Nota
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Importante
Esta característica se encuentra en versión preliminar.
Fabric Runtime ofrece una integración perfecta en el ecosistema de Microsoft Fabric, que ofrece un entorno sólido para proyectos de ingeniería de datos y ciencia de datos con tecnología de Apache Spark.
En este artículo se presenta La versión preliminar pública de Fabric Runtime 2.0, el entorno de ejecución más reciente diseñado para cálculos de macrodatos en Microsoft Fabric. Resalta las características y componentes clave que hacen de esta versión un paso importante para el análisis escalable y las cargas de trabajo avanzadas.
Fabric Runtime 2.0 incorpora los siguientes componentes y actualizaciones diseñados para mejorar las funcionalidades de procesamiento de datos:
- Apache Spark 4.1
- Sistema operativo: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta Lake: 4,2
- R: 4.5.2
Importante
El equipo de Microsoft Fabric está lanzando una actualización para Microsoft Fabric Runtime 2.0. Como parte de esta actualización, la actualización de Python introduce un cambio radical para los clientes que utilizan artefactos de Entorno con bibliotecas de python y ruedas. Los clientes ven uno de los dos mensajes de error con la ejecución de Notebook o Spark Job Definition (SJD):
- Error: advertencia: 1 obsolescencia (desde la versión 2.13.0); para más detalles, activa
:setting -deprecationo:replay -deprecation. Fuente: SparkCoreService. - "LibraryManagementError": "Se ha detectado una actualización al entorno base de Spark Python. Por favor, vuelva a publicar el entorno.|Error de usuario
Acciones necesarias
Vuelve a publicar tu entorno (incluidas las bibliotecas). Para ello, elimina todas las librerías, publica el Entorno, vuelve a añadir todas las bibliotecas y vuelve a publicar. Este proceso recrea el entorno utilizando el runtime actualizado en Python y resuelve el problema.
Sugerencia
Fabric Runtime 2.0 incluye compatibilidad con el motor de ejecución nativo, lo que puede mejorar significativamente el rendimiento sin más costos. Puede habilitar el motor de ejecución nativo en el nivel de entorno para que todos los trabajos y cuadernos hereden automáticamente las funcionalidades de rendimiento mejoradas.
Habilitación del entorno de ejecución 2.0
Puede habilitar Runtime 2.0 en el nivel de área de trabajo o en el nivel de elemento de entorno. Use la configuración del área de trabajo para aplicar Runtime 2.0 como valor predeterminado para todas las cargas de trabajo de Spark del área de trabajo. Como alternativa, cree un elemento de entorno con Runtime 2.0 para usarlo con cuadernos específicos o definiciones de trabajo de Spark, que invalida el valor predeterminado del área de trabajo.
Habilitación del entorno de ejecución 2.0 en la configuración del área de trabajo
Para establecer Runtime 2.0 como valor predeterminado para todo el área de trabajo:
Vaya a la página Configuración del área de trabajo dentro del área de trabajo de Fabric.
