Huomautus
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Tämä artikkeli on suunnattu tietomallintajille, jotka kehittävät Power BI -yhdistelmämalleja. Artikkelissa kuvaillaan yhdistelmämallin käyttötapauksia ja annetaan suunnitteluohjeita. Tarkemmin sanottuna ohjeet voivat auttaa selvittämään, sopiiko yhdistelmämalli ratkaisullesi. Jos näin on, tämän artikkelin avulla voit myös suunnitella optimaalisia yhdistelmämalleja ja raportteja.
Muistiinpano
Tämä artikkeli ei sisällä johdantoa yhdistelmämalleihin. Jos et ole perehtynyt yhdistelmämalleihin, suosittelemme, että luet ensin yhdistelmämallien käyttäminen Power BI Desktopissa -artikkelin.
Koska yhdistelmämallit koostuvat vähintään yhdestä DirectQuery-lähteestä, on tärkeää ymmärtää myös mallien suhteet, DirectQuery-mallit ja DirectQuery-mallin suunnitteluohjeet.
Yhdistelmämallin käyttötapaukset
Yhdistelmämalli yhdistää siis useita lähderyhmiä. Lähderyhmä voi edustaa tuotuja tietoja tai yhteyttä DirectQuery-lähteeseen. DirectQuery-lähde voi olla joko relaatiotietokanta tai toinen taulukkomalli, joka voi olla Power BI:n semanttinen malli tai Analysis Services -taulukkomalli. Kun taulukkomalli muodostaa yhteyden toiseen taulukkomalliin, sitä kutsutaan ketjuttamiseksi. Lisätietoja on artikkelissa Yhdistelmämallien käyttäminen Power BI Desktopissa.
Muistiinpano
Kun malli muodostaa yhteyden taulukkomalliin, mutta ei laajenna sitä lisätiedoilla, se ei ole yhdistelmämalli. Tässä tapauksessa kyseessä on DirectQuery-malli, joka muodostaa yhteyden etämalliin, joten se koostuu vain yhdestä lähderyhmästä. Voit luoda tämän tyyppisen mallin, jolla muokataan lähdemallin objektin ominaisuuksia, kuten taulukon nimeä, sarakkeen lajittelujärjestystä, muotoilumerkkijonoa tai muita.
Taulukkomalleihin yhdistäminen on erityisen tärkeää, kun laajennat yrityksen semanttista mallia (kun kyseessä on Power BI:n semanttinen malli tai Analysis Services -malli). Semanttinen yritysmalli on olennainen osa tietovaraston kehittämistä ja toimintaa. Se tarjoaa abstraktiokerroksen tietovaraston tietojen päälle, jotta voidaan esittää liiketoimintamääritelmiä ja terminologiaa. Sitä käytetään yleisesti linkkinä fyysisten tietomallien ja raportointityökalujen, kuten Power BI:n, välillä. Useimmissa organisaatioissa sitä hallitsee keskustiimi, minkä vuoksi sitä kuvataan suuryritykseksi. Lisätietoja on yrityksen BI-käyttöskenaariossa.
Voit harkita yhdistelmämallin kehittämistä seuraavissa tilanteissa:
- Mallisi voi olla DirectQuery-malli ja haluat parantaa suorituskykyä. Yhdistelmämallissa voit parantaa suorituskykyä määrittämällä kullekin taulukolle sopivan tallennustilan. Voit myös lisätä käyttäjän määrittämiä koosteita. Molemmat optimoinnit kuvataan myöhemmin tässä artikkelissa.
- Haluat yhdistää DirectQuery-mallin ja enemmän tietoja, jotka on tuotava malliin. Voit ladata tuotuja tietoja eri tietolähteestä tai lasketuista taulukoista.
- Haluat yhdistää vähintään kaksi DirectQuery-tietolähdettä yhdeksi malliksi. Nämä lähteet voivat olla relaatiotietokantoja tai muita taulukkomalleja.
Muistiinpano
Yhdistelmämallit eivät voi sisältää yhteyksiä tiettyihin ulkoisiin analytiikkatietokantoihin. Näihin tietokantoihin kuuluvat SAP Business Warehouse ja SAP HANA, kun SAP HANA -tietokantoja käsitellään monidimensioisena lähteenä.
Muiden mallien suunnitteluasetusten arvioiminen
Vaikka Power BI -yhdistelmämallit voivat ratkaista tiettyjä suunnitteluongelmia, ne voivat hidastaa suorituskykyä. Joissakin tilanteissa voi myös tapahtua odottamattomia laskentatuloksia (kuvataan myöhemmin tässä artikkelissa). Arvioi näistä syistä muita mallin rakenneasetuksia, kun ne ovat olemassa.
