Opetusohjelma: Synthea-tietojoukon suhteiden etsiminen semanttisen linkin avulla
Tässä opetusohjelmassa kuvataan, miten voit tunnistaa yhteydet julkisessa Synthea-tietojoukossa semanttisen linkin avulla.
Kun käsittelet uusia tietoja tai työskentelet ilman aiemmin luotua tietomallia, voi olla hyödyllistä löytää suhteet automaattisesti. Tämän suhteen tunnistuksen avulla voit tehdä seuraavaa:
- ymmärtää mallia korkealla tasolla,
- saada lisää merkityksellisiä tietoja valmistelevan tietoanalyysin aikana,
- vahvistetaan päivitetyt tiedot tai uudet, saapuvat tiedot ja
- tietojen puhdistaminen.
Vaikka suhteita tiedettäisiin jo etukäteen, suhteiden etsiminen voi auttaa ymmärtämään tietomallia paremmin tai tunnistamaan tietojen laatuun liittyviä ongelmia.
Tässä opetusohjelmassa aloitat yksinkertaisella perusesimerkinnällä, jossa kokeillaan vain kolmea taulukkoa, jotta niiden välisiä yhteyksiä on helppo seurata. Sen jälkeen näytät monimutkaisemman esimerkin, jossa on suurempi taulukkojoukko.
Tässä opetusohjelmassa opit:
- Käytä semanttisen linkin Python-kirjaston (SemPy) komponentteja, jotka tukevat Power BI -integrointia ja auttavat tietojen analysoinnin automatisoinnissa. Näitä osia ovat seuraavat:
- FabricDataFrame – pandas-kaltainen rakenne, joka on parannettu semanttisten lisätietojen avulla.
- Funktiot semanttisten mallien hakemiseen Fabric-työtilasta muistikirjaan.
- Funktiot, jotka automatisoivat semanttisten mallien suhteiden etsimistä ja visualisointia.
- Semanttisten mallien suhteiden etsimisprosessin vianmääritys, jossa on useita taulukoita ja keskenään riippuvaisia.
Edellytykset
Hanki Microsoft Fabric -tilaus. Voit myös rekisteröityä ilmaiseen Microsoft Fabric -kokeiluversioon.
Siirry Synapse Data Science -käyttökokemukseen aloitussivun vasemmassa reunassa olevan käyttökokemuksen vaihtajan avulla.

- Etsi ja valitse työtila valitsemalla vasemmasta siirtymisruudusta Työtilat . Tästä työtilasta tulee nykyinen työtilasi.
Seuraa mukana muistikirjassa
relationships_detection_tutorial.ipynb-muistikirja on tämän opetusohjelman mukana.
Jos haluat avata tämän opetusohjelman liitteenä olevan muistikirjan, tuo muistikirja työtilaasi noudattamalla ohjeita kohdassa Järjestelmän valmisteleminen datatieteen opetusohjelmia varten.
Jos haluat kopioida ja liittää koodin tältä sivulta, voit luoda uuden muistikirjan.
Muista liittää lakehouse muistikirjaan ennen kuin aloitat koodin suorittamisen.
Muistikirjan asettaminen
Tässä osiossa määrität muistikirjaympäristön, joka sisältää tarvittavat moduulit ja tiedot.