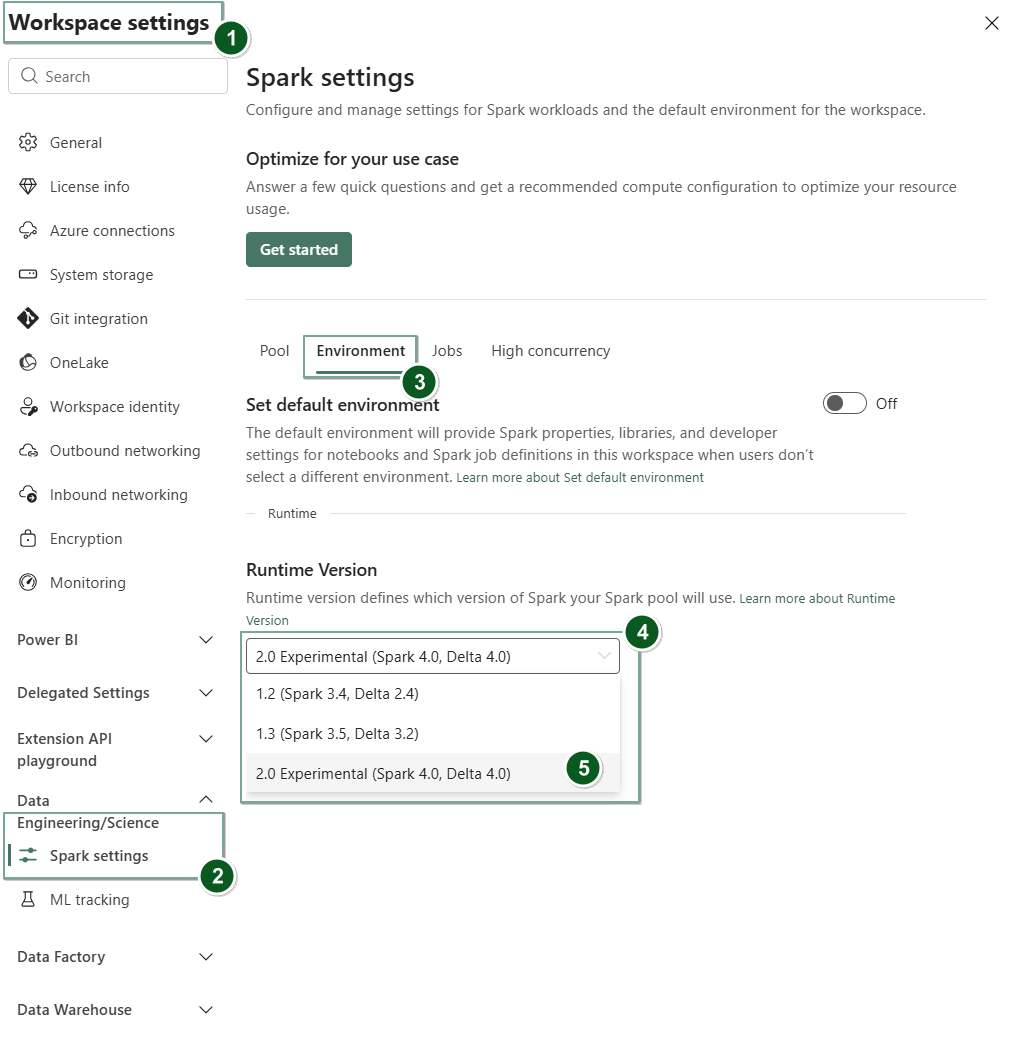
Seleccione la pestaña Ingeniería de datos/Ciencia y, a continuación, seleccione Configuración de Spark.
Seleccione la pestaña Entorno.
En el desplegable de la versión de Runtime , selecciona Vista previa pública 2.0 (Spark 4.1, Delta 4.2) y guarda tus cambios.
Runtime 2.0 se establece como el tiempo de ejecución predeterminado para el área de trabajo.

Habilitar entorno de ejecución 2.0 en un elemento de entorno
Para usar Runtime 2.0 con cuadernos específicos o definiciones de trabajo de Spark:
Cree un nuevo elemento Entorno o abra uno existente.
En el menú desplegable Runtime , selecciona 2.0 Vista previa pública (Spark 4.1, Delta 4.2)), Guardar y Publicar tus cambios.