Malli kannattaa aina mahdollisuuksien mukaan kehittää tuontitilassa. Tämä tila tarjoaa parhaan suunnittelujoustovuuden ja parhaan suorituskyvyn. Tuontimallit eivät kuitenkaan aina pysty ratkaisemaan haasteita, jotka liittyvät suuriin tietomääriin tai lähes reaaliaikaisten tietojen raportointiin. Kummassakin tapauksessa voit harkita DirectQuery-mallia sillä oletetulla tavalla, että tiedot on tallennettu DirectQuery-tilan tukemaan yksittäiseen tietolähteeseen. Lisätietoja on artikkelissa DirectQuery-mallit Power BI Desktopissa.
Vihje
Jos tavoitteena on vain laajentaa olemassa olevaa taulukkomallia lisätiedillä aina kun mahdollista, lisää nämä tiedot olemassa olevaan tietolähteeseen.
Taulukon tallennustila
Yhdistelmämallissa voit määrittää tallennustilan tilan kullekin taulukolle (lukuun ottamatta laskettuja taulukoita).
- DirectQuery-: Suosittelemme, että asetat tämän tilan taulukoille, jotka edustavat suuria tietomääriä tai joiden on tuotettava lähes reaaliaikaisia tuloksia. Tietoja ei tuoda näihin taulukoihin. Yleensä nämä taulukot faktataulukoita, jotka ovat yhteenvetotaulukoita.
- Tuonti-: Suosittelemme, että asetat tämän tilan taulukoille, joita ei käytetä faktataulukoiden suodattamiseen ja ryhmittelyyn DirectQuery- tai Hybridi-tilassa. Se on myös ainoa vaihtoehto sellaisia taulukoita varten, jotka perustuvat lähteisiin, joita DirectQuery-tila ei tue. Lasketut taulukot ovat aina tuontitaulukoita.
- Kaksoistaulukko-: Suosittelemme, että asetat tämän tilan -dimensiotaulukoille, jos on olemassa mahdollisuus, että niille tehdään kyselyitä yhdessä samassa lähteessä olevien DirectQuery-faktataulukoiden kanssa.
- Hybrid: Suosittelemme, että asetat tämän tilan lisäämällä tuonti-osiot ja yhden DirectQuery-osion faktataulukkoon, kun haluat sisällyttää uusimmat tietojen muutokset reaaliaikaisesti tai kun haluat tarjota useimmin käytettyjen tietojen nopean käytön tuontiosioiden kautta niin, että tietovarastossa käytetään useita harvoin käytettyjä tietoja.
Power BI voi tehdä kyselyitä yhdistelmämalliin useissa eri tilanteissa.
- Kyselyt tuovat tai vain kaksoistaulukot: Power BI noutaa kaikki tiedot mallin välimuistista. Se tuottaa parhaan mahdollisen suorituskyvyn. Tämä tilanne on yleinen dimensiotaulukoille, joihin suodattimet tai osittajavisualisoinnit kyseleevät.
- Kyselyt saman lähteenkaksoistaulukoihin tai DirectQuery-taulukoihin: Power BI noutaa kaikki tiedot lähettämällä vähintään yhden alkuperäisen kyselyn DirectQuery-lähteeseen. Se tarjoaa hyvän suorituskyvyn erityisesti silloin, kun lähdetaulukoissa on asianmukaiset indeksit. Tämä tilanne on yleinen kyselyissä, jotka liittyvät kaksoisdimensiotaulukoihin ja DirectQuery-faktataulukoihin. Nämä kyselyt ovat lähderyhmän sisäisiä, joten kaikki yksi yhteen- tai yksi moneen -suhteet arvioidaan säännöllisiksi suhteiksi.
- Kyselyt saman lähteen kaksoistaulukoihin tai yhdistelmätaulukoihin: Tämä skenaario on kahden edellisen skenaarion yhdistelmä. Power BI noutaa tiedot mallin välimuistista, kun ne ovat käytettävissä tuontiosioissa. Muussa tapauksessa se lähettää vähintään yhden alkuperäisen kyselyn DirectQuery-lähteeseen. Se tuottaa parhaan mahdollisen suorituskyvyn, koska tietovarastoon tehdään kysely vain osittajalle, erityisesti silloin, kun lähdetaulukoissa on asianmukaiset indeksit. Mitä tulee kaksoisdimensiotaulukoihin ja DirectQuery-faktataulukoihin, nämä kyselyt ovat lähderyhmän sisäisiä, joten kaikki yksi yhteen- tai yksi moneen -suhteet arvioidaan säännöllisiksi suhteiksi.
