Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Koskee:✅ Microsoft Fabric -varasto
Tämä artikkeli korostaa Fabric Data Warehousen arkkitehtuurin ominaisuuksia ja innovaatioita, jotka tukevat sen suorituskykyä, skaalautuvuutta ja kustannustehokkuutta.
Fabric Data Warehouse toimii tulevaisuuteen sopivalla arkkitehtuurilla konvergooidussa dataalustassa. Avoimen Delta-tallennusmuodon ja OneLake-integraation avulla Fabric Data Warehousessa oleva datasi on valmis analysoitavaksi.
Korkean tason arkkitehtuuri

Fabric Data Warehouse on suunniteltu erityisesti laajamittaiseen analytiikkaan seuraavilla rakennuspalikoilla:
| Rakennuspalikka | Description |
|---|---|
| Unified query optimizer | Luo optimaalisen suoritussuunnitelman hajautetuille pilviympäristöille, riippumatta käyttäjien kirjoittamien SQL-kyselyiden laadusta. |
| Hajautettu kyselyjen käsittely | Tukee massiivista rinnakkaiskyselyjen suoritusta nopealla automaattisesti skaalautuvalla pilvi-infrastruktuurilla, tarjoten välittömästi tarvittavat laskentaresurssit kyselyille. Erilliset SELECT- ja DML-työkuormat käyttävät erillisiä pooleja tehokkaaseen ja eristettyyn suoritukseen. |
| Kyselyn suoritusmoottori | SQL-pohjainen moottori, joka suorittaa analytiikkakyselyitä suurella datamäärällä nopealla suorituskyvyllä ja korkealla rinnakkaisnopeudella. |
| Metatiedot ja transaktioiden hallinta | Metatiedot sijaitsevat frontendissä, backendissä sekä paikallisessa SSD-välimuistissa että etätilassa olevassa OneLake-tallennustilassa. Tukee samanaikaisia tapahtumia ja varmistaa ACID-vaatimusten noudattamisen. |
| Varastointi OneLakessa | Log Structured Tables toteutettu avoimella Delta-taulumuodolla, joka on järvitalomalli, jossa on suojattu avoin tallennus. |
| Kangasalusta | Fabric Platform tarjoaa yhtenäisen todennus- ja tietoturvamallin, valvonnan ja auditoinnin. Fabric Data Warehouse on automaattisesti käytettävissä muille Fabric-alustapalveluille liiketoiminnan tarpeisiin, kuten Power BI:hin, Data Factoryn dataputkiin, Real-Time Intelligenceen ja muihin. |
Yhtenäinen kyselyoptimointimoottori
Unified query optimizer Fabric Data Warehousessa on moottori, joka päättää älykkäimmän tavan suorittaa SQL-kyselysi.
Kun lähetät kyselyn, yhtenäinen kyselyoptimointiohjelma tarkastelee mahdollisia tapoja suorittaa se: miten yhdistää tauluja, missä siirtää dataa ja miten käyttää resursseja kuten CPU:ta, muistia ja verkkoa. Yhtenäinen kyselyoptimointiohjelma ei valitse vain ensimmäistä vaihtoehtoa, vaan valitsee optimaalisimman suunnitelman sallitussa ajassa arvioimalla kustannuksia näiden tekijöiden sekä saatavilla olevien metatietojen ja tilastojen välillä.
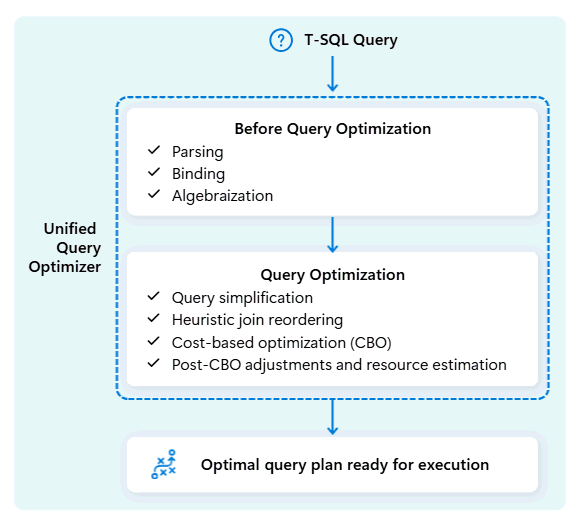
Kun optimoidaan kyselyn suoritussuunnitelmaa, yhtenäinen kyselyoptimointi ottaa kaiken huomioon yhdellä kertaa: kyselyn muodon, taulujen datan jakautumisen sekä datan siirron ja paikallisen käsittelyn kustannukset. Yhtenäinen kyselyoptimointiohjelma voi tehdä fiksuja kompromisseja, kuten päättää, onko pienen taulukon lähettäminen halvempaa kuin suuren taulukon sekoittaminen. Tämä tarkoittaa vähemmän tarpeettomia tietojen siirtoja, parempaa laskentatoiminnan käyttöä ja nopeampaa suorituskykyä, jopa monimutkaisissa tai huonosti kirjoitetuissa T-SQL-kyselyissä.
