Estimación y administración de la capacidad de un servicio de búsqueda
En Azure AI Search, la capacidad se basa en réplicas y particiones que se pueden escalar a la carga de trabajo. Las réplicas son copias del motor de búsqueda. Las particiones son unidades de almacenamiento. Cada nuevo servicio de búsqueda comienza con una de cada, pero puede agregar o quitar réplicas y particiones de forma independiente para dar cabida a cargas de trabajo fluctuantes. La incorporación de capacidad aumenta el costo de ejecutar un servicio de búsqueda.
Las características físicas de las réplicas y las particiones, como la velocidad de procesamiento y la E/S de disco, varían según el nivel de servicio. En un servicio de búsqueda estándar, las réplicas y las particiones son más rápidas y de mayor tamaño que las de un servicio básico.
El cambio de capacidad no es instantáneo. Las particiones pueden tardar hasta una hora en aprovisionarse o retirarse, especialmente en servicios con grandes cantidades de datos.
Al escalar un servicio de búsqueda, puede elegir entre las siguientes herramientas y enfoques:
Nota:
Las particiones de mayor capacidad están disponibles con la misma tarifa de facturación en los servicios más recientes creados después de abril y mayo de 2024. Para más información, consulte Límites de servicio para las actualizaciones de tamaño de partición.
Conceptos: unidades de búsqueda, réplicas, particiones
La capacidad se expresa en unidades de búsqueda que se pueden asignar en combinaciones de particiones y réplicas.
| Concepto | Definición |
|---|---|
| Unidad de búsqueda | Un único incremento de la capacidad total disponible (36 unidades). Se requiere un mínimo de una unidad para ejecutar el servicio. El primer par de réplica y partición es la primera unidad de búsqueda. Sin embargo, cada instancia adicional de una réplica o partición consume una unidad de búsqueda adicional. Por ejemplo, si empieza con una réplica y partición (una unidad de búsqueda) y agrega una segunda réplica, ahora consume dos unidades de búsqueda. Una unidad de búsqueda también es la unidad de facturación de un servicio de Búsqueda de Azure AI. |
| Réplica | Instancias del servicio de búsqueda, que se utilizan principalmente para equilibrar la carga de las operaciones de consulta. Cada réplica hospeda una copia de un índice. Si asigna tres réplicas, tendrá tres copias de un índice disponibles para atender las solicitudes de consulta. |
| Partición | Almacenamiento físico y E/S para operaciones de lectura y escritura (por ejemplo, al volver a compilar o actualizar un índice). Cada partición tiene un segmento del índice total. Si asigna tres particiones, el índice se divide en tercios. |
Revise la tabla de particiones y réplicas para ver las posibles combinaciones que permanecen por debajo del límite de 36 unidades.
Cuándo ampliar la capacidad
Inicialmente, se asigna un servicio a un nivel mínimo de recursos que consta de una partición y una réplica. El plan que elija determina el tamaño y la velocidad de la partición y cada plan se optimiza alrededor de un conjunto de características que se adapta a varios escenarios. Si elige un plan de gama superior, puede que necesite menos particiones que si elige S1. Una de las preguntas que tendrá que responder mediante pruebas autodirigidas es si una partición más grande y más cara aumentará más el rendimiento que dos particiones más baratas en un servicio aprovisionado con un plan inferior.
Un único servicio debe tener recursos suficientes para controlar todas las cargas de trabajo (indexación y consultas). Ninguna carga de trabajo se ejecuta en segundo plano. Puede programar la indexación en horas en las que las solicitudes de consulta son menos frecuentes por naturaleza, pero el servicio no dará prioridad a una tarea sobre otra. Además, una determinada cantidad de redundancia suaviza el rendimiento de la consulta cuando los servicios o nodos se están actualizando internamente.
