Activités client nécessaires
Pré-incident
Pour les services Azure
- Familiarisez-vous avec Azure Service Health dans le portail Azure. Cette page servira de « guichet unique » lors d'un incident.
- Utilisez des alertes Service Health, que vous pouvez configurer pour produire automatiquement des notifications lorsque des incidents Azure se produisent
Pour Power BI
- Familiarisez-vous avec Service Health dans le Centre d’administration Microsoft 365. Cette page servira de « guichet unique » lors d'un incident.
- Utilisez l’application mobile Centre d’administration Microsoft 365 pour obtenir des notifications automatiques en cas d’incident de service
Pendant l’incident
Pour les services Azure
- Azure Service Health dans le portail de gestion Azure fournit les dernières mises à jour
- Si vous n’arrivez pas à accéder à Service Health, reportez-vous à la page État d’Azure
- Si vous n’arrivez pas à accéder à la page État, allez à @AzureSupport sur X (anciennement Twitter)
- Si l'impact/les problèmes ne correspondent pas à l'incident (ou persistent après l'atténuation), contactez le service d'assistance pour créer un ticket d'assistance.
Pour Power BI
- La page Service Health dans le Centre d’administration Microsoft 365 fournit les dernières mises à jour
- Si vous n’arrivez pas à accéder à Service Health, reportez-vous à la page État de Microsoft 365
- Si l’impact ou les problèmes ne correspondent pas à l’incident (ou si les problèmes persistent après atténuation), les clients doivent créer un ticket de support de service.
Après la reprise d’activité Microsoft
Pour plus d’informations, consultez les sections ci-dessous.
Après l’incident
Pour les services Azure
- Microsoft va publier un rapport post-incident sur le portail Azure - Service Health
Pour Power BI
- Microsoft va publier un rapport post-incident sur le Centre d’administration Microsoft 365 - Service Health
Processus Attendre Microsoft
Le processus « Wait for Microsoft » consiste simplement à attendre que Microsoft récupère tous les composants et services dans la région primaire affectée. Une fois la récupération effectuée, validez la liaison entre la plateforme de données et les services partagés d’entreprise ou autres services, ainsi que la date du jeu de données, puis exécutez les processus nécessaires à la mise à jour du système à la date actuelle.
Une fois ce processus achevé, la validation des experts techniques et commerciaux peut être réalisée, ce qui permet aux parties prenantes d'approuver le rétablissement des services.
Redéployer en cas de sinistre
Dans le cas d'une stratégie de « redéploiement en cas de sinistre », le processus de haut niveau suivant peut être décrit.
Récupérer Contoso – Services partagés d’entreprise et systèmes sources

- Cette étape est un prérequis à la récupération de la plateforme de données
- Cette étape est normalement effectuée par les différents groupes de support opérationnel Contoso chargés des services partagés d’entreprise et des systèmes sources opérationnels.
Récupérer les services Azure Les services Azure font référence aux applications et services qui constituent l’offre cloud Azure, et qui sont disponibles dans la région secondaire pour le déploiement.

Les services Azure font référence aux applications et services qui constituent l’offre cloud Azure, et qui sont disponibles dans la région secondaire pour le déploiement.
- Cette étape est un prérequis à la récupération de la plateforme de données
- Cette étape serait réalisée par Microsoft et d'autres partenaires de plateforme en tant que service (PaaS)/logiciel en tant que service (SaaS).
