Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Koskee: ✅ SQL analytiikan päätepiste ja Warehouse Microsoft Fabricissa
Mukautetut SQL-poolit antavat ylläpitäjille enemmän kontrollia siihen, miten resursseja jaetaan pyyntöjen käsittelyyn. Tässä pikaaloituksessa konfiguroit mukautetut SQL-poolit ja tarkkailet luokittelijan arvoja Fabric REST API:n avulla.
Työtilan ylläpitäjät voivat käyttää yhteyden merkkijonosta peräisin olevaa sovelluksen nimeä (tai ohjelman nimeä) reitittääkseen pyyntöjä eri laskentapooleihin. Työtilan ylläpitäjät voivat myös hallita, kuinka paljon resursseja kukin laskenta-SQL-pooli voi käyttää, riippuen työtilan kapasiteetin räjähtävästä skaalausrajasta.
Fabric REST API määrittelee yhtenäisen päätepisteen operaatioille.
Edellytykset
- Pääsy varastoesineeseen työtilassa. Sinun tulisi olla ylläpitäjän roolissa.
Hanki nykyinen konfiguraatio
Käytä seuraavaa API:ta saadaksesi nykyisen konfiguraation.
Fabric-muistikirjaesimerkki
Voit ajaa seuraavan esimerkin Python-koodista Fabric Spark -muistikirjassa.
- Koodi lähettää pyynnön
GETmukautettuun SQL-poolin konfiguraatiorajapintaan ja palauttaa oman SQL-poolin konfiguraation työtilalle. - Kenttä
workspace_idkäyttää Mapiamssparkutils.runtime.contextsaadakseen työtilan GUID:n, jossa muistikirja toimii. Jos haluat konfiguroida mukautetun SQL-poolin toisessa työtilassa, päivitäworkspace_idsen työtilan GUID-tiedostoon, jossa haluat konfiguroida mukautetut SQL-poolit.
import requests
import json
from notebookutils import mssparkutils
# This will get the workspace_id where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspaceId = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspaceId}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='get', url=url, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print(json.dumps(response.json(), indent=4))
else:
print(response.text)
Mukautettujen SQL-poolien konfigurointi
Seuraava Python-esimerkki mahdollistaa ja konfiguroi mukautetut SQL-poolit. Voit ajaa tämän Python-koodin Fabric Spark -muistikirjassa.
- Mukautettu SQL-poolien konfiguraatio on aktiivinen vain, kun
customSQLPoolsEnabledattribuutti on asetettu true-arvoon. Voit määritellä hyötykuorman objektimäärittelyssäcustomSQLPools, mutta jos et aseta customSQLPoolsEnabledia true-tilaan, hyötykuorma jätetään huomiotta ja käytetään autonomista työkuorman hallintaa . - Koodi konfiguroi kaksi mukautettua
ContosoSQLPoolSQL-poolia, jaAdhocPool.- Se
ContosoSQLPoolsaa 70% käytettävissä olevista resursseista. Sovelluksen nimiluokittelun arvoMyContosoAppon . - Kaikki SQL-kyselyt, jotka tulevat yhteysmerkkijonosta, joka määrittää
MyContosoAppsovelluksen nimen, luokitellaan mukautettuunContosoSQLPoolSQL-pooliin ja niillä on pääsy 70% kaikista purkautuvan kapasiteetin solmuista. - Kaikki SQL-kyselyt, jotka eivät sisällä
MyContosoAppyhteysmerkkijonon sovelluksen nimeä, lähetetään mukautettuunAdhocSQL-pooliin, joka määritellään oletuspooliksi. Nämä pyynnöt saavat pääsyn 30% kaikista räjähdettävistä solmuista.
- Se
- Kaikissa mukautetuissa SQL-poolin kokoonpanoissa täytyy olla yksi oletus SQL Pool, joka tunnistetaan asettamalla attribuutiksi
isDefaulttrue. - Kaikkien
maxResourcePercentagearvojen summa on oltava pienempi tai yhtä suuri kuin 100%. - Kenttä
workspace_idkäyttää Mapiamssparkutils.runtime.contextsaadakseen työtilan GUID:n, jossa muistikirja toimii. Jos haluat konfiguroida mukautetun SQL-poolin toisessa työtilassa, päivitäworkspace_idsen työtilan GUID-tiedostoon, jossa haluat konfiguroida mukautetut SQL-poolit.
