Recommendations for using availability zones and regions
Applies to this Azure Well-Architected Framework Reliability checklist recommendation:
| RE:05 | Add redundancy at different levels, especially for critical flows. Apply redundancy to the compute, data, network, and other infrastructure tiers in accordance with the identified reliability targets. |
|---|
Related guides: Highly available multiregional design | Redundancy
This guide describes the recommendations for determining when to deploy workloads across availability zones or regions.
When you design a solution for Azure, you need to decide whether you'll deploy across multiple availability zones in a region or deploy into multiple regions. This decision affects your solution's reliability, cost, and performance, and your team's ability to operate the solution. This guide provides information about the key business requirements that influence your decision, the approaches you can consider, the tradeoffs involved in each approach, and the effect of each approach on the core pillars of the Azure Well-Architected Framework.
The decision about the best Azure regions to use for your solution is a critical choice. The Select Azure Regions guide describes how to select and operate in multiple geographic regions. Your choice of how you use regions and availability zones within your solution also affects several of the pillars of the Well-Architected Framework:
- Reliability: Your choice of deployment approach can help you to mitigate various types of risks. In general, by spreading your workload across a more geographically distributed area, you can achieve higher resiliency.
- Cost Optimization: Some architectural approaches require deploying more resources than others, which can increase your resource costs. Other approaches involve sending data across geographically separated availability zones or regions, which might incur network traffic charges. It's also important to consider the ongoing cost of managing your resources, which is usually higher when you have comprehensive business requirements.
- Performance Efficiency: Availability zones are connected together through a high-bandwidth, low-latency network link, which is sufficient for most workloads to enable synchronous replication and communication across the zones. However, if your workload has been tested and is sensitive to network latency across zones, you might need to consider physically locating your workload's components close together to minimize latency when they communicate.
- Operational Excellence: A complex architecture takes more effort to deploy, configure, and manage. Additionally, for a highly available solution, you might need to plan how to fail over to a secondary set of resources. Failover, failback, and transparently redirecting your traffic can be complex, especially when manual steps are required. It's a good practice to automate your deployment and management processes. For more information, see the Operational Excellence pillar guides, including OE:05 Infrastructure as code, OE:09 Task automation, OE:10 Automation design, and OE:11 Deployment practices.
However you design your solution, the Security pillar applies. Usually, decisions about whether and how you use availability zones and regions doesn't change your security posture. Azure applies the same security rigor to every region and availability zone.
Tip
For many production workloads, a zone-redundant deployment provides the best balance of tradeoffs. You can extend this approach with asynchronous data backup to another region. If you aren't sure which approach to select, start with this type of deployment.
Consider other workload approaches when you need the specific benefits that those approaches provide, but be aware of the tradeoffs involved.
Definitions
| Term | Definition |
|---|---|
| Active-active | An architecture in which multiple instances of a solution actively process requests at the same time. |
| Active-passive | An architecture in which one instance of a solution is designated as the primary and processes traffic, and one or more secondary instances are deployed to serve traffic if the primary is unavailable. |
| Asynchronous replication | A data replication approach in which data is written and committed to one location. At a later time, the changes are replicated to another location. |
| Availability zone | A separated group of datacenters within a region. Each availability zone is independent of the others, with its own power, cooling, and networking infrastructure. Many regions support availability zones. |
| Datacenter | A facility that contains servers, networking equipment, and other hardware to support Azure resources and workloads. |
| Locally redundant deployment | A deployment model in which a resource is deployed into a single region without reference to an availability zone. In a region that supports availability zones, the resource might be deployed in any of the region's availability zones. |
| Multi-region deployment | A deployment model in which resources are deployed into multiple Azure regions. |
| Paired regions | A relationship between two Azure regions. Some Azure regions are connected to another defined region to enable specific types of multi-region solutions. Newer Azure regions aren't paired. |
| Region | A geographic perimeter that contains a set of datacenters. |
| Region architecture | The specific configuration of the Azure region, including the number of availability zones and whether the region is paired with another region. |
| Synchronous replication | A data replication approach in which data is written and committed to multiple locations. Each location must acknowledge completion of the write operation before the overall write operation is considered complete. |
| Zonal (pinned) deployment | A deployment model in which a resource is deployed into a specific availability zone. |
| Zone-redundant deployment | A deployment model in which a resource is deployed across multiple availability zones. Microsoft manages data synchronization, traffic distribution, and failover if a zone experiences an outage. |
Key design strategies
Azure has a large global footprint. An Azure region is a geographic perimeter that contains a set of datacenters. You need to have a complete understanding of Azure regions and availability zones.
