Análisis del rendimiento en Azure AI Search
En este artículo se describen las herramientas, los comportamientos y los enfoques para analizar el rendimiento de las consultas y la indexación en Azure AI Search.
Desarrollo de números de línea de base
En cualquier implementación grande, es fundamental realizar una prueba de punto de referencia de rendimiento del servicio Azure AI Search antes de implementarlo en producción. Debe probar la carga de consulta de búsqueda que espera, pero también las cargas de trabajo de ingesta de datos esperadas (si es posible, ejecutar ambas cargas de trabajo al mismo tiempo). Tener números de punto de referencia ayuda a validar el nivel de búsqueda adecuado, la configuración del servicio y la latencia de consulta esperada.
Para desarrollar puntos de referencia, se recomienda la herramienta azure-search-performance-testing (GitHub).
Para aislar los efectos de una arquitectura de servicio distribuida, pruebe las configuraciones de servicio de una réplica y una partición.
Nota:
En el caso de los niveles de Almacenamiento optimizado (L1 y L2), debe esperar un rendimiento más bajo de las consultas y una latencia superior que en los niveles Estándar.
Uso de registro de recurso
La herramienta de diagnóstico más importante a la disposición de un administrador es el registro de recursos. El registro de recursos es la recopilación de datos operativos y métricas sobre el servicio de búsqueda. El registro de recurso se habilita a través de Azure Monitor. Hay costos asociados con el uso de Azure Monitor y el almacenamiento de datos, pero si lo habilita para el servicio, puede ser fundamental para investigar problemas de rendimiento.
En la siguiente imagen se muestra la cadena de eventos en una solicitud y respuesta de consulta. La latencia puede producirse en cualquiera de ellas, ya sea durante una transferencia de red, el procesamiento de contenido en el nivel de servicios de aplicaciones o en un servicio de búsqueda. Una ventaja clave del registro de recursos es que las actividades se registran desde la perspectiva del servicio de búsqueda, lo que significa que el registro puede ayudarle a determinar si el problema de rendimiento se debe a problemas con la consulta o la indexación, o algún otro punto de error.
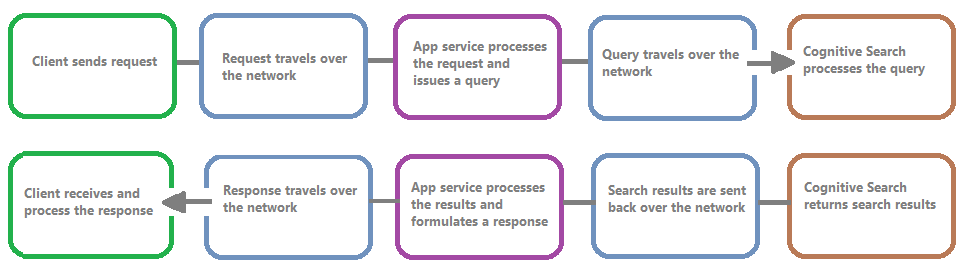
El registro de recursos proporciona opciones para almacenar información registrada. Se recomienda usar Log Analytics para que pueda ejecutar consultas avanzadas de Kusto en los datos para responder a muchas preguntas sobre el uso y el rendimiento.
En las páginas del portal del servicio de búsqueda, puede habilitar el registro a través de la configuración de diagnóstico y, a continuación, emitir consultas de Kusto en Log Analytics si elige Registro. Para saber cómo enviar registros de recursos a un área de trabajo de Log Analytics donde puede analizarlos con consultas de registro, consulte Recopilación y análisis de registros de recursos de un recurso Azure.
Comportamiento de limitación
La limitación se produce cuando el servicio de búsqueda está en capacidad. La limitación puede producirse durante las consultas o la indexación. Desde el lado cliente, una llamada API da como resultado una respuesta HTTP 503 cuando se ha limitado. Durante la indexación, también existe la posibilidad de recibir una respuesta HTTP 207, que indica que uno o varios elementos no se pudieron indexar. Este error es un indicador de que el servicio de búsqueda se acerca a su capacidad.
