Sugerencias para mejorar el rendimiento en Azure AI Search
Este artículo es una colección de sugerencias y procedimientos recomendados para aumentar el rendimiento de las consultas y la indexación para la búsqueda de palabras clave. Saber qué factores tienen más probabilidades de afectar al rendimiento de la búsqueda puede ayudarle a evitar ineficiencias y sacar el máximo partido del servicio de búsqueda. Entre los factores clave se incluyen los siguientes:
- Composición de índices (esquema y tamaño)
- Diseño de consultas
- Capacidad del servicio (nivel y número de réplicas y particiones)
Nota:
¿Busca estrategias en la indexación de gran volumen? Consulte Indexación de conjuntos de datos de gran tamaño en Azure AI Search.
Tamaño y esquema del índice
Las consultas se ejecutan más rápido en índices más pequeños. Esto es en parte una función al tener menos campos para examinar, pero también se debe a la forma en que el sistema almacena en caché el contenido de las consultas futuras. Después de la primera consulta, parte del contenido permanece en memoria, donde se busca de forma más eficaz. Dado que el tamaño del índice tiende a crecer con el tiempo, un procedimiento recomendado es revisar periódicamente la composición del índice, tanto el esquema como los documentos, para buscar oportunidades de reducción de contenido. Sin embargo, si el índice tiene el tamaño correcto, la única calibración que puede realizar es aumentar la capacidad: ya sea agregando réplicas o actualizando el nivel de servicio. En la sección "Sugerencia: actualización a un nivel Estándar S2" se describe la decisión de escalado vertical frente al escalado horizontal.
La complejidad del esquema también puede afectar negativamente a la indexación y al rendimiento de las consultas. La atribución excesiva de campos se basa en limitaciones y requisitos de procesamiento. Los tipos complejos tardan más tiempo en indexar y consultar. En las secciones siguientes se explora cada condición.
Sugerencia: selectividad en la atribución de campos
Un error común que los administradores y desarrolladores cometen al crear un índice de búsqueda es seleccionar todas las propiedades disponibles para los campos, en lugar de seleccionar solo las necesarias. Por ejemplo, si un campo no necesita poder realizar búsquedas de texto completo, omítalo al establecer el atributo que permite búsquedas.
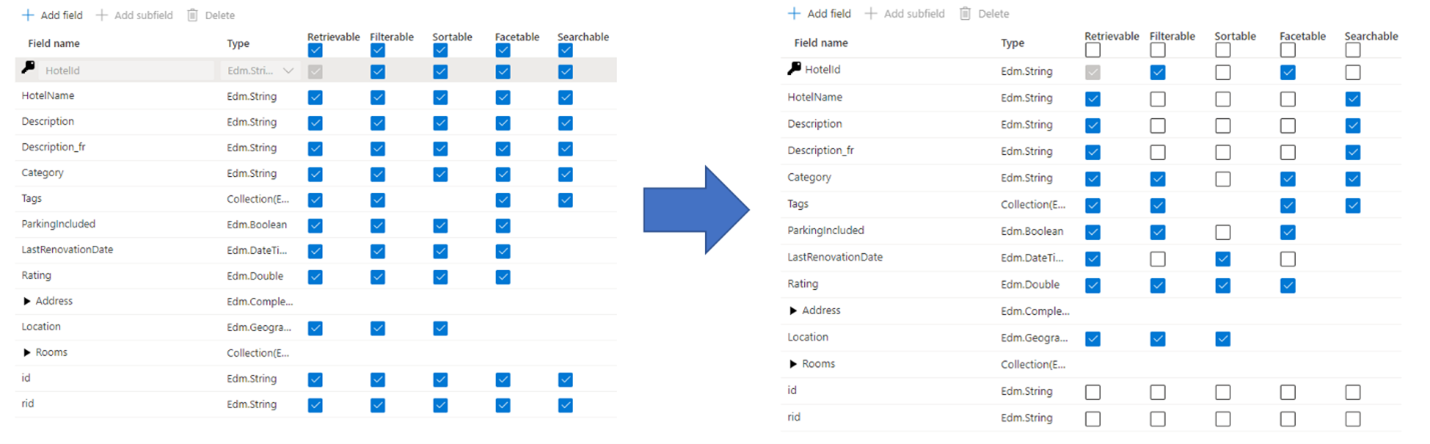
La compatibilidad con filtros, facetas y ordenación puede cuadruplicar los requisitos de almacenamiento. Si agrega sugerencias, los requisitos de almacenamiento aumentar aún más. Para obtener un ejemplo sobre el impacto de los atributos en el almacenamiento, vea Atributos y tamaño de índice.
En resumen, las ramificaciones de la sobreatribución incluyen lo siguiente:
Degradación del rendimiento de indexación debido al trabajo adicional necesario para procesar el contenido del campo y, a continuación, almacenarlo en el índice invertido de búsqueda (establezca el atributo "permite búsquedas" solo en campos que incluyan contenido que permite búsquedas).
Crea una superficie mayor que cada consulta tiene que cubrir. Todos los campos marcados como que permiten búsquedas se examinan en una búsqueda de texto completo.