- Kaikki muut kyselyt: Näihin kyselyihin liittyy ryhmien välisiä suhteita. Tämä johtuu joko siitä, että tuontitaulukko liittyy DirectQuery-taulukkoon, tai siitä, että kaksoistaulukko liittyy eri lähteessä olevaan DirectQuery-taulukkoon, jolloin se käyttäytyy tuontitaulukkona. Kaikki suhteet arvioidaan rajoitetuiksi suhteiksi. Tämä tarkoittaa myös sitä, että muihin kuin DirectQuery-taulukoihin käytetyt ryhmittelyt on lähetettävä DirectQuery-lähteeseen muodostettuina alikyselyinä (virtuaalitaulukot). Tässä tapauksessa alkuperäinen kysely voi olla tehoton erityisesti suurissa ryhmittelyjoukoissa.
Yhteenvetona suosittelemme seuraavaa:
- Harkitse tarkkaan, onko yhdistelmämalli oikea ratkaisu. Vaikka se mahdollistaa eri tietolähteiden mallitason integroinnin, se tuo myös mukanaan suunnittelun monimutkaisuuksia, joilla on mahdolliset seurauksensa (kuvataan myöhemmin tässä artikkelissa).
- Aseta tallennustilaksi DirectQueryn , kun taulukko on suuria tietomääriä sisältävä faktataulukko tai kun sen on tuotettava lähes reaaliaikaisia tuloksia.
- Harkitse yhdistelmätilan käyttämistä määrittämällä lisäävän päivityskäytännön ja reaaliaikaiset tiedot tai osittamalla faktataulukko TOM:n, TMSL:n tai kolmannen osapuolen työkalun avulla. Lisätietoja on artikkelissa Semanttisten mallien lisäävä päivitys ja reaaliaikaiset tiedot ja Kehittyneen tietomallin hallinnan käyttöskenaario.
- Aseta tallennustilaksi kaksoistaulukko, kun taulukko on dimensiotaulukko, ja siihen tehdään kysely yhdessä samaan lähderyhmään liittyvien DirectQuery- tai yhdistelmä faktataulukoiden kanssa.
- Määritä asianmukaiset päivitystiheydet, jotta kaksois- ja yhdistelmätaulukoiden (ja mahdollisten riippuvaisten laskettujen taulukoiden) mallin välimuisti säilyy synkronoituna lähdetietokantojen kanssa.
- Pyri varmistamaan tietojen eheys lähderyhmissä (mukaan lukien mallin välimuisti), koska rajoitetut suhteet poistavat kyselytulosten rivit, kun liittyvät sarakearvot eivät täsmää.
- Optimoi DirectQuery-tietolähteet mahdollisuuksien mukaan sopivilla indekseillä tehokkaiden liitosten, suodattamisen ja ryhmittelyn varmistamiseksi.
Käyttäjän määrittämät koosteet
Voit lisätä käyttäjän määrittämiä koosteita DirectQuery-taulukoihin. Niiden tarkoituksena on parantaa yksityiskohtaisempien kyselyiden suorituskykyä.
Kun koosteita tallennetaan mallin välimuistiin, ne toimivat tuontitaulukoina (vaikka niitä ei voi käyttää mallitaulukon tavoin). Kun lisäät tuontikoosteita DirectQuery-malliin, tuloksena on yhdistelmämalli.
Muistiinpano
Yhdistelmätaulukot eivät tue koosteita, koska osa osioista toimii tuontitilassa. Koosteita ei voi lisätä yksittäisen DirectQuery-osion tasolla.
Suosittelemme, että koostaminen noudattaa tätä perussääntöä: Sen rivien määrän tulisi olla vähintään kymmenenkertaa pienempi kuin pohjana olevassa taulukossa. Jos pohjana olevassa taulukossa on esimerkiksi miljardi riviä, koostetaulukon rivien ei pitäisi ylittää sataa miljoonaa riviä. Tämä sääntö varmistaa, että koosteen luomisesta ja ylläpitämisestä on riittävä suorituskykyhyöty.
Lähderyhmien väliset suhteet
Kun malliyhteys kattaa lähderyhmiä, sitä kutsutaan lähderyhmien väliseksi suhteeksi. Lähderyhmien väliset yhteydet ovat myös rajoitettuja suhteita, koska taattua "yksi"-puolta ei ole. Lisätietoja on kohdassa Suhteen arviointi.
Muistiinpano
Joissakin tilanteissa voit välttää lähderyhmien välisen suhteen luomisen. Lisätietoja on tämän artikkelin myöhemmässä kohdassa Synkronoi osittajat .
Kun määrität lähderyhmien välisiä suhteita, ota huomioon seuraavat suositukset.