Como regla general, intente cuantificar la cantidad de limitación y cualquier patrón. Por ejemplo, si se limita una consulta de búsqueda de 500 000, es posible que no valga la pena investigar. Sin embargo, si un gran porcentaje de consultas se limita durante un período, esto sería un problema mayor. Al observar la limitación durante un período, también ayuda a identificar los períodos de tiempo en los que es más probable que se produzca y le ayudará a decidir cómo adaptarlo mejor.
Una solución sencilla a la mayoría de los problemas de limitación es iniciar más recursos en el servicio de búsqueda (normalmente réplicas para la limitación basada en consultas o particiones para la limitación basada en la indexación). Sin embargo, aumentar las réplicas o particiones agrega costos, por lo que es importante saber el motivo por el que se produce la limitación. La investigación de las condiciones que provocan la limitación se explicará en las siguientes secciones.
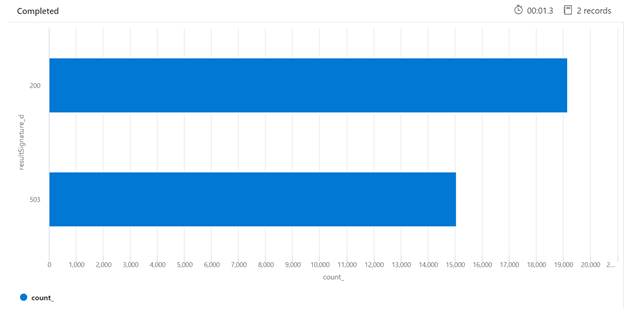
A continuación, se muestra un ejemplo de una consulta de Kusto que puede identificar el desglose de las respuestas HTTP del servicio de búsqueda que se ha cargado. Durante un período de 7 días, el gráfico de barras representado muestra que se ha limitado un porcentaje relativamente grande de las consultas de búsqueda, en comparación con el número de respuestas correctas (200).
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
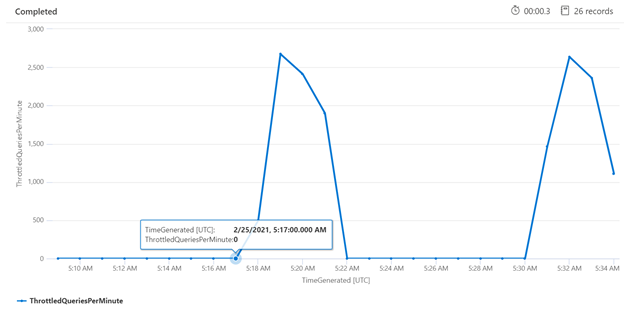
Examinar la limitación durante un período de tiempo específico puede ayudarle a identificar las horas en las que la limitación puede producirse con más frecuencia. En el ejemplo siguiente, se usa un gráfico de serie temporal para mostrar el número de consultas limitadas que se produjeron durante un período de tiempo especificado. En este caso, se realizaron las consultas limitadas correlacionadas con los tiempos de los puntos de referencia de rendimiento.
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Medición de consultas individuales
En algunos casos, puede ser útil probar consultas individuales para ver cómo funcionan. Para ello, es importante poder ver cuánto tiempo tarda el servicio de búsqueda en completar el trabajo, así como cuánto tiempo se tarda en realizar la solicitud de ida y vuelta desde el cliente y de vuelta a este. Los registros de diagnóstico se pueden usar para buscar operaciones individuales, pero puede ser más fácil hacerlo todo desde un cliente REST.
