Guía de modelos compuestos de Power BI Desktop
Este artículo va dirigido a los modeladores de datos que desarrollan modelos compuestos de Power BI. En él se describen los casos de uso de modelos compuestos y se proporciona una guía de diseño. En concreto, la guía puede ayudarle a determinar si un modelo compuesto es adecuado para su solución. En caso afirmativo, este artículo también le ayudará a diseñar modelo compuestos e informes óptimos.
Nota
El artículo no incluye una introducción a los modelos compuestos. Si no está totalmente familiarizado con los modelos compuestos, le recomendamos que primero lea el artículo Usar modelos compuestos en Power BI Desktop.
Dado que los modelos compuestos constan de al menos un origen de DirectQuery, también es importante comprender perfectamente las relaciones del modelo, los modelos de DirectQuery y la guía de diseño de modelos de DirectQuery.
Casos de uso del modelo compuesto
Por definición, un modelo compuesto combina varios grupos de orígenes. Un grupo de orígenes puede representar datos importados o una conexión a un origen de DirectQuery. Un origen de DirectQuery puede ser una base de datos relacional u otro modelo tabular, que puede ser un modelo semántico de Power BI (conocido anteriormente como conjunto de datos) o un modelo tabular de Analysis Services. Cuando un modelo tabular se conecta a otro modelo tabular, se conoce como encadenamiento. Para más información, consulte Uso de DirectQuery para modelos semánticos de Power BI y Analysis Services.
Nota:
Cuando un modelo se conecta a un modelo tabular, pero no lo extiende con datos adicionales, no es un modelo compuesto. En este caso, es un modelo de DirectQuery que se conecta a un modelo remoto, por lo que consta solo del grupo de orígenes. Puede crear este tipo de modelo para modificar las propiedades de los objetos del modelo de origen, como un nombre de tabla, un criterio de ordenación de columnas o una cadena de formato.
La conexión a modelos tabulares es especialmente interesante al extender un modelo semántico empresarial (cuando se trata de un modelo semántico de Power BI o un modelo de Analysis Services). Un modelo semántico empresarial es fundamental para el desarrollo y el funcionamiento de un almacenamiento de datos. Proporciona una capa de abstracción sobre los datos del almacenamiento de datos para presentar definiciones y terminología de negocio. Normalmente se usa como vínculo entre los modelos de datos físicos y las herramientas de informes, como Power BI. En la mayoría de las organizaciones, se administra mediante un equipo central y por eso se describe como empresarial. Para más información, consulte el escenario de uso de BI empresarial.
Además, puede considerar el desarrollo de un modelo compuesto en las siguientes situaciones.
- El modelo podría ser un modelo de DirectQuery, pero quiere mejorar el rendimiento. En un modelo compuesto, puede mejorar el rendimiento configurando el almacenamiento adecuado para cada tabla. También puede incorporar agregaciones definidas por el usuario. Estas dos optimizaciones se describen más adelante en este artículo.
- Quiere combinar un modelo de DirectQuery con datos adicionales, que se deben importar en el modelo. Los datos importados se pueden cargar desde un origen de datos diferente o desde tablas calculadas.
- Desea combinar dos o más orígenes de datos DirectQuery en un único modelo. Estos orígenes podrían ser bases de datos relacionales u otros modelos tabulares.
Nota
Los modelos compuestos no pueden incluir conexiones a determinadas bases de datos analíticas externas. Entre estas bases de datos se incluyen SAP Business Warehouse y SAP HANA cuando se trata SAP HANA como un origen multidimensional.
Evaluación de otras opciones de diseño de modelos
Aunque los modelos compuestos de Power BI pueden resolver desafíos de diseño concretos, pueden contribuir a ralentizar el rendimiento. Además, en algunas situaciones, pueden producirse resultados de cálculo inesperados (descritos más adelante en este artículo). Por estos motivos, evalúe otras opciones de diseño de modelos cuando existan.
Siempre que sea posible, es mejor desarrollar un modelo en modo de importación. Este modo proporciona la mayor flexibilidad de diseño y el mejor rendimiento.
Sin embargo, los modelos de importación no pueden resolver los desafíos relacionados con grandes volúmenes de datos o con la generación de informes sobre datos casi en tiempo real. En cualquiera de estos casos, puede considerar un modelo DirectQuery, siempre y cuando los datos se almacenen en un único origen de datos que sea compatible con el modo DirectQuery. Para más información, consulte Modelos de DirectQuery en Power BI Desktop.