Algunas directrices para determinar si se debe ampliar la capacidad incluyen:
- Cumplimiento de los criterios de alta disponibilidad para el Acuerdo de Nivel de Servicio
- La frecuencia de los errores HTTP 503 va en aumento
- Se esperan grandes volúmenes de consultas
Como norma general, las aplicaciones de búsqueda tienden a necesitar más réplicas que particiones, sobre todo cuando las operaciones de servicio están orientadas a las cargas de trabajo de consulta. Cada réplica es una copia del índice, lo que permite que el servicio equilibre la carga de las solicitudes en varias copias. Azure AI Search administra todo el equilibrio de carga y la replicación de un índice, y puede modificar el número de réplicas asignado a su servicio en cualquier momento. Puede asignar hasta 12 réplicas en un servicio de búsqueda estándar y 3 réplicas en un servicio de búsqueda básico. La asignación de réplicas se puede realizar desde Azure Portal o una de las opciones de programación.
Las particiones adicionales son útiles para cargas de trabajo de indexación intensivas. Las particiones adicionales reparten las operaciones de lectura/escritura entre un mayor número de recursos informáticos.
Por último, las consultas en índices de mayor tamaño tardan más tiempo en realizarse. Por lo tanto, es posible que con cada aumento incremental de las particiones sea necesario también un aumento menor, pero proporcional, de las réplicas. La complejidad y el volumen de las consultas afectarán a la rapidez con que se ejecuta la consulta.
Nota:
La adición de más réplicas o particiones aumenta el costo de ejecución del servicio y puede generar pequeñas variaciones en cómo se ordenan los resultados. Asegúrese de activar la calculadora de precios para comprender las implicaciones que tiene en la facturación el agregar más nodos. El gráfico siguiente puede ayudarle a establecer una referencia cruzada con el número de unidades de búsqueda necesarias para una configuración específica. Para obtener más información sobre cómo las réplicas adicionales afectan al procesamiento de las consultas, visite Organización de los resultados.
Como cambiar la capacidad
Para aumentar o disminuir la capacidad del servicio de búsqueda, agregue o quite particiones y réplicas.
Inicie sesión en Azure Portal y seleccione su servicio de búsqueda.
En Configuración, abra la página Escala para modificar réplicas y particiones.
En la siguiente captura de pantalla se muestra un servicio estándar aprovisionado con una réplica y una partición. La fórmula de la parte inferior indica cuántas unidades de búsqueda se usan (1). Si el precio por unidad era de 100 USD (no un precio real), el costo de ejecución de este servicio sería, de media, de 100 USD.
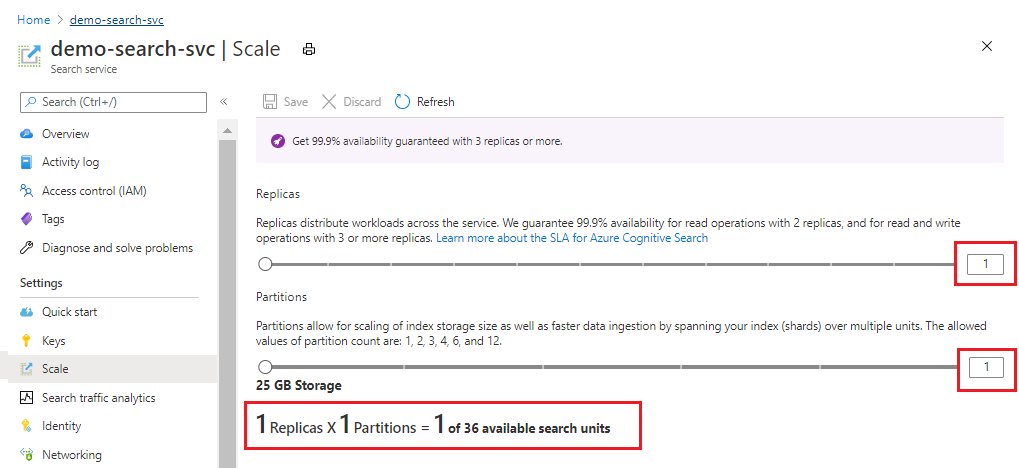
Use el control deslizante para aumentar o reducir el número de particiones. Seleccione Guardar.
