Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Tämä artikkeli on tarkoitettu IT-ammattilaisille ja IT-johtajille. Opit BI-ratkaisuarkkitehtuurista COE:ssä ja erilaisista käytetyistä tekniikoista. Niitä ovat esimerkiksi Azure, Power BI ja Excel. Yhdessä niitä voidaan hyödyntää skaalattavan ja datapohjaisen BI-pilviympäristön tarjoamisessa.
Tukevan BI-ympäristön suunnittelu on kuin sillan rakentaminen. silta, joka yhdistää muunnetut ja täydennettyjä lähdetiedot tietojen kuluttajiin. Tällaisen monimutkaisen rakenteen suunnittelu vaatii suunnitteluajattelun, mutta se voi olla yksi luovimmista ja palkitsevimmista IT-arkkitehtuureista, joita voisit suunnitella. Suuressa organisaatiossa BI-ratkaisuarkkitehtuuri voi koostua seuraavista:
- Tietolähteet
- Tietojen käsittely
- Massadata / tietojen valmistelu
- Tietovarasto
- Semanttiset BI-mallit
- Raportit
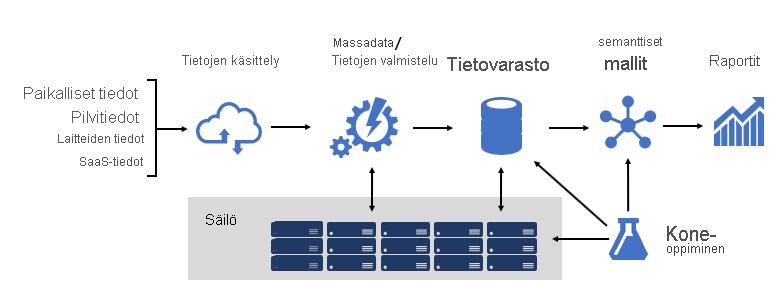
Ympäristön on tuettava tiettyjä vaatimuksia. Tarkemmin sanottuna sen täytyy olla skaalattava ja täyttää yrityspalvelujen ja datan kuluttajien odotukset. Samanaikaisesti sen täytyy myös olla turvallinen alusta alkaen. Sen on oltava riittävän joustava sopeutuakseen muutokseen, koska on varmaa, että ajan myötä uutta dataa ja uusia aihealueita on saatava mukaan ratkaisuun.
Puitteet
Microsoft on alusta alkaen suhtautunut järjestelmämäiseen lähestymistapaan investoimalla sovelluskehyksiin. Tekniset ja liiketoiminnallisen prosessin sovelluskehykset lisäävät suunnittelun ja logiikan uudelleenkäyttöä ja takaavat johdonmukaiset tulokset. Ne tarjoavat myös joustavuutta, jotta arkkitehtuuri voi hyödyntää monia tekniikoita, sekä järkeistävät ja keventävät suunnittelutyötä toistettavissa prosessien avulla.
Olemme huomanneet, että hyvin suunnitellut sovelluskehykset parantavat näkyvyyttä tietojen historiatietoihin, vaikutusanalyyseihin, liiketoimintalogiikan ylläpitoon, taksonomian hallintaan ja hallinnan järkeistämiseen. Lisäksi kehitys on nopeampaa ja yhteistyö suurissa tiimeissä tehokkaampaa.
Kuvaamme useita sovelluskehyksiämme tässä artikkelissa.
Tietomallit
Tietomallien avulla voit hallita sitä, miten tiedot jäsentetään ja miten niitä käytetään. Yrityspalveluihin ja tietojen kuluttajille tietomallit ovat käyttöliittymä BI-ympäristöön.
BI-ympäristö voi tarjota kolmenlaisia malleja:
- Yritysmallit
- Semanttiset BI-mallit
- koneoppimismalleja
Yritysmallit
yritysmallit ovat IT-arkkitehtien luomia ja ylläpitämiä. Niitä kutsutaan joskus dimensiomalleiksi tai tietovaraston osajoukoiksi. Yleensä tiedot tallennetaan relaatiomuodossa dimensio- ja faktataulukoina. Näihin taulukoihin tallennetaan siistittyjä ja täydennettyjä tietoja, jotka on koottu useista järjestelmistä ja jotka muodostavat valtuutettavan lähteen raportoinnille ja analytiikalle.