Aumenta los costos operativos debido al almacenamiento adicional. El filtrado y la ordenación requieren espacio adicional para almacenar cadenas originales (no analizadas). Evite establecer filtros o elementos ordenables en campos que no lo necesiten.
En muchos casos, la sobreatribución limita las funcionalidades del campo. Por ejemplo, si un campo es calificable, filtrable y permite búsquedas, solo puede almacenar 16 KB de texto dentro de un campo, mientras que un campo que permite búsquedas puede contener hasta 16 MB de texto.
Nota:
Solo se debe evitar la atribución innecesaria. Los filtros y las facetas suelen ser esenciales para la experiencia de búsqueda y, en los casos en los que se usan filtros, con frecuencia la ordenación es necesaria para poder ordenar los resultados (los filtros por sí mismos devuelven en un conjunto desordenado).
Sugerencia: consideración de alternativas a los tipos complejos
Los tipos de datos complejos son útiles cuando los datos tienen una estructura anidada complicada, como los elementos primarios y secundarios que se encuentran en los documentos JSON. La desventaja de los tipos complejos son los requisitos de almacenamiento y los recursos adicionales necesarios para indexar el contenido, en comparación con los tipos de datos no complejos.
En algunos casos, puede evitar estos inconvenientes al asignar una estructura de datos compleja a un tipo de campo más sencillo, como una colección. Como alternativa, puede optar por aplanar una jerarquía de campos en campos de nivel de raíz individuales.

Diseño de consultas
La composición y complejidad de las consultas son uno de los factores más importantes para el rendimiento y la optimización de consultas puede mejorar drásticamente el rendimiento. Al diseñar consultas, piense en los siguientes puntos:
Número de campos que permiten búsquedas. Cada campo de búsqueda adicional genera más trabajo para el servicio de búsqueda. Puede limitar los campos que permiten búsquedas en el momento de la consulta mediante el parámetro "searchFields". Es mejor especificar solo los campos que le interesa para mejorar el rendimiento.
Cantidad de datos que se devuelven. La recuperación de una gran cantidad de contenido puede ralentizar las consultas. Al estructurar una consulta, devuelva solo los campos que necesita para representar la página de resultados y, a continuación, recupere los campos restantes mediante Lookup API una vez que un usuario seleccione una coincidencia.
Uso de búsquedas de términos parciales. Las búsquedas de términos parciales, como la búsqueda de prefijos, la búsqueda aproximada y la búsqueda de expresiones regulares, son más costosas desde el punto de vista computacional que las búsquedas de palabras clave típicas, ya que requieren exámenes de índice completos para generar resultados.
Número de facetas. Agregar facetas a las consultas requiere agregaciones para cada consulta. La solicitud de un "recuento" superior para una faceta también requiere trabajo adicional por parte del servicio. En general, agregue solo las facetas que piensa representar en la aplicación y evite solicitar un recuento alto de facetas a menos que sea necesario.
Valores de omisión altos. El establecimiento del parámetro
$skipen un valor alto (por ejemplo, en miles) aumenta la latencia de búsqueda porque el motor recupera y clasifica un volumen mayor de documentos para cada solicitud. Por motivos de rendimiento, es mejor evitar los valores$skipaltos y usar otras técnicas en su lugar, como el filtrado, para recuperar un gran número de documentos.Limitar los campos de alta cardinalidad. Un campo de alta cardinalidad hace referencia a un campo clasificable o filtrable que tiene un número significativo de valores únicos y, como resultado, consume recursos importantes al procesar los resultados. Por ejemplo, el establecimiento de un campo de identificador de producto o de descripción como filtrable y clasificable contaría como alta cardinalidad ya que la mayoría de los valores de un documento a otro son únicos.
Sugerencia: uso de funciones de búsqueda en lugar de sobrecargar los criterios de filtro
A medida que una consulta usa criterios de filtro cada vez más complejos, el rendimiento de la consulta de búsqueda se degrada. Considere el ejemplo siguiente que muestra el uso de filtros para recortar los resultados en función de una identidad de usuario:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
En este caso, las expresiones de filtro se usan para comprobar si un solo campo de cada documento es igual a uno de los muchos valores posibles de una identidad de usuario. Es más probable encontrar este patrón en aplicaciones que implementan el recorte de seguridad (mediante la comparación de un campo que contiene uno o varios identificadores de entidad de seguridad y una lista de identificadores de entidad de seguridad que representa al usuario que emite la consulta).
Una manera más eficaz de ejecutar filtros que contienen un gran número de valores es usar la función search.in, como se muestra en este ejemplo:
search.in(userid, '123,234,345,456,567', ',')
Sugerencia: adición de particiones para consultas individuales lentas
Cuando el rendimiento de las consultas se ralentiza en general, la adición de más réplicas suele solucionar el problema. Pero, ¿qué ocurre si el problema es una sola consulta que tarda demasiado tiempo en completarse? En este escenario, agregar réplicas no ayudará, pero es posible que las particiones adicionales sirvan de ayuda. Una partición divide los datos entre recursos informáticos adicionales. Dos particiones dividen los datos por la mitad, una tercera partición los divide en tercios, etc.