- Käytä pienen kardinaliteetin yhteyssarakkeita: Parhaan suorituskyvyn vuoksi suosittelemme, että suhdesarakkeiden kardinaliteetti on pieni. Tämä tarkoittaa sitä, että niihin tulisi tallentaa alle 50 000 yksilöllistä arvoa. Tämä suositus koskee erityisesti taulukkomalleja ja muita kuin tekstisarakkeita.
- Vältä suurten tekstisuhteiden sarakkeiden käyttämistä: Jos sinun on käytettävä tekstisarakkeita suhteessa, laske suodattimen odotettu tekstin pituus kertomalla kardinaliteetti tekstisarakkeen keskimääräisellä pituudella. Tekstin mahdollisen pituuden tulee olla enintään 1 000 000 merkkiä.
- Ota suhteen askelväli: Jos mahdollista, luo suhteita korkeammalla rakeisuustasolla. Sen sijaan, että liität päivämäärätaulukon päivämääräavaimeen, käytä sen sijaan sen kuukausiavainta. Tämä suunnittelumenetelmä edellyttää, että liittyvässä taulukossa on kuukauden avainsarake eikä raporteissa voida näyttää päivittäisiä faktoja.
- Pyri luomaan yksinkertainen suhteiden rakenne: luo vain tarvittaessa lähderyhmien välinen suhde ja yritä rajoittaa yhteyspolun taulukoiden määrää. Tämä rakennemenetelmä auttaa parantamaan suorituskykyä ja välttämään moniselitteisiä suhdepolkuja.
Varoitus
Koska Power BI Desktop ei vahvista lähderyhmien välisiä suhteita perusteellisesti, on mahdollista luoda monitulkintaisia suhteita.
Lähderyhmien välinen suhdeskenaario 1
Ajattele monitasoista suhderakennetta ja sitä, miten se voisi tuottaa erilaisia, mutta kelvollisia tuloksia.
Tässä skenaariossa lähderyhmän Region taulukolla A on suhde Date-taulukkoon ja Sales-taulukkoon lähderyhmän B.
Region taulukon ja Date-taulukon välinen suhde on aktiivinen, kun taas Region taulukon ja Sales-taulukon välinen suhde on passiivinen. Lisäksi Region-taulukon ja Sales-taulukon välillä on aktiivinen yhteys, jotka kumpikin kuuluvat lähderyhmään B.
Sales-taulukko sisältää mittarin nimeltä TotalSales, ja Region-taulukko sisältää kaksi mittaria nimeltään RegionalSales ja RegionalSalesDirect.
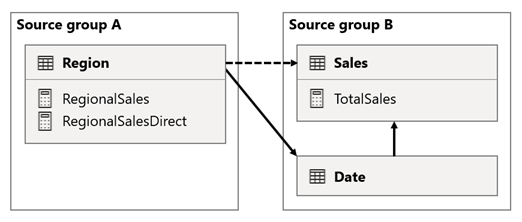
Tässä ovat mittarimääritykset.
TotalSales = SUM(Sales[Sales])
RegionalSales = CALCULATE([TotalSales], USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
RegionalSalesDirect = CALCULATE(SUM(Sales[Sales]), USERELATIONSHIP(Region[RegionID], Sales[RegionID]))
Huomaa, miten RegionalSales-mittari viittaa TotalSales-mittariin, kun taas RegionalSalesDirect-mittari ei. sen sijaan RegionalSalesDirect-mittari käyttää lauseketta SUM(Sales[Sales]), joka on TotalSales mittarin lauseke.
Ero tuloksessa on hienovarainen. Kun Power BI arvioi RegionalSales-mittarin, se käyttää Region-taulukon suodatinta sekä Sales- että Date-taulukkoon. Siksi suodatin leviää myös Date taulukosta Sales taulukkoon. Sen sijaan kun Power BI arvioi RegionalSalesDirect mittaria, se levittää suodattimen vain Region-taulukosta Sales-taulukkoon.
RegionalSales mittarin ja RegionalSalesDirect-mittarin palauttamat tulokset voivat vaihdella, vaikka lausekkeet ovat semanttisesti toisiaan vastaavia.
Tärkeä
Aina, kun käytät funktiota CALCULATE lausekkeella, joka on etälähderyhmässä, testaa laskentatulokset perusteellisesti.
Lähderyhmien välinen suhdeskenaario 2
Ajattele tilannetta, jossa lähderyhmien välisellä yhteydellä on suuren kardinaliteetin suhdesarakkeet.
Tässä skenaariossa Date-taulukko liittyy DateKey sarakkeiden Sales taulukkoon.