Yritysmallit tarjoavat johdonmukaisen ja yksittäisen tietolähteen raportointia ja BI-liiketoimintatietoja varten. Ne luodaan kerran ja jaetaan yrityksen standardina. Hallintakäytännöt varmistavat, että tiedot ovat turvallisia, joten luottamuksellisten tietojoukkojen, kuten asiakastietojen tai taloustietojen, käyttöä rajoitetaan tarvepohjaisesti. Niissä noudatetaan nimeämiskäytäntöjä, jotka takaavat yhdenmukaisuuden. Tämä lisää tietojen uskottavuutta ja laatua.
BI-pilviympäristössä yritysmalleja voidaan ottaa käyttöön Synapse SQL -varannossa Azure Synapse. Synapse SQL -varannosta tulee sitten ainoa totuuden versio, jolle organisaatio voi luottaa nopeita ja tehokkaita merkityksellisiä tietoja hyödyntäen.
Semanttiset BI-mallit
semanttiset BI-mallit edustavat semanttista kerrosta yritysmallien päällä. Niitä rakennetaan ja ylläpidetään BI-kehittäjille sekä yrityskäyttäjille. BI-kehittäjät luovat semanttisia BI-perusmalleja, jotka hankkivat tietoja yritysmalleista. Yrityskäyttäjät voivat luoda pienempiä itsenäisiä malleja tai laajentaa semanttisia BI-perusmalleja osastokohtaisilla tai ulkoisilla lähteillä. Semanttiset BI-mallit keskittyvät yleensä yhteen aihealueeseen. Niitä jaetaan usein laajalti.
Liiketoimintatoimintoja otetaan käyttöön paitsi tietojen avulla, myös niiden semanttisten BI-mallien avulla, jotka kuvaavat käsitteitä, suhteita, sääntöjä ja standardeja. Näin ne edustavat intuitiivisia ja helposti ymmärrettäviä rakenteita, jotka määrittävät tietosuhteita ja tiivistävät liiketoimintasääntöjä laskutoimituksiksi. Ne voivat myös valvoa tarkasti määritettyjä tietojen käyttöoikeuksia ja varmistaa, että oikeat käyttäjät voivat käyttää oikeita tietoja. Tärkeää on se, että ne nopeuttavat kyselyiden toimintaa ja tarjoavat erittäin hyvin reagoivia vuorovaikutteisia analyyseja – jopa teratavuja tietoja. Kuten yritysmalleissakin, myös semanttisissa BI-malleissa noudatetaan yhdenmukaisuuden takaavia nimeämiskäytäntöjä.
BI-pilviympäristössä BI-kehittäjät voivat ottaa semanttisia BI-malleja käyttöön Azure Analysis Services
Tärkeä
Tässä artikkelissa viitataan Power BI Premiumiin tai sen kapasiteettitilauksiin (P-varastointiyksiköt). Tällä hetkellä Microsoft vahvistaa ostovaihtoehtoja ja poistaa käytöstä kapasiteettikohtaisen Power BI Premiumin SKU:t. Uusien ja nykyisten asiakkaiden kannattaa harkita Fabric-kapasiteettitilausten (F-varastointiyksiköiden) ostamista.
Lisätietoja on kohdassa Tärkeitä päivityksiä tulossa Power BI Premium -käyttöoikeuksien ja Power BI Premiumin usein kysytyt kysymykset.
Suosittelemme käyttöönottoa Power BI:hin, kun sitä käytetään raportointi- ja analytiikkatasona. Nämä tuotteet tukevat eri tallennustiloja, jolloin tietomallitaulukot voivat tallentaa tietonsa välimuistiin tai käyttää DirectQuery-. Se on tekniikka, joka välittää kyselyt pohjana olevaan tietolähteeseen. DirectQuery on ihanteellinen tallennustila, kun mallitaulukot edustavat suuria tietomääriä tai kun on tarpeen toimittaa lähes reaaliaikaisia tuloksia. Kahta tallennustilaa voidaan yhdistää: yhdistelmämallit yhdistää taulukoita, jotka käyttävät eri tallennustiloja yhdessä mallissa.
Jos mallissa on paljon kyselyjä, Azuren kuormituksentasainta voidaan käyttää kyselyn kuormituksen jakamiseen tasaisesti mallireplkaatissa. Sen avulla voit skaalata sovelluksia ja luoda erittäin suuren käytettävyyden semanttisia BI-malleja.
