Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Fabric Runtime tarjoaa saumattoman integraation Microsoft Fabricin ekosysteemissä, tarjoten vahvan ympäristön data-insinööri- ja data-analytiikkaprojekteille, joita tukee Apache Spark.
Tässä artikkelissa esitellään Fabric Runtime 2.0 Public Preview, uusin Microsoft Fabricin big data -laskentaan suunniteltu ajonaikainen. Se korostaa keskeisiä ominaisuuksia ja komponentteja, jotka tekevät tästä julkaisusta merkittävän askeleen eteenpäin skaalautuvan analytiikan ja edistyneiden työkuormien saralla.
Fabric Runtime 2.0 sisältää seuraavat komponentit ja päivitykset, jotka on suunniteltu parantamaan datankäsittelykykyäsi:
- Apache Spark 4.1
- Käyttöjärjestelmä: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Scala: 2.13
- Python: 3.13
- Delta-järvi: 4,2
- R: 4.5.2
Tärkeää
Microsoft Fabric -tiimi julkaisee päivityksen Microsoft Fabric Runtime 2.0:aan. Osana tätä päivitystä Python-päivitys tuo mukanaan murskaavan muutoksen asiakkaille, jotka käyttävät ympäristöartefakteja python- ja pyöräkirjastoilla. Asiakkaat näkevät yhden kahdesta virheilmoituksesta Notebook- tai Spark Job Definition (SJD) -suorituksen yhteydessä:
- Virhe: varoitus: 1 vanhentuminen (vuodesta 2.13.0); lisätietoja varten, ota käyttöön
:setting -deprecationtai:replay -deprecationlähde: SparkCoreService. - "LibraryManagementError": "Perus-Spark Python -ympäristön päivitys on havaittu. Julkaise ympäristö uudelleen.|UserError"
Vaaditut toimenpiteet
Julkaise ympäristösi uudelleen (mukaan lukien kirjastot). Tätä varten poista kaikki kirjastot, julkaise ympäristö, lisää kaikki kirjastot uudelleen ja julkaise uudelleen. Tämä prosessi luo ympäristön uudelleen käyttämällä päivitettyä Python-ajonaikaa ja ratkaisee ongelman.
Vinkki
Fabric Runtime 2.0 sisältää tuen Native Execution Enginelle, joka voi merkittävästi parantaa suorituskykyä ilman lisäkustannuksia. Voit ottaa natiivisuoritusmoottorin käyttöön ympäristötasolla, jolloin kaikki työt ja muistikirjat perivät automaattisesti parannetut suorituskykyominaisuudet.
Ota käyttöön Runtime 2.0
Voit ottaa Runtime 2.0:n käyttöön joko työtilan tasolla tai ympäristön kohdetasolla. Käytä työtilan asetusta soveltaaksesi Runtime 2.0:aa oletusarvona kaikille Spark-työkuormille työtilassasi. Vaihtoehtoisesti voit luoda ympäristökohteen Runtime 2.0:lla käytettäväksi tiettyjen muistikirjojen tai Spark-työn määritelmien kanssa, joka ohittaa työtilan oletusarvon.
Ota Runtime 2.0 käyttöön Workspace-asetuksissa
Asetetaan Runtime 2.0 oletuseksi koko työtilallesi:
Siirry Workspace-asetuksiin Fabric-työtilassasi.