Sugerencia
Si el objetivo es ampliar un modelo tabular existente con más datos, siempre que sea posible, agregue esos datos al origen de datos existente.
Modo Table Storage
En un modelo compuesto, puede configurar el modo de almacenamiento de cada tabla (excepto las tablas calculadas).
- DirectQuery: se recomienda establecer este modo para las tablas que representan grandes volúmenes de datos o que deben proporcionar resultados casi en tiempo real. Los datos nunca se importarán en estas tablas. Normalmente, estas tablas serán tablas de tipo hechos, que son tablas que se resumen.
- Importación: se recomienda establecer este modo para las tablas que no se usan para el filtrado y la agrupación de tablas de hechos en modo híbrido o DirectQuery. También es la única opción para las tablas basadas en orígenes no compatibles con el modo DirectQuery. Las tablas calculadas siempre son tablas de importación.
- Dual: se recomienda establecer este modo para las tablas de tipo dimensión, cuando exista la posibilidad de que se realicen consultas en ellas junto con las tablas de tipo hechos de DirectQuery del mismo origen.
- Híbrido: se recomienda configurar este modo agregando particiones de importación y una partición de DirectQuery a una tabla de hechos cuando quiera incluir los cambios de datos más recientes en tiempo real, o bien proporcionar acceso rápido a los datos usados con más frecuencia mediante particiones de importación, pero quiera dejar la mayor parte de los datos usados con menos frecuencia en el almacenamiento de datos.
Hay varios escenarios posibles cuando Power BI consulta un modelo compuesto.
- Consulta solo tablas de importación o duales: Power BI recupera todos los datos de la caché del modelo. Este escenario proporcionará el rendimiento más rápido posible. Es común para las tablas de tipo dimensión consultadas mediante filtros u objetos visuales de segmentación de datos.
- Consulta tablas duales o tablas de DirectQuery del mismo origen: Power BI recupera todos los datos mediante el envío de una o varias consultas nativas al origen de DirectQuery. Este escenario proporcionará un rendimiento óptimo, especialmente cuando existan índices adecuados en las tablas de origen. Este escenario es común para las consultas que relacionan tablas duales de tipo dimensión y tablas de DirectQuery de tipo hechos. Estas consultas son intragrupo de origen y, por tanto, todas las relaciones de uno a uno o de uno a varios se evalúan como relaciones normales.
- Consulta tablas duales o híbridas del mismo origen: este escenario es una combinación de los dos escenarios anteriores. Power BI recupera datos de la caché de modelos cuando está disponible en las particiones de importación; de lo contrario, envía una o varias consultas nativas al origen de DirectQuery. Este escenario proporcionará el rendimiento más rápido posible, ya que solo se consulta un segmento de datos en el almacenamiento de datos, especialmente cuando existan índices adecuados en las tablas de origen. En cuanto a las tablas duales de tipo dimensión y las tablas DirectQuery de tipo hechos, estas consultas son intragrupo, por lo que todas las relaciones uno a uno o uno a varios se evalúan como relaciones normales.
- Todas las demás consultas: estas consultas implican relaciones entre grupos de origen. O bien porque una tabla de importación se relaciona con una tabla de DirectQuery o una tabla dual se relaciona con una tabla de DirectQuery de un origen diferente, en cuyo caso se comporta como una tabla de importación. Todas las relaciones se evalúan como relaciones limitadas. También significa que los agrupamientos aplicados a tablas que no son DirectQuery deben enviarse al origen de DirectQuery como subconsultas materializadas (tablas virtuales). En este caso, la consulta nativa puede ser ineficaz, en especial con conjuntos de agrupamiento grandes.
En resumen, se recomienda que:
- Considere detenidamente que un modelo compuesto sea la solución correcta: si bien permite la integración de nivel de modelo de distintos orígenes de datos, también presenta complejidades de diseño con posibles consecuencias (que se describen más adelante en este artículo).
- Establezca el modo de almacenamiento en DirectQuery cuando una tabla sea una tabla de tipo hechos que almacene grandes volúmenes de datos, o cuando necesite ofrecer resultados casi en tiempo real.
- Considere la posibilidad de usar el modo híbrido definiendo una directiva de actualización incremental y datos en tiempo real, o creando particiones de la tabla de hechos mediante TOM, TMSL o una herramienta de terceros. Para más información, consulte Actualización incremental y datos en tiempo real para modelos semánticos y el escenario de uso Administración avanzada de modelos de datos.