Koneoppimismallit
koneoppimismalleja rakennetaan ja ylläpidetään tietojenkäsittelyasiantuntijat. Ne kehitetään yleensä raakalähteistä Data Lake -tallennustilassa.
Koulutetut koneoppimismallit voivat paljastaa kuvioita tiedoissasi. Monissa tapauksissa näiden mallien avulla voidaan tehdä ennusteita, joita voidaan käyttää täydentämään tietoja. Ostokäyttäytymisen avulla voidaan esimerkiksi ennustaa asiakkaiden vaihtuvuutta tai segmentin asiakkaita. Ennustetuloksia voidaan lisätä yritysmalleihin, jotta analysointi on mahdollista asiakassegmenteittäin.
BI-pilviympäristössä voit Azuren automaattianalyysipalveluiden avulla harjoittaa, ottaa käyttöön, automatisoida, hallita ja seurata koneoppimismalleja.
Tietovarasto
BI-ympäristön ytimessä on tietovarasto, joka isännöi yritysmallejasi. Se on hyväksyttyjen tietojen lähde, kaiken keskus, joka palvelee yritysmalleja raportoinnissa, BI-toimissa ja tietojenkäsittelytoimissa.
Monet yrityspalvelut, mukaan lukien toimialakohtaiset sovellukset, voivat luottaa tietovarastoon määräävänä ja hallittuna yritystiedon lähteenä.
Microsoftin tietovarastoa isännöidään Azure Data Lake Storage Gen2 (ADLS Gen2) ja Azure Synapse Analyticsissa.
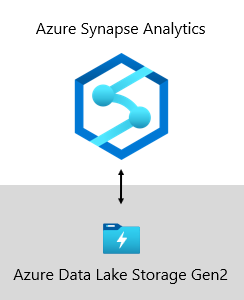
- ADLS Gen2 tekee Azure Storagesta yrityksen Data Lake -tallennustilojen luomisen perustan Azuressa. Se on suunniteltu tukemaan useita petatavuja tietoa sekä useiden gigabittien siirtomääriä. Lisäksi se tarjoaa edullisen tallennuskapasiteetin ja tapahtumat. Lisäksi se tukee Hadoop-yhteensopivaa käyttöoikeutta, jonka avulla voit hallita ja käyttää tietoja samalla tavalla kuin Hadoop Distributed File Systemissä (HDFS). Itse asiassa Azure HDInsight, Azure Databricks, ja Azure Synapse Analytics voivat kaikki käyttää ADLS Gen2:een tallennettuja tietoja. BI-ympäristössä se on siis hyvä vaihtoehto tallentaa raakalähdetiedot, puolikäsiteltyjä tai valmisteltuja tietoja ja käyttövalmiita tietoja. Tallennamme sen avulla kaikki yritystietomme.
- Azure Synapse Analytics on analytiikkapalvelu, joka yhdistää yritysten tietovarastot ja massadata-analytiikan. Sen avulla voit kysellä tietoja ehdoillasi joko palvelimettomalla ratkaisulla tarpeen mukaan tai valmiilla resursseilla – suuressa mittakaavassa. Synapse SQL, joka on Azure Synapse Analyticsin komponentti, tukee kattavaa T-SQL-pohjaista analytiikkaa, joten se soveltuu erinomaisesti dimensio- ja faktataulukoistasi koostuvien yritysmallien isännöintiin. Taulukot voidaan ladata tehokkaasti ADLS Gen2:sta käyttämällä yksinkertaisia Polybase T-SQL kyselyitä. Sen jälkeen voit MPP- suorittaa suorituskykyisiä analyyseja.
Business Rules Engine -sovelluskehys
Olemme kehittäneet Business Rules Engine (BRE) -sovelluskehyksen, jolla luetteloidaan kaikki liiketoimintalogiikat, jotka voidaan ottaa käyttöön tietovarastotasolla. BRE voi merkitä monia asioita, mutta tietovaraston kontekstissa siitä on hyötyä laskettujen sarakkeiden luomisessa relaatiotaulukoissa. Nämä lasketut sarakkeet esitetään yleensä matemaattisina laskutoimituksina tai lausekkeina ehdollisten lauseiden avulla.
