Oharra
Baimena behar duzu orria atzitzeko. Direktorioetan saioa has dezakezu edo haiek alda ditzakezu.
Baimena behar duzu orria atzitzeko. Direktorioak alda ditzakezu.
SE APLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Sugerencia
Data Factory en Microsoft Fabric es la próxima generación de Azure Data Factory, con una arquitectura más sencilla, inteligencia artificial integrada y nuevas características. Si no está familiarizado con la integración de datos, comience con Fabric Data Factory. Las cargas de trabajo de ADF existentes pueden actualizarse a Fabric para acceder a nuevas funcionalidades en ciencia de datos, análisis en tiempo real e informes.
La actividad de Python de Azure Databricks en un pipeline ejecuta un archivo Python en el clúster de Azure Databricks. Este artículo se basa en el artículo sobre actividades de transformación de datos , que presenta información general de la transformación de datos y las actividades de transformación admitidas. Azure Databricks es una plataforma administrada para ejecutar Apache Spark.
Si desea una introducción y demostración de once minutos de esta característica, vea el siguiente vídeo:
Adición de una actividad de Python para Azure Databricks a una canalización con interfaz de usuario
Para usar una actividad de Python para Azure Databricks en una canalización, complete los pasos siguientes:
Busque Python en el panel Actividades de canalización y arrastre una actividad de Python al lienzo de la canalización.
Seleccione la nueva actividad Python en el lienzo si aún no está seleccionada.
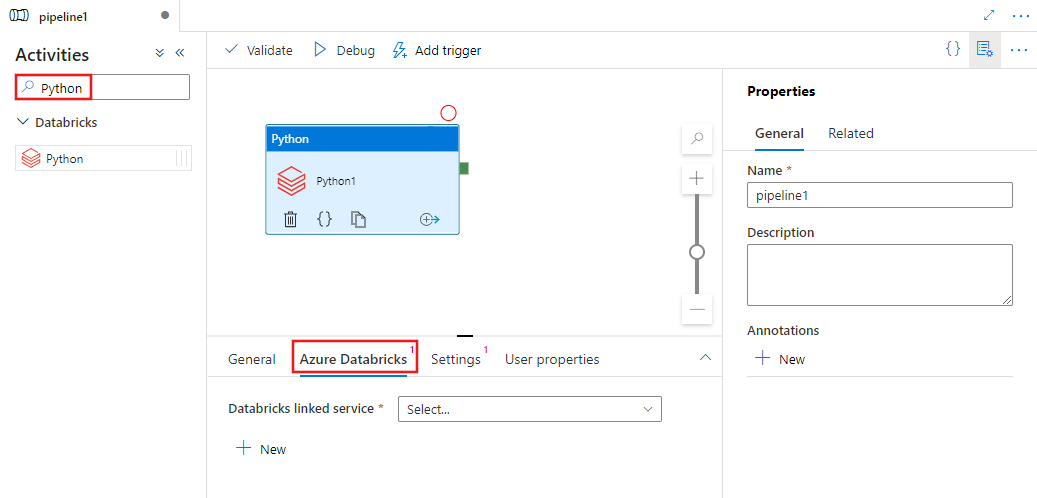
Seleccione la pestaña Azure Databricks para seleccionar o crear un nuevo servicio vinculado Azure Databricks que ejecutará la actividad de Python.