- Establezca el modo de almacenamiento en Dual cuando una tabla sea una tabla de tipo dimensión y se vaya a consultar junto con tablas de DirectQuery o híbridas de tipo hechos que están en el mismo origen.
- Configure las frecuencias de actualización adecuadas para mantener sincronizada la caché de modelos de tablas duales e híbridas (y las tablas calculadas dependientes) con las bases de datos de origen.
- Asegúrese de garantizar la integridad de los datos entre grupos de orígenes (incluida la caché de modelos) porque relaciones limitadas eliminarán las filas de los resultados de la consulta cuando los valores de columna relacionados no coincidan.
- Siempre que sea posible, optimice los orígenes de datos de DirectQuery con los índices adecuados para conseguir combinaciones, filtrados y agrupaciones eficaces.
Agregaciones definidas por el usuario
Puede incorporar agregaciones definidas por el usuario a tablas de DirectQuery. Su finalidad es mejorar el rendimiento de las consultas de más alto nivel de detalle.
Cuando se almacenan en caché agregaciones en el modelo, se comportan como tablas de importación (aunque no se pueden usar como una tabla de modelo). Incorporar agregaciones de importación a un modelo de DirectQuery dará como resultado un modelo compuesto.
Nota
Las tablas híbridas no admiten agregaciones porque algunas de las particiones funcionan en modo de importación. No es posible incorporar agregaciones a nivel de particiones de DirectQuery individuales.
Se recomienda que una agregación siga una regla básica: su recuento de filas debe ser al menos un factor de 10 inferior a la tabla subyacente. Por ejemplo, si la tabla subyacente almacena mil millones de filas, la tabla de agregación no debe superar los 100 millones de filas. Esta regla garantiza una ganancia de rendimiento adecuada en relación con el costo de la creación y el mantenimiento de la agregación.
Relaciones entre grupos de origen
Cuando una relación de modelos abarca grupos de orígenes, se conoce como una relación de grupo entre orígenes. Las relaciones de grupos entre orígenes también son relaciones limitadas porque no hay ningún lado "uno" garantizado. Para más información, vea Evaluación de las relaciones.
Nota
En algunas situaciones, puede evitar la creación de una relación de grupo entre orígenes. Consulte el tema Uso de segmentaciones de sincronización más adelante en este artículo.
Al definir relaciones de grupo entre orígenes, tenga en cuenta las siguientes recomendaciones.
- Use columnas de relación de cardinalidad baja: para obtener el mejor rendimiento, se recomienda que las columnas de relación sean de cardinalidad baja, lo que significa que deben almacenar menos de 50 000 valores únicos. Esta recomendación es especialmente cierta al combinar modelos tabulares y para columnas que no son de texto.
- Evite el uso de columnas de relación de texto grandes: si debe usar columnas de texto en una relación, calcule la longitud de texto esperada para el filtro multiplicando la cardinalidad por la longitud media de la columna de texto. La longitud de texto posible no debe superar el 1 000 000 de caracteres.
- Aumente la granularidad de la relación: si es posible, cree relaciones con un nivel superior de granularidad. Por ejemplo, en lugar de relacionar una tabla de fechas en su clave de fecha, use mejor su clave de mes. Este enfoque de diseño requiere que la tabla relacionada incluya una columna de clave de mes y los informes no podrán mostrar hechos diarios.
- Esfuércese por lograr un diseño de relación simple: cree solo una relación de grupo entre orígenes cuando sea necesario e intente limitar el número de tablas de la ruta de acceso de relación. Este enfoque de diseño ayudará a mejorar el rendimiento y evitar rutas de acceso de relación ambiguas.
Advertencia
Dado que Power BI Desktop no valida exhaustivamente las relaciones de origen entre grupos, es posible crear relaciones ambiguas.
Escenario de relación de grupos entre orígenes 1
Considere un escenario de un diseño de relaciones complejas y cómo podría producir resultados diferentes, pero válidos.
En este escenario, la tabla Region del grupo de orígenes A tiene una relación con la tabla Date y la tabla Sales del grupo de orígenes B. La relación entre la tabla Region y la tabla Date está activa, mientras que la relación entre la tabla Region y la tabla Sales está inactiva. Además, hay una relación activa entre la tabla Region y la tabla Sales, ambas de las cuales están en el grupo de orígenes B. La tabla Sales incluye una medida denominada TotalSales y la tabla Region incluye dos medidas llamadas RegionalSales y RegionalSalesDirect.