DateKey sarakkeiden tietotyyppi on kokonaisluku, johon tallennetaan kokonaislukuja, jotka käyttävät muotoa vvkkkkd muotoa. Taulukot kuuluvat eri lähderyhmiin. Lisäksi kyseessä on suuren kardinaliteetin suhde, koska Date taulukon aikaisin päivämäärä on 1.1.1900 ja viimeisin päivämäärä on 31.12.2100 . Taulukossa on siis yhteensä 73 414 riviä (yksi rivi kullekin päivämäärälle 1900–2100-aikavälillä).
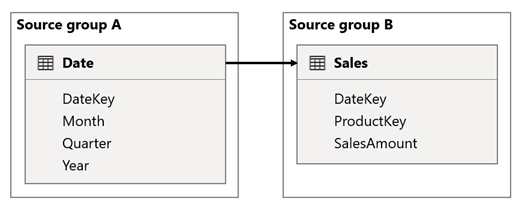
Huolenaiheena on kaksi tapausta.
Kun käytät Date taulukon sarakkeita suodattimina, suodatuksen levitys suodattaa Sales taulukon DateKey sarakkeen mittareiden arvioimiseksi. Kun suodatat yhden vuoden mukaan, kuten 2022, DAX-kysely sisältää suodatinlausekkeen, kuten Sales[DateKey] IN { 20220101, 20220102, …20221231 }. Kyselyn tekstin koko voi kasvaa erittäin suureksi, kun suodatinlausekkeen arvojen määrä on suuri tai kun suodatinarvot ovat pitkiä merkkijonoja. Power BI:n on kallista luoda pitkä kysely ja suorittaa kysely tietolähteelle.
Kun käytät Date taulukon sarakkeita – kuten Year, Quartertai Month– sarakkeiden ryhmittelynä, tuloksena on suodattimia, jotka sisältävät kaikki yksilölliset vuoden, vuosineljänneksen tai kuukauden yhdistelmät jaDateKey sarakearvot. Kyselyn merkkijonon koko, joka sisältää ryhmittelysarakkeiden ja suhdesarakkeen suodattimet, voi muuttua erittäin suureksi. Tämä pätee erityisesti silloin, kun ryhmittelysarakkeiden määrä ja/tai liitossarakkeen (DateKey-sarakkeen) kardinaliteetti on suuri.
Voit korjata suorituskykyyn liittyviä ongelmia kysymyksillä:
- Lisää
Date-taulukko tietolähteeseen, jolloin tuloksena on yksi lähderyhmämalli (eli se ei ole enää yhdistelmämalli). - Nostaa suhteen askelväliä. Voit esimerkiksi lisätä
MonthKey-sarakkeen molempiin taulukoihin ja luoda yhteyden kyseisiin sarakkeisiin. Kun nostat yhteyden askelväliä, menetät kuitenkin mahdollisuuden raportoida päivittäisestä myyntitoiminnasta (ellet käytäDateKey-sarakettaSales-taulukosta).
Lähderyhmien välinen suhdeskenaario 3
Ajattele tilannetta, jossa taulukoiden välillä ei ole vastaavia arvoja lähderyhmien välisessä suhteessa.
Tässä skenaariossa lähderyhmän Date taulukolla B on yhteys Sales-taulukkoon kyseisessä lähderyhmässä sekä lähderyhmän ATarget taulukkoon. Kaikki suhteet ovat yksi moneen Date-taulukosta, joka koskee Year sarakkeita.
Sales taulukko sisältää SalesAmount -sarakkeen, joka tallentaa myyntimäärät, kun taas Target taulukko sisältää TargetAmount-sarakkeen, joka tallentaa tavoitemäärät.
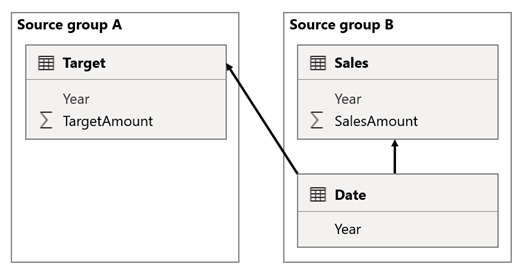
Date-taulukko sisältää vuodet 2021 ja 2022.
Sales-taulukko sisältää vuosien 2021 (100) ja 2022 (200) myyntimäärät, kun taas Target taulukko tallentaa tavoitemäärät vuosille 2021 (100), 2022 (200), ja 2023 (300)eli tulevan vuoden.