En el ejemplo siguiente, se ejecutó una consulta de búsqueda basada en REST. Azure AI Search incluye en cada respuesta el número de milisegundos que se tarda en completar la consulta, visible en la pestaña Encabezados, en "tiempo transcurrido". Junto a Estado en la parte superior de la respuesta, encontrará la duración del recorrido de ida y vuelta, en este caso, 418 milisegundos (ms). En la sección de resultados, se eligió la pestaña "Encabezados". Con estos dos valores resaltados con un cuadro rojo en la imagen siguiente, vemos que el servicio de búsqueda tardó 21 ms en completar la consulta de búsqueda y que toda la solicitud de ida y vuelta del cliente tardó 125 ms. Al restar estos dos números, podemos determinar que se tardó 104 ms más en transmitir la consulta de búsqueda al servicio de búsqueda y transferir los resultados de la búsqueda al cliente.
Esta técnica le ayuda a aislar las latencias de red de otros factores que afectan al rendimiento de las consultas.

Tasas de consulta
Una posible razón para que el servicio de búsqueda limite las solicitudes se debe al gran número de consultas que se realizan donde el volumen se captura como consultas por segundo (QPS) o consultas por minuto (QPM). A medida que el servicio de búsqueda recibe más QPS, normalmente tardará cada vez más tiempo en responder a esas consultas hasta que ya no pueda mantenerse al día, momento en el que enviará una respuesta HTTP 503 de limitación.
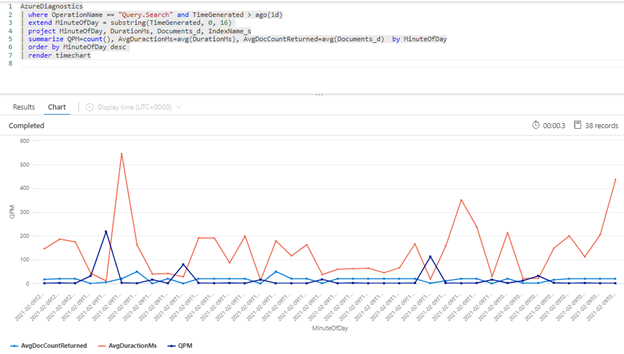
La siguiente consulta de Kusto muestra el volumen de consulta medido en QPM, junto con la duración media de una consulta en milisegundos (AvgDurationMS) y el número medio de documentos (AvgDocCountReturned) devueltos en cada uno de ellos.
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
Sugerencia
Para mostrar los datos que hay tras este gráfico, quite la línea | render timechart y vuelva a ejecutar la consulta.
Impacto de la indexación en las consultas
Un factor importante que se debe tener en cuenta al examinar el rendimiento es que la indexación usa los mismos recursos que las consultas de búsqueda. Si va a indexar una gran cantidad de contenido, puede esperar ver que la latencia aumenta a medida que el servicio intenta dar cabida a ambas cargas de trabajo.
Si las consultas se ralentizan, consulte el tiempo de la actividad de indexación para ver si coincide con la degradación de las consultas. Por ejemplo, quizás un indexador ejecuta un trabajo diario o cada hora que se correlaciona con el rendimiento reducido de las consultas de búsqueda.
En esta sección se proporciona un conjunto de consultas que pueden ayudarle a visualizar las tasas de búsqueda e indexación. En estos ejemplos, el intervalo de tiempo se establece en la consulta. Asegúrese de indicar Establecer en la consulta al ejecutar las consultas en Azure Portal.