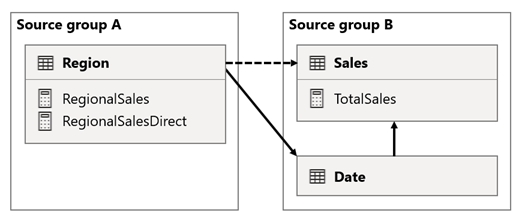
Estas son las definiciones de medida.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Observe cómo la medida RegionalSales hace referencia a la medida TotalSales, mientras que la medida RegionalSalesDirect no. En su lugar, la medida RegionalSalesDirect usa la expresión SUM(Sales[Sales]), que es la expresión de la medida TotalSales.
La diferencia en el resultado es sutil. Cuando Power BI evalúa la medida RegionalSales, aplica el filtro de la tabla Region a la tabla Sales y a la tabla Date. Por lo tanto, el filtro también se propaga de la tabla Date a la tabla Sales. Por el contrario, cuando Power BI evalúa la medida RegionalSalesDirect, solo se propaga el filtro de la tabla Region a la tabla Sales. Los resultados devueltos por la medida RegionalSales y la medida RegionalSalesDirect podrían diferir, aunque las expresiones sean semánticamente equivalentes.
Importante
Siempre que use la función CALCULATE con una expresión que sea una medida en un grupo de orígenes remoto, pruebe los resultados del cálculo exhaustivamente.
Escenario de relación de grupos entre orígenes 2
Considere un escenario en el que una relación de grupo entre orígenes tiene columnas de relación de cardinalidad alta.
En este escenario, la tabla Date está relacionada con la tabla Sales en las columnas DateKey. El tipo de datos de las columnas DateKey es entero, y almacena números enteros que usan el formato aaaammdd. Las tablas pertenecen a diferentes grupos de orígenes. Además, es una relación de cardinalidad alta porque la fecha más antigua de la tabla Date es el 1 de enero de 1900 y la fecha más reciente es el 31 de diciembre de 2100, por lo que hay un total de 73 414 filas en la tabla (una fila para cada fecha en el intervalo de tiempo 1900-2100).
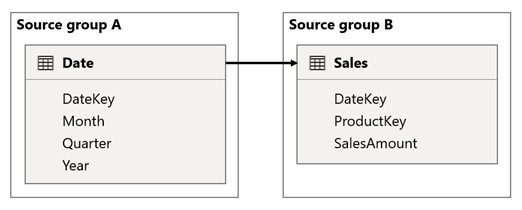
Hay dos problemas.
En primer lugar, cuando use las columnas de la tabla Date como filtros, la propagación del filtro hará que se filtre la columna DateKey de la tabla Sales para evaluar las medidas. Al filtrar por un solo año, como 2022, la consulta DAX incluirá una expresión de filtro como Sales[DateKey] IN { 20220101, 20220102, …20221231 }. El tamaño de texto de la consulta puede crecer hasta llegar a ser extremadamente grande cuando el número de valores de la expresión de filtro es grande o cuando los valores de filtro son cadenas largas. Para Power BI resulta costoso generar la consulta larga y para el origen de datos ejecutar la consulta.
En segundo lugar, cuando se usan columnas de la tabla Date (como Year, Quarter o Month) como columnas de agrupación, se traducen en filtros que incluyen todas las combinaciones únicas de año, trimestre o mes y los valores de la columna DateKey. El tamaño de cadena de la consulta, que contiene filtros en las columnas de agrupación y la columna de relación, puede ser extremadamente grande. Esto es especialmente cierto cuando el número de columnas de agrupación o la cardinalidad de la columna de combinación (la columna DateKey) es grande.
Para solucionar los problemas de rendimiento, puede hacer lo siguiente:
- Agregue la tabla Date al origen de datos, lo que da lugar a un modelo de grupo de un solo origen (es decir, ya no es un modelo compuesto).
- Aumente la granularidad de la relación. Por ejemplo, podría agregar una columna MonthKey a ambas tablas y crear la relación en esas columnas. Sin embargo, al aumentar la granularidad de la relación, se pierde la capacidad de informar sobre la actividad diaria de ventas (a menos que use la columna DateKey de la tabla Sales).