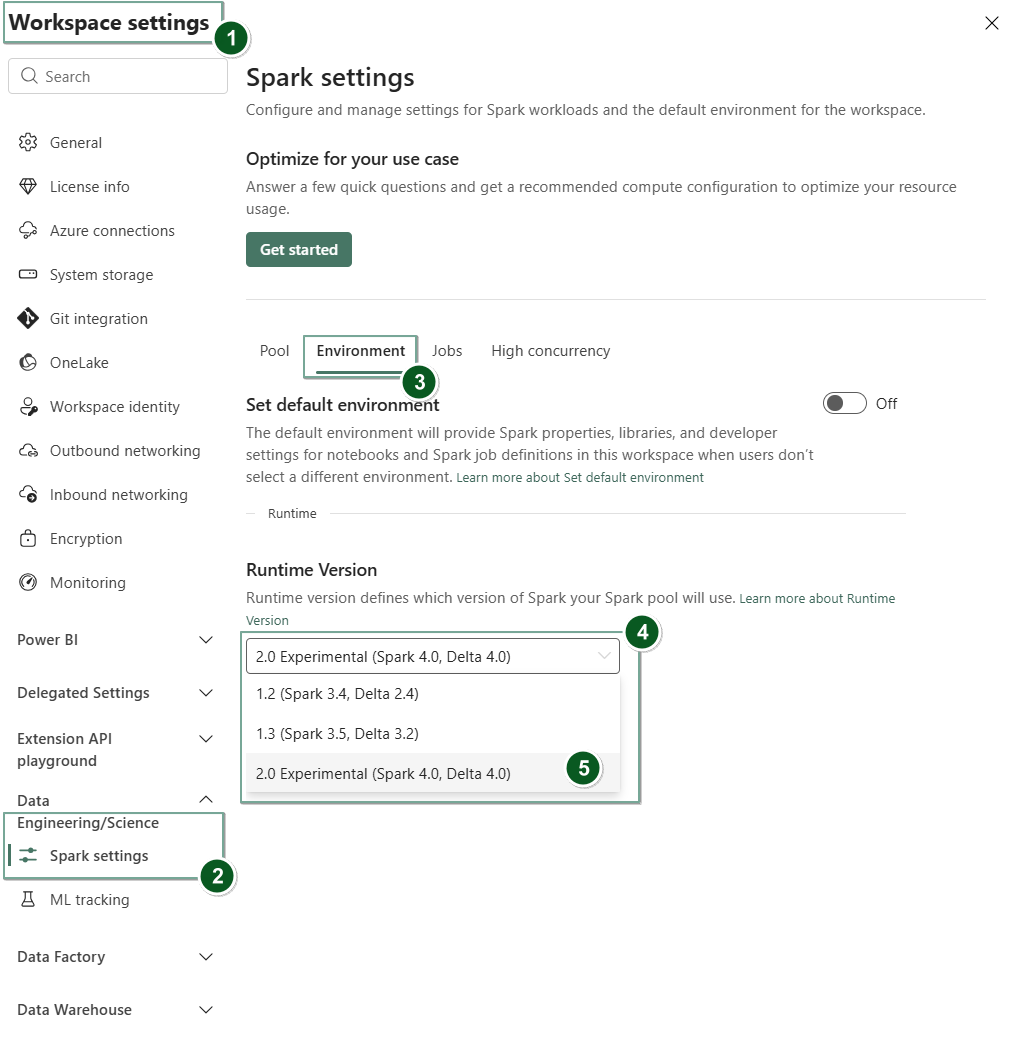
Valitse Data Engineering/Science -välilehti ja valitse sitten Spark settings.
Valitse Ympäristö-välilehti .
Runtime-version pudotusvalikosta valitse 2.0 Public Preview (Spark 4.1, Delta 4.2) ja tallenna muutoksesi.
Runtime 2.0 on asetettu oletusajonaikaksi työtilallesi.

Ota käyttöön Runtime 2.0 Ympäristö-kohteessa
Käyttääksesi Runtime 2.0:aa tiettyjen muistikirjojen tai Spark-tehtävämääritelmien kanssa:
Luo uusi Ympäristö-kohde tai avaa olemassa oleva.
Runtime-pudotusvalikosta valitse 2.0 Public Preview (Spark 4.1, Delta 4.2),tallenna ja Julkaise muutoksesi.