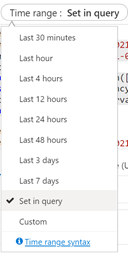
Latencia media de consulta
En la consulta siguiente, se usa un tamaño de intervalo de 1 minuto para mostrar la latencia media de las consultas de búsqueda. En el gráfico, podemos ver que la latencia media era baja hasta las 5:45 p. m. y duraba hasta las 5:53 p. m.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
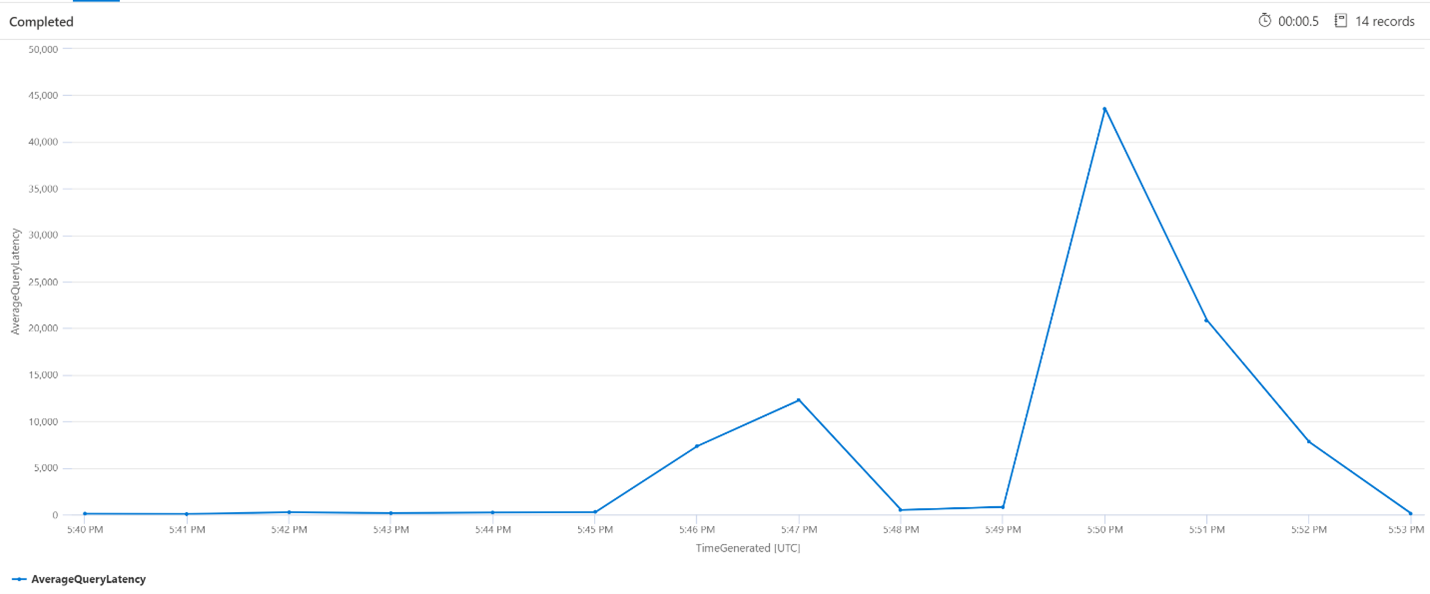
Media de consultas por minuto (QPM)
La consulta siguiente examina el número medio de consultas por minuto para asegurarse de que no había un pico en las solicitudes de búsqueda que podrían haber afectado a la latencia. En el gráfico podemos ver que hay alguna varianza, pero nada que indique un pico en el número de solicitudes.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
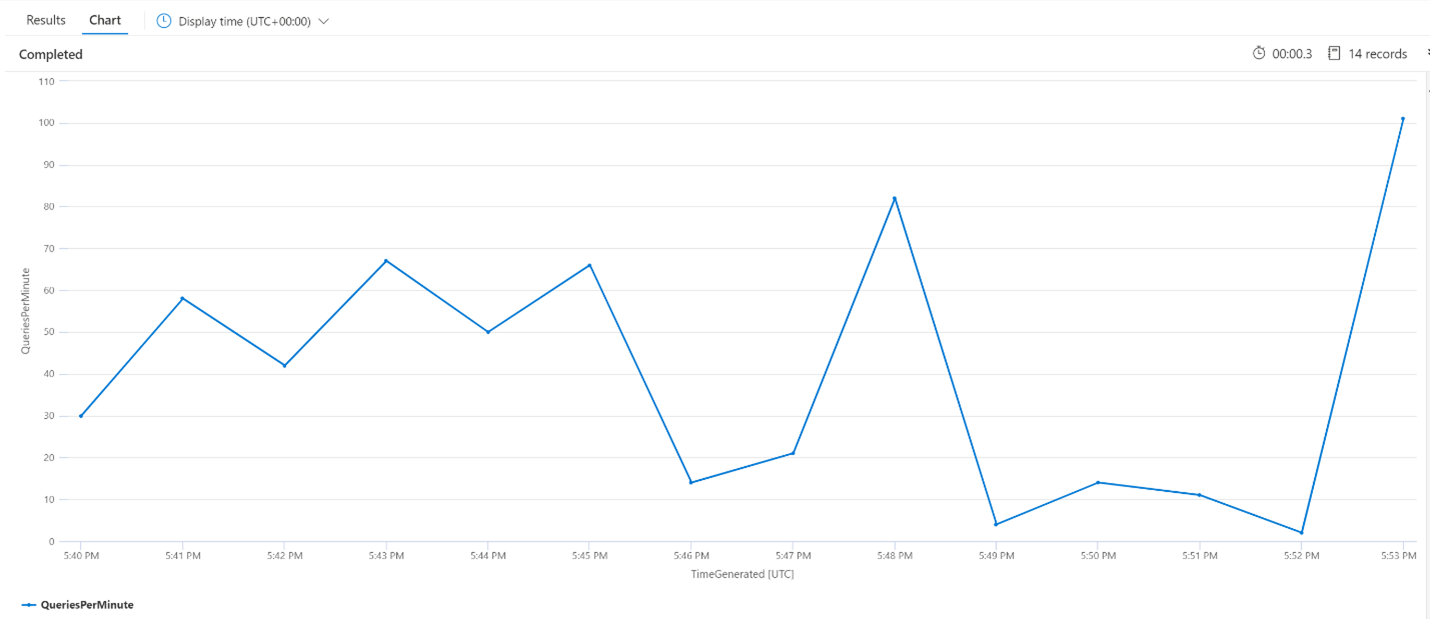
Operaciones de indexación por minuto (OPM)
A continuación, veremos el número de operaciones de indexación por minuto. En el gráfico, podemos ver que una gran cantidad de datos se indexó a las 5:42 p. m. y finalizó a las 5:50 p. m. Esta indexación comenzó 3 minutos antes de que las consultas de búsqueda empezaran a estar latentes y finalizaron 3 minutos antes de que ya no estuvieran latentes.