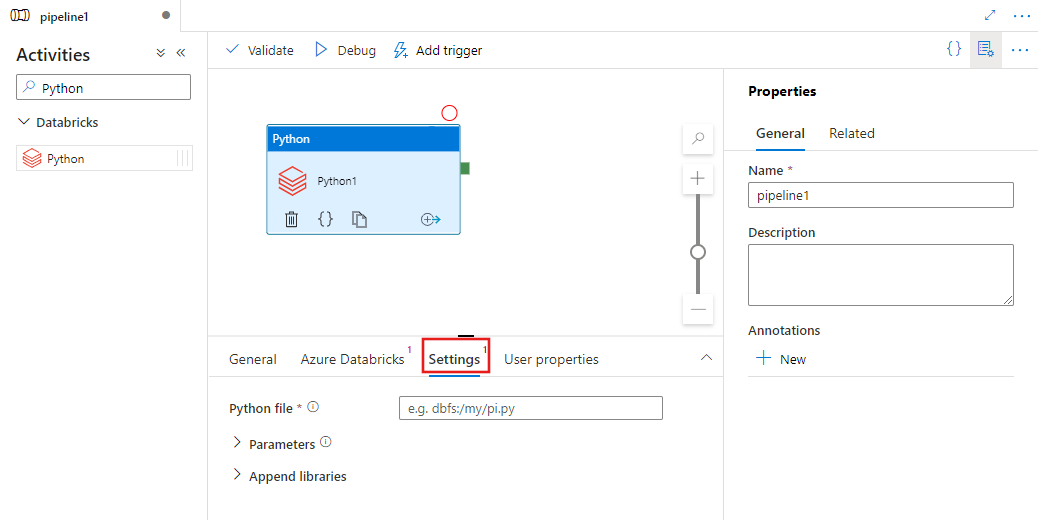
Seleccione la pestaña Settings y especifique la ruta de acceso dentro de Azure Databricks en un archivo Python que se va a ejecutar, parámetros opcionales que se van a pasar y las bibliotecas adicionales que se van a instalar en el clúster para ejecutar el trabajo.
Definición de actividad de Python de Databricks
Esta es la definición JSON de ejemplo de una actividad de databricks Python:
{
"activity": {
"name": "MyActivity",
"description": "MyActivity description",
"type": "DatabricksSparkPython",
"linkedServiceName": {
"referenceName": "MyDatabricksLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"pythonFile": "dbfs:/docs/pi.py",
"parameters": [
"10"
],
"libraries": [
{
"pypi": {
"package": "tensorflow"
}
}
]
}
}
}
Propiedades de actividad de Python de Databricks
En la siguiente tabla se describen las propiedades JSON que se usan en la definición de JSON:
| Propiedad | Descripción | Obligatorio |
|---|---|---|
| nombre | Nombre de la actividad en la canalización. | Sí |
| descripción | Texto que describe para qué se usa la actividad. | No |
| tipo | Para Databricks Python Activity, el tipo de actividad es DatabricksSparkPython. | Sí |
| linkedServiceName | Nombre del servicio vinculado de Databricks en el que se ejecuta la actividad Python. Para obtener más información sobre este servicio vinculado, consulte el artículo Compute linked services (Servicios vinculados de cálculo). | Sí |
| pythonFile | URI del archivo Python que se ejecutará. Solo se admiten rutas de acceso de DBFS. | Sí |
| parámetros | Parámetros de línea de comandos que se pasarán al archivo Python. Se trata de una matriz de cadenas. | No |
| bibliotecas | Lista de bibliotecas para instalar en el clúster que ejecutará el trabajo. Puede ser una matriz de <cadena, objeto>. | No |
Bibliotecas compatibles con las actividades de Databricks
En la definición de la actividad de Databricks anterior, especifica estos tipos de biblioteca: jar, egg, maven, pypi, cran.
{
"libraries": [
{
"jar": "dbfs:/mnt/libraries/library.jar"
},
{
"egg": "dbfs:/mnt/libraries/library.egg"
},
{
"maven": {
"coordinates": "org.jsoup:jsoup:1.7.2",
"exclusions": [ "slf4j:slf4j" ]
}
},
{
"pypi": {
"package": "simplejson",
"repo": "http://my-pypi-mirror.com"
}
},
{
"cran": {
"package": "ada",
"repo": "https://cran.us.r-project.org"
}
}
]
}
Para más detalles, consulte la documentación de Databricks sobre los tipos de bibliotecas.
Carga de una biblioteca en Databricks
Puede usar la interfaz de usuario del área de trabajo:
Uso de la interfaz de usuario del área de trabajo de Databricks
Para obtener la ruta de acceso de dbfs de la biblioteca que se agregó mediante la interfaz de usuario, puede usar la CLI de Databricks.
Habitualmente, las bibliotecas de Jar se almacenan en dbfs:/FileStore/jars mientras se usa la interfaz de usuario. Puede enumerar todo mediante la CLI: databricks fs ls dbfs:/FileStore/job-jars
O bien, puede usar la CLI de Databricks:
Uso de la CLI de Databricks (pasos de instalación)
Por ejemplo, para copiar un archivo JAR en dbfs:
dbfs cp SparkPi-assembly-0.1.jar dbfs:/docs/sparkpi.jar