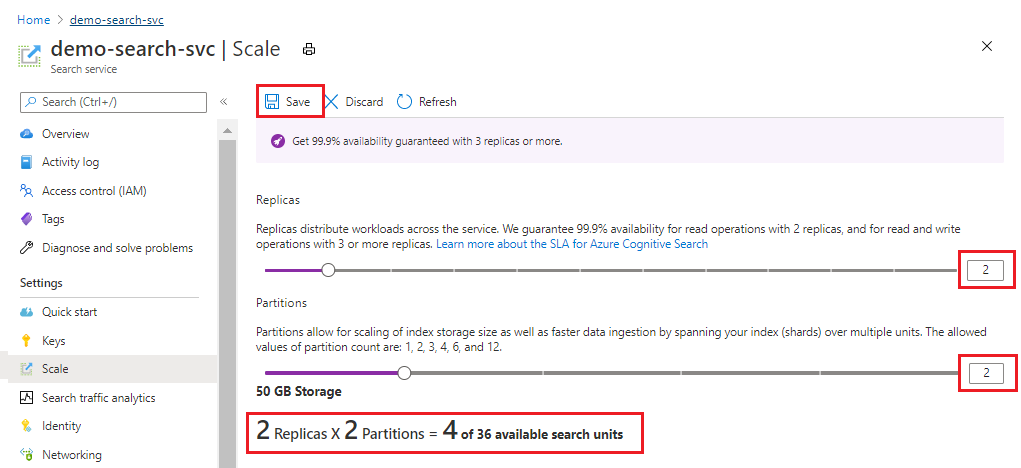
En este ejemplo se agrega una segunda réplica y también otra partición. Observe el recuento de unidades de búsqueda; ahora es cuatro porque la fórmula de facturación son las réplicas multiplicadas por las particiones (2 x 2). Cuanto más se duplica la capacidad, más se duplica el costo de ejecución del servicio. Si el costo de la unidad de búsqueda era de 100 USD, la nueva factura mensual sería ahora de 400 USD.
Para ver los costos por unidad actuales de cada nivel, visite la Página de precios.
Después de guardar, puede comprobar las notificaciones para confirmar que la acción se ha realizado correctamente.
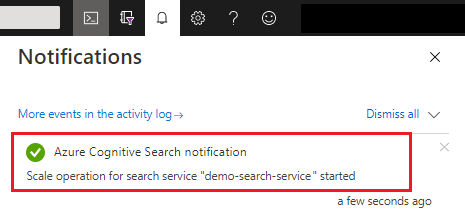
Los cambios en la capacidad pueden tardar entre 15 minutos y varias horas en completarse. No se puede cancelar una vez que se ha iniciado el proceso y no hay ningún tipo de supervisión en tiempo real de los ajustes de réplica y partición. Sin embargo, el siguiente mensaje se puede seguir viendo mientras se están realizando los cambios.

Nota:
Una vez que se aprovisiona un servicio, no se puede actualizar a un plan superior. Debe crear un servicio de búsqueda en el nivel nuevo y volver a cargar los índices. Consulte Creación de un servicio Azure AI Search mediante Azure Portal para obtener ayuda con el proceso de aprovisionamiento de servicios.
Control de las solicitudes de escalado
Tras la recepción de una solicitud de escalado, el servicio de búsqueda:
- Comprueba si la solicitud es válida.
- Inicia la copia de seguridad de los datos y la información del sistema.
- Comprueba si el servicio ya está en estado de aprovisionamiento (agregando o eliminando actualmente réplicas o particiones).
- Inicia el aprovisionamiento.
El escalado de un servicio puede tardar tan solo 15 minutos o más de una hora, según el tamaño del servicio y el ámbito de la solicitud. La copia de seguridad puede tardar varios minutos, en función de la cantidad de datos y el número de particiones y réplicas.
Los pasos anteriores no son completamente consecutivos. Por ejemplo, el sistema inicia el aprovisionamiento cuando puede hacerlo de forma segura, que podría ser mientras se está completando la copia de seguridad.
Errores durante el escalado
El mensaje de error "No se permiten operaciones de actualización del servicio en este momento porque estamos procesando una solicitud anterior" se debe a la repetición de una solicitud para escalar o reducir verticalmente cuando el servicio ya está procesando una solicitud anterior.
