Considérations de sécurité relatives au déplacement des données dans Azure Data Factory
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Cet article décrit l’infrastructure de sécurité de base qu’utilisent les services de déplacement des données dans Azure Data Factory pour vous aider à sécuriser vos données. Les ressources de gestion Data Factory reposent sur l’infrastructure de sécurité Azure et utilisent toutes les mesures de sécurité possibles proposées par Azure.
Dans une solution Data Factory, vous créez un ou plusieurs pipelines de données. Un pipeline constitue un regroupement logique d’activités qui exécutent ensemble une tâche. Ces pipelines se trouvent dans la région où la fabrique de données a été créée.
Bien que Data Factory soit disponible uniquement dans certaines régions, le service de déplacement de données est disponible globalement pour assurer la conformité des données, l’efficacité et une réduction des coûts de sortie réseau.
Azure Data Factory, y compris Azure Integration Runtime et IR auto-hébergé, ne stocke aucune donnée temporaires, données de cache ou journaux, à l’exception des informations d’identification du service lié pour les banques de données cloud, chiffrées à l’aide de certificats. Grâce à Data Factory, vous créez des workflows pilotés par les données afin d’orchestrer le déplacement de données entre les banques de données prises en charge, ainsi que le traitement des données à l’aide des services de calcul situés dans d’autres régions ou dans un environnement local. Il vous permet également analyser et gérer des workflows au moyen de Kits de développement logiciel (SDK) et d’Azure Monitor.
Data Factory a obtenu les certifications suivantes :
| Certification CSA STAR |
|---|
| ISO 20000-1:2011 |
| ISO 22301:2012 |
| ISO 27001:2013 |
| ISO 27017:2015 |
| ISO 27018:2014 |
| ISO 9001:2015 |
| SOC 1, 2, 3 |
| HIPAA BAA |
| HITRUST |
Si la conformité Azure vous intéresse et que vous désirez savoir comment Azure sécurise sa propre infrastructure, consultez le Centre de confidentialité Microsoft. Pour obtenir la liste la plus récente de toutes les offres de conformité Azure, consultez https://aka.ms/AzureCompliance.
Cet article présente les principes de sécurité à prendre en compte dans les deux scénarios de déplacement de données suivants :
- Scénario cloud : Dans ce scénario, votre source et votre destination sont toutes deux accessibles publiquement via Internet. Cela inclut les services de stockage cloud managés comme Stockage Azure, Azure Synapse Analytics, Azure SQL Database, Azure Data Lake Store, Amazon S3, Amazon Redshift, les services SaaS tels que Salesforce et les protocoles web tels que FTP et OData. Recherchez une liste complète des sources de données prises en charge dans Banques de données et formats pris en charge.
- Scénario hybride : Dans ce scénario, votre source ou votre destination se trouve derrière un pare-feu ou à l’intérieur d’un réseau d’entreprise local. Ou bien, la banque de données est un réseau ou un réseau virtuel (le plus souvent la source) et n’est pas accessible publiquement. Les serveurs de base de données hébergés sur des machines virtuelles sont également inclus dans ce scénario.
Notes
Nous vous recommandons d’utiliser le module Azure Az PowerShell pour interagir avec Azure. Pour bien démarrer, consultez Installer Azure PowerShell. Pour savoir comment migrer vers le module Az PowerShell, consultez Migrer Azure PowerShell depuis AzureRM vers Az.
Scénarios cloud
Sécurisation des informations d’identification des banques de données
- Stocker les informations d’identification chiffrées dans un magasin managé Azure Data Factory. Data Factory permet de protéger les informations d’identification de vos banques de données en les chiffrant à l’aide de certificats managés par Microsoft. Ces certificats sont remplacés tous les deux ans (avec renouvellement des certificats et migration des informations d’identification). Pour plus d’informations sur la sécurité du stockage Azure, consultez Vue d’ensemble de la sécurité du stockage Azure.
- Stocker les informations d’identification dans Azure Key Vault. Vous pouvez également stocker les informations d’identification de la banque de données dans Azure Key Vault. Data Factory récupère les informations d’identification lors de l’exécution d’une activité. Pour plus d’informations, consultez Store credential in Azure Key Vault (Stocker les informations d’identification dans Azure Key Vault).