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": True,
"customSQLPools": [
{
"name": "ContosoSQLPool",
"isDefault": False,
"maxResourcePercentage": 70,
"optimizeForReads": False,
"classifier": {
"type": "Application Name",
"value": [
"MyContosoApp"
]
}
},
{
"name": "AdhocPool",
"isDefault": True,
"maxResourcePercentage": 30,
"optimizeForReads": True
}
]
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools configured successfully.")
else:
print(response.text)
Vinkki
Käytä näitä hyödyllisiä Application Name (regex) -luokitteluarvoja Fabricin liikenteelle:
- Fabric-putkiston kyselyjen luokitteluun käytetään
^Data Integration-to[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[1-5][0-9a-fA-F]{3}-[89abAB][0-9a-fA-F]{3}-[0-9a-fA-F]{12}$. - Power BI:n kyselyjen luokitteluun käytetään
^(PowerBIPremium-DirectQuery|Mashup Engine(?: \(PowerBIPremium-Import\))?). -
Fabric-portaalin SQL-kyselyeditorin kyselyjen luokittelemiseksi käytä
DMS_user.
Aseta sovelluksen nimi SQL Server Management Studiossa (SSMS)
Mukautettujen SQL-poolien luokittelija käyttää yleisten yhteysmerkkijonojen sovelluksen nimeä tai ohjelman nimiparametria.
SQL Server Management Studiossa (SSMS) määritä varaston palvelimen nimi ja anna todennus. Microsoft Entra MFA on suositeltava.
Valitse Advanced-painike .
Lisäominaisuudet-sivulla, Kontekstissa, muuta sovelluksen nimen
MyContosoApparvo .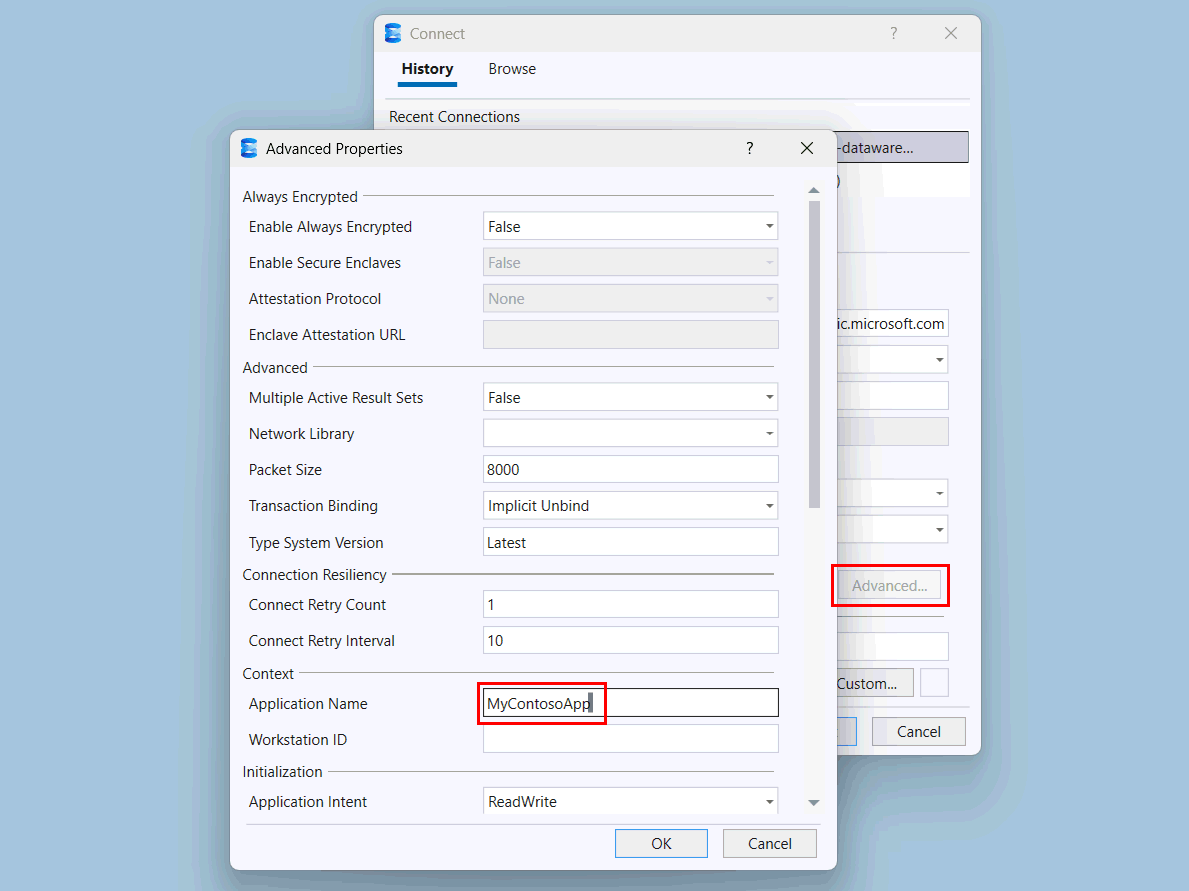
Valitse OK.