Azure regions have a variety of configurations, which are also called region architectures.
Many Azure regions provide availability zones, which are separated groups of datacenters. Within a region, availability zones are close enough to have low-latency connections to other availability zones, but they're far enough apart to reduce the likelihood that more than one will be affected by local outages or weather. Availability zones have independent power, cooling, and networking infrastructure. They're designed so that if one zone experiences an outage, then regional services, capacity, and high availability are supported by the remaining zones.
The following diagram shows several example Azure regions. Regions 1 and 2 support availability zones.

If you deploy into an Azure region that contains availability zones, you can use multiple availability zones together. By using multiple availability zones, you can keep separate copies of your application and data within separate physical datacenters in a large metropolitan area.
There are two ways to use availability zones in a solution:
- Zonal resources are pinned to a specific availability zone. You can combine multiple zonal deployments across different zones to meet high reliability requirements. You're responsible for managing data replication and distributing requests across zones. If an outage occurs in a single availability zone, you're responsible for failover to another availability zone.
- Zone-redundant resources are spread across multiple availability zones. Microsoft manages spreading requests across zones and the replication of data across zones. If an outage occurs in a single availability zone, Microsoft manages failover automatically.
Azure services support one or both of these approaches. Platform as a service (PaaS) services typically support zone-redundant deployments. Infrastructure as a service (IaaS) services typically support zonal deployments. For more information about how Azure services work with availability zones, see Azure services with availability zone support.
When Microsoft deploys updates to services, we try to use approaches that are the least disruptive to you. For example, we aim to deploy updates to a single availability zone at a time. This approach can reduce the impact that updates might have on an active workload, because the workload can continue to run in other zones while the update is in process. However, it’s ultimately the workload team’s responsibility to ensure their workload continues to function during platform upgrades. For example, when you use virtual machine scale sets with the flexible orchestration mode, or most Azure PaaS services, Azure intelligently places your resources to reduce the impact of platform updates. Additionally, you might consider overprovisioning - deploying more instances of a resource - so that some instances remain available while other instances are upgraded. For more information about how Azure deploys updates, see Advancing safe deployment practices.
Many regions also have a paired region. Paired regions support certain types of multi-region deployment approaches. Some newer regions have multiple availability zones and don't have a paired region. You can still deploy multi-region solutions into these regions, but the approaches you use might be different.
For more information about how Azure uses regions and availability zones, see What are Azure regions and availability zones?
Understand shared responsibilities
The shared responsibility principle describes how responsibilities are divided between the cloud provider (Microsoft) and you. Depending on the type of services you use, you might take on more or less responsibility for operating the service.
Microsoft provides availability zones and regions to give you flexibility in how you design your solution to meet your requirements. When you use managed services, Microsoft takes on more of the management responsibilities for your resources, which might even include data replication, failover, failback, and other tasks related to operating a distributed system.
Your own code needs to recommended practices and design patterns for handling failures gracefully. These practices are even more important during failover operations, such as those that happen when an availability zone or region failover occurs, because failover between zones or regions usually requires that your application retry connections to services.
Identify key business and workload requirements
To make an informed decision about how to use availability zones and regions in your solution, you need to understand your requirements. These requirements should be driven by discussions between solution designers and business stakeholders.
Risk tolerance
Different organizations have different degrees of risk tolerance. Even within an organization, risk tolerance is often different for each workload. Most workloads don't need extremely high availability. However, some workloads are so important that it's even worth mitigating risks that are unlikely to occur, like major natural disasters that affect a wide geographic area.
This table lists a few of the common risks that you should consider in a cloud environment:
| Risk | Examples | Likelihood |
|---|---|---|
| Hardware outage | Problem with hard disk or networking equipment. Host reboots. |
High. Any resiliency strategy should account for these risks. |
| Datacenter outage | Power, cooling, or network failure across an entire datacenter. Natural disaster in one part of a metropolitan area. |
Medium |
| Region outage | Major natural disaster that affects a wide geographical area. Network or service problem that makes one or more Azure services unavailable in an entire region. |
Low |
It would be ideal to mitigate every possible risk for every workload, but it's not practical or cost effective to do so. It's important to have an open discussion with business stakeholders so you can make informed decisions about the risks that you should mitigate.