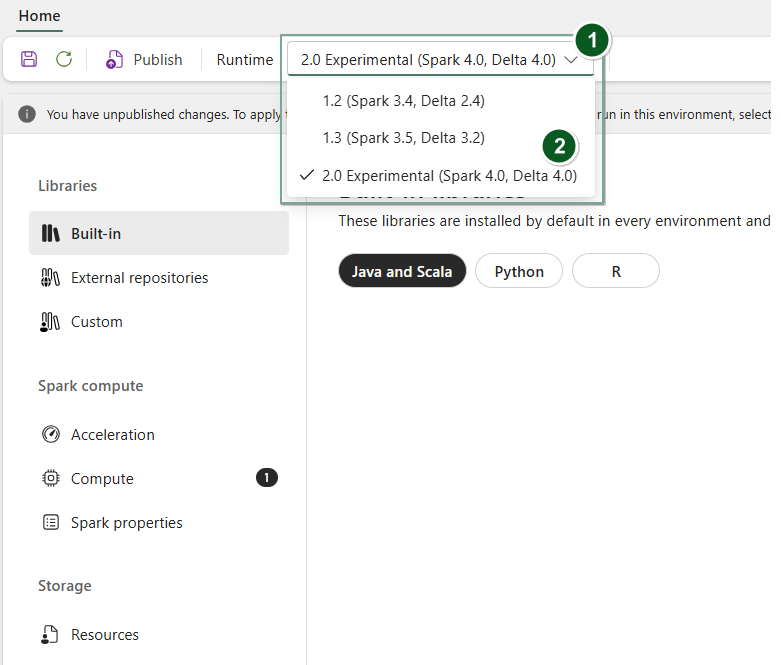
Seuraavaksi voit käyttää tätä Ympäristö-elementtiä muistikirjan tai Spark-tehtävämäärittelyn kanssa.

Nyt voit alkaa kokeilla Fabric Runtime 2.0:n uusimpia parannuksia ja toimintoja (Spark 4.1 ja Delta Lake 4.2).
Julkinen esiversio
Fabric Runtime 2.0:n julkinen esikatseluvaihe antaa pääsyn uusiin ominaisuuksiin ja API:iin sekä Spark 4.1:stä että Delta Lake 4.2:sta. Esikatselu antaa sinun käyttää uusimmat Spark- ja Delta-pohjaiset parannukset heti sekä varmistaa sujuvan valmiuden ja siirtymän parannetuille muutoksille, kuten uudemmille Java-, Scala- ja Python-versioille.
Vinkki
Saat ajan tasalla olevat tiedot, yksityiskohtaisen luettelon muutoksista ja Fabric-suorituspalvelun erityisistä julkaisutiedoista tarkistamalla Spark Runtimes -julkaisut ja -päivitykset ja tilaamalla ne.
Tärkeimmät tiedot
Suorituskyvyn ja suoritusmoottorin parannukset
Fabric Runtime 2.0 sisältää Native Execution Enginen, joka tarjoaa merkittäviä suorituskyvyn parannuksia avoimen lähdekoodin Spark-ohjelmistoon verrattuna. Moottori käyttää vektoroitua käsittelyä nopeuttaakseen Spark-kyselyitä järvenrakennusinfrastruktuurissa ilman, että koodimuutoksia tarvitaan.
Keskeiset suorituskykyominaisuudet Runtime 2.0:ssa:
- Jopa kuusi kertaa nopeampia: Testit näyttävät jopa kuusi kertaa nopeampaa suorituskykyä verrattuna avoimen lähdekoodin Sparkiin TPC-DS työkuormissa.
- Vektoroitu CSV-jäsennys: Natiivisuoritusmoottori sisältää vektoroidun CSV-jäsentimen, joka nopeuttaa CSV:n vastaanottoa ja kyselykuormia. Vektoroitu JSON-jäsennys ja Spark Structured Streaming -tuki ovat suunnitteilla tulevia päivityksiä varten.
Natiivin suoritusmoottorin ottamiseksi käyttöön katso Fabric Data Engineeringin natiivisuoritusmoottori.
Apache Spark 4.1
Apache Spark 4.0 merkitsi merkittävää virstanpylvästä 4.x-sarjan ensimmäisenä julkaisuna, ilmentäen elävän avoimen lähdekoodin yhteisön yhteistä ponnistusta. Fabric Runtime 2.0 toimii nyt Apache Spark 4.1 -pohjalla, joka rakentaa tätä pohjaa lisäparannuksilla.