Johdonmukainen suorituskyky ei vaadi kehittäjiltä aikaa manuaaliseen T-SQL-kyselyjen viritykseen. Esimerkiksi sinun ei tarvitse manuaalisesti määrittää parasta JOIN järjestystä kyselyissä. Jos SQL:si listaa ensin suuren taulukon ja pienemmän, erittäin valikoivan datataulukon vasta toisena, optimoija voi automaattisesti vaihtaa sijaintiaan paremman suorituskyvyn saavuttamiseksi. Se käyttää pienempää taulukkoa lähtökohtana rivien sovittamiselle ("build"-puoli) ja isompaa taulukkoa etsittävänä ("probe"-puoli, tarkistettu osumuuksien varalta). Tämä lähestymistapa minimoi muistin kulutuksen, vähentää datan liikettä ja parantaa rinnakkaisuutta, samalla kun tulokset ovat tarkkoja.
Yhtenäinen kyselyoptimointiohjelma oppii jatkuvasti aiemmista kyselysuorituksista työkuormien kehittyessä ja hioi optimointialgoritmiaan parhaan mahdollisen suorituskyvyn saavuttamiseksi. Käyttäjät hyötyvät nopeasta kyselyn suorituksesta automaattisesti, monimutkaisuudesta riippumatta ja ilman tarvetta puuttua asioihin.
Hajautettu kyselyjen käsittelymoottori
Fabric Data Warehousessa hajautettu kyselyjen käsittelymoottori kohdentaa laskentaresursseja kyselysuunnitelmien tehtäviin. Hajautettu kyselyjen käsittelymoottori voi ajoittaa tehtäviä laskentasolmujen välillä siten, että jokainen solmu suorittaa osan kyselysuunnitelmasta, mahdollistaen rinnakkaisen suorituksen nopeamman suorituskyvyn saavuttamiseksi. Monimutkaiset raportit suurista aineistoista voivat hyötyä hajautetusta kyselyjen käsittelystä.
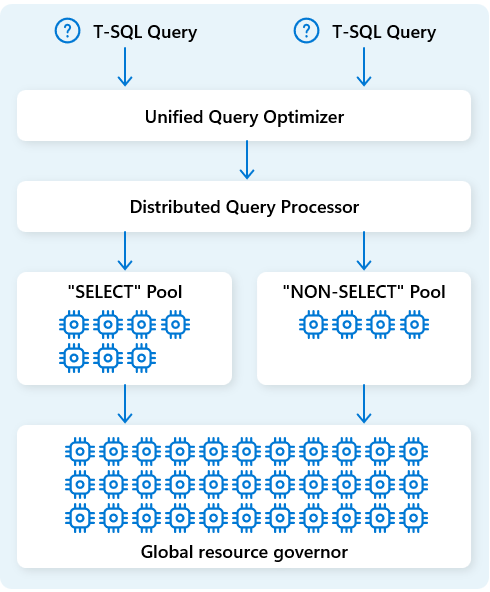
Resurssien edelleen optimoimiseksi hajautettu kyselyjen käsittelymoottori jakaa laskentaresurssit kahteen pooliin: SELECT kyselyihin ja tiedon vastaanottotehtäviin (NON-SELECT kyselyihin). Jokainen työkuorma saa tarvittavat resurssit. Tämä tarkoittaa esimerkiksi, että yölliset ETL-työsi eivät viivästytä aamun hallintapaneelit.
Nopean solmujen provisionoinnin ansiosta pilvessä hajautettu kyselyjen käsittelymoottori skaalaa automaattisesti laskentaresursseja ylös- tai alaspäin kyselymäärän, datan koon ja kyselyn monimutkaisuuden muutosten mukaan. Fabric Data Warehousella on rinnakkaiskäsittelymahdollisuudet pienille aineistoille tai monipetatavun mittakaavassa toimiville datalle.