Tip
Regardless of reliability targets, all workloads must have some mitigation for disaster recovery. If your workload demands high reliability targets, then your mitigation strategies should be comprehensive and you should reduce the risk of even low-likelihood events. For other workloads, make an informed decision on which risks you’re prepared to accept and which you need to mitigate.
Resiliency requirements
It's important to understand the resiliency requirements for your workload, including the recovery time objective (RTO) and recovery point objective (RPO). These objectives help you decide which approaches to rule out. If you don't have clear requirements, you can't make an informed decision about which approach to follow. For more information, see Target functional and nonfunctional requirements.
Service-level objectives
You should understand your solution's expected uptime service-level objective (SLO). For example, you might have a business requirement that your solution needs to meet 99.9% uptime.
Azure provides service level agreements (SLAs) for each service. An SLA indicates the level of uptime you should expect from the service and the conditions you need to meet to achieve that expected SLA. However, remember that the way that an Azure SLA indicates the service's availability doesn't always match the way you consider the health of your workload.
Your architectural decisions affect your solution's composite SLO. In general, the more redundancy you build into your solution, the higher your SLO is likely to be. Many Azure services provide higher SLAs when you deploy services in a zone-redundant or multi-region configuration. Review the SLAs for each of the Azure services you use to ensure that you understand how to maximize the resiliency and SLA of the service.
Data residency
Some organizations place restrictions on the physical locations into which their data can be stored and processed. Sometimes these requirements are based on legal or regulatory standards. In other situations, an organization might decide to adopt a data residency policy to avoid customer concerns. If you have strict data residency requirements, you might need to use a single-region deployment or use a subset of Azure regions and services.
Note
Avoid making unfounded assumptions about your data residency requirements. If you need to comply with specific regulatory standards, verify what those standards actually specify.
User location
By understanding where your users are located, you can make an informed decision about how to optimize latency and reliability for your needs. Azure provides many options to support a geographically dispersed user base.
If your users are concentrated in one area, a single-region deployment can simplify your operational requirements and reduce your costs. However, you need to consider whether a single-region deployment meets your reliability requirements. For mission-critical applications, you should still use a multi-region deployment even if your users are colocated.
If your users are geographically dispersed, it might make sense to deploy your workload across multiple regions. Azure services provide different capabilities to support a multi-region deployment, and you can use Azure's global footprint to improve your user experience and bring your applications into closer proximity to your user base. You might use the Deployment Stamps pattern or the Geodes pattern, or replicate your resources across multiple regions.
Even if your users are in different geographical areas, consider whether you need a multi-region deployment. Consider whether you can achieve your requirements within a single region by using global traffic acceleration, like the acceleration provided by Azure Front Door.
Budget
If you operate under a constrained budget, it's important to consider the costs involved in deploying redundant workload components. These costs can include additional resource charges, networking costs, and the operational costs of managing more resources and a more complex environment.
Complexity
It's a good practice to avoid unnecessary complexity in your solution architecture. The more complexity you introduce, the harder it becomes to make decisions about your architecture. Complex architectures are harder to operate, harder to secure, and often less performant. Follow the principle of simplicity.
Azure facilitation
By providing regions and availability zones, Azure enables you to select a deployment approach that fits your needs. There are many approaches that you can choose from, each of which provides benefits and incurs costs.
To illustrate the deployment approaches that you can use, consider an example scenario. Suppose you're thinking about deploying a new solution that includes an application that writes data to some sort of storage:

This example isn't specific to any particular Azure services. It's intended to provide a simple example for illustrating fundamental concepts.