Tarkoitus on erottaa liiketoimintalogiikka BI-peruskoodista. Perinteisesti liiketoimintasäännöt on koodattu kiinteästi SQL:n tallennettuihin toimintosarjoihin, joten niiden ylläpito on usein työllista, kun liiketoiminta muuttuu. BRE:ssä liiketoimintasäännöt määritetään kerran ja niitä käytetään useita kertoja eri tietovarastoentiteeteissä. Jos laskentalogiikan täytyy muuttua, se on päivitettävä vain yhdessä paikassa, ei useissa tallennetuissa toimintosarjoissa. Tällä on myös lisäetuna se, että BRE-sovelluskehys edistää toteutetun liiketoimintalogiikan läpinäkyvyyttä ja näkyvyyttä. Se voidaan näyttää raporteilla, jotka luovat itse päivittyviä ohjeita.
Tietolähteet
Tietovarastoon voi koota tietoja käytännöllisesti katsoen mistä tahansa tietolähteestä. Se perustuu enimmäkseen LOB-tietolähteisiin, jotka ovat yleensä relaatiotietokantoja, joihin tallennetaan myynnin, markkinoinnin, taloushallinnon ja muiden vastaavien aihekohtaisia tietoja. Näitä tietokantoja voidaan isännöidä pilvessä tai paikallisesti. Muut tietolähteet voivat olla tiedostopohjaisia, erityisesti verkkolokeja tai IOT-tietoja, jotka on hankittu laitteista. Lisäksi tietoja voidaan hankkia SaaS-palveluntarjoajilta.
Microsoftilla jotkin sisäiset järjestelmämme tuottavat operatiivisia tietoja suoraan ADLS Gen2:een raakatiedostomuotojen avulla. Data Lake -tallennustilan lisäksi myös muut lähdejärjestelmät koostuvat LOB-relaatiosovelluksista, Excel-työkirjoista, muista tiedostopohjaisista lähteistä sekä ydintietojen hallinnasta (MDM) ja mukautetuista tietosäilöistä. MDM-säilöjen avulla voimme hallita ydintietojamme, jotta voimme varmistaa tietojen kelvollisen, standardoidun ja vahvistetun version.
Tietojen käsittely
Tietoja käsitellään lähdejärjestelmistä säännöllisesti ja liiketoiminnan rytmin mukaisesti ladattavaksi tietovarastoon. Päivitysväli voi olla kerran päivässä tai tiheämmin välein. Tietojen tiedoissa on kyse tietojen purkamisesta, muuntamisesta ja lataamisesta. Tai ehkä toisin päin: se voi olla tietojen purkaminen, lataaminen ja muuntaminen. Ero on siinä, missä muuntaminen tapahtuu. Muunnoksia tehdään tietojen siistimiseksi, yhdenmukaistamiseksi, integroimiseksi ja standardoimiseksi. Katso lisätietoja artikkelista Poimi, muunna ja lataa (ETL).
Lopulta tavoitteena on ladata oikeat tiedot yritysmalliin mahdollisimman nopeasti ja tehokkaasti.
Microsoft käyttää Azure Data Factory (ADF). Palvelun avulla ajoitetaan ja järjestetään tietojen vahvistukset, muunnokset ja joukkolataukset ulkoisista lähdejärjestelmistä Data Lake -tallennustilaan. Sitä hallitaan mukautetuilla sovelluskehyksillä, jotka käsittelevät tietoja rinnakkain ja skaalautuviksi. Lisäksi suoritamme kattavaa kirjaamista vianmäärityksen tukemiseksi, suorituskyvyn valvomiseksi ja ilmoitusten käynnistämiseksi, kun tietyt ehdot täyttyvät.
Samaan aikaan Azure Databricks(se on Apache Sparkiin perustuva analytiikkaympäristö, joka on optimoitu Azure-pilvipalveluympäristölle) suorittaa muunnoksia erityisesti tietojenkäsittelyä varten. Se myös luo ja suorittaa koneoppimismalleja Python-muistikirjojen avulla. Näiden koneoppimismallien pisteet ladataan tietovarastoon, jotta ennusteet voidaan integroida yrityssovelluksiin ja raportteihin. Koska Azure Databricks käyttää Data Lake -tallennustilan tiedostoja suoraan, tietoja ei tarvitse kopioida tai hankkia.