Récupérer les bases de la plateforme de données
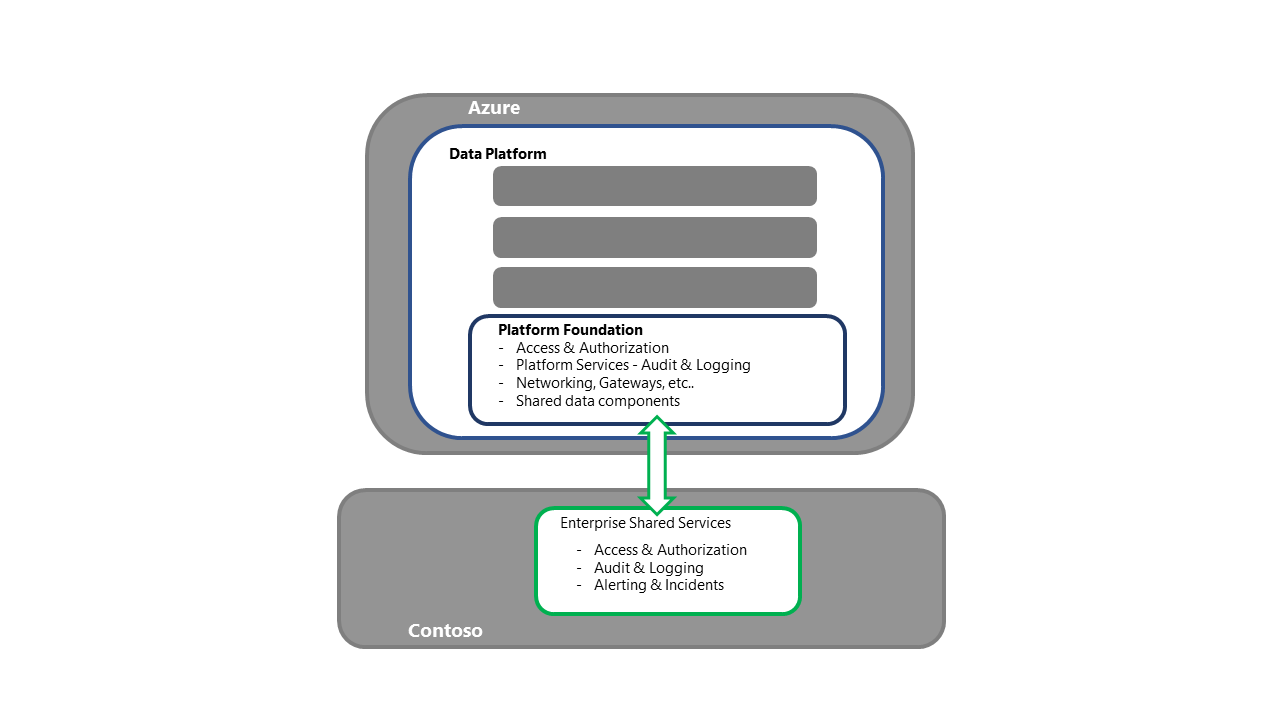
- Cette étape est le point d’entrée des activités de récupération de la plateforme
- Pour la stratégie de redéploiement, chaque composant ou service nécessaire est généralement acheté et déployé dans la région secondaire
- Pour voir le détail des composants et des stratégies de déploiement, consultez la section Services et composants Azure de cette série.
- Ce processus doit également inclure des activités telles que la liaison aux services partagés d’entreprise, la vérification de la connectivité aux accès ou aux authentifications, ainsi que la vérification du bon fonctionnement du déplacement des journaux, tout en garantissant la connectivité aux processus en amont et en aval
- Les données et les traitement doivent être vérifiés. Par exemple, la validation de l’horodatage de la plateforme récupérée
- Si vous n’êtes pas sûr de l’intégrité des données, vous pouvez remontrer encore davantage dans le temps avant d’exécuter le nouveau processus de mise à jour de la plateforme
- Le fait d’avoir un ordre de priorité pour les processus (en fonction de l’impact sur l’entreprise) vous aidera à orchestrer la récupération
- Cette étape doit être close par la validation technique, sauf si les utilisateurs professionnels interagissent directement avec les services. Si c’est le cas, il devra y avoir une étape de validation métier
- Une fois la validation achevée, les équipes chargées des solutions individuelles sont chargées de lancer leur propre processus de reprise après sinistre (DR).
- Ce transfert doit inclure la confirmation de l’horodatage actuel des données et des processus
- Si des processus de données d’entreprise importants sont exécutés, les solutions doivent en être informées (flux entrants et sortants, par exemple)
Récupérer les solutions hébergées par la plateforme
- Chaque solution doit avoir son propre runbook de récupération d’urgence. Les runbooks doivent contenir au moins les parties prenantes métier désignées qui testeront et confirmeront que la récupération de service a été effectuée
- En fonction de la contention ou de la priorité des ressources, les solutions ou charges de travail clés peuvent être prioritaires par rapport à d’autres (des processus d’entreprise importants par rapport à des labos ad hoc, par exemple).