La centralisation du stockage des secrets d’application dans Azure Key Vault vous permet de contrôler la distribution de ces secrets. Key Vault réduit considérablement les risques de fuite accidentelle des secrets. Dans ce cas, plutôt que d’inclure la chaîne de connexion dans le code de l’application, vous pouvez simplement la stocker en toute sécurité dans Key Vault. Vos applications peuvent accéder en toute sécurité aux informations nécessaires en utilisant des URI. Ces URI permettent aux applications de récupérer des versions spécifiques d’un secret. Aucune écriture de code personnalisé n’est nécessaire pour protéger les informations secrètes stockées dans Key Vault.
Chiffrement des données en transit
Tous les transferts de données entre les services de déplacement des données dans Data Factory et une banque de données cloud s’effectuent via un canal HTTPS ou TLS sécurisé, si la banque de données cloud prend en charge HTTPS ou TLS.
Notes
Toutes les connexions à Azure SQL Database et à Azure Synapse Analytics doivent être chiffrées (via SSL/TLS) lorsque les données sont en transit depuis et vers la base de données. Lorsque vous créez un pipeline à l’aide de JSON, ajoutez la propriété de chiffrement et définissez sa valeur sur true dans la chaîne de connexion. Pour le stockage Azure, vous pouvez utiliser HTTPS dans la chaîne de connexion.
Notes
Pour activer le chiffrement en transit pendant le déplacement de données depuis Oracle, suivez l’une des options suivantes :
- Sur le serveur Oracle, accédez à Oracle Advanced Security (OAS) et configurez les paramètres de chiffrement, qui prennent en charge les chiffrements Triple DES (3DES) et Advanced Encryption Standard (AES) ; les détails sont disponibles ici. ADF négocie automatiquement la méthode de chiffrement pour utiliser celle que vous configurez dans OAS durant l’établissement de la connexion à Oracle.
- Dans ADF, vous pouvez ajouter EncryptionMethod=1 dans la chaîne de connexion (dans le service lié). Cette opération utilise SSL/TLS comme méthode de chiffrement. Pour l’utiliser, vous devez désactiver les paramètres de chiffrement non SSL dans OAS du côté serveur Oracle pour éviter tout conflit de chiffrement.
Notes
La version du protocole TLS utilisée est 1.2.
Chiffrement des données au repos
Certaines banques de données prennent en charge le chiffrement des données au repos. Nous vous recommandons d’activer le mécanisme de chiffrement des données pour ces banques de données.
Azure Synapse Analytics
Transparent Data Encryption (TDE) dans Azure Synapse Analytics vous aide à vous protéger contre les menaces d’activités malveillantes, par le biais d’un chiffrement et d’un déchiffrement en temps réel de vos données au repos. Ce comportement est transparent pour le client. Pour plus d’informations, consultez Sécuriser une base de données dans Azure Synapse Analytics.
Azure SQL Database
Azure SQL Database prend également en charge TDE (Transparent Data Encryption) qui vous permet de vous protéger contre toute menace d’activité malveillante, en effectuant un chiffrement et un déchiffrement en temps réel des données, sans qu’il soit nécessaire de modifier l’application. Ce comportement est transparent pour le client. Pour plus d’informations, consultez Transparent Data Encryption avec SQL Database et Data Warehouse.
Azure Data Lake Store
Azure Data Lake Store assure également le chiffrement des données stockées dans le compte. Une fois activé, Data Lake Store chiffre automatiquement les données avant qu’elles soient rendues persistantes, il les déchiffre avant qu’elles soient récupérées, les rendant transparentes pour le client qui accède aux données. Pour plus d’informations, consultez Sécurité dans Azure Data Lake Store.
Stockage Blob Azure et stockage Table Azure
Le stockage Blob Azure et le stockage Table Azure prennent en charge le SSE (Storage Service Encryption), qui chiffre automatiquement vos données avant qu’elles ne soient persistantes dans le stockage et les déchiffre avant leur récupération. Pour plus d’informations, consultez Azure Storage Service Encryption pour les données au repos.
Amazon S3
Amazon S3 prend en charge le chiffrement des données au repos côté client et côté serveur. Pour plus d’informations, consultez Protection des données à l’aide du chiffrement.
Amazon Redshift
Amazon Redshift prend en charge le chiffrement du cluster pour les données au repos. Pour plus d’informations, consultez Amazon Redshift Database Encryption (Chiffrement de base de données Amazon Redshift).
Salesforce
Salesforce prend en charge Shield Platform Encryption qui permet de chiffrer tous les fichiers, pièces jointes et champs personnalisés. Pour plus d’informations, consultez Understanding the Web Server OAuth Authentication Flow (Comprendre le flux d’authentification Web Server OAuth).
