Query Apache Hive through the JDBC driver in HDInsight
Learn how to use the JDBC driver from a Java application. To submit Apache Hive queries to Apache Hadoop in Azure HDInsight. The information in this document demonstrates how to connect programmatically, and from the SQuirreL SQL client.
For more information on the Hive JDBC Interface, see HiveJDBCInterface.
Prerequisites
- An HDInsight Hadoop cluster. To create one, see Get started with Azure HDInsight. Ensure that service HiveServer2 is running.
- The Java Developer Kit (JDK) version 11 or higher.
- SQuirreL SQL. SQuirreL is a JDBC client application.
JDBC connection string
JDBC connections to an HDInsight cluster on Azure are made over port 443. The traffic is secured using TLS/SSL. The public gateway that the clusters sit behind redirects the traffic to the port that HiveServer2 is actually listening on. The following connection string shows the format to use for HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Replace CLUSTERNAME with the name of your HDInsight cluster.
Host name in connection string
Host name 'CLUSTERNAME.azurehdinsight.net' in the connection string is the same as your cluster URL. You can get it through Azure portal.
Port in connection string
You can only use port 443 to connect to the cluster from some places outside of the Azure virtual network. HDInsight is a managed service, which means all connections to the cluster are managed via a secure Gateway. You can't connect to HiveServer 2 directly on ports 10001 or 10000. These ports aren't exposed to the outside.
Authentication
When establishing the connection, use the HDInsight cluster admin name and password to authenticate. From JDBC clients such as SQuirreL SQL, enter admin name and password in client settings.
From a Java application, you must use the name and password when establishing a connection. For example, the following Java code opens a new connection:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Connect with SQuirreL SQL client
SQuirreL SQL is a JDBC client that can be used to remotely run Hive queries with your HDInsight cluster. The following steps assume that you have already installed SQuirreL SQL.
Create a directory to contain certain files to be copied from your cluster.
In the following script, replace
sshuserwith the SSH user account name for the cluster. ReplaceCLUSTERNAMEwith the HDInsight cluster name. From a command line, change your work directory to the one created in the prior step, and then enter the following command to copy files from an HDInsight cluster:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Start the SQuirreL SQL application. From the left of the window, select Drivers.

From the icons at the top of the Drivers dialog, select the + icon to create a driver.
In the Added Driver dialog, add the following information:
Property Value Name Hive Example URL jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Extra Class Path Use the Add button to add the all of jar files downloaded earlier. Class Name org.apache.hive.jdbc.HiveDriver 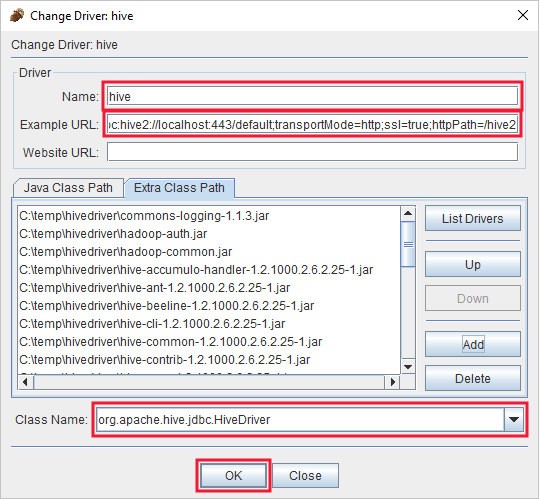
Select OK to save these settings.
On the left of the SQuirreL SQL window, select Aliases. Then select the + icon to create a connection alias.
Use the following values for the Add Alias dialog:
Property Value Name Hive on HDInsight Driver Use the drop-down to select the Hive driver. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Replace CLUSTERNAME with the name of your HDInsight cluster.User Name The cluster login account name for your HDInsight cluster. The default is admin. Password The password for the cluster login account. 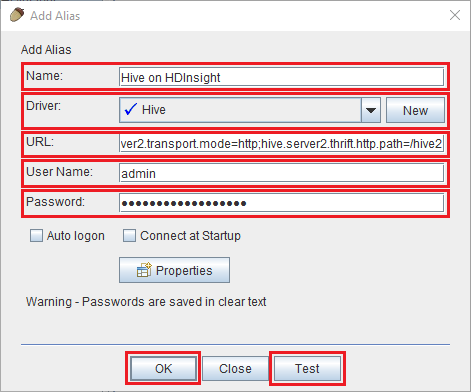
Important
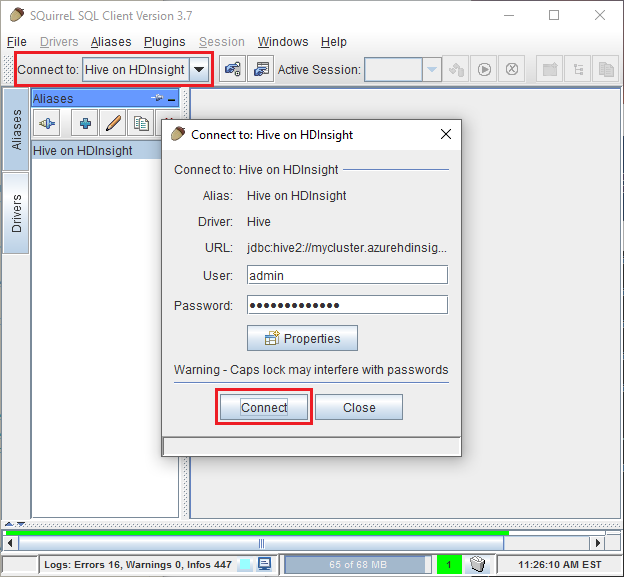
Use the Test button to verify that the connection works. When Connect to: Hive on HDInsight dialog appears, select Connect to perform the test. If the test succeeds, you see a Connection successful dialog. If an error occurs, see Troubleshooting.