Asenna
SemPyPyPI:%pipstä muistikirjan sisäisen asennustoiminnon avulla:%pip install semantic-linkSuorita semPy-moduulien tarpeellinen tuonti, jotka tarvitset myöhemmin:
import pandas as pd from sempy.samples import download_synthea from sempy.relationships import ( find_relationships, list_relationship_violations, plot_relationship_metadata )Tuo pandas, jotta voit pakottaa määritysvaihtoehdon, joka auttaa tulosteen muotoilussa:
import pandas as pd pd.set_option('display.max_colwidth', None)Hae mallitiedot. Tässä opetusohjelmassa käytetään synteettisten potilastietojen Synthea-tietojoukkoa (pieni versio selvyyden vuoksi):
download_synthea(which='small')
Suhteiden havaitseminen pienessä Synthea-taulukoiden alijoukossa
Valitse kolme taulukkoa suuremmasta joukkoa:
patientsmäärittää potilastiedotencounterstäsmennetään potilaat, joilla oli lääketieteellisiä kohtaamisia (esimerkiksi lääkärinkäynti, toimenpide)providersmäärittää, mitkä lääketieteelliset palveluntarjoajat osallistuvat potilaiden hoitoon
Taulukko
encountersratkaisee monta moneen -yhteyden kohteiden välillepatientsjaprovidersvoidaan kuvata assositiiviseksi entiteetiksi:patients = pd.read_csv('synthea/csv/patients.csv') providers = pd.read_csv('synthea/csv/providers.csv') encounters = pd.read_csv('synthea/csv/encounters.csv')Etsi taulukoiden väliset suhteet SemPy-funktion
find_relationshipsavulla:suggested_relationships = find_relationships([patients, providers, encounters]) suggested_relationshipsVisualisoi suhteet DataFrame kaaviona SemPy-funktion
plot_relationship_metadataavulla.plot_relationship_metadata(suggested_relationships)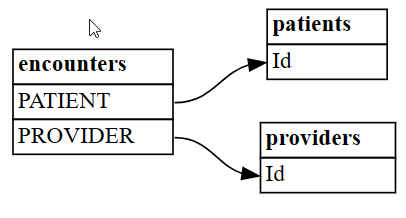
Funktio määrittää suhdehierarkian vasemmalta puolelta oikealle, mikä vastaa tuloksen "from"- ja "to"-taulukoita. Toisin sanoen vasemmalla puolella olevat riippumattomat "from"-taulukot osoittavat oikeanpuoleisiin riippuvuustaulukoihin viiteavaimillaan. Jokaisessa entiteettiruudussa näkyvät sarakkeet, jotka osallistuvat suhteen "kohteesta" tai "to"-puolelle.
Oletusarvon mukaan suhteet luodaan muodossa "m:1" (ei muodossa "1:m") tai "1:1". 1:1-suhteet voidaan luoda jommallakummalla tai kummallakin tavalla sen mukaan, ylittääkö
coverage_thresholdyhdistettyjen arvojen suhde kaikkiin arvoihin vain yhteen tai molempiin suuntiin. Myöhemmin tässä opetusohjelmassa käsittelet m:m-suhteita harvemmin.

Suhteiden tunnistusongelmien vianmääritys
Perusesimerkki näyttää onnistuneen suhteen tunnistamisen puhtaissa Synthea-tiedoissa . Käytännössä tiedot ovat harvoin puhtaita, mikä estää onnistuneen tunnistamisen. On useita tekniikoita, joista voi olla hyötyä, kun tiedot eivät ole puhtaita.
Tässä opetusohjelman osiossa käsitellään suhteiden havaitsemista, kun semanttinen malli sisältää likaista tietoja.
Aloita käsittelemällä alkuperäisiä DataFrames-kehyksiä, jotta saat "likaiset" tiedot, ja tulosta virheellisten tietojen koko.
# create a dirty 'patients' dataframe by dropping some rows using head() and duplicating some rows using concat() patients_dirty = pd.concat([patients.head(1000), patients.head(50)], axis=0) # create a dirty 'providers' dataframe by dropping some rows using head() providers_dirty = providers.head(5000) # the dirty dataframes have fewer records than the clean ones print(len(patients_dirty)) print(len(providers_dirty))Vertailun vuoksi alkuperäisten taulukoiden tulostuskoot:
print(len(patients)) print(len(providers))Etsi taulukoiden väliset suhteet SemPy-funktion
find_relationshipsavulla:find_relationships([patients_dirty, providers_dirty, encounters])Koodin tulos näyttää, että suhteita ei havaita aiemmin käyttöön otettujen virheellisen semanttisen mallin luomisen virheiden vuoksi.