Kyselyn suoritusmoottori
Kyselyjen suoritusmoottori on prosessi, joka suorittaa osia hajautetun suoritussuunnitelmasta, jotka on määritetty yksittäisille laskentasolmuille. Kyselyjen suoritusmoottori perustuu samaan moottoriin, jota SQL Server ja Azure SQL Database käyttävät eräajo- ja sarakkeusdatamuotojen avulla tehokkaaseen big datan analytiikkaan optimaalisella hinnalla.
Kyselyjen suoritusmoottori lukee dataa suoraan Delta Parquet -tiedostoista, jotka on tallennettu Fabric OneLakeen, ja hyödyntää useita välimuistikerroksia (muisti ja SSD) nopeuttaakseen kyselyiden suorituskykyä ja varmistaakseen kyselyjen suorituskyvyn optimaalisella nopeudella. Kyselyn suoritusmoottori käsittelee dataa muistissa ja tarvittaessa hakee lisädataa SSD-välimuistista tai OneLake-tallennustilasta.
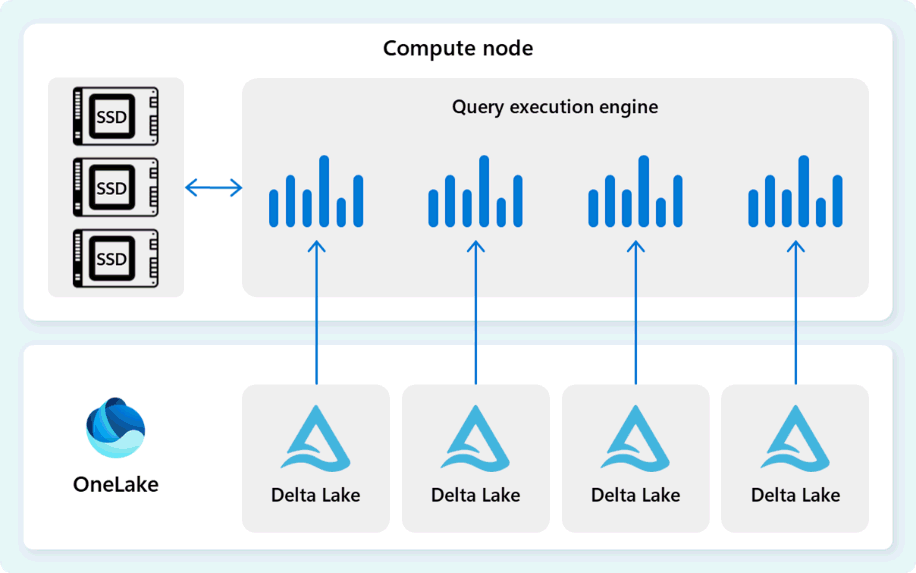
Kun kyselyn suoritusmoottori käsittelee dataa, se suorittaa sarakkeiden ja riviryhmien poistamisen ohittaakseen segmentit, jotka eivät ole relevantteja kyselylle. Tämä optimointi vähentää tiedostoista ja muistivälimuistista skannattavan datan määrää, mikä auttaa minimoimaan resurssien käyttöä ja parantamaan kokonaissuoritusaikaa.
Kyselyjen suoritusmoottori on erinomainen miljardien rivien suodattamisessa ja kokoamisessa, tukien nykyaikaisten tietovarastoratkaisujen yleisiä data-analytiikkamalleja. Eräajotapa hyödyntää nykyaikaista CPU:n kykyä käsitellä useita rivejä rinnakkain, mikä vähentää huomattavasti ylikuormitusta ja nopeuttaa kyselyitä jopa satoja kertoja verrattuna perinteiseen rivi rivi kerrallaan suoritukseen.
Metatiedot ja transaktioiden hallinta
Varastomoottori käyttää metatietoja kuvaamaan taulukkoskeemaa, tiedostojen järjestelyä, versiohistoriaa ja transaktiotiloja. Tämä metadata mahdollistaa varastomoottorin tehokkaan hallinnan ja kyselyn datasta. Fabric Data Warehouse tarjoaa vahvan ja kattavan metatietojen ja transaktioiden hallinnan arkkitehtuurin, laajentaen OLTP-transaktionhallintaa orkestroimaan hyvin samanaikaiset metatietotoiminnot ja varmistamaan ACID-säädösten noudattamisen.