- Une fois les étapes de validation terminées, le processus est transféré aux solutions en aval afin qu’elles puissent démarrer leur propre processus de récupération d’urgence
Transfert aux systèmes dépendants en avalSchéma montrant les systèmes dépendants.
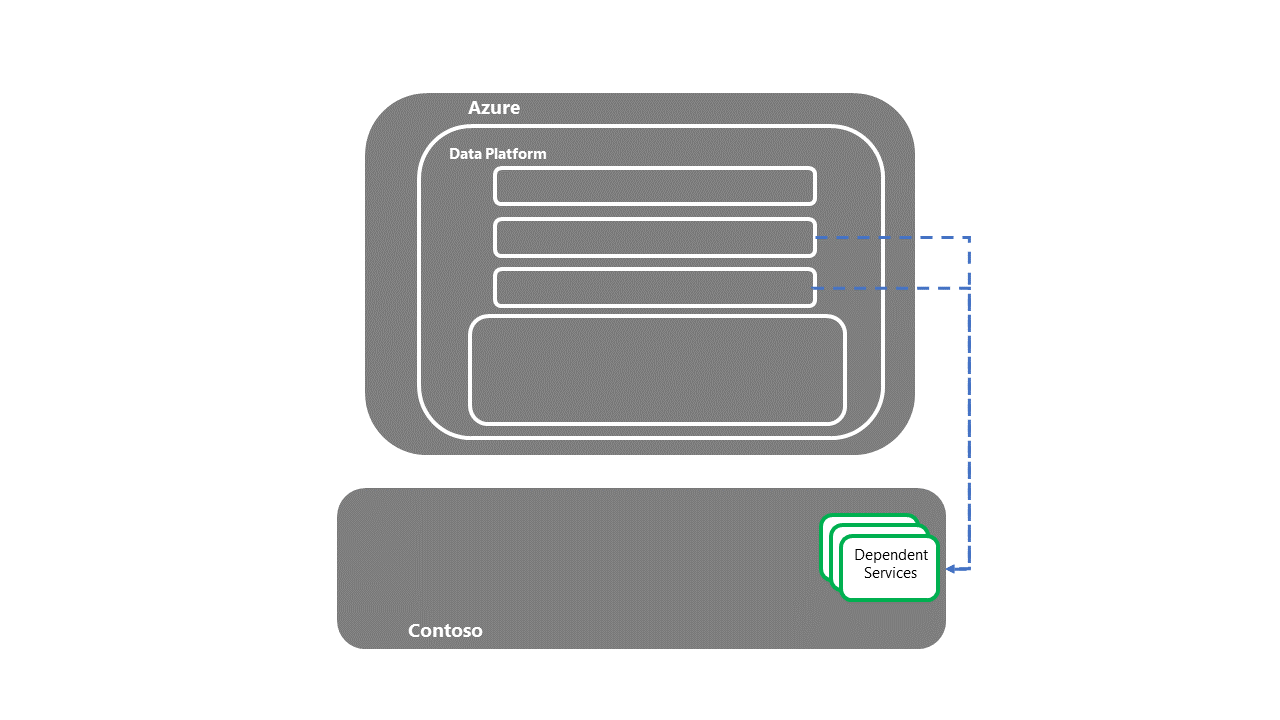
- Une fois les services dépendants récupérés, le processus de récupération d’urgence E2E est terminé
Remarque
Bien qu'il soit théoriquement possible d'automatiser complètement un processus DR E2E, c'est peu probable étant donné le risque de l'événement par rapport au coût des activités SDLC nécessaires pour couvrir le processus E2E.
Rétablissement vers la région primaire Le processus de rétablissement consiste à replacer le service de plateforme de données et ses données dans la région primaire, une fois celui-ci disponible pour l’utilisateur de l’authentification de base.
Selon la nature des systèmes sources et des différents processus de données, le rétablissement de la plateforme de données peut être effectué indépendamment des autres parties de l’écosystème de données.
Il est conseillé aux clients d'examiner les dépendances de leur propre plateforme de données (en amont et en aval) pour prendre la décision appropriée. La section suivante suppose une récupération indépendante de la plateforme de données.