There are multiple ways to deploy this solution. Each approach provides a different set of benefits and incurs different costs. At a high level, you can consider a locally redundant, zonal (pinned), zone-redundant, or multi-region deployment. This table summarizes some of the pillar concerns:
| Pillar | Locally redundant | Zonal (pinned) | Zone-redundant | Multi-region |
|---|---|---|---|---|
| Reliability | Low reliability | Depends on approach | High or very high reliability | High or very high reliability |
| Cost Optimization | Low cost | Depends on approach | Moderate cost | High cost |
| Performance Efficiency | Acceptable performance (for most workloads) | High performance | Acceptable performance (for most workloads) | Depends on approach |
| Operational Excellence | Low operational requirements | High operational requirements | Low operational requirements | High operational requirements |
This table summarizes some of the approaches you can use and how they affect your architecture:
| Architectural concern | Locally redundant | Zonal (pinned) | Zone-redundant | Multi-region |
|---|---|---|---|---|
| Compliance with data residency | High | High | High | Depends on region |
| Regional availability | All regions | Regions with availability zones | Regions with availability zones | Depends on region |
The rest of this article describes each of the approaches listed in the preceding table. The list of approaches isn't exhaustive. You might decide to combine multiple approaches or use different approaches in different parts of your solution.
Deployment approach 1: Locally redundant deployments
If you don't specify multiple availability zones or regions when you deploy your resources, Azure doesn't make any guarantees about whether the resources are deployed into a single datacenter or split across multiple datacenters in the region. In some situations, Azure might also move your resource between availability zones.

Most Azure resources are highly available by default, with high SLAs and built-in redundancy within a datacenter that's managed by the platform. However, from a reliability perspective, if any part of the region experiences an outage, there's a chance that your workload might be affected. If it is, your solution might be unavailable, or your data could be lost.
For highly latency-sensitive workloads, this approach might also result in lower performance. Your workload components might not be colocated in the same datacenter, so you might observe some latency for intra-region traffic. Azure might also transparently move your service instances between availability zones, which might slightly affect performance. However, this isn't a concern for most workloads.
This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | Low reliability. Services are subject to outages if a datacenter fails. You can, however, build an application to be resilient to other types of failures. |
| Cost Optimization | Lowest cost. You only need to have a single instance of each resource, and you don't incur any inter-region bandwidth costs. |
| Performance Efficiency | For most workloads: Acceptable performance. This approach is likely to provide satisfactory performance. For highly latency-sensitive workloads: Low performance. Components aren't guaranteed to be located in the same availability zone, so you might see lower performance for highly latency-sensitive components. |
| Operational Excellence | High operational efficiency. You only need to deploy and manage a single instance of each resource. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | High. When you deploy a solution that uses this approach, data is stored in the Azure region that you select. |
| Regional availability | High. This approach can be used in any Azure region. |
Locally redundant deployments with backup across regions
You can extend a locally redundant deployment by performing regular backups of your infrastructure and data to a secondary region. This approach adds an extra layer of protection to mitigate against an outage in your primary region. Here's what it looks like:

When you implement this approach, you need to carefully consider your RTO and RPO:
- Recovery time: If a regional outage occurs, you might need to rebuild your solution in another Azure region, which affects your recovery time. Consider building your solution by using an infrastructure-as-code (IaC) approach so that you can quickly redeploy into another region if a major disaster occurs. Ensure that your deployment tools and processes are just as resilient as your applications so that you can use them to redeploy your solution even if there's an outage. Plan for and rehearse the steps that are required to restore your solution back to a working state.
- Recovery point: Your backup frequency determines the amount of data loss that you might experience (your recovery point). You can typically control the frequency of backups so that you can meet your RPO.
This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | Moderate reliability. Services are subject to outages if a datacenter fails. Data is backed up asynchronously to a geographically separated region, which reduces the effect of a full region outage by minimizing data loss. In a full region outage, you can manually restore operations into another region. However, recovery processes can be complex, and it can take time to manually restore into the other region. |
| Cost Optimization | Low cost. Typically, adding a backup to another region costs only slightly more than deploying a locally redundant resource. |
| Performance Efficiency | For most workloads: Acceptable performance. This approach is likely to provide satisfactory performance. For highly latency-sensitive workloads: Low performance. Components aren't guaranteed to be located in the same availability zone, so you might see lower performance for highly latency-sensitive components. |
| Operational Excellence | During any outage within a region: Low operational efficiency. Failover is your responsibility and might require manual operations and redeployments. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | Depends on region selection. Data is primarily stored in the Azure region that you specify. However, you need to select another region to store your backups, so it's important that you select a region that's compatible with your data residency requirements. |
| Regional availability | High. You can use this approach in any Azure region. |
Deployment approach 2: Zonal (pinned) deployments
In a zonal deployment, you specify that your resources should be deployed to a specific availability zone. This approach is sometimes called a zone-pinned deployment.