Para resolver este error, compruebe el estado del servicio para comprobar el estado de aprovisionamiento:
- Use la API REST de administración, Azure PowerShell o la CLI de Azure para obtener el estado del servicio.
- Llame al servicio Get (REST) o equivalente para PowerShell o la CLI.
- Compruebe en la respuesta que el valor de "provisioningState" sea "provisioning" (Aprovisionamiento).
Si el estado es "Aprovisionando", espere a que se complete la solicitud. El estado debe ser "Succeeded" (Correcto) o "Failed" (Con errores) antes de intentar otra solicitud. No hay estado para la copia de seguridad. La copia de seguridad es una operación interna y es poco probable que sea un factor en cualquier interrupción de un ejercicio de escalado.
Si el servicio de búsqueda parece estar detenido en un estado de aprovisionamiento, compruebe si hay índices huérfanos que no se pueden usar, sin volúmenes de consulta ni actualizaciones de índices. Un índice inutilizable puede bloquear los cambios en la capacidad del servicio. En concreto, busque índices cifrados por CMK, cuyas claves ya no son válidas. Debe eliminar el índice o restaurar las claves para volver a ponerlo en línea y desbloquear la operación de escalado.
Combinaciones de particiones y réplicas
El gráfico siguiente se aplica al nivel Estándar y superior. Muestra todas las combinaciones posibles de particiones y réplicas, sujeto al máximo de 36 unidades de búsqueda por servicio.
| 1 partición | 2 particiones | 3 particiones | 4 particiones | 6 particiones | 12 particiones | |
|---|---|---|---|---|---|---|
| 1 réplica | 1 unidad de búsqueda | 2 unidades de búsqueda | 3 unidades de búsqueda | 4 unidades de búsqueda | 6 unidades de búsqueda | 12 unidades de búsqueda |
| 2 réplicas | 2 unidades de búsqueda | 4 unidades de búsqueda | 6 unidades de búsqueda | 8 unidades de búsqueda | 12 unidades de búsqueda | 24 unidades de búsqueda |
| 3 réplicas | 3 unidades de búsqueda | 6 unidades de búsqueda | 9 unidades de búsqueda | 12 unidades de búsqueda | 18 unidades de búsqueda | 36 unidades de búsqueda |
| 4 réplicas | 4 unidades de búsqueda | 8 unidades de búsqueda | 12 unidades de búsqueda | 16 unidades de búsqueda | 24 unidades de búsqueda | N/D |
| 5 réplicas | 5 unidades de búsqueda | 10 unidades de búsqueda | 15 unidades de búsqueda | 20 unidades de búsqueda | 30 unidades de búsqueda | N/D |
| 6 réplicas | 6 unidades de búsqueda | 12 unidades de búsqueda | 18 unidades de búsqueda | 24 unidades de búsqueda | 36 unidades de búsqueda | N/D |
| 12 réplicas | 12 unidades de búsqueda | 24 unidades de búsqueda | 36 unidades de búsqueda | N/D | N/D | N/D |
Los servicios de búsqueda básicos tienen menores recuentos de unidades de búsqueda.
En los servicios de búsqueda creados antes del 3 de abril de 2024, un servicio de búsqueda básico puede tener exactamente una partición y hasta tres réplicas, para un límite máximo de tres SU. El único recurso que puede ajustarse son las réplicas.
En los servicios de búsqueda creados después del 3 de abril de 2024 en las regiones admitidas, los servicios básicos pueden tener hasta tres particiones y tres réplicas. El límite máximo de SU es nueve para admitir un complemento completo de particiones y réplicas.
Para los servicios de búsqueda en cualquier nivel facturable, independientemente de la fecha de creación, necesita un mínimo de dos réplicas para alta disponibilidad en las consultas.
Para conocer las tarifas de facturación por nivel y moneda, consulte la página de precios de Azure AI Search.
Estimación de la capacidad con un nivel facturable
Las necesidades de almacenamiento vienen determinadas por el tamaño de los índices que espera compilar. No hay ninguna heurística o generalización sólida que ayude con las estimaciones. La única manera de determinar el tamaño de un índice es compilar uno. Su tamaño se basa en la tokenización y las inserciones, y si habilita sugerencias, filtrado y ordenación, o puede aprovechar la compresión de vectores.