Valitse Yhdistä.
Jonkin esimerkkitoiminnan luomiseksi käytä tätä yhteyttä SSMS:ssä suorittaaksesi yksinkertaisen kyselyn varastossasi, esimerkiksi:
SELECT * FROM dbo.DimDate;

Tarkkaile kyselyoivalluksia mukautetulle SQL-poolille
Tarkista dynaamisen
sys.dm_exec_sessionshallinnan näkymä nähdäksesi, ettäMyContosoAppsovellusnimi siirtyy SSMS:stä SQL-moottorille.SELECT session_id, program_name FROM sys.dm_exec_sessions WHERE program_name = 'MyContosoApp';Esimerkkejä:
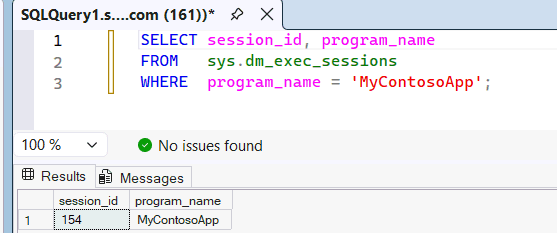
Koska se
program_namevastaa sovelluksen nimeä mukautetussaMyContosoAppSQL-poolissa, tämä kysely käyttää kyseisen poolin resursseja. Todistaaksesi, mitä mukautettua SQL-poolia kysely käytti, voit hakea queryinsights.exec_requests_history järjestelmänäkymää. Odota 10–15 minuuttia, että kyselyn oivallukset täyttyvät, ja suorita sitten seuraava kysely.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE program_name = 'MyContosoApp';Voit myös tunnistaa kyselypoolin sen Statement ID:n perusteella. Fabric-portaalin SQL-kyselyeditorissa suorita kysely varastosi tai SQL-analytiikkapäätepisteesi kanssa.
SELECT * FROM dbo.DimDate;Valitse Viestit-välilehti ja tallenna kyselyn suorituksen Statement ID. SQL-kyselyeditorissa on
program_nameDMS_user, jonka olit aiemmin konfiguroinut käyttämään mukautettuaMyContosoAppSQL-poolia.Odota 10–15 minuuttia, että kyselytiedot täyttyvät.
Hae tiedot
sql_pool_nameja muut tiedot varmistaaksesi, että oikea mukautettu SQL-pooli on käytetty.SELECT distributed_statement_id, submit_time, program_name, sql_pool_name, start_time, end_time FROM queryinsights.exec_requests_history WHERE distributed_statement_id = '<Statement ID>';
Revert the custom SQL pools configuration
Palauttaaksesi työtilan alkuperäiseen tilaan, muuta ominaisuus customSQLPoolsEnabled .False Jos haluat säilyttää mukautettujen SQL-poolien konfiguraatiot, sinun täytyy syöttää jokaisen poolin nimi kuten listassa customSQLPools .
Tämä esimerkki Python-koodi poistaa omat SQL-poolit käytöstä ja palauttaa autonomisen työkuormanhallinnan konfiguraatioon ja SELECT ei-poolitSELECT .
PATCH Pyyntö kutsutaan siten, että ominaisuus customSQLPoolsEnabled on asetettu .False
import requests
import json
from notebookutils import mssparkutils
body = {
"customSQLPoolsEnabled": False,
"customSQLPools": []
}
# This will get the workspaceId where this notebook is running.
# Update to the workspace_id (guid) if running this notebook outside of the workspace where the warehouse exists.
workspace_id = mssparkutils.runtime.context.get('currentWorkspaceId')
url = f'https://api.fabric.microsoft.com/v1/workspaces/{workspace_id}/warehouses/sqlPoolsConfiguration?beta=true'
response = requests.request(method='patch', url=url, json=body, headers={'Authorization': f'Bearer {mssparkutils.credentials.getToken("pbi")}'})
if response.status_code == 200:
print("SQL Custom Pools successfully disabled.")
else:
print(response.text)