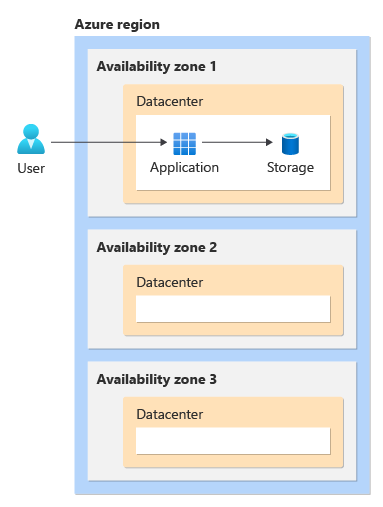
A zonal approach reduces the latency between your components. However, by itself, it doesn't increase the resiliency of your solution. To increase your resiliency, you need to deploy multiple instances of your components into multiple availability zones and decide how to route traffic between each instance. This example shows an active-passive traffic routing approach:

In the previous example, a load balancer is deployed across multiple availability zones. It's important to consider how you route traffic between instances in different availability zones, because a zone outage might also affect the networking resources deployed into that zone. You might also consider using a global load balancer, like Azure Front Door or Azure Traffic Manager, which isn't deployed into a region at all.
When you use a zonal deployment model, you take on many responsibilities:
- You need to deploy resources to each availability zone, and configure and manage those resources individually.
- You need to decide how and when to replicate data between the availability zones, and then configure and manage the replication.
- You're responsible for distributing the requests to the correct resources, by using, for example, a load balancer. You need to ensure that the load balancer meets your resiliency requirements. You also need to decide whether to use an active-passive or an active-active request distribution model.
- If an availability zone experiences an outage, you need to handle the failover to send traffic to resources in another availability zone.
An active-passive deployment across multiple availability zones is sometimes called in-region DR or Metro DR.
This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | When deployed in a single availability zone: Low reliability. A zonal deployment doesn't provide any resiliency to an outage in a datacenter or availability zone. You must deploy redundant resources across multiple availability zones to achieve high resiliency. When deployed in multiple availability zones: High reliability. Services can be made resilient to a datacenter or availability zone outage. |
| Cost Optimization | When deployed in a single availability zone: Low cost. A single-zone deployment requires only a single instance of each resource. When deployed in multiple availability zones: High cost. You deploy multiple instances of the resources, each of which are billed separately. |
| Performance Efficiency | High performance. Latency can be very low when the components that serve a request are located in the same availability zone. |
| Operational Excellence | Low operational efficiency. You need to configure and manage multiple instances of your service. You need to replicate data between availability zones. During an availability zone outage, failover is your responsibility. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | High. When you deploy a solution that uses this approach, data is stored in the Azure region that you select. |
| Regional availability | Regions with availability zones. This approach is available in any region that supports availability zones. |
This approach is typically used for workloads that are based on virtual machines. For a complete list of services that support zonal deployments, see Availability zone service and regional support.
When you plan a zonal deployment, verify that the Azure services you use are supported in the availability zones you plan to use. For example, to list which virtual machine SKUs are available in each availability zone, see Check VM SKU availability.
Tip
When you deploy a resource into a specific availability zone, you select the zone number. The sequence of zone numbers is different for each Azure subscription. If you deploy resources across multiple Azure subscriptions, verify the zone numbers that you should use in each subscription. For more information, see Physical and logical availability zones.
Deployment approach 3: Zone-redundant deployments
When you use this approach, your application tier is spread across multiple availability zones. When requests arrive, a load balancer that's built into the service (which itself spans availability zones) disperses the requests across the instances in each availability zone. If an availability zone experiences an outage, the load balancer directs traffic to instances in the healthy availability zones.
Your storage tier is also spread across multiple availability zones. Copies of your application's data are distributed across multiple availability zones via synchronous replication. When the application makes a change to data, the storage service writes the change to multiple availability zones, and the transaction is considered complete only when all of these changes are complete. This process ensures that each availability zone always has an up-to-date copy of the data. If an availability zone experiences an outage, another availability zone can be used to access the same data.