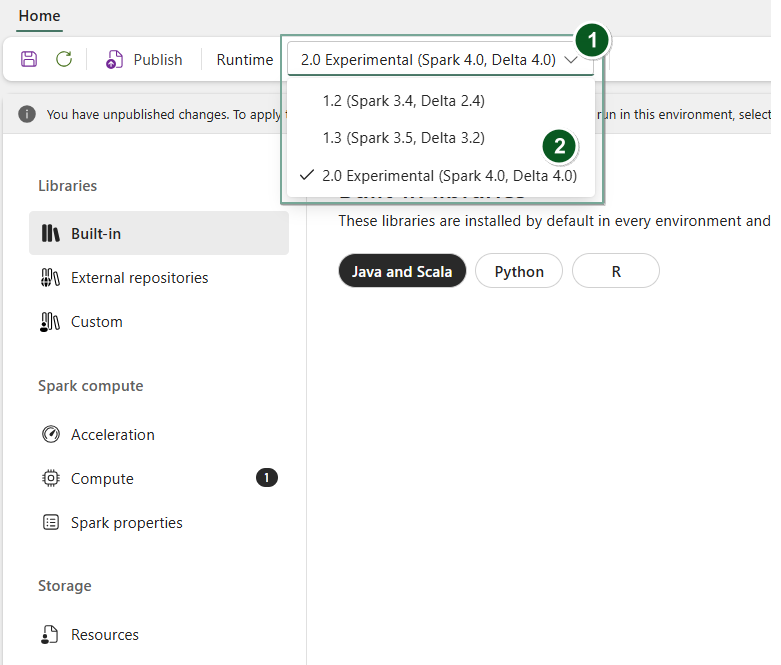
A continuación, puede usar este elemento de entorno con el cuaderno o la definición de trabajo de Spark.

Ahora puedes empezar a experimentar con las últimas mejoras y funcionalidades introducidas en Fabric Runtime 2.0 (Spark 4.1 y Delta Lake 4.2).
Versión preliminar pública
La fase de vista previa pública de Fabric Runtime 2.0 te da acceso a nuevas funciones y APIs tanto de Spark 4.1 como de Delta Lake 4.2. La versión preliminar le permite usar las mejoras más recientes basadas en Spark y Delta inmediatamente, así como garantizar una preparación y transición sin problemas para cambios mejorados y mejorados, como las versiones más recientes de Java, Scala y Python.
Sugerencia
Para obtener información actualizada, una lista detallada de cambios y notas de la versión específicas de los entornos de ejecución de Fabric, comprueba y suscríbete a Versiones y actualizaciones de Spark Runtimes.
Aspectos destacados clave
Mejoras en el rendimiento y el motor de ejecución
Fabric Runtime 2.0 incluye el motor de ejecución nativo, que proporciona mejoras de rendimiento significativas en Spark de código abierto. El motor usa el procesamiento vectorizado para acelerar las consultas de Spark en la infraestructura de LakeHouse sin necesidad de cambios de código.
Características clave de rendimiento en Runtime 2.0:
- Hasta seis veces más rápido: las pruebas comparativas muestran un rendimiento hasta seis veces más rápido en comparación con Spark de código abierto en cargas de trabajo de TPC-DS.
- Análisis de CSV vectorializado: el motor de ejecución nativo incluye un analizador CSV vectorizado que acelera la ingesta y las cargas de trabajo de consulta de CSV. El análisis de JSON vectorializado y la compatibilidad con Spark Structured Streaming están planeadas para futuras actualizaciones.
Para habilitar el motor de ejecución nativo, consulte Motor de ejecución nativo para Fabric Data Engineering.
Apache Spark 4.1
Apache Spark 4.0 marcó un hito importante como la versión inicial de la serie 4.x, que encarna el esfuerzo colectivo de la vibrante comunidad de código abierto. Fabric Runtime 2.0 ahora se ejecuta en Apache Spark 4.1, que se basa en esa base con mejoras adicionales.