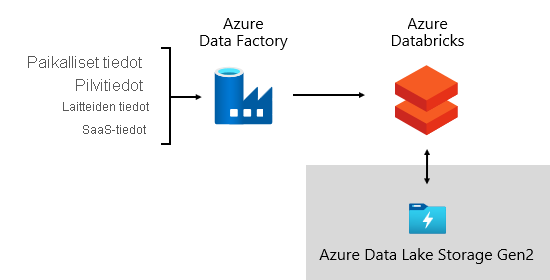
Tietojen käsittelykehys
Kehitimme tietojen käsittelykehyksen joukon kokoonpanotaulukoita ja toimintasyistä. Se tukee datapohjaista lähestymistapaa suurten tietomäärien hankkimiseen nopeasti ja mahdollisimman vähäisellä koodilla. Lyhyesti sanottuna tämä kehys yksinkertaistaa tietojen hankintaprosessia tietovarastoon lataamiseksi.
Kehys käyttää määritystaulukoita, joihin tallennetaan tietolähteeseen ja tietokohteeseen liittyviä tietoja, kuten lähdetyyppi, palvelin, tietokanta, rakenne ja taulukkoon liittyvät tiedot. Tämän lähestymistavan ansiosta meidän ei tarvitse kehittää tiettyjä ADF-putkia tai SQL Server Integration Services (SSIS) --paketteja. Sen sijaan toimintosanat kirjoitetaan valitsemallamme kielellä luodaksemme ADF-putkia, jotka luodaan ja suoritetaan dynaamisesti suorituksen aikana. Tietojen hankinnasta tulee siis määritysharjoitus, joka on helposti toimintakykyinen. Perinteisesti kiinteästi koodatun ADF- tai SSIS-paketin luominen vaatisi paljon kehitysresursseja.
Tietojen käsittelykehyksen tarkoitus on yksinkertaistaa myös lähderakennemuutosten käsittelyä. Määritystiedot on helppo päivittää manuaalisesti tai automaattisesti, kun rakenteen muutoksia havaitaan, jotta lähdejärjestelmän uudet lisätyt määritteet voidaan hankkia.
Orkestrointikehys
Kehitimme orkestrointikehyksen tietoputkien operationalisoimiseksi ja orkestroimiseksi. Orkestrointikehyksessä käytetään tietopohjaista rakennetta, joka riippuu määritystaulukoiden joukosta. Näihin taulukoihin tallennetaan metatiedot, jotka kuvaavat putkien riippuvuuksia ja sitä, miten lähdetiedot yhdistetään kohdetietorakenteisiin. Tämän mukautuvan kehyksen kehittämiseen tehty investointi on sittemmin maksanut itsensä; jokaista tietojen siirtoa ei enää tarvitse koodata tietojenkäsittelyllä.
Tietojen tallennus
Data Lake -tallennustilaan voidaan tallentaa suuria määriä raakadataa myöhempää käyttöä varten valmistelutietojen ja muunnosten ohella.
Microsoft käyttää ADLS Gen2:ta ainoana totuuden lähteenä. Se tallentaa raakadatan yhdessä valmisteltujen tietojen ja käyttövalmiiden tietojen kanssa. Se tarjoaa erittäin skaalattavan ja kustannustehokkan Data Lake -tallennustilaratkaisun massadata-analytiikkaan. Kun erittäin suorituskykyisen tiedostojärjestelmän teho yhdistetään valtavaan mittakaavaan, se on optimoitu data-analytiikkakuormituksia varten, mikä nopeuttaa merkityksellisten tietojen saamista.
ADLS Gen2 tarjoaa kahden maailman parhaat puolet: sen BLOB-tallennuksen ja erittäin suorituskykyisen tiedostojärjestelmän nimitilan, jotka määritämme tarkasti määritetyillä käyttöoikeuksilla.
Jalostetut tiedot tallennetaan sitten relaatiotietokantaan, jotta voimme tarjota suorituskykyisen, erittäin skaalattavan tietosäilön yritysmalleille sekä sille liittyvän suojauksen, hallinnan ja hallittavuuden. Aihekohtaiset tietovaraston osajoukot tallennetaan Azure Synapse Analyticsiin ja ne ladataan Azure Databricksin tai PolyBase T-SQL -kyselyiden avulla.
Tietojen kulutus
Raportointitasolla yrityspalvelut käyttävät yritystietoja, jotka hankitaan tietovarastosta. Ne käyttävät myös tietoja suoraan Data Lake -tallennustilasta ad hoc -analyyseja tai tietojenkäsittelytehtäviä varten.
