Muistiinpano
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää kirjautua sisään tai vaihtaa hakemistoa.
Tämän sivun käyttö edellyttää valtuutusta. Voit yrittää vaihtaa hakemistoa.
Klusteriarvot luovat automaattisesti samankaltaisia ryhmiä käyttämällä epätarkkaa vastaavuusalgoritmia, ja sitten kunkin sarakkeen arvo yhdistetään parhaiten sovitettuun ryhmään. Tämä muunnos on hyödyllinen, kun työskentelet datan kanssa, jossa on monia eri variaatioita samasta arvosta, ja sinun täytyy yhdistää arvot johdonmukaisiksi ryhmiksi.
Kuvitellaan esimerkkitaulukkoa, jossa on id-sarakke, joka sisältää joukon ID-numeroita, sekä Person-sarakke, joka sisältää joukon eri tavoin kirjoitettuja ja isolla kirjattuja versioita nimistä Miguel, Mike, William ja Bill.
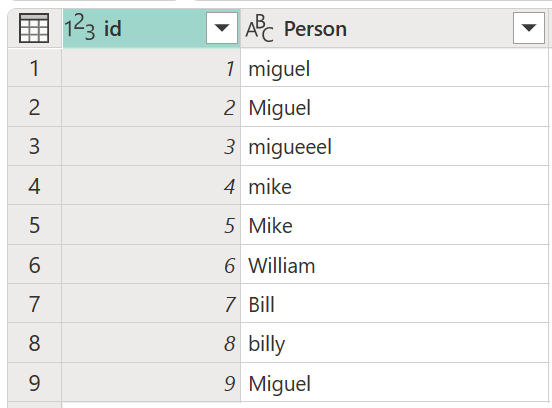
Tässä esimerkissä etsimäsi lopputulos on taulukko, jossa on uusi sarakke, joka näyttää oikeat arvoryhmät Henkilö-sarakkeesta, eikä kaikkia saman sanan eri variaatioita.
Note
Klusteriarvot -ominaisuus on saatavilla vain Power Query Onlinessa.
Luo klusterisarake
Arvojen ryhmittelyyn valitse ensin Henkilö-sarakke, mene nauhan Lisää-sarakkeen välilehdelle ja valitse sitten Klusteriarvot-vaihtoehto.
![]()
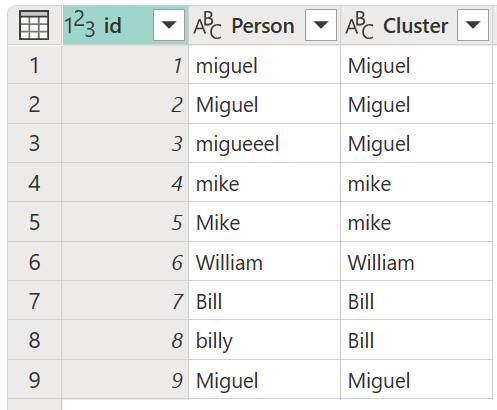
Klusterin arvot -valintaikkunasta vahvista sarakke, jota haluat käyttää klustereiden luomiseen, ja syötä sarakkeen uusi nimi. Tässä tapauksessa nimeä tämä uusi sarake Clusteriksi.
Tämän operaation tulos on esitetty seuraavassa kuvassa.
Note
Jokaiselle arvoklusterille Power Query valitsee valitusta sarakkeesta yleisimmän instanssin "kanoniseksi" instanssiksi. Jos useita tapauksia esiintyy samalla tiheydellä, Power Query valitsee ensimmäisen.
Sumeiden klusterivaihtoehtojen käyttö
Seuraavat vaihtoehdot ovat saatavilla arvojen klusterointiin uuteen sarakkeeseen:
- Samankaltaisuuskynnys (valinnainen): Tämä vaihtoehto osoittaa, kuinka samankaltaisia kahden arvon on oltava ryhmiteltäväksi. Nollan (0) minimiasetus saa kaikki arvot ryhmittelemään yhteen. Maksimiasetus 1 sallii ryhmitellä vain täsmälleen täsmälleen täsmäävät arvot. Oletusarvo on 0,8.
- Sivusija: Kun tekstimerkkijonoja verrataan, sijako jätetään huomiotta. Tämä vaihtoehto on oletuksena käytössä.
- Ryhmittele yhdistämällä tekstiosia: Algoritmi pyrkii yhdistämään tekstiosia (kuten yhdistämällä Micro- ja soft-osia Microsoftiin) arvojen ryhmittämiseksi.
- Näytä samankaltaisuuspisteet: Näyttää samankaltaisuuspisteet syötearvojen ja laskettujen edustavien arvojen välillä epämääräisen klusteroinnin jälkeen.
- Muunnostaulu (valinnainen): Voit valita muunnostaulun, joka yhdistää arvot (kuten MSFT:n kartoittaminen Microsoftiin) ryhmitelläksesi ne yhteen.
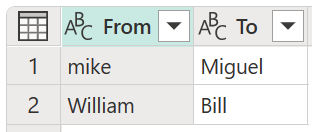
Tässä esimerkissä käytetään uutta muunnostaulukkoa nimeltä My transform table osoittamaan, miten arvot voidaan kartoittaa. Tässä muunnostaulukossa on kaksi saraketta:
- Lähettäjä: Tekstimerkkijono, jota etsit taulukostasi.
- Vastaanottaja: Tekstimerkkijono, jota käytetään korvaamaan tekstimerkkijono From-sarakkeessa.