Se recomienda calcular en un nivel facturable, Básico o superior. El nivel Gratis se ejecuta en recursos físicos compartidos por varios clientes y está sujeto a factores más allá del control. Sólo los recursos dedicados de un servicio de búsqueda facturable pueden acomodar mayores tiempos de muestreo y procesamiento para estimaciones más realistas de la cantidad, el tamaño y los volúmenes de consulta del índice durante el desarrollo.
Revise los límites del servicio en cada nivel para determinar si los niveles más bajos pueden admitir la cantidad de índices que necesita. Considere si necesita varias copias de un índice para el desarrollo, las pruebas y la producción activos.
Un servicio de búsqueda está sujeto a límites de objetos (número máximo de índices, indexadores, conjuntos de aptitudes, etc.) y límites de almacenamiento. El límite que se alcance primero es el vigente.
Cree un servicio en un nivel facturable. Los niveles están optimizados para determinadas cargas de trabajo. Por ejemplo, el nivel de almacenamiento optimizado tiene un límite de 10 índices porque está diseñado para soportar un número reducido de índices muy grandes.
Comience por abajo, en Básico o S1, si no está seguro de la carga proyectada.
Comience alto, en S2 o incluso S3, si las pruebas incluyen indexación a gran escala y cargas de consulta.
Empiece con Almacenamiento optimizado, en L1 o L2, si va a indexar una gran cantidad de datos y la carga de consultas es relativamente baja, como con una aplicación empresarial interna.
Genere un índice inicial para determinar cómo se traducen los datos de origen a un índice. Esta es la única manera de calcular el tamaño del índice. Los atributos de las definiciones de campo afectan a los requisitos de almacenamiento físico:
Para la búsqueda de palabras clave, marcar campos como filtrables y ordenables aumenta el tamaño del índice.
Para la búsqueda de vectores, puede establecer parámetros para reducir el almacenamiento.
Supervise el almacenamiento, los límites del servicio, el volumen de consultas y la latencia en el portal. El portal muestra las consultas por segundo, las consultas limitadas y la latencia de búsqueda. Todos estos valores pueden ayudarle a decidir si ha seleccionado el nivel correcto.
Agregue réplicas para lograr una alta disponibilidad o para mitigar el rendimiento lento de las consultas.
No hay instrucciones sobre cuántas réplicas se necesitan para acomodar las cargas de consulta. El rendimiento de consulta depende de la complejidad de la consulta y de las cargas de trabajo competitivas. Si bien la adición de réplicas genera claramente un mejor rendimiento, el resultado final no será estrictamente lineal: la adición de tres réplicas no garantiza el triple rendimiento. Para obtener una guía sobre cómo estimar las QPS de la solución, consulte Análisis del rendimiento y Supervisión de consultas.
Para un índice invertido, el tamaño y la complejidad vienen determinados por el contenido, y no necesariamente por la cantidad de datos que se incorporan. Un origen de datos de gran tamaño con mucha redundancia podría dar lugar a un índice más pequeño que un conjunto de datos más pequeño que incluya contenido muy variable. Así que es poco probable deducir el tamaño del índice en función del tamaño del conjunto de datos original.
Los requisitos de almacenamiento pueden parecer excesivos si incluye datos que nunca se buscarán. Lo ideal es que los documentos contengan solo los datos que necesita para la experiencia de búsqueda.
Consideraciones sobre el contrato de nivel de servicio
El nivel Gratis y las características en vista previa no están cubiertos por Acuerdos de Nivel de Servicio (SLA). Para todos los niveles facturables, los SLA tomarán efecto cuando se aprovisione suficiente redundancia para el servicio.
Dos o más réplicas satisfacen los Acuerdos de Nivel de Servicio de consulta (lectura).
Tres o más réplicas satisfacen los acuerdos de nivel de servicio de consulta e indexación (lectura y escritura).
El número de particiones no afecta a los SLA.