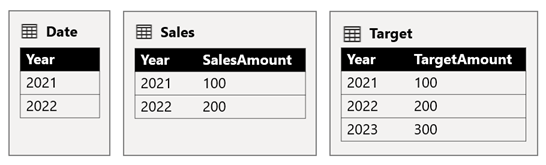
Kun Power BI -taulukon visualisointi tekee kyselyn yhdistelmämalliin ryhmittelemällä Date-taulukon Year sarakkeen ja laskemalla yhteen SalesAmount- ja TargetAmount-sarakkeet, siinä ei näytetä vuoden 2023 tavoitesummaa. Tämä johtuu siitä, että lähderyhmien välinen suhde on rajoitettu, joten se käyttää INNER JOIN semantiikkaa, joka poistaa rivit, joilla ei ole vastaavaa arvoa kummallakaan puolella. Se tuottaa kuitenkin oikean tavoitesumman (600), koska Date taulukkosuodatin ei koske sen arviointia.
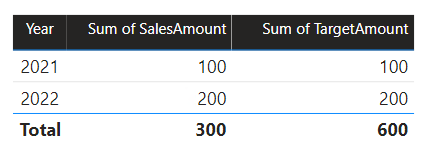
Jos Date taulukon ja Target taulukon välinen suhde on lähderyhmän sisäinen suhde (olettaen, että Target taulukko kuuluu lähderyhmään B), visualisointi sisältää (Tyhjä) vuoden, jolloin vuoden 2023 tavoitesumma näytetään (ja mitkä tahansa muut yhteensopimattomat vuodet).
Tärkeä
Jos haluat välttää virheelliset raportit, varmista, että suhdesarakkeissa on vastaavia arvoja, kun dimensio- ja faktataulukot sijaitsevat eri lähderyhmissä.
Lisätietoja rajoitetuista suhteista on kohdassa Yhteyden arviointi.
Laskutoimitukset
Ota huomioon tietyt rajoitukset, kun lisäät laskettuja sarakkeita ja laskentaryhmiä yhdistelmämalliin.
Lasketut sarakkeet
DirectQuery-taulukkoon lisätyt lasketut sarakkeet, jotka hankkivat tietonsa relaatiotietokannasta, kuten Microsoft SQL Serveristä, on rajoitettu lausekkeisiin, jotka toimivat yhdellä rivillä kerrallaan. Nämä lausekkeet eivät voi käyttää DAX-iteraattorifunktioita, kuten SUMX, tai suodatinkontekstin muokkausfunktioita, kuten CALCULATE.
Muistiinpano
Ei ole mahdollista lisätä laskettuja sarakkeita tai laskettuja taulukoita, jotka riippuvat ketjuttuista taulukkomalleista.
DirectQuery-etätaulukon lasketun sarakkeen lauseke on rajoitettu vain rivin sisäiseen arviointiin. Voit kuitenkin luoda tällaisen lausekkeen, mutta se aiheuttaa virheen, kun sitä käytetään visualisoinnissa. Jos esimerkiksi lisäät lasketun sarakkeen directquery-etätaulukkoon nimeltä DimProduct käyttämällä lauseketta [Product Sales] / SUM (DimProduct[ProductSales]), voit tallentaa lausekkeen mallissa. Se aiheuttaa kuitenkin virheen, kun sitä käytetään visualisoinnissa, koska se rikkoo rivin sisäistä arviointirajoitusta.
Lasketut sarakkeet, jotka on sen sijaan lisätty DirectQuery-etätaulukkoon, jonka taulukkomalli on joko Power BI:n semanttinen malli tai Analysis Services -malli, ovat joustavampia. Tässä tapauksessa kaikki DAX-funktiot sallitaan, koska lauseke arvioidaan lähteen taulukkomallissa.
Monet lausekkeet edellyttävät, että Power BI muodostaa lasketun sarakkeen, ennen kuin sitä käytetään ryhmänä tai suodattimena tai koostaa se. Kun laskettu sarake muodostetaan suurelle taulukolle, se voi tulla kalliiksi suorittimen ja muistin suhteen sen mukaan, mikä on lasketun sarakkeen sarakkeiden kardinaliteetti. Tässä tapauksessa suosittelemme, että lisäät nämä lasketut sarakkeet lähdemalliin.
Muistiinpano
Kun lisäät laskettuja sarakkeita yhdistelmämalliin, muista testata kaikki mallin laskutoimitukset. Yläpuoliset laskutoimitukset eivät ehkä toimi oikein, koska ne eivät ole harkinneet niiden vaikutusta suodatinkontekstiin.
Laskentaryhmät
Jos lähderyhmässä on laskentaryhmiä, jotka muodostavat yhteyden Power BI:n semanttiseen malliin tai Analysis Services -malliin, Power BI voi palauttaa odottamattomia tuloksia. Lisätietoja on kohdassa Laskentaryhmät, Kyselyn ja mittarin arviointi.