To save the connection alias, use the Ok button at the bottom of the Add Alias dialog.
From the Connect to dropdown at the top of SQuirreL SQL, select Hive on HDInsight. When prompted, select Connect.
Once connected, enter the following query into the SQL query dialog, and then select the Run icon (a running person). The results area should show the results of the query.
select * from hivesampletable limit 10;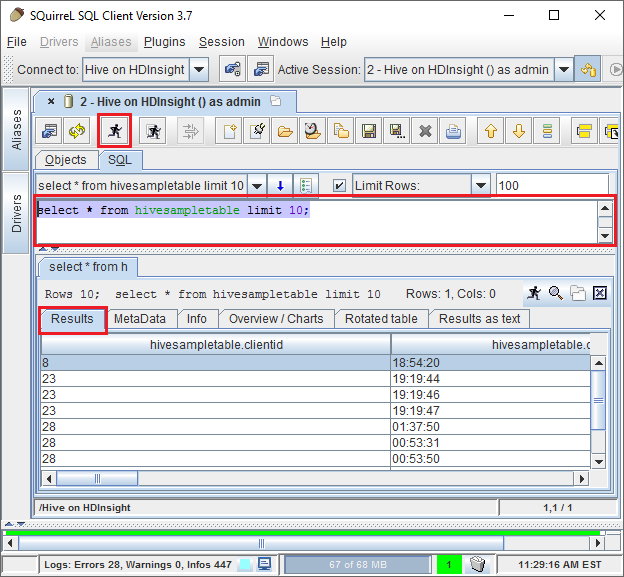
Connect from an example Java application
An example of using a Java client to query Hive on HDInsight is available at https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Follow the instructions in the repository to build and run the sample.
Troubleshooting
Unexpected Error occurred attempting to open an SQL connection
Symptoms: When connecting to an HDInsight cluster that is version 3.3 or greater, you may receive an error that an unexpected error occurred. The stack trace for this error begins with the following lines:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Cause: This error is caused by an older version commons-codec.jar file included with SQuirreL.
Resolution: To fix this error, use the following steps:
Exit SQuirreL, and then go to the directory where SQuirreL is installed on your system, perhaps
C:\Program Files\squirrel-sql-4.0.0\lib. In the SquirreL directory, under thelibdirectory, replace the existing commons-codec.jar with the one downloaded from the HDInsight cluster.Restart SQuirreL. The error should no longer occur when connecting to Hive on HDInsight.
Connection disconnected by HDInsight
Symptoms: HDInsight unexpectedly disconnects the connection when trying to download a huge amount of data (say several GBs) through JDBC/ODBC.
Cause: The limitation on Gateway nodes causes this error. When getting data from JDBC/ODBC, all data needs to pass through the Gateway node. However, a gateway isn't designed to download a huge amount of data, so the Gateway might close the connection if it can't handle the traffic.
Resolution: Avoid using JDBC/ODBC driver to download huge amounts of data. Copy data directly from blob storage instead.
Next steps
Now that you've learned how to use JDBC to work with Hive, use the following links to explore other ways to work with Azure HDInsight.
- Visualize Apache Hive data with Microsoft Power BI in Azure HDInsight.
- Visualize Interactive Query Hive data with Power BI in Azure HDInsight.
- Connect Excel to HDInsight with the Microsoft Hive ODBC Driver.
- Connect Excel to Apache Hadoop by using Power Query.
- Use Apache Hive with HDInsight
- Use Apache Pig with HDInsight
- Use MapReduce jobs with HDInsight
Palaute
Tulossa pian: Vuoden 2024 aikana poistamme asteittain GitHub Issuesin käytöstä sisällön palautemekanismina ja korvaamme sen uudella palautejärjestelmällä. Lisätietoja on täällä: https://aka.ms/ContentUserFeedback.
Lähetä ja näytä palaute kohteelle