A zone-redundant approach increases your solution's resiliency to issues like datacenter outages. Because data is replicated synchronously, however, your application has to wait for the data to be written across multiple separate locations that might be in different parts of a metropolitan area. For most applications, the latency involved in inter-zone communication is negligible. However, for some highly latency-sensitive workloads, synchronous replication across availability zones might affect the application's performance.
This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | High reliability. Services are resilient to an outage of a datacenter or availability zone. Data is synchronously replicated across availability zones and with no delay. |
| Cost Optimization | Moderate cost. Depending on the services you use, you might incur some costs for higher service tiers to enable zone redundancy. |
| Performance Efficiency | For most workloads: Acceptable performance. This approach is likely to provide satisfactory performance. For highly latency-sensitive workloads: Low performance. Some components might be sensitive to latency due to inter-zone traffic or data replication time. |
| Operational Excellence | High operational efficiency. You typically need to manage only a single logical instance of each resource. For most services, during an availability zone outage, failover is the responsibility of Microsoft and happens automatically. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | High. When you deploy a solution that uses this approach, data is stored in the Azure region that you select. |
| Regional availability | Regions with availability zones. This approach is available in any region that supports availability zones. |
This approach is possible with many Azure services, including Azure Virtual Machine Scale Sets, Azure App Service, Azure Functions, Azure Kubernetes Service, Azure Storage, Azure SQL, Azure Service Bus, and many others. For a complete list of services that support zone redundancy, see Availability zone service and regional support.
Zone-redundant deployments with backup across regions
You can extend a zone-redundant deployment by performing regular backups of your infrastructure and data to a secondary region. This approach gives you the benefits of a zone-redundant approach and adds a layer of protection to mitigate the extremely unlikely event of a full region outage.

When you implement this approach, you need to carefully consider your RTO and RPO:
Recovery time: If a regional outage does occur, you might need to rebuild your solution in another Azure region, which affects your recovery time. Consider building your solution by using an IaC approach so that you can quickly redeploy into another region during a major disaster. Ensure that your deployment tools and processes are just as resilient as your applications so that you can use them to redeploy your solution even if an outage occurs. Plan for and rehearse the steps required to restore your solution back to a working state.
Recovery point: Your backup frequency determines the amount of data loss that you might experience (your recovery point). You can typically control the frequency of backups to meet your RPO.
Tip
This approach often provides a good balance for all architectural concerns. If you aren't sure which approach to use, start with this type of deployment.
This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | Very high reliability. Services are resilient to an outage of a datacenter or availability zone. For most services, data is replicated across zones automatically and with no delay. Data is backed up asynchronously to a geographically separated region. This backup reduces the effect of a full region outage by minimizing data loss. After a full region outage, you can manually restore operations into another region. However, recovery processes can be complex, and it can take time to manually restore into the other region. |
| Cost Optimization | Moderate cost. Typically, adding a backup to another region costs only slightly more than implementing zone redundancy. |
| Performance Efficiency | For most workloads: Acceptable performance. This approach is likely to provide satisfactory performance. For highly latency-sensitive workloads: Low performance. Some components might be sensitive to latency due to inter-zone traffic or data replication time. |
| Operational Excellence | During an availability zone outage: High operational efficiency. Failover is the responsibility of Microsoft and happens automatically. During a regional outage: Low operational efficiency. Failover is your responsibility and might require manual operations and redeployments. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | Depends on region selection. Data is stored primarily in the Azure region that you specify, but you need to select another region to store your backups. Select a region that's compatible with your data residency requirements. |
| Regional availability | Regions with availability zones. This approach is available in any region that supports availability zones. |
Deployment approach 4: Multi-region deployments
You can use multiple Azure regions together to distribute your solution across a wide geographical area. You can use this multi-region approach to improve your solution's reliability or to support geographically distributed users. By deploying into multiple regions, you also reduce the risk that you'll encounter a temporary resource capacity constraint in a single region. If data residency is an important concern for your solution, carefully consider which regions you use to ensure that your data is stored only in locations that meet your requirements.
Active and passive regions
Multi-region architectures are complex, and there are many ways to design a multi-region solution. For some workloads, it makes sense to have multiple regions actively processing requests simultaneously (active-active deployments). For other workloads, it's better to designate one primary region and use one or more secondary regions for failover (active-passive deployments). This section focuses on the second scenario, in which one region is active and another is passive. For information about active-active multi-region solutions, see Deployment Stamps pattern and Geode pattern.