Mallin rakenne
Sinun tulee aina optimoida Power BI -malli ottamalla käyttöön tähtirakenne.
Vihje
Lisätietoja on kohdassa Tutustu tähtirakenteeseen ja sen merkitykseen Power BI:ssä.
Muista luoda dimensiotaulukoita, jotka ovat erillään faktataulukoista, jotta Power BI voi tulkita liitokset oikein ja tuottaa tehokkaita kyselysuunnitelmia. Vaikka nämä ohjeet koskevat mitä tahansa Power BI -mallia, se pätee erityisesti malleihin, joiden tunnistat tulevan yhdistelmämallin lähderyhmäksi. Se mahdollistaa muiden taulukoiden yksinkertaisemman ja tehokkaamman integroinnin jatkojalostusmalleihin.
Vältä aina mahdollisuuksien mukaan sitä, että yhteen lähderyhmään kuuluvat dimensiotaulukot liittyvät faktataulukkoon eri lähderyhmässä. Tämä johtuu siitä, että on parempi käyttää lähderyhmän sisäisiä suhteita kuin lähderyhmien välisiä suhteita, erityisesti suuren kardinaliteetin yhteyssarakkeissa. Kuten aiemmin kuvattiin, lähderyhmien väliset suhteet luottavat siihen, että suhdesarakkeissa on vastaavia arvoja, muuten raportin visualisoinneissa voidaan näyttää odottamattomia tuloksia.
Rivitason suojaus
Jos mallissasi on käyttäjän määrittämiä koosteita, tuotujen taulukoiden laskettuja sarakkeita tai laskettuja taulukoita, varmista, että kaikki rivitason suojaus (RLS) on määritetty oikein ja testattu.
Jos yhdistelmämalli muodostaa yhteyden muihin taulukkomalleihin, rivitason suojauksen sääntöjä sovelletaan vain lähderyhmässä (paikallinen malli), jossa ne on määritetty. Niitä ei käytetä muissa lähderyhmissä (etämalleissa). Et myöskään voi määrittää RLS-sääntöjä toisesta lähderyhmästä peräisin olevalle taulukolle tai määrittää RLS-sääntöjä paikallisessa taulukossa, jolla on suhde toiseen lähderyhmään.
Raportin suunnittelu
Joissakin tilanteissa voit parantaa yhdistelmämallin suorituskykyä suunnittelemalla optimoidun raportin asettelun.
Yhden lähderyhmän visualisoinnit
Luo visualisointeja, jotka käyttävät yhden lähderyhmän kenttiä aina kun mahdollista. Tämä johtuu siitä, että visualisointien luomat kyselyt toimivat paremmin, kun tulos noudetaan yhdestä lähderyhmästä. Harkitse kahden vierekkäin asetetun visualisoinnin luomista, jotka hakevat tietoja kahdesta eri lähderyhmästä.
Synkronoi osittajat -osittajan käyttäminen
Joissakin tilanteissa voit määrittää synkronoinnin osittajia , jotta malliin ei luoda lähderyhmien välistä suhdetta. Sen avulla voit yhdistää lähderyhmiä visuaalisesti , mikä toimii paremmin.
Harkitse skenaariota, jossa mallissa on kaksi lähderyhmää. Kullakin lähderyhmällä on tuotedimensiotaulukko, jota käytetään jälleenmyyjän ja Internet-myynnin suodattamiseen.
Tässä skenaariossa lähderyhmän A sisältää Product taulukon, joka liittyy ResellerSales-taulukkoon. Lähderyhmän B sisältää InternetSales taulukkoon liittyvän Product2-taulukon. Lähderyhmien välisiä suhteita ei ole.
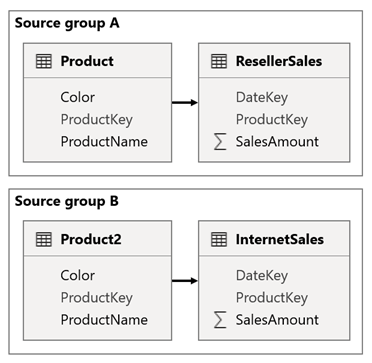
Raportissa lisäät osittajan, joka suodattaa sivun Product-taulukon Color-sarakkeen avulla. Osittaja suodattaa oletusarvoisesti ResellerSales taulukon, mutta ei InternetSales taulukkoa. Sen jälkeen lisäät piilotetun osittajan Product2-taulukon Color-sarakkeella. Kun määrität samanlaisen ryhmän nimen (löytyy synkronoi osittajat Lisäasetukset) näkyvään osittajaan käytetyt suodattimet leviävät automaattisesti piilotettuun osittajaan.