A partir de esta información, podemos ver que el servicio de búsqueda tardó unos 3 minutos en estar lo suficientemente ocupado como para que la indexación afecte a la latencia de las consultas. También podemos ver que después de completar la indexación, el servicio de búsqueda tardó otros 3 minutos en completar todo el trabajo del contenido recién indexado y para que la latencia de consulta se resuelva.
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
Procesamiento del servicio en segundo plano
No es raro ver picos periódicos en la latencia de consulta o indexación. Es posible que se produzcan picos en respuesta a la indexación o a tasas de consulta elevadas, pero también podrían producirse durante las operaciones Merge. Los índices de búsqueda se almacenan en fragmentos o particiones. Periódicamente, el sistema combina particiones más pequeñas en particiones grandes, lo que puede ayudar a optimizar el rendimiento del servicio. Este proceso de combinación también limpia los documentos que se han marcado previamente para su eliminación del índice, lo que da lugar a la recuperación del espacio de almacenamiento.
La combinación de particiones es rápida, pero también consume muchos recursos y, por tanto, tiene el potencial de degradar el rendimiento del servicio. Si observa ráfagas cortas de latencia de consulta y coinciden con los cambios recientes en el contenido indexado, puede suponer que la latencia se debe a operaciones de combinación de particiones.
Pasos siguientes
Revise estos artículos relacionados con el análisis del rendimiento del servicio.