Käytä vahvistusta
Vahvistus on paras työkalu suhteiden tunnistamisen virheiden vianmääritykseen, koska:
- Se ilmoittaa selvästi, miksi tietty suhde ei noudata viiteavainsääntöjä, joten sitä ei voida havaita.
- Se toimii nopeasti suurten semanttisten mallien kanssa, koska se keskittyy vain määritettyihin suhteisiin eikä suorita hakua.
Vahvistus voi käyttää mitä tahansa DataFrame-kehystä, jos sarakkeet ovat samankaltaisia kuin kohteen luomat sarakkeet find_relationships. Seuraavassa koodissa suggested_relationships DataFrame viittaa kohteeseen patients eikä patients_dirty, mutta voit aliaksena DataFrame-kehyksen hakemiston avulla:
dirty_tables = {
"patients": patients_dirty,
"providers" : providers_dirty,
"encounters": encounters
}
errors = list_relationship_violations(dirty_tables, suggested_relationships)
errors
Löysennä hakuehtoja
Hämärämmissä skenaarioissa voit kokeilla hakuehtojesi löysäämistä. Tämä menetelmä lisää false-positiivisten positiivisten mahdollisuutta.
Määritä
include_many_to_many=Trueja arvioi, auttaako se:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=1)Tulokset osoittavat, että suhde
encounterskohteesta kohteeseenpatientshavaittiin, mutta ongelmia on kaksi:- Suhde ilmaisee suunnan kohteesta
patientskohteeseenencounters, mikä on käänteisenä odotetusta suhteesta. Tämä johtuu siitä, että kaikkipatientstapahtui niin, ettäencounters(Coverage Fromon 1.0)encounterskattaa vain osittainpatients(Coverage To= 0,85), koska potilaiden rivejä puuttuu. - Pienen kardinaliteetin sarakkeessa on vahingossa vastaavuus
GENDER, joka sattuu vastaamaan molempien taulukoiden nimeä ja arvoa, mutta se ei ole kiinnostava "m:1"-suhde. -jaUnique Count To-sarakkeet ilmoittavatUnique Count Frompienen kardinaliteetin.
- Suhde ilmaisee suunnan kohteesta
Suorita uudelleen
find_relationships, jotta voit etsiä vain "m:1"-suhteita, mutta alaosassacoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=False, coverage_threshold=0.5)Tulos näyttää suhteiden oikean suunnan kohteesta
encountersproviderskohteeseen . Yhteyttäencounterskohteesta kohteeseenpatientsei kuitenkaan tunnisteta, koskapatientsse ei ole yksilöivä, joten se ei voi olla m:1-suhteen "Yksi"-puolella.Löysennä sekä
include_many_to_many=Trueettäcoverage_threshold=0.5:find_relationships(dirty_tables, include_many_to_many=True, coverage_threshold=0.5)Nyt molemmat kiinnostavat suhteet ovat näkyvissä, mutta melua on paljon enemmän:
- Matala kardinaliteettivastaavuus
GENDERon olemassa. - Esiin tuli suurempi kardinaliteetti "m:m" -vastaavuus
ORGANIZATION, mikä tekee selväksi, ettäORGANIZATIONsarakkeen normalisointi on todennäköisesti poistettu molemmista taulukoista.
- Matala kardinaliteettivastaavuus
Täsmää sarakkeiden nimet
SemPy ottaa oletusarvoisesti huomioon, että se vastaa vain määritteitä, jotka näyttävät nimien samankaltaisuuden, ja hyödyntää sitä, että tietokannan suunnittelijat nimeävät liittyvät sarakkeet yleensä samalla tavalla. Tämä toiminta auttaa välttämään vääriä suhteita, joita esiintyy useimmin pienen kardinaliteetin kokonaislukuavaimilla. Jos käytössä ovat 1,2,3,...,10 esimerkiksi tuoteluokat ja 1,2,3,...,10 tilauksen tilakoodi, ne sekoitetaan toisiinsa, kun tarkastellaan arvojen yhdistämismäärityksiä ottamatta sarakkeiden nimiä huomioon. Virheellisten suhteiden ei pitäisi olla ongelmia GUID-tunnuksen kaltaisten avainten kanssa.