Muistiinpano
Synkronoi osittajat voivat välttää lähderyhmien välisen suhteen luomisen, mutta se kasvattaa mallin rakenteen monimutkaisuutta. Muista kouluttaa muita käyttäjiä siitä, miksi suunnittelit mallin dimensiotaulukoiden kaksoiskappaleilla. Vältä sekaannuksia piilottamalla dimensiotaulukoita, joita et halua muiden käyttäjien käyttävän. Voit myös lisätä kuvaustekstiä piilotettuihin taulukoihin niiden tarkoituksen dokumentoimiseksi.
Lisätietoja on kohdassa Synkronoi erilliset osittajat.
Muita ohjeita
Seuraavassa on joitakin muita ohjeita, joiden avulla voit suunnitella ja ylläpitää yhdistelmämalleja.
- suorituskyky ja skaalaus: Jos raporttisi oli aiemmin reaaliaikaisesti yhdistetty Power BI:n semanttiseen malliin tai Analysis Services -malliin, Power BI -palvelu voi käyttää visuaalisia välimuisteja uudelleen kaikissa raporteissa. Kun olet muuntanut reaaliaikaisen yhteyden ja luonut paikallisen DirectQuery-mallin, raportit eivät enää hyödy välimuisteista. Tämän seurauksena suorituskyky saattaa hidastua tai jopa uudelleen lataaminen epäonnistuu. Lisäksi Power BI -palvelun kuormitus kasvaa, mikä saattaa edellyttää kapasiteetin suurentamista tai kuormituksen jakamista muihin kapasiteetteihin. Lisätietoja tietojen päivittämisestä ja tallentamisesta välimuistiin on artikkelissa Tietojen päivittäminen Power BI:ssä.
- uudelleen: Emme suosittele yhdistelmämallien käyttämien semanttisten mallien nimeämistä uudelleen tai niiden työtilojen nimeämistä uudelleen. Tämä johtuu siitä, että yhdistelmämallit yhdistetään Power BI:n semanttisiin malleihin käyttämällä työtilan ja semanttisen mallin nimiä (ei niiden sisäisiä yksilöllisiä tunnisteita). Semanttisen mallin tai työtilan nimeäminen uudelleen voi rikkoa yhdistelmämallisi käyttämät yhteydet.
- Governance: Emme suosittele, että yksittäinen versio totuudesta malli on yhdistelmämalli. Tämä johtuu siitä, että se olisi riippuvainen muista tietolähteistä tai malleista, mikä voi päivittyessä aiheuttaa yhdistelmämallin rikkomisen. Suosittelemme sen sijaan, että julkaiset yrityksen semanttisen mallin yksittäisenä versiona totuudesta. Pidä tätä mallia luotettavana pohjana. Muut tietojen mallintajat voivat sitten luoda yhdistelmämalleja, jotka laajentavat perusmallia erikoismallien luomiseksi.
Tietojen historiatietojen : Käytätietojen periytymisen jasemanttisen mallin vaikutusanalyysia ominaisuuksien ennen yhdistelmämallin muutosten julkaisemista. Nämä ominaisuudet ovat käytettävissä Power BI -palvelussa, ja ne auttavat sinua ymmärtämään, miten semanttiset mallit liittyvät toisiinsa ja miten niitä käytetään. On tärkeää ymmärtää, että et voi suorittaa vaikutusanalyysia ulkoisille semanttisissa malleissa, jotka näytetään tietojen historiatietojen näkymässä mutta jotka itse asiassa sijaitsevat toisessa työtilassa. Jos haluat suorittaa vaikutusanalyysin ulkoisessa semanttisessa mallissa, sinun on siirryttävä lähdetyötilaan.- rakennepäivitykset: Yhdistelmämalli on päivitettävä Power BI Desktopissa, kun rakenteen muutoksia tehdään yläpuolisiin tietolähteisiin. Tämän jälkeen sinun on julkaistava malli uudelleen Power BI -palveluun. Muista testata laskelmat ja riippuvaiset raportit perusteellisesti.
Liittyvä sisältö
Saat lisätietoja tähän artikkeliin liittyen tutustumalla seuraaviin resursseihin.
- Yhdistelmämallien käyttäminen Power BI Desktopissa
- Mallien suhteet Power BI Desktopissa
- DirectQuery-mallit Power BI Desktopissa
- DirectQueryn käyttö Power BI Desktopissa
- Tallennustilan tila Power BI Desktopissa
- Käyttäjän määrittämät koosteet
- Kysyttävää? Voit esittää kysymyksiä Fabric-yhteisön
- Ehdotuksia? Edistä ideoita Fabric- parantamiseksi