Data replication
Communicating across regions is much slower than communicating within a region. In general, a larger geographic distance between two regions incurs more network latency because of the longer physical distance that data needs to travel. See Azure network round-trip latency statistics for the expected network latency when you connect between two regions.
Cross-region network latency can significantly affect your solution design because you need to carefully consider how the extra latency affects data replication and other transactions. For many solutions, a cross-region architecture requires asynchronous replication to minimize the effect of cross-region traffic on performance.
Asynchronous data replication
When you implement asynchronous replication across regions, your application doesn't wait for all regions to acknowledge a change. After the change is committed in the primary region, the transaction is considered complete. The change is replicated to the secondary regions at a later time. This approach ensures that inter-region connection latency doesn't directly affect application performance. However, because of the delay in replication, a region-wide outage might result in some data loss. This data loss can occur because a region might experience an outage after a write is completed in the primary region but before the change could be replicated to another region.

This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | High reliability. The solution is resilient to an outage of a datacenter, an availability zone, or an entire region. Data is replicated but might not be synchronous, so some data loss is possible in a failover scenario. |
| Cost Optimization | High cost. You need to deploy separate resources in each region, and each resource incurs deployment and maintainenance costs. Data replication across regions might also incur significant costs. |
| Performance Efficiency | High performance. Application requests don't require cross-region traffic, so traffic is typically low latency. |
| Operational Excellence | Low operational efficiency. You need to deploy and manage resources across multiple regions. You're also responsible for failover between regions during a regional outage. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | Depends on region selection. This approach requires you to select multiple regions for your workload to run in. Choose regions that are compatible with your data residency requirements. |
| Regional availability | Many Azure regions are paired. Some Azure services use paired regions to replicate data automatically. If you run your workload in a region that doesn't have a pair, you might need to use a different approach to replicate your data. |
Synchronous data replication
If you implement a synchronous multi-region solution, your application needs to wait for write operations to complete in each Azure region before the transaction is considered complete. The latency incurred by waiting for write operations depends on the distance between the regions. For many workloads, inter-region latency can make synchronous replication too slow to be useful.

This table summarizes some of the pillar concerns:
| Pillar | Impact |
|---|---|
| Reliability | Very high reliability. The solution is resilient to an outage of a datacenter, an availability zone, or an entire region. Data is always in sync across regions, so, even if a complete region loss occurs, your data is available and complete in another region. |
| Cost Optimization | High cost. You need to deploy separate resources in each region, and each resource incurs deployment and maintainenance costs. Data replication across regions might also incur significant costs. |
| Performance Efficiency | Low performance. Application requests require cross-region traffic. Depending on the distance between the regions, synchronous replication might add significant latency to requests. |
| Operational Excellence | Low operational efficiency. You need to deploy and manage resources across multiple regions. You're also responsible for failover between regions during a regional outage. |
This table summarizes some of the concerns from an architectural perspective:
| Architectural concern | Impact |
|---|---|
| Compliance with data residency | Depends on region selection. This approach requires you to select multiple regions for your workload to run in. Select regions that are compatible with your data residency requirements. |
| Regional availability | Many Azure regions are paired. Some Azure services use paired regions to replicate data automatically. If you run your workload in a region that doesn't have a pair, you might need to use a different approach to replicate your data. |
Region architectures
When you design a multi-region solution, consider whether the Azure regions you plan to use are paired.
You can create a multi-region solution even when the regions aren't paired. However, the approaches that you use to implement a multi-region architecture might be different. For example, in Azure Storage, you can use geo-redundant storage (GRS) with paired regions. If GRS isn't available, consider using features like Azure Storage object replication, or design your application to write to multiple regions.
Combine multi-zone and multi-region approaches
You should combine multi-zone and multi-region statements if your business requirements demand such a solution. For example, you might deploy zone-redundant components into each region and also configure replication between the regions. For some solutions, this approach provides a very high degree of reliability. However, configuring this type of approach can be complicated, and this approach can be expensive.
Important
Mission-critical workloads should use both multiple availability zones and multiple regions. For more information about the considerations that you should give when designing mission-critical workloads, see Mission-critical workload documentation.