Tässä versiossa Spark SQL on merkittävästi rikastettu tehokkailla uusilla ominaisuuksilla, jotka on suunniteltu lisäämään SQL-työkuormien ilmaisukykyä ja monipuolisuutta, kuten VARIANT-tietotyyppien tuki, SQL-käyttäjän määrittelemät funktiot, istuntomuuttujat, putkisyntaksi ja merkkijonojen kokoaminen. PySpark sitoutuu jatkuvasti sekä toiminnalliseen laajuuteen että kehittäjäkokemukseen, tuoden mukanaan natiivin piirto-API:n, uuden Python Data Source API:n, tuen Python UDTF:ille ja yhtenäisen profiloinnin PySpark UDF:ille sekä lukuisia muita parannuksia. Strukturoitu suoratoisto kehittyy tärkeiden lisäysten myötä, jotka tarjoavat paremman hallinnan ja helpomman virheenkorjauksen, erityisesti Arbitrary State API v2:n käyttöönoton myötä joustavampaan tilanhallintaan sekä State Data Sourcen myötä helpompaan virheenkorjaukseen.
Voit tarkistaa koko listan ja yksityiskohtaiset muutokset täältä:
Note
Spark 4.x:ssä SparkR on vanhentunut ja se voidaan poistaa tulevassa versiossa.
Delta Lake 4.2
Delta Lake 4.2 rakentuu aiempien Delta Lake -julkaisujen pohjalle jatkaen sitoutumista tehdä Delta Lakesta yhteensopiva eri formaateissa, helpommin käsiteltävä ja suorituskykyisempi. Se sisältää tehokkaita uusia ominaisuuksia, suorituskyvyn optimointeja ja perustavanlaatuisia parannuksia avoimen datan järvenrakennusten tulevaisuudelle.
Koko lista ja yksityiskohtaiset muutokset, jotka on tehty Delta Lake 3.3:n, 4.0:n, 4.1:n ja 4.2:n myötä, katso:
Datan asettelu ja optimointi
Runtime 2.0 tukee datan asettelun ja optimointiominaisuuksia Delta-tauluille:
- Z-järjestys: Järjestä Delta-taulutiedostojen tiedot määriteltyjen sarakkeiden mukaan parantaaksesi suodatettujen kyselyiden suorituskykyä.
- Liquid Clustering: Joustava klusterointimenetelmä, joka optimoi datan asettelun automaattisesti ilman manuaalista ylläpitoa.
- Rinnakkainen Delta-snapshotin lataus: Natiivisuoritusmoottori lataa Delta-taulukon snapshotit rinnakkain, mikä lyhentää kyselyjen käynnistysaikaa suurille tauluille.
Tärkeää
Delta Lake 4.2:n erityisominaisuudet ovat kokeellisia ja toimivat vain Spark-kokemuksissa, kuten muistikirjoissa ja Spark-tehtävien määrittelyissä. Jos sinun täytyy käyttää samoja Delta Lake -taulukoita useissa Microsoft Fabricin työkuormissa, älä ota näitä ominaisuuksia käyttöön. Lisätietoja siitä, mitkä protokollaversiot ja ominaisuudet ovat yhteensopivia kaikissa Microsoft Fabric -kokemuksissa, löydät Delta Lake Table Format Interoperability.
Laskennan hallinta Runtime 2.0:ssa
Runtime 2.0 tukee seuraavia laskentahallinnan ominaisuuksia:
- Resurssiprofiilit: Määritä ennalta määritellyt resurssiallokaatiot Spark-istunnoille vastaamaan työkuormavaatimuksia ja hallitsemaan kustannuksia.
- Mukautetut live-poolit (esikatselu): Luo omistetut, esilämmitetyt Spark-poolit, jotka lyhentävät istuntojen käynnistysaikaa. Mukautetut live-poolit ovat saatavilla esikatselussa Runtime 2.0 -työkuormille.
Rajoitukset ja huomautukset
- Delta Lake 4.x -ominaispiirteet ovat kokeellisia ja toimivat vain Spark-kokemuksissa, kuten muistikirjoissa ja Spark-tehtävämääritteyksissä. Jos sinun täytyy käyttää samoja Delta Lake -tauluja useissa Fabric-työkuormissa, älä ota näitä ominaisuuksia käyttöön. Lisätietoja löytyy Delta Lake -taulukkomuotojen yhteentoimivuudesta.
- Runtime 2.0 on julkisessa esikatselussa. Jotkin ominaisuudet ja rajapinnat voivat muuttua ennen yleistä saatavuutta.
- Fabric Sparkin VS Code -laajennus tukee Runtime 2.0:aa kannettavan ja Sparkin työnmäärittelyn kehitykseen.