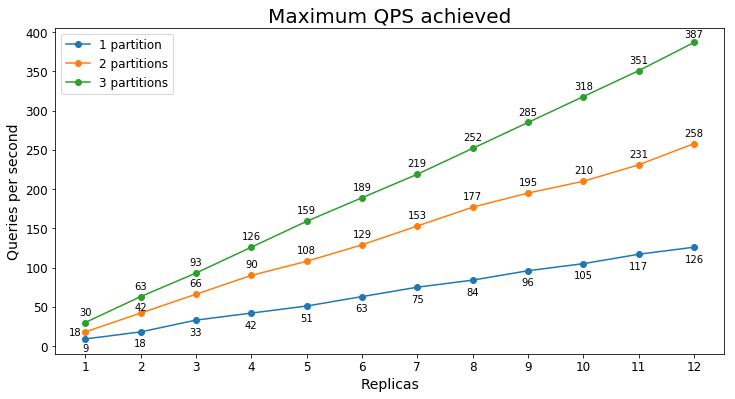
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 67 ms | 44 ms | 77 ms | 103 ms | 126 ms | 216 ms |
| 50 % | 93 ms | 59 ms | 110 ms | 150 ms | 184 ms | 304 ms |
| 80% | 150 ms | 96 ms | 184 ms | 248 ms | 297 ms | 424 ms |
Rendimiento S2
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
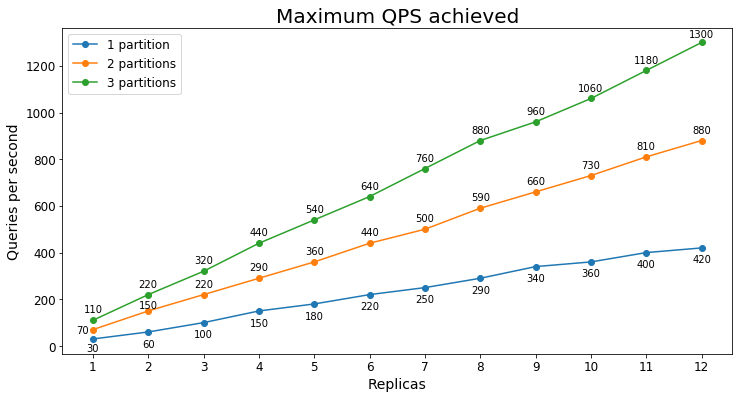
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 45 ms | 31 ms | 55 ms | 73 ms | 84 ms | 109 ms |
| 50 % | 63 ms | 39 ms | 81 ms | 106 ms | 123 ms | 163 ms |
| 80% | 115 ms | 73 ms | 145 ms | 191 ms | 224 ms | 291 ms |
Rendimiento S3
Consultas por segundo
En el siguiente gráfico se muestra la carga de consulta más alta que un servicio podría controlar durante un largo período de tiempo en términos de consultas por segundo (QPS).
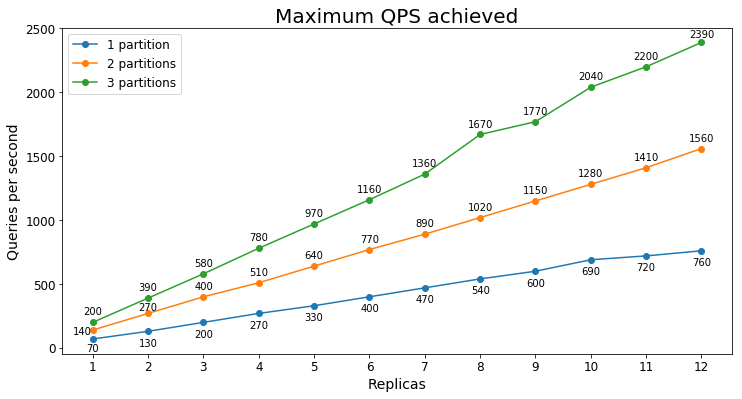
Latencia de consultas
La latencia de consulta varía en función de la carga del servicio y los servicios bajo un mayor estrés tienen una latencia de consulta media más alta. En la siguiente tabla se muestran los percentiles 25, 50, 75, 90, 95 y 99 de latencia de consulta para tres niveles de uso diferentes.
| Porcentaje de QPS máximo | Latencia media | 25 % | 75 % | 90 % | 95 % | 99% |
|---|---|---|---|---|---|---|
| 20 % | 43 ms | 29 ms | 53 ms | 74 ms | 86 ms | 111 ms |
| 50 % | 65 ms | 37 ms | 85 ms | 111 ms | 128 ms | 164 ms |
| 80% | 126 ms | 83 ms | 162 ms | 205 ms | 233 ms | 281 ms |
Puntos clave
A través de estos puntos de referencia, puede obtener una idea del rendimiento que ofrece Azure AI Search. También puede ver la diferencia entre los servicios en distintos niveles.
Algunas de las conclusiones principales de estos puntos de referencia son:
- Un nivel S2 normalmente puede controlar al menos cuatro veces el volumen de consultas de un nivel S1
- Normalmente, una S2 tiene una latencia menor que una S1 en volúmenes de consulta comparables
- A medida que agregue réplicas, el QPS que un servicio puede controlar normalmente escalará linealmente (por ejemplo, si una réplica puede controlar 10 QPS, cinco réplicas normalmente podrán controlar 50 QPS).
- Cuanto mayor sea la carga del servicio, mayor será la latencia media
También puede ver que el rendimiento podría variar drásticamente entre escenarios. Si no está logrando el rendimiento esperado, consulte las sugerencias para mejorar el rendimiento.
Pasos siguientes
Ahora que ha visto los puntos de referencia de rendimiento, puede obtener más información acerca de cómo analizar el rendimiento de Azure AI Search y los factores clave que influyen en el rendimiento.