Tarkasti määritettyjä käyttöoikeuksia käytetään kaikilla tasoilla: Data Lake -tallennustilassa, yritysmalleissa ja semanttisissa BI-malleissa. Käyttöoikeudet varmistavat, että tietojen kuluttajat näkevät vain tiedot, joihin heillä on käyttöoikeus.
Me Microsoftilla käytämme Power BI:n raportteja ja koontinäyttöjä ja Power BI:n sivutettuja raportteja. Osa raportoinnista ja ad hoc -analyyseistä tehdään Excelissä – erityisesti talousraportointia.
Julkaisemme tietosanastoja, jotka tarjoavat viitetietoja tietomalleistamme. Ne ovat käyttäjien käytettävissä, jotta he saavat tietoja BI-ympäristöstämme. Sanastoissa kuvataan mallien rakenteet ja kuvataan entiteettejä, muotoja, rakennetta, tietojen historiatietoja, suhteita ja laskutoimituksia. Käytämme Azure-tietohakemistoa, jotta tietolähteemme ovat helposti löydettävissä ja ymmärrettäviä.
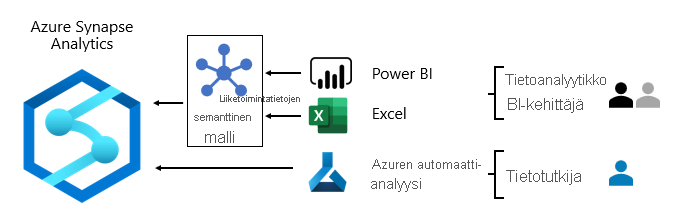
Yleensä tietojen kulutustavat vaihtelevat roolin mukaan:
- tietoanalyytikot muodostaa suoraan yhteyden semanttisiin BI-perusmalleihin. Kun semanttiset BI-perusmallit sisältävät kaiken heidän tarvitsemansa tiedon ja logiikan, he luovat Power BI:n raportteja ja koontinäyttöjä reaaliaikaisten yhteyksien avulla. Kun heidän täytyy laajentaa malleja osastokohtaisilla tiedoilla, he luovat Power BI -yhdistelmämalleista. Jos on tarvetta laskentataulukkotyylisille raporteilla, he tuottavat Excelissä raportteja, jotka perustuvat semanttisiin BI-perusmalleihin ja osastokohtaisiin semanttisiin BI-malleihin.
- BI -kehittäjät ja operatiivisten raporttien tekijät muodostavat yhteyden suoraan yritysmalleihin. He luovat reaaliaikaisen yhteyden analytiikkaraportteja Power BI Desktopin avulla. He voivat luoda myös operatiivisen tyypin BI-raportteja sivutettuina Power BI -raportteina ja kirjoittaa SQL-natiivikyselyitä, joilla he käyttävät tietoja Azure Synapse Analyticsin yritysmalleista T-SQL:n tai semanttisten Power BI -mallien avulla DAX:ää tai MDX:ää hyödyntämällä.
- Tietojenkäsittelyasiantuntijat muodostaa suoraan yhteyden Data Lake -tallennustilan tietoihin. He kehittävät Azure Databricksin ja Python-muistikirjojen avulla koneoppimismalleja, jotka ovat usein kokeellisia ja edellyttävät erikoisosaamista tuotantokäyttöön.
Aiheeseen liittyvä sisältö
Lisätietoja tästä artikkelista saat seuraavista resursseista:
- Fabricin käyttöönottosuunnitelma: Center of Excellence
- Enterprise BI Azuressa Azure Synapse Analytics -
- Kysymyksiä? Voit esittää kysymyksiä Fabric-yhteisön
- Ehdotuksia? Edistä ideoita Fabric- parantamiseksi
Asiantuntijapalvelut
Tarjolla on sertifioituja Power BI -kumppaneita, jotka voivat auttaa organisaatiotasi onnistumaan COE:n määrityksessä. Ne voivat tarjota kustannustehokkaalle koulutukselle tai tietojen valvonnan. Löydät Power BI -kumppanin Microsoft Power BI -kumppanien portaalista.
Voit myös olla yhteydessä kokeneihin konsultointikumppaneihin. Ne voivat auttaa sinua arvioimaan, arvioidatai Power BI:n käyttöönottoa.