How Azure services support deployment approaches
It's important to understand the specific details of the Azure services that you use. For example, some Azure services require that you configure their availability zone configuration when you first deploy the resource, while others support changing the deployment approach later. Similarly, some service features might not be available with every deployment approach.
To learn more about the specific deployment options and approaches to consider for each Azure service, visit the Reliability hub.
Examples
This section describes some common use cases and the key requirements that you typically need to consider for each workload. For each workload, one or more suggested deployment approaches are provided, based on the requirements and approaches described in this article.
Line-of-business application for an enterprise
Contoso, Ltd., is a large manufacturing company. The company is implementing a line-of-business application to manage some components of its financial processes.
Business requirements: The information that the system manages is difficult to replace, so data needs to be persisted reliably. The architects say that the system needs to incur as little downtime and as little data loss as possible. Contoso's employees use the system throughout the workday, so high performance is important to avoid keeping team members waiting. Cost is also a concern, because the finance team has to pay for the solution.
Suggested approach: Zone-redundant deployment with backup across regions provides multiple layers of resiliency with high performance.
Internal application
Fourth Coffee is a small business. The company is developing a new internal application that employees can use to submit timesheets.
Business requirements: For this workload, cost efficiency is a primary concern. Fourth Coffee evaluated the business impact of downtime and decided that the application doesn't need to prioritize resiliency or performance. The company accepts the risk that an outage in an Azure availability zone or region might make the application temporarily unavailable.
Suggested approaches:
- Locally redundant deployment with backups across regions has the lowest cost, but also has significant risks.
- Zone-redundant deployment with backup across regions provides better resiliency, but at a slightly higher cost.
Legacy application migration
Fabrikam, Inc., is migrating a legacy application from an on-premises datacenter to Azure. The implementation will use an IaaS approach that's based on virtual machines. The application wasn't designed for a cloud environment, and communication between the application tier and the database is very chatty.
Business requirements: Performance is a priority for this application. Resiliency is also important, and the application must continue to work even if an Azure datacenter experiences an outage.
Suggested approach:
- Fabrikam should first try a zone-redundant deployment. They should verify the performance meets their requirements.
- If the performance of the zone-redundant solution isn't acceptable, consider a zonal (pinned) deployment, with passive deployments across multiple availability zones (in-region DR).
Healthcare application
Lamna Healthcare Company is implementing a new electronic health record system on Azure.
Business requirements: Because of the nature of the data that this solution stores, data residency is critically important. Lamna operates under a strict regulatory framework that mandates that data must remain in a specific location.
Suggested approaches:
- Multi-zone multi-region deployment, if there are multiple regions that fit Lamna's data residency requirements.
- If there's only a single region that suits their needs, consider a zone-redundant deployment or a zone-redundant deployment with backup across regions provides a single-region solution
Banking system
Woodgrove Bank runs its core banking operations from a large solution that's deployed to Azure.
Business requirements: This is a mission-critical system. Any outages can cause major financial impact for customers. As a result, Woodgrove Bank has very low risk tolerance. The system needs the highest level of reliability possible, and the architecture needs to mitigate the risk of any failures that can be mitigated.
Suggested approach: For a mission-critical system, use a multi-zone multi-region deployment. Ensure that the regions fit the company's data residency requirements.
Software as a service (SaaS)
Proseware, Inc., builds software that's used by companies across the world. The company's user base is widely distributed geographically.
Business requirements: Proseware needs to enable each of its customers to choose a deployment region that's close to the customer. Enabling this choice is important for latency and for the customers' data residency requirements.
Suggested approaches:
- A multi-zone multi-region deployment is typically a good choice for a SaaS provider, especially when it's used within the Deployment Stamps pattern.
- A single-region zone-redundant deployment in conjunction with a global traffic acceleration solution, like Azure Front Door.
Related links
Following are some reference architectures and example scenarios for multi-zone and multi-region solutions:
- Baseline highly available zone-redundant web application
- Highly available multi-region web application
- Multi-region N-tier application
- Multi-tier web application built for HA/DR
Many Azure services provide guidance about how to use multiple availability zones, including the following examples:
- Azure Site Recovery: Enable Azure VM disaster recovery between availability zones
- Azure NetApp Files: Understand cross-zone replication of Azure NetApp Files
- Azure Storage redundancy
Reliability checklist
Refer to the complete set of recommendations.