Scénarios hybrides
Pour les scénarios hybrides, un runtime d’intégration auto-hébergé doit être installé au sein d’un réseau local, d’un réseau virtuel (Azure) ou d’un cloud privé virtuel (Amazon). Le runtime d’intégration auto-hébergé doit être en mesure d’accéder aux banques de données locales. Pour plus d’informations sur le runtime d’intégration auto-hébergé, consultez Comment créer et configurer un runtime d’intégration auto-hébergé.

Le canal de commande autorise la communication entre les services de déplacement des données dans Data Factory et le runtime d’intégration auto-hébergé. La communication contient des informations relatives à l’activité. Le canal de données est utilisé pour transférer des données entre les banques de données locales et les banques de données cloud.
Informations d’identification des banques de données locales
Les informations d’identification peuvent être stockées dans une fabrique de données ou référencées par une fabrique de données au moment de l’exécution à partir d’Azure Key Vault. Quand vous stockez des informations d’identification dans une fabrique de données, elles sont toujours chiffrées sur le runtime d’intégration auto-hébergé.
Stocker des informations d’identification localement. Si vous utilisez directement l’applet de commande Set-AzDataFactoryV2LinkedService avec les chaînes de connexion et les informations d’identification incluses dans le JSON, le service lié est chiffré et stocké sur le runtime d’intégration auto-hébergé. Dans ce cas, les informations d’identification passent par le service principal Azure, hautement sécurisé, avant d’aboutir à la machine d’intégration auto-hébergée, où elles sont chiffrées et stockées. Le runtime d’intégration auto-hébergé utilise l’API de protection des données (DPAPI) Windows pour chiffrer les données sensibles et les informations d’identification.
Stocker les informations d’identification dans Azure Key Vault. Vous pouvez également stocker les informations d’identification de la banque de données dans Azure Key Vault. Data Factory récupère les informations d’identification lors de l’exécution d’une activité. Pour plus d’informations, consultez Store credential in Azure Key Vault (Stocker les informations d’identification dans Azure Key Vault).
Stocker des informations d’identification localement sur le runtime d’intégration auto-hébergé sans les faire passer par le service back-end Azure. Si vous souhaitez chiffrer et stocker des informations d’identification localement sur le runtime d’intégration auto-hébergé sans les faire passer par le service back-end de la fabrique de données, suivez les étapes décrites dans Chiffrer des informations d’identification pour les banques de données locales dans Azure Data Factory. Tous les connecteurs prennent en charge cette option. Le runtime d’intégration auto-hébergé utilise l’API de protection des données (DPAPI) Windows pour chiffrer les données sensibles et les informations d’identification.
Utilisez la cmdlet New-AzDataFactoryV2LinkedServiceEncryptedCredential pour chiffrer les informations d’identification et les informations sensibles du service lié. Vous pouvez ensuite utiliser le JSON retourné (avec l’élément EncryptedCredential dans la chaîne de connexion) pour créer un service lié à l’aide de la cmdlet Set-AzDataFactoryV2LinkedService.
Ports utilisés pendant le chiffrement du service lié sur le runtime d’intégration auto-hébergé
Par défaut, quand l’accès à distance à partir de l’intranet est activé, PowerShell utilise le port 8060 sur l’ordinateur avec le runtime d’intégration auto-hébergé pour la communication sécurisée. Si nécessaire, vous pouvez modifier ce port à partir du Gestionnaire de configuration Microsoft Integration Runtime sous l’onglet Paramètres :


Chiffrement en transit
Tous les transferts de données s’effectuent via un canal sécurisé HTTPS et TLS via TCP pour empêcher les attaques de l’intercepteur pendant la communication avec les services Azure.
Vous pouvez également utiliser un VPN IPSec ou Azure ExpressRoute pour renforcer la sécurité du canal de communication entre votre réseau local et Azure.
Le réseau virtuel Azure est une représentation logique de votre réseau dans le cloud. Vous pouvez connecter un réseau local à votre réseau virtuel Azure en configurant VPN IPSec (de site à site) ou ExpressRoute (peering privé).