Escenario de relación de grupos entre orígenes 3
Considere un escenario en el que no hay valores coincidentes entre las tablas en una relación de grupos entre orígenes.
En este escenario, la tabla Date del grupo de orígenes B tiene una relación con la tabla Sales de ese grupo de orígenes y también con la tabla Target del grupo de orígenes A. Todas las relaciones son de uno a varios desde la tabla Date relacionada con las columnas Year. La tabla Sales incluye una columna SalesAmount que almacena los importes de ventas, mientras que la tabla Target incluye una columna TargetAmount que almacena los importes de destino.
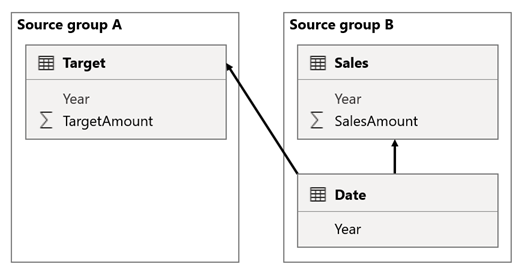
La tabla Date almacena los años 2021 y 2022. La tabla Sales almacena los importes de ventas de los años 2021 (100) y 2022 (200), mientras que la tabla Target almacena los importes de destino para 2021 (100), 2022 (200) y 2023 (300).
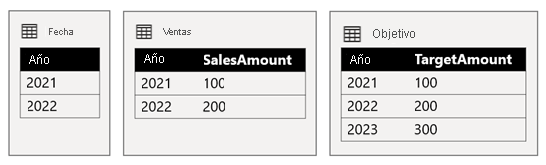
Cuando el objeto visual de una tabla de Power BI consulta el modelo compuesto agrupando por la columna Year de la tabla Date y sumando las columnas SalesAmount y TargetAmount, no mostrará un importe de destino para 2023. Esto se debe a que la relación de grupo entre orígenes es una relación limitada y, por tanto, usa semántica INNER JOIN, que elimina las filas en las que no hay ningún valor coincidente en ambos lados. Sin embargo, se generará un total correcto del importe de destino (600), porque un filtro de tabla Date no se aplica a su evaluación.
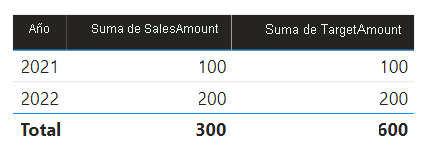
Si la relación entre la tabla Date y la tabla Target es una relación de grupo dentro del origen (suponiendo que la tabla Target pertenezca al grupo de orígenes B), el objeto visual incluirá un año (En blanco) para mostrar el importe de destino de 2023 (y cualquier otro año no coincidente).
Importante
Para evitar informes incorrectos, asegúrese de que haya valores coincidentes en las columnas de relación cuando las tablas de dimensiones y de hechos residen en diferentes grupos de orígenes.
Para más información sobre las relaciones limitadas, consulte Evaluación de relaciones.
Cálculos
Al agregar columnas calculadas y grupos de cálculo a un modelo compuesto, debe tener en cuenta las limitaciones específicas.
Columnas calculadas
Las columnas calculadas agregadas a una tabla de DirectQuery que obtienen los datos de una base de datos relacional, como Microsoft SQL Server, se limitan a expresiones que operan en una sola fila a la vez. Estas expresiones no pueden usar funciones de iterador DAX, como SUMX, o funciones de modificación del contexto de filtro, como CALCULATE.
Nota
No es posible agregar columnas ni tablas calculadas que dependan de modelos tabulares encadenados.
Una expresión de columna calculada en una tabla de DirectQuery remota solo se limita a la evaluación dentro de la fila. No obstante, puede crear esta expresión, si bien producirá un error cuando se use en un objeto visual. Por ejemplo, si agrega una columna calculada a una tabla de DirectQuery remota denominada DimProduct mediante la expresión [Product Sales] / SUM (DimProduct[ProductSales]), podrá guardar correctamente la expresión en el modelo. Sin embargo, cuando se use en un objeto visual, se producirá un error porque infringe la restricción de la evaluación dentro de la fila.
En cambio, las columnas calculadas agregadas a una tabla de DirectQuery remota que es un modelo tabular, que es un modelo semántico de Power BI o un modelo de Analysis Services, son más flexibles. En este caso, se permiten todas las funciones DAX porque la expresión se evaluará dentro del modelo tabular de origen.