Tärkeää
On tärkeää, että muunnostaulukossa on samat sarakkeet ja sarakkeen nimet kuin edellisessä kuvassa (ne täytyy nimetä "From" ja "To"), muuten Power Query ei tunnista tätä taulukkoa muunnostauluksi, eikä muunnosta tapahdu.
Käyttämällä aiemmin luotua kyselyä kaksoisklikkaa Clustered values -vaihetta ja laajenna Fuzzy cluster -valikkoon Cluster values -valintaikkunassa. Fuzzy cluster -asetuksissa ota käyttöön Näytä samankaltaisuuspisteet -vaihtoehto. Muunnostaululle (valinnainen) valitse kysely, jossa on muunnostaulu.
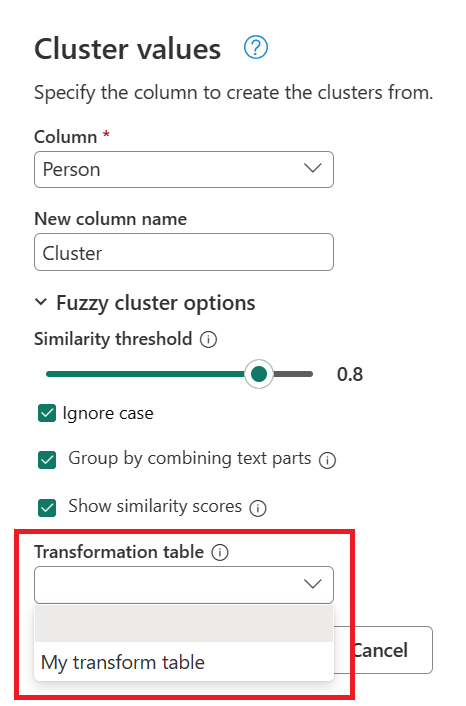
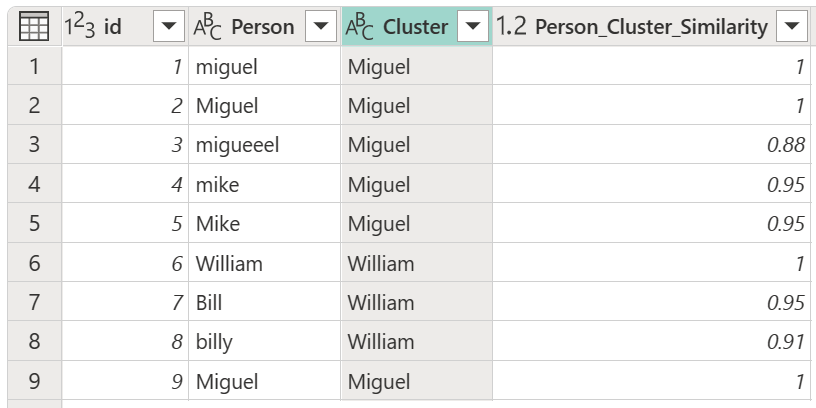
Kun olet valinnut muunnostaulukon ja ottanut käyttöön Näytä samankaltaisuuspisteet -vaihtoehdon, valitse OK. Tämän operaation tuloksena saat taulukon, joka sisältää samat id- ja Person-sarakkeet kuin alkuperäinen taulukko, mutta sisältää myös kaksi uutta saraketta nimeltä Cluster ja Person_Cluster_Similarity. Cluster-sarakkeessa on oikein kirjoitetut ja isolla kirjaimilla kirjoitetut nimet Miguel Miguelin ja Miken versioille sekä William Billin, Billin ja Williamin nimille. Person_Cluster_Similarity sarakkeessa on kunkin nimen samankaltaisuuspisteet.
Muunnostaulukon periaatteet
Saatat huomata, että edellisen osion muunnostaulukko näytti näyttävän, että Mike-instanssit on vaihdettu Migueliksi ja Williamin instanssit Billiksi. Kuitenkin taulukossa Bill ja "billy" muutettiin sen sijaan muotoon William. Muunnostaulukossa muunnostaulukko ei ole suora From to To -polku, vaan symmetrinen klusteroinnin aikana, mikä tarkoittaa, että "Mike" vastaa "Miguelia" ja päinvastoin. Muunnostaulukossa annettujen ekvivalenttien tulos riippuu seuraavista säännöistä:
- Jos enemmistö on identtisiä arvoja, nämä arvot ovat etusijalla ei-identtisiin arvoihin nähden.
- Jos arvoja ei ole enemmistöä, ensimmäisenä ilmestyvä arvo menee etusijalle.
Esimerkiksi tässä artikkelissa käytetyssä alkuperäisessä taulukossa Miguelin versiot (sekä "miguel" että Miguel) Person-sarakkeessa muodostavat suurimman osan nimien Miguel ja Mike esiintymistä. Lisäksi nimi Miguel alkukirjaimilla muodostaa suurimman osan nimestä Miguel. Näin ollen yhdistämällä Miguel ja sen derivaatat sekä Mike ja sen derivaatat muunnostaulukkoon, nimi Miguel käytetään Cluster-sarakkeessa .
Kuitenkin nimillä William, Bill ja "billy" ei ole enemmistöä, koska kaikki kolme ovat ainutlaatuisia. Koska William esiintyy ensimmäisenä, William esiintyy Cluster-sarakkeessa. Jos "billy" olisi esiintynyt ensin taulukossa, "billy" olisi käytetty Cluster-sarakkeessa . Koska arvoista ei ole enemmistöä, käytetään yksittäisten nimien sijamuotoa. Toisin sanoen, jos William on ensimmäinen, Williamin isolla "W" käytetään tulosarvona; Jos "billy" on ensimmäinen, käytetään "billy" pienellä "b"-kirjaimella.