Le tableau suivant récapitule les recommandations pour la configuration du réseau et du runtime d’intégration auto-hébergé selon différentes combinaisons d’emplacements source et de destination pour le déplacement de données hybrides.
| Source | Destination | Configuration réseau | Installation du runtime d’intégration |
|---|---|---|---|
| Local | Machines virtuelles et services cloud déployés au sein de réseaux virtuels | VPN IPSec (de point à site ou de site à site) | Le runtime d’intégration auto-hébergé doit être installé sur une machine virtuelle Azure au sein du réseau virtuel. |
| Local | Machines virtuelles et services cloud déployés au sein de réseaux virtuels | ExpressRoute (peering privé) | Le runtime d’intégration auto-hébergé doit être installé sur une machine virtuelle Azure au sein du réseau virtuel. |
| Local | Services Azure disposant d’un point de terminaison public | ExpressRoute (peering Microsoft) | Le runtime d’intégration auto-hébergé peut être installé en local ou sur une machine virtuelle Azure. |
Les images suivantes décrivent l’utilisation du runtime d’intégration auto-hébergé pour le déplacement de données entre une base de données locale et les services Azure à l’aide d’ExpressRoute et d’un VPN IPSec (avec un réseau virtuel) :
ExpressRoute
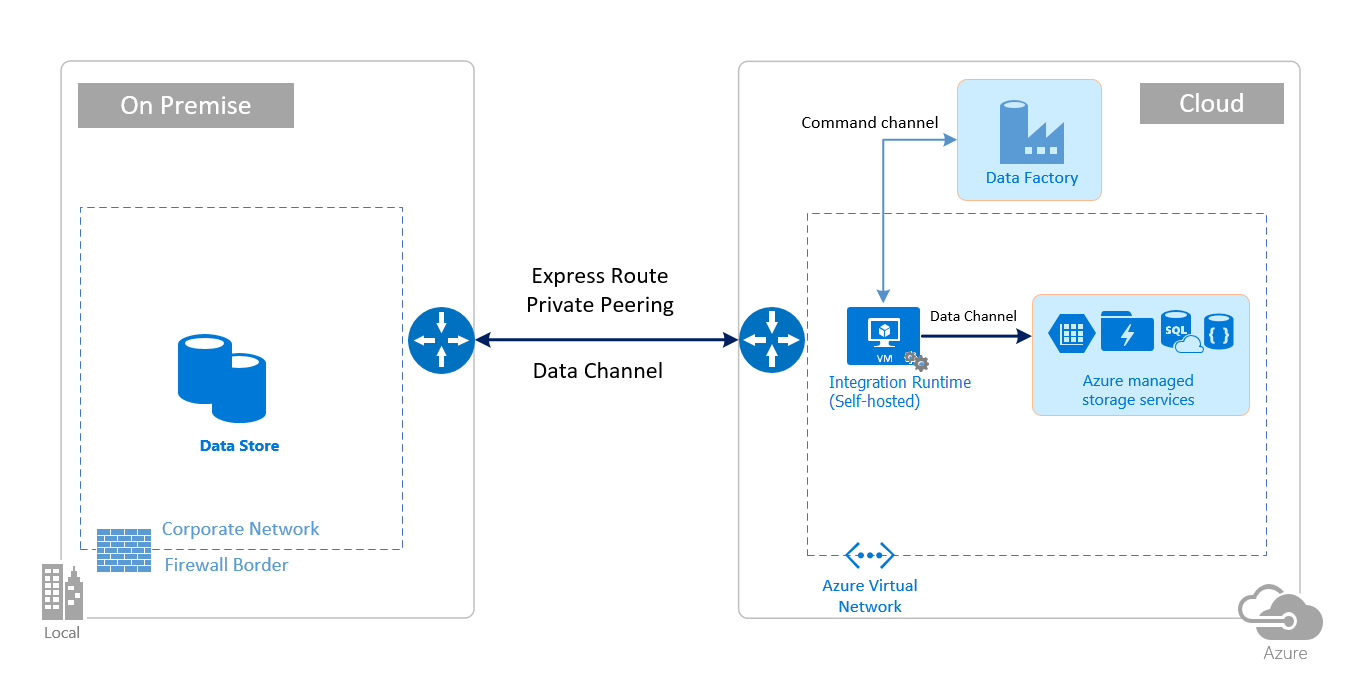
VPN IPSec

Configurations de pare-feu et configuration de la liste d’autorisation pour les adresses IP
Notes
Vous devrez peut-être gérer les ports ou configurer une liste d’autorisation pour les domaines au niveau du pare-feu d’entreprise tel que requis par les sources de données respectives. Ce tableau utilise uniquement Azure SQL Database, Azure Synapse Analytics et Azure Data Lake Store comme exemples.
Notes
Pour plus d’informations sur les stratégies d’accès aux données par le biais d’Azure Data Factory, consultez cet article.
Configuration requise du pare-feu pour un réseau local/privé
Dans une entreprise, un pare-feu d’entreprise s’exécute sur le routeur central de l’organisation. Le pare-feu Windows s’exécute en tant que démon sur la machine locale sur laquelle est installé le