Muchas expresiones requieren Power BI para materializar la columna calculada antes de usarla como un grupo o filtro, o agregarla. Cuando una columna calculada se materializa en una tabla grande, puede ser costoso en términos de CPU y memoria, dependiendo de la cardinalidad de las columnas de las que depende la columna calculada. En este caso, se recomienda agregar esas columnas calculadas al modelo de origen.
Nota
Al agregar columnas calculadas a un modelo compuesto, asegúrese de probar todos los cálculos del modelo. Es posible que los cálculos ascendentes no funcionen correctamente porque no consideran su influencia en el contexto de filtro.
Grupos de cálculo
Si existen grupos de cálculo en un grupo de origen que se conecta a un modelo de datos de Power BI o a un modelo de Analysis Services, Power BI podría devolver resultados inesperados. Para más información, consulte Evaluación de medidas, consultas y grupos de cálculo.
Diseño de modelos
Optimice siempre un modelo de Power BI mediante la adopción de un diseño de esquema de estrella.
Sugerencia
Para más información, vea Descripción de un esquema de estrella e importancia para Power BI.
Asegúrese de crear tablas de dimensiones independientes de las tablas de hechos para que Power BI pueda interpretar las combinaciones correctamente y generar planes de consulta eficaces. Aunque esta guía es válida para cualquier modelo de Power BI, es especialmente válida para los modelos que reconozca que se convertirán en un grupo de orígenes de un modelo compuesto. Va a permitir una integración más sencilla y eficaz de otras tablas en modelos descendentes.
Siempre que sea posible, evite tener tablas de dimensiones en un grupo de orígenes que se relacionen con una tabla de hechos en un grupo de orígenes diferentes. El motivo es que es mejor tener relaciones de grupo dentro del origen que relaciones de grupo entre orígenes, especialmente en el caso de las columnas de relación de cardinalidad alta. Como se ha descrito anteriormente, las relaciones de grupo entre orígenes dependen de tener valores coincidentes en las columnas de relación; de lo contrario, pueden mostrarse resultados inesperados en los objetos visuales del informe.
Seguridad de nivel de fila
Si el modelo incluye agregaciones definidas por el usuario, columnas calculadas en tablas de importación o tablas calculadas, asegúrese de que la seguridad de nivel de fila (RLS) esté configurada correctamente y se haya probado.
Si el modelo compuesto se conecta a otros modelos tabulares, las reglas de RLS solo se aplican en el grupo de orígenes (modelo local) donde se definen. No se aplicarán a otros grupos de orígenes (modelos remotos). Además, no puede definir reglas RLS en una tabla de otro grupo de orígenes ni puede definirlas en una tabla local que tenga una relación con otro grupo de orígenes.
Diseño del informe
En algunas situaciones, puede mejorar el rendimiento de un modelo compuesto mediante el diseño de un informe optimizado.
Objetos visuales de grupos de origen único
Siempre que sea posible, cree objetos visuales que usen campos de un grupo de origen único. El motivo es que las consultas generadas por objetos visuales funcionarán mejor cuando el resultado se recupere de un grupo de origen único. Considere la posibilidad de crear dos objetos visuales colocados en paralelo que recuperen datos de dos grupos de origen diferentes.
Uso de segmentaciones de sincronización
En algunas situaciones, puede configurar segmentaciones de sincronización para evitar crear una relación de grupo entre orígenes en el modelo. Esto puede permitirle combinar grupos de orígenes visualmente que puedan funcionar mejor.
Considere un escenario en el que el modelo tiene dos grupos de orígenes. Cada grupo de orígenes tiene una tabla de dimensiones de producto que se usa para filtrar el revendedor y las ventas por Internet.
En este escenario, el grupo de orígenes A contiene la tabla Product relacionada con la tabla ResellerSales. El grupo de orígenes B contiene la tabla Product2 relacionada con la tabla InternetSales. No hay ninguna relación de grupo entre orígenes.
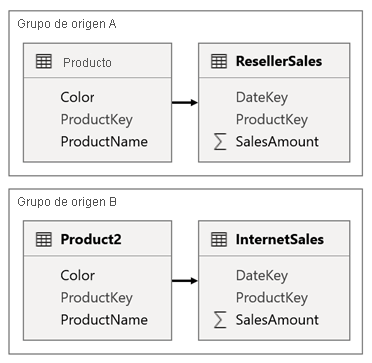
En el informe, se agrega una segmentación que filtra la página mediante la columna Color de la tabla Product. De forma predeterminada, la segmentación filtra la tabla ResellerSales, pero no la tabla InternetSales. A continuación, agregue una segmentación oculta mediante la columna Color de la tabla Product2. Al establecer un nombre de grupo idéntico (que se encuentra en las opciones avanzadas de segmentaciones de sincronización), los filtros aplicados a la segmentación visible se propagan automáticamente a la segmentación oculta.