- Une fois que tous les composants et services nécessaires sont disponibles dans la région primaire, les clients effectuent un test de détection de fumée pour valider la récupération Microsoft
- La configuration du composant ou du service est validée. Les deltas seraient traités par le biais d’un redéploiement à partir du contrôle de code source
- La date du système dans la région primaire est établie entre les composants avec état. Le delta entre la date établie et la date/l'horodatage dans la région secondaire doit être traité en ré-exécutant ou en rejouant les processus d'ingestion de données à partir de ce point de transfert.
- Avec l’approbation des parties prenantes métier et techniques, une fenêtre est sélectionnée pour le rétablissement. Idéalement, pendant une période calme dans l’activité système et le traitement
- Pendant le rétablissement, la région primaire est généralement synchronisée avec la région secondaire, avant que le système ne soit basculé
- Après une période d’exécution parallèle, la région secondaire est déconnectée du système
- Les composants de la région secondaire sont supprimés ou retirés, en fonction de la stratégie de récupération d’urgence sélectionnée
Processus Warm Spare
Pour une stratégie « Warm Spare », le processus de haut niveau est étroitement aligné sur celui du « Redeploy on Disaster », la principale différence étant que les composants ont déjà été achetés dans la région secondaire. Cette stratégie élimine le risque de conflit de ressources d’autres organisations qui cherchent à effectuer leur propre récupération d’urgence dans cette région.
Processus Hot Spare
La stratégie « Hot Spare » signifie que les services de la plateforme, y compris les systèmes PaaS et d'infrastructure en tant que service (IaaS), persisteront malgré le sinistre, les systèmes secondaires fonctionnant en tandem avec les systèmes primaires. Comme pour la stratégie « Warm Spare », cette stratégie élimine le risque de conflit de ressources d’autres organisations qui cherchent à effectuer leur propre récupération d’urgence dans la même région.
Les clients Hot Spare monitorent la récupération Microsoft des composants et services dans la région primaire. Une fois la récupération terminée, les clients valident les systèmes de la région primaire et procèdent au rétablissement vers la région primaire. Ce processus est similaire au processus de basculement de la récupération d’urgence, c’est-à-dire vérifier le codebase et les données disponibles, en redéployant si nécessaire.
Notes
Notez que toutes les métadonnées système doivent être cohérentes entre les deux régions.
- Une fois le rétablissement effectué vers la région primaire, les équilibreurs de charge système peuvent être mis à jour pour rétablir la région primaire dans la topologie système. Si cette option est disponible, vous pouvez effectuer un contrôle de validité de mise en production afin d’activer de manière incrémentielle la région primaire pour le système.
Structure du plan de récupération d’urgence
Un plan de récupération d’urgence efficace fournit un guide pas à pas pour la récupération des services qui peut être exécutée par le personnel technique Azure. Voici donc une proposition de structure MVP pour un plan de récupération d’urgence.
- Exigences du processus
- Tout détail spécifique au processus DR du client, tel que l'autorisation correcte requise pour démarrer le DR, et prendre les décisions clés concernant la reprise si nécessaire (y compris la « définition de ce qui est fait »), la référence du ticket DR du support de service, et les détails de la salle de crise.
- Confirmation des ressources, notamment le responsable de la récupération d’urgence et son remplaçant. Toutes les ressources doivent être documentées avec des contacts principaux et secondaires, des chemins d’escalade et des calendriers de congés. Dans les situations critiques de récupération d’urgence, il peut être nécessaire d’utiliser un système de tableau de service
- Les ordinateurs portables, les blocs d'alimentation ou l'alimentation de secours, la connectivité réseau et les coordonnées des téléphones portables de l'exécutant du DR, du responsable du DR et de tout point d'escalade.
- Le processus à suivre si l'une des exigences du processus n'est pas respectée.
- Liste des contacts
- Responsable de la récupération d’urgence et groupes de support
- Experts techniques qui termineront le cycle de test/révision de la récupération technique
- Propriétaires d'entreprise concernés, y compris les personnes chargées d'approuver la reprise des services
- Les responsables techniques concernés, y compris les personnes chargées d'approuver la reprise technique.