Un efecto secundario positivo de la adición de particiones es que las consultas más lentas a veces se ejecutan más rápido debido a la computación en paralelo. Se observó la paralelización de consultas de selectividad baja, como las consultas que coinciden con muchos documentos, o facetas que proporcionan recuentos a través de un gran número de documentos. Como se necesita una gran cantidad de cálculo para puntuar la relevancia de los documentos o para contar el número de documentos, agregar particiones adicionales ayuda a que las consultas se completen más rápido.
Para agregar particiones, use Azure Portal, PowerShell, la CLI de Azure o un SDK de administración.
Capacidad del servicio
Un servicio se sobrecarga cuando las consultas tardan demasiado tiempo o cuando el servicio empieza a eliminar solicitudes. Si esto sucede, puede solucionar el problema actualizando el servicio o agregando capacidad.
El nivel del servicio de búsqueda y el número de réplicas o particiones también tienen un gran impacto en el rendimiento. Cada nivel progresivamente superior proporciona CPU más rápidas y más memoria, aspectos que tienen un impacto positivo en el rendimiento.
Sugerencia: crear un nuevo servicio de búsqueda de alta capacidad
Los servicios básicos y estándar creados [en regiones admitidas](regiones admitidas después del 3 de abril de 2024 tienen más almacenamiento por partición que los servicios anteriores. Antes de actualizar a un nivel superior y una tasa facturable superior, vuelva a consultar los límites de servicio de nivel para ver si el mismo nivel en un servicio más reciente proporciona el almacenamiento necesario.
Sugerencia: actualización a un nivel Estándar S2
A menudo, el nivel de búsqueda Estándar S1 es donde comienzan los clientes. Un patrón común para los servicios S1 es que los índices crecen con el tiempo, lo que requiere más particiones. El aumento de particiones provoca tiempos de respuesta más lentos, por lo que se agregan más réplicas para controlar la carga de consultas. Como puede imaginar, el costo de ejecutar un servicio S1 ha progresado a niveles más allá de la configuración inicial.
En este momento, una pregunta importante que se debe realizar es si sería beneficioso pasar a un nivel superior, en lugar de aumentar progresivamente el número de particiones o réplicas del servicio actual.
Considere la topología siguiente como ejemplo de un servicio que ha ido aumentando los niveles de capacidad:
- Nivel Estándar S1
- Tamaño del índice: 190 GB
- Recuento de particiones: 8 (en S1, el tamaño de partición es de 25 GB por partición)
- Recuento de réplicas: 2
- Total de unidades de búsqueda: 16 (8 particiones x 2 réplicas)
- Precio de venta al por menor hipotético: ~4000 USD/mes (suponga 250 USD x 16 unidades de búsqueda)
Supongamos que el administrador de servicios sigue viendo mayores tasas de latencia y está considerando agregar otra réplica. Esto cambiaría el recuento de réplicas de 2 a 3 y, como resultado, cambiaría el recuento de unidades de búsqueda a 24 y un precio resultante de 6000 USD/mes.
Sin embargo, si el administrador decide pasar a un nivel Estándar S2, la topología tendría el siguiente aspecto:
- Nivel Estándar S2
- Tamaño del índice: 190 GB
- Recuento de particiones: 2 (en S2, el tamaño de partición es de 100 GB por partición)
- Recuento de réplicas: 2
- Total de unidades de búsqueda: 4 (2 particiones x 2 réplicas)
- Precio de venta al por menor hipotético: ~4000 USD/mes (1,000 USD x 4 unidades de búsqueda)
Como se muestra en este escenario hipotético, puede tener configuraciones en niveles inferiores que resulten en costos similares como si hubiera optado por un nivel superior en primer lugar. Sin embargo, los niveles superiores incluyen Premium Storage, lo que hace que la indexación sea más rápida. Los niveles superiores también tienen mucha más potencia de proceso, así como memoria adicional. Para los mismos costos, podría tener una infraestructura más eficaz que haga una copia de seguridad del mismo índice.
Una ventaja importante de la memoria agregada es que la mayor parte del índice se puede almacenar en caché, lo que da lugar a una menor latencia de búsqueda y un mayor número de consultas por segundo. Con esta capacidad adicional, es posible que el administrador no tenga que aumentar el número de réplicas y podría pagar menos que si se quedara en el servicio S1.
Sugerencia: Considerar alternativas a las consultas de expresiones regulares
Las consultas de expresiones regulares o (regex) pueden ser muy costosas. Aunque pueden ser muy útiles para las búsquedas avanzadas, la ejecución puede requerir una gran potencia de procesamiento, especialmente si la expresión regular es complicada o si busca una gran cantidad de datos. Todos estos factores contribuyen a una alta latencia de búsqueda. Como mitigación, intente simplificar la expresión regular o dividir la consulta compleja en consultas más pequeñas y manejables.
Pasos siguientes
Revise estos artículos adicionales relacionados con el análisis del rendimiento del servicio.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de