Nota
Aunque el uso de segmentaciones de sincronización puede evitar la necesidad de crear una relación de grupo entre orígenes, aumenta la complejidad del diseño del modelo. Asegúrese de informar a otros usuarios sobre por qué ha diseñado el modelo con tablas de dimensiones duplicadas. Evite confusiones ocultando las tablas de dimensiones que no quiera que usen otros usuarios. También puede agregar texto de descripción a las tablas ocultas para documentar su propósito.
Para más información, consulte Sincronización de segmentaciones independientes.
Otra guía
Estos son algunos otros consejos que le ayudarán a diseñar y mantener los modelos compuestos.
- Rendimiento y escala: si los informes estaban conectados previamente de forma dinámica a un modelo semántico de Power BI o a un modelo de Analysis Services, el servicio Power BI podría reutilizar las cachés de objetos visuales en los informes. Después de convertir la conexión dinámica para crear un modelo de DirectQuery local, los informes ya no se beneficiarán de esas cachés. Como resultado, puede experimentar un rendimiento más lento o incluso errores de actualización. Además, la carga de trabajo del servicio Power BI aumentará, lo que puede requerir que escale verticalmente la capacidad o que distribuya la carga de trabajo entre otras capacidades. Para más información sobre la actualización y el almacenamiento en caché de datos, consulte Actualización de datos en Power BI.
- Cambio de nombre: no se recomienda cambiar el nombre de los modelos semánticos usados por los modelos compuestos ni cambiar el nombre de sus áreas de trabajo. Esto se debe a que los modelos compuestos se conectan a modelos semánticos de Power BI mediante el uso de los nombres de área de trabajo y de modelo semántico (y no sus identificadores únicos internos). Cambiar el nombre de un modelo semántico o de un área de trabajo podría interrumpir las conexiones usadas por el modelo compuesto.
- Gobernanza: no se recomienda que el modelo de versión única de la verdad sea un modelo compuesto. Esto se debe a que dependería de otros orígenes de datos o modelos, lo que, si se actualiza, podría provocar la interrupción del modelo compuesto. En su lugar, se recomienda publicar un modelo semántico empresarial como única versión de la verdad. Considere este modelo como una base confiable. A continuación, otros modeladores de datos pueden crear modelos compuestos que extiendan el modelo base para crear modelos especializados.
- Linaje de datos: use las características de linaje de datos y análisis de impacto para modelos semánticos antes de publicar cambios en el modelo compuesto. Estas características están disponibles en el servicio Power BI y pueden ayudarle a comprender cómo se relacionan y usan los modelos semánticos. Es importante comprender que no se puede realizar un análisis de impacto en modelos semánticos externos que se muestren en la vista de linaje pero que en realidad se encuentran en otra área de trabajo. Para realizar el análisis de impacto en un modelo semántico externo, debe navegar hasta el área de trabajo de origen.
- Actualizaciones de esquema: debe actualizar el modelo compuesto en Power BI Desktop cuando se realicen cambios de esquema en orígenes de datos ascendentes. A continuación, tendrá que volver a publicar el modelo en el servicio Power BI. Asegúrese de probar exhaustivamente los cálculos y los informes dependientes.
Contenido relacionado
Para más información sobre este artículo, consulte los recursos siguientes.
- Usar modelos compuestos en Power BI Desktop
- Relaciones de modelos en Power BI Desktop
- Modelos de DirectQuery en Power BI Desktop
- Usar DirectQuery en Power BI Desktop
- Uso de DirectQuery para modelos semánticos de Power BI y Analysis Services
- Modo de almacenamiento en Power BI Desktop
- Agregaciones definidas por el usuario
- ¿Tiene alguna pregunta? Pruebe a preguntar a la comunidad de Power BI
- ¿Sugerencias? Ideas para contribuir a mejorar Power BI
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente las Cuestiones de GitHub como mecanismo de retroalimentación para el contenido y lo sustituiremos por un nuevo sistema de retroalimentación. Para más información, consulta: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de