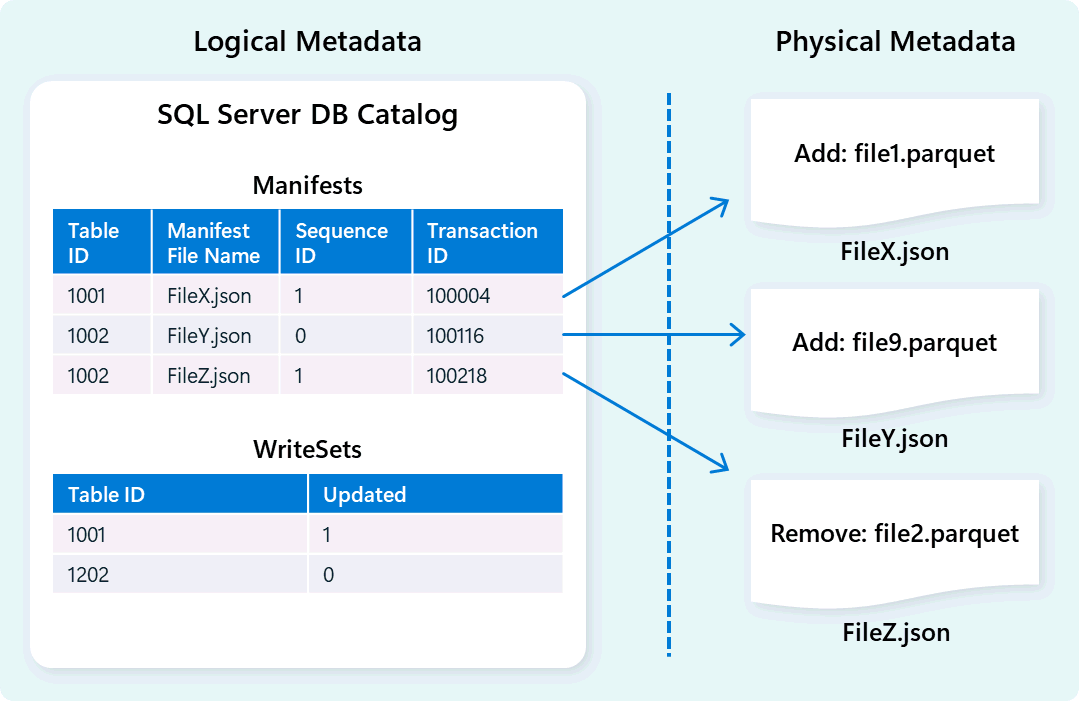
Tämä suunnittelu mahdollistaa nopean ja luotettavan transaktiontilojen navigoinnin, tukee työkuormia korkealla rinnakkaisrinnalla varmistaen samalla johdonmukaisuuden.
Tallennus ja tiedon vastaanotto
Fabric Data Warehouse käyttää lakehouse-arkkitehtuuria avoimen lähdekoodin Delta-muodossa skaalautuvan, turvallisen ja korkean suorituskyvyn tallennusta varten. Delta-taulukkomuoto tukee datan versiointia, mahdollistaen välittömän pääsyn historiallisiin snapshotteihin aikamatkailun ja nollakopion kloonauksen avulla turvallista testausta ja palautusoperaatioita varten. Käyttäjätiedot tallennetaan OneLakeen, mikä mahdollistaa kaikkien Fabric-moottoreiden tehokkaan pääsyn jaettuun dataan ilman redundanssia.
Tämän perustan pohjalta Fabric Data Warehouse on suunniteltu tarjoamaan optimaalinen tiedon vastaanottosuorituskyky keskittyen yksinkertaisuuteen ja joustavuuteen. Moottori hallitsee taulukkotietojen tallennusta tehokkaasti automaattisen datan tiivistämisen avulla, joka yhdistää fragmentoituneet tiedostot taustalle vähentäen tarpeetonta datan skannausta. Sen älykäs datanjakomenetelmä jakaa ja järjestää datan mikrojakoisiksi soluiksi rinnakkaiskäsittelyn tehostamiseksi ja kyselytulosten parantamiseksi. Nämä ominaisuudet toimivat itsenäisesti ilman manuaalisia säätöjä.