Creación, exportación y puntuación de modelos de aprendizaje automático de Spark en Clústeres de macrodatos de SQL Server
Importante
El complemento Clústeres de macrodatos de Microsoft SQL Server 2019 se va a retirar. La compatibilidad con Clústeres de macrodatos de SQL Server 2019 finalizará el 28 de febrero de 2025. Todos los usuarios existentes de SQL Server 2019 con Software Assurance serán totalmente compatibles con la plataforma, y el software se seguirá conservando a través de actualizaciones acumulativas de SQL Server hasta ese momento. Para más información, consulte la entrada de blog sobre el anuncio y Opciones de macrodatos en la plataforma Microsoft SQL Server.
En el siguiente ejemplo se muestra cómo crear un modelo con Spark ML, exportarlo a MLeap y puntuarlo en SQL Server con su extensión de lenguaje Java. Esto se hace en el contexto de un clúster de macrodatos de SQL Server.
En el siguiente diagrama se muestra el trabajo que se lleva a cabo en este ejemplo:
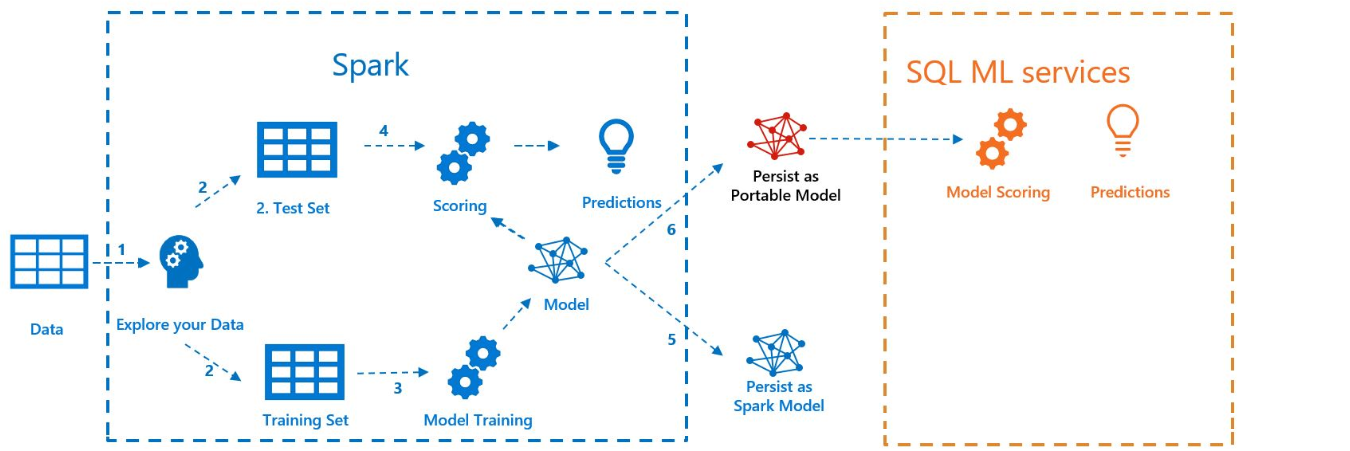
Requisitos previos
Todos los archivos de este ejemplo se encuentran en https://github.com/microsoft/sql-server-samples/tree/master/samples/features/sql-big-data-cluster/spark/sparkml.
Para ejecutar el ejemplo, también debe cumplir los siguientes requisitos previos:
-
- kubectl
- curl
- Azure Data Studio
Entrenamiento de modelos con Spark ML
En este ejemplo, los datos de censo (AdultCensusIncome.csv) sirven para crear un modelo de canalización de Spark ML.
Use el archivo mleap_sql_test/Setup.sh para descargar el conjunto de datos de Internet y colocarlo en HDFS en el clúster de macrodatos de SQL Server. Esto permite que Spark tenga acceso a él.
Luego, descargue el cuaderno de ejemplo train_score_export_ml_models_with_spark.ipynb. Desde una línea de comandos de PowerShell o Bash, ejecute el siguiente comando para descargar el cuaderno:
curl -o mssql_spark_connector.ipynb "https://raw.githubusercontent.com/microsoft/sql-server-samples/master/samples/features/sql-big-data-cluster/spark/sparkml/train_score_export_ml_models_with_spark.ipynb"Este cuaderno contiene celdas con los comandos necesarios para esta sección del ejemplo.
Abra el cuaderno en Azure Data Studio y ejecute cada bloque de código. Para obtener más información sobre el trabajo con cuadernos, vea Procedimiento para usar cuadernos con SQL Server.
Los datos se leen primero en Spark y se dividen en conjuntos de datos de entrenamiento y de prueba. Después, el código entrena un modelo de canalización con los datos de entrenamiento. Por último, exporta el modelo a un conjunto de MLeap.
Sugerencia
También puede revisar o ejecutar el código de Python asociado a estos pasos fuera del cuaderno en el archivo mleap_sql_test/mleap_pyspark.py.
Puntuación del modelo con SQL Server
Ahora que el modelo de canalización de Spark ML se encuentra en un formato de serialización común de agrupación de MLeap, puede puntuarlo en Java sin la presencia de Spark.
En este ejemplo se usa la extensión del lenguaje Java en SQL Server. Para poder puntuar el modelo en SQL Server, primero debe compilar una aplicación Java que pueda cargar el modelo en Java y puntuarlo. Encontrará el código de ejemplo para esta aplicación Java en la carpeta mssql-mleap-app.
Después de compilar el ejemplo, puede usar Transact-SQL para llamar a la aplicación Java y puntuar el modelo con una tabla de base de datos. Puede verse en el archivo de código fuente mleap_sql_test/mleap_sql_tests.py.
Pasos siguientes
Para obtener más información sobre los clústeres de macrodatos, vea Cómo implementar Clústeres de macrodatos de SQL Server en Kubernetes.