SemPy tarkastelee sarakkeiden nimien ja taulukoiden nimien välistä samankaltaisuutta. Vastaavuus on likimääräinen ja kirjainkoolla ei ole merkitystä. Se ohittaa useimmin havaitut "decorator"-alimerkkijonot, kuten "tunnus", "koodi", "nimi", "avain", "pk", "fk". Tämän seurauksena yleisimmät vastaavuustapaukset ovat:
- määrite nimeltä "column" entiteetissä "foo" vastaa määritettä nimeltä "column" (myös "COLUMN" tai "Column") entiteetissä 'bar'.
- entiteetin foo-entiteetissä "column"-määrite vastaa määritettä, jonka nimi on column_id rivillä.
- määrite nimeltä bar entiteetissä "foo" vastaa määritettä nimeltä "code" kohteessa 'bar'.
Tunnistaminen suoritetaan nopeammin, kun sarakkeiden nimet täsmäytellään ensin.
Täsmää sarakkeiden nimet:
- Jos haluat tietää, mitkä sarakkeet on valittu jatkoarviointia varten, käytä
verbose=2-asetusta (verbose=1luetteloi vain käsiteltävät entiteetit). name_similarity_thresholdParametri määrittää, miten sarakkeita verrataan. Raja-arvo 1 ilmaisee, että olet kiinnostunut vain 100 %:n vastaamisesta.
find_relationships(dirty_tables, verbose=2, name_similarity_threshold=1.0);100 prosentin samankaltaisuudet eivät selitä pieniä eroja nimien välillä. Esimerkissä taulukoilla on monikkomuotoinen ja "s"-jälkiliite, minkä tuloksena ei ole tarkkaa vastaavuutta. Tätä käsitellään hyvin oletusarvon
name_similarity_threshold=0.8mukaisesti.- Jos haluat tietää, mitkä sarakkeet on valittu jatkoarviointia varten, käytä
Suorita uudelleen käyttäen oletusarvoa
name_similarity_threshold=0.8:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0.8);Huomaa, että monikkomuodon
patientsTunnusta verrataan nyt yksikönpatientkanssa ilman, että suoritusaikaan lisätään liian monta muuta virheellistä vertailua.Suorita uudelleen käyttäen oletusarvoa
name_similarity_threshold=0:find_relationships(dirty_tables, verbose=2, name_similarity_threshold=0);Jos arvoksi vaihdetaan
name_similarity_threshold0, se tarkoittaa myös sitä, että haluat verrata kaikkia sarakkeita. Tämä on harvoin tarpeen, ja se kasvattaa suoritusaikaa ja vääriä vastaavuuksia, joita on tarkistettava. Huomaa vertailujen määrä yksityiskohtaisessa tulosteessa.
Yhteenveto vianmääritysvihjeistä
- Aloita m:1-yhteyksien tarkasta vastaavuuden alusta (eli oletus
include_many_to_many=Falsejacoverage_threshold=1.0). Tämä on yleensä mitä haluat. - Keskity ahtaasti taulukoiden pienempiin alijoukkoihin.
- Käytä vahvistusta tietojen laatuongelmien tunnistamiseen.
- Käytä
verbose=2tätä, jos haluat ymmärtää, mitä sarakkeita käsitellään suhteessa. Tämä voi aiheuttaa suuren tulostemäärän. - Ota huomioon hakuargumenttien kompromissit.
include_many_to_many=Truejacoverage_threshold<1.0se voi aiheuttaa vääriä suhteita, joita on ehkä vaikeampi analysoida ja jotka on suodatettava.