- Le soutien des experts techniques dans tous les domaines concernés, y compris les solutions clés hébergées par la plate-forme.
- Systèmes d’impact en aval – Support opérationnel
- Systèmes sources en amont – Support opérationnel
- Contacts des services partagés d’entreprise. Par exemple, la prise en charge des accès et des authentifications, le monitoring de la sécurité et la prise en charge de la passerelle
- Tous les fournisseurs externes ou tiers, y compris les contacts de support pour les fournisseurs de services cloud
- Conception de l’architecture
- Décrire les détails du scénario E2E de bout en bout et joindre toute la documentation de support associée
- Dépendances
- Dressez la liste de toutes les relations et dépendances des composants.
- Prérequis à la récupération d’urgence
- Confirmation que les systèmes sources en amont sont disponibles en fonction des besoins
- Accès avec élévation de privilèges dans la pile accordé aux ressources de l’exécuteur de la récupération d’urgence
- Les services Azure sont disponibles en fonction des besoins
- Le processus à suivre si l'une des conditions préalables n'a pas été remplie.
- Récupération technique – Instructions pas à pas
- Ordre d’exécution
- Description de l’étape
- Prérequis de l’étape
- les étapes détaillées du processus pour chaque action discrète, y compris les URL.
- Instructions de validation, y compris les preuves nécessaires
- Temps nécessaire attendu pour effectuer chaque étape, y compris la contingence
- Processus à suivre en cas d’échec de l’étape
- Points d’escalade en cas de défaillance ou d’assistance des experts techniques
- Récupération technique – Conditions requises post-récupération
- Confirmer l’horodatage actuel du système dans les composants clés
- Confirmer les adresses IP et les URL du système de récupération d’urgence
- Préparer le processus de révision des parties prenantes, y compris la confirmation de l’accès aux systèmes et la finalisation de la validation et de l’approbation par les experts techniques
- Examen et approbation des parties prenantes
- Coordonnées des ressources professionnelles
- Étapes de validation conformément selon la récupération technique ci-dessus
- La piste de preuve exigée par l’approbateur qui approuve la récupération
- Conditions requises post-récupération
- Transfert au support opérationnel afin qu’il exécute les processus de données nécessaires à la mise à jour du système
- Transfert des processus et solutions en aval : confirmation de la date et des détails de connexion du système de récupération d’urgence
- Confirmer l’achèvement du processus de récupération auprès du responsable de la récupération d’urgence : confirmation de la piste de preuve et du runbook terminé
- Informer l’administration de la sécurité que les privilèges d’accès élevés peuvent être supprimés pour l’équipe de récupération d’urgence
Légendes
- Il est recommandé d’inclure des captures d’écran système de chaque processus d’étape. Ces captures d’écran permettront d’effectuer les tâches sans dépendre des experts techniques système
- Pour atténuer les risques liés à l’évolution rapide des services cloud, le plan de récupération d’urgence doit être régulièrement revisité, testé et exécuté par les ressources ayant une connaissance actualisée d’Azure et de ses services
- Les étapes de récupération technique doivent refléter la priorité du composant et de la solution pour l’organisation. Par exemple, les flux de données d’entreprise principaux sont récupérés avant les laboratoires d’analyse des données ad hoc
- Les étapes de récupération technique doivent suivre l’ordre des workflows (généralement de gauche à droite), une fois que les composants ou services principaux tels que Key Vault ont été récupérés. Cette stratégie garantit que les dépendances en amont sont disponibles et que les composants peuvent être testés de manière appropriée
- Une fois le plan pas à pas terminé, il convient d’obtenir un délai total pour les activités en cas d’urgence. Si ce total est supérieur à l'objectif de délai de rétablissement (RTO) convenu, plusieurs options sont possibles :
- Automatiser les processus de récupération sélectionnés (si possible)
- Rechercher les opportunités d’exécution des étapes de récupération sélectionnées en parallèle (si possible). Toutefois, notez que cette stratégie peut nécessiter des exécuteurs de récupération d’urgence supplémentaires.