En esta versión, Spark SQL se enriquece significativamente con eficaces características nuevas diseñadas para aumentar la expresividad y la versatilidad de las cargas de trabajo de SQL, como la compatibilidad con el tipo de datos VARIANT, las funciones definidas por el usuario de SQL, las variables de sesión, la sintaxis de canalización y la intercalación de cadenas. PySpark ve una dedicación continua tanto a su amplitud funcional como a la experiencia general del desarrollador, lo que aporta una API de trazado nativo, una nueva API de origen de datos de Python, compatibilidad con UDF de Python y generación de perfiles unificada para UDF de PySpark, junto con muchas otras mejoras. Structured Streaming evoluciona con adiciones clave que proporcionan un mayor control y facilidad de depuración, en particular la introducción de la API de estado arbitrario v2 para una administración de estado más flexible y el origen de datos de estado para facilitar la depuración.
Puede comprobar la lista completa y los cambios detallados aquí:
Nota:
En Spark 4.x, SparkR está en desuso y podría quitarse en una versión futura.
Delta Lake 4.2
Delta Lake 4.2 se basa en lanzamientos anteriores de Delta Lake, continuando el compromiso de hacer que Delta Lake sea interoperable entre formatos, más fácil de manejar y más eficiente. Incluye nuevas y potentes funciones, optimizaciones del rendimiento y mejoras fundamentales para el futuro de las plataformas lakehouse de datos abiertas.
Para la lista completa y los cambios detallados introducidos con Delta Lake 3.3, 4.0, 4.1 y 4.2, véase:
Diseño y optimización de datos
Runtime 2.0 admite características de diseño y optimización de datos para tablas Delta:
- Ordenación Z: organice los datos dentro de los archivos de tabla Delta mediante columnas especificadas para mejorar el rendimiento de las consultas filtradas.
- Agrupación en clústeres líquidos: un enfoque flexible de agrupación en clústeres que optimiza automáticamente el diseño de datos sin mantenimiento manual.
- Carga de instantáneas Delta paralelas: el motor de ejecución nativo carga en paralelo instantáneas de tablas Delta, reduciendo el tiempo de inicio de consulta para tablas grandes.
Importante
Las características específicas de Delta Lake 4.2 son experimentales y solo funcionan en experiencias de Spark, como los Cuadernos y las Definiciones de Puestos de Spark. Si necesita usar las mismas tablas de Delta Lake en varias cargas de trabajo de Microsoft Fabric, no habilite esas características. Para saber más sobre qué versiones y características de protocolo son compatibles en todas las experiencias de Microsoft Fabric, consulte la interoperabilidad del formato de tabla Delta Lake.
Administración de procesos en runtime 2.0
Runtime 2.0 admite las siguientes características de administración de procesos:
- Perfiles de recursos: configure asignaciones de recursos predefinidas para las sesiones de Spark para que coincidan con los requisitos de carga de trabajo y controlen los costos.
- Grupos dinámicos personalizados (versión preliminar): cree grupos de Spark dedicados y previamente calientes que reduzcan el tiempo de inicio de la sesión. Los grupos dinámicos personalizados están disponibles en versión preliminar para cargas de trabajo en tiempo de ejecución 2.0.
Limitaciones y notas
- Las características específicas de Delta Lake 4.x son experimentales y solo funcionan en experiencias de Spark, como cuadernos y definiciones de trabajos de Spark. Si necesita usar las mismas tablas de Delta Lake en varias cargas de trabajo de Fabric, no habilite esas características. Para obtener más información, consulte Interoperabilidad con formato de tabla delta Lake.
- Runtime 2.0 está en versión preliminar pública. Algunas características y API pueden cambiar antes de la disponibilidad general.
- La extensión de VS Code para Fabric Spark admite Runtime 2.0 para el desarrollo de cuadernos y definiciones de trabajos de Spark.
Contenido relacionado
- Entornos de ejecución de Apache Spark en Fabric: información general, control de versiones y compatibilidad con varios entornos de ejecución
- Guía de migración de Spark Core
- Guías de migración de SQL, DataSets y DataFrame
- Guía de migración de Structured Streaming
- Guía de migración de MLlib (Machine Learning)
- Guía de migración de PySpark (Python en Spark)
- Guía de migración de SparkR (R en Spark)