Suhteiden havaitseminen koko Synthea-tietojoukossa
Yksinkertainen perusesimerkki oli kätevä oppimis- ja vianmääritystyökalu. Käytännössä voit aloittaa semanttisesta mallista, kuten koko Synthea-tietojoukosta , jossa on paljon enemmän taulukoita. Tutustu koko synthea-tietojoukkoon seuraavasti.
Lue kaikki tiedostot synthea/csv-hakemistosta:
all_tables = { "allergies": pd.read_csv('synthea/csv/allergies.csv'), "careplans": pd.read_csv('synthea/csv/careplans.csv'), "conditions": pd.read_csv('synthea/csv/conditions.csv'), "devices": pd.read_csv('synthea/csv/devices.csv'), "encounters": pd.read_csv('synthea/csv/encounters.csv'), "imaging_studies": pd.read_csv('synthea/csv/imaging_studies.csv'), "immunizations": pd.read_csv('synthea/csv/immunizations.csv'), "medications": pd.read_csv('synthea/csv/medications.csv'), "observations": pd.read_csv('synthea/csv/observations.csv'), "organizations": pd.read_csv('synthea/csv/organizations.csv'), "patients": pd.read_csv('synthea/csv/patients.csv'), "payer_transitions": pd.read_csv('synthea/csv/payer_transitions.csv'), "payers": pd.read_csv('synthea/csv/payers.csv'), "procedures": pd.read_csv('synthea/csv/procedures.csv'), "providers": pd.read_csv('synthea/csv/providers.csv'), "supplies": pd.read_csv('synthea/csv/supplies.csv'), }Etsi taulukoiden väliset suhteet SemPy-funktion
find_relationshipsavulla:suggested_relationships = find_relationships(all_tables) suggested_relationshipsVisualisoi suhteet:
plot_relationship_metadata(suggested_relationships)
Laske, kuinka monta uutta m:m-suhdetta kohteen kanssa
include_many_to_many=Truehavaitaan. Nämä suhteet täydentävät aiemmin näytettyjä "m:1"-suhteita. siksi sinun täytyy suodattaa :n mukaanmultiplicity:suggested_relationships = find_relationships(all_tables, coverage_threshold=1.0, include_many_to_many=True) suggested_relationships[suggested_relationships['Multiplicity']=='m:m']Voit lajitella suhdetietoja eri sarakkeiden mukaan, jotta saat syvemmän käsityksen niiden luonteesta. Voit esimerkiksi järjestää tulokset -, ja
Row Count FromRow Count To-mukaan, mikä auttaa tunnistamaan suurimmat taulukot.suggested_relationships.sort_values(['Row Count From', 'Row Count To'], ascending=False)Erilaisessa semanttisessa mallissa olisi ehkä tärkeää keskittyä tyhjäarvojen
Null Count Frommäärään taiCoverage To.Tämän analyysin avulla voit ymmärtää, voiko jokin suhteista olla virheellinen, ja jos ne on poistettava ehdokasluettelosta.

Liittyvä sisältö
Katso muut opetusohjelmat semanttisesta linkistä /SemPy:stä:
- Opetusohjelma: Funktionaalisia riippuvuuksia sisältävien tietojen siistiminen
- Opetusohjelma: semanttisen malliesimerkkien toiminnallisten riippuvuuksien analysointi
- Opetusohjelma: Suhteiden etsiminen semanttisessa mallissa semanttisen linkin avulla
- Opetusohjelma: Poimi ja laske Power BI -mittareita Jupyter-muistikirjasta
Palaute
Tulossa pian: Vuoden 2024 aikana poistamme asteittain GitHub Issuesin käytöstä sisällön palautemekanismina ja korvaamme sen uudella palautejärjestelmällä. Lisätietoja on täällä: https://aka.ms/ContentUserFeedback.
Lähetä ja näytä palaute kohteelle