- Élever les composants clés vers des niveaux de service plus élevés, tels que PaaS, où Microsoft assume une plus grande responsabilité pour les activités de récupération de service
- Étendre le RTO avec les parties prenantes
Test de récupération d’urgence
La nature de l’offre du service Cloud Azure entraîne des contraintes pour tous les scénarios de test de récupération d’urgence. Il est donc conseillé de mettre en place un abonnement de récupération d’urgence avec les composants de plateforme de données qui sont disponibles dans la région secondaire.
À partir de cette base de référence, le runbook du plan de récupération d’urgence peut être exécuté de manière sélective, en accordant une attention particulière aux services et aux composants qui peuvent être déployés et validés. Ce processus nécessite un jeu de données de test organisé permettant la confirmation des vérifications de validation technique et métier, conformément au plan.
Un plan de récupération d’urgence doit être testé régulièrement pour non seulement s’assurer qu’il est à jour, mais également pour créer une « mémoire musculaire » à destination des équipes qui effectuent des activités de basculement et de récupération.
- Les sauvegardes des données et de la configuration doivent également être testées régulièrement afin de s'assurer qu'elles sont « adaptées à l'usage » pour soutenir toute activité de récupération.
Pendant un test de récupération d’urgence, il faut principalement s’assurer que les étapes prescriptives sont toujours correctes et que les délais estimés sont toujours pertinents.
- Si les instructions reflètent les écrans du portail plutôt que le code, elles doivent être validées au moins tous les 12 mois en raison de la cadence des changements du cloud.
Même si l’on pourrait souhaiter un processus de récupération d’urgence entièrement automatisé, l’automatisation complète est peu probable en raison de la rareté de l’événement. Il est donc recommandé d'établir la base de reprise avec la configuration de l'état désiré (DSC) de l'infrastructure en tant que code (IaC) utilisée pour fournir la plateforme, puis de la relever au fur et à mesure que les nouveaux projets se construisent sur la base de la base.
- À mesure que les composants et les services sont étendus, un NFR doit être appliqué, ce qui nécessite que le pipeline de déploiement de production soit refactorisé dans le but de fournir une couverture pour la récupération d’urgence.
Si les minutages de votre runbook dépassent votre RTO, plusieurs options s’offrent à vous :
- Étendre le RTO avec les parties prenantes
- Réduire le temps nécessaire aux activités de récupération via l’automatisation, l’exécution de tâches en parallèle ou la migration vers des niveaux de serveur cloud supérieurs
Azure Chaos Studio
Azure Chaos Studio est un service géré permettant d’améliorer la résilience en injectant des erreurs dans vos applications Azure. Chaos Studio vous permet d’orchestrer l’injection d’erreurs sur vos ressources Azure de façon sécurisée et contrôlée, à l’aide d’expériences. Consultez la documentation du produit pour obtenir une description des types d’erreurs actuellement pris en charge.
L’itération actuelle de Chaos Studio couvre uniquement un sous-ensemble de composants et de services Azure. Tant que d’autres bibliothèques d’erreurs ne sont pas ajoutées, nous vous recommandons d’utiliser Chaos Studio pour les tests de résilience isolés plutôt que pour les tests de récupération d’urgence système complets.
Vous trouverez plus d'informations sur Chaos Studio dans la documentation d'Azure Chaos Studio.
Azure Site Recovery
Pour les composants IaaS, Azure Site Recovery protège la plupart des charges de travail exécutées sur une machine virtuelle ou un serveur physique pris en charge
Vous trouverez des instructions détaillées pour les actions suivantes :
- Exécution d’un exercice de récupération d’urgence de machine virtuelle Azure
- Exécution d’un basculement de récupération d’urgence vers une région secondaire
- Exécution d’un rétablissement de récupération d’urgence vers la région primaire
- Activation de l’automatisation d’un plan de récupération d’urgence
Ressources associées
- Intégrer la résilience et la disponibilité à l'architecture
- Continuité d’activité et reprise d’activité
- Sauvegarde et reprise d’activité pour les applications Azure
- Résilience dans Azure
- Récapitulatif des contrats de niveau de service
- Cinq bonnes pratiques pour anticiper les défaillances
Étapes suivantes
Maintenant que vous avez appris à déployer ce scénario, vous pouvez lire un résumé de la série relative à la plateforme de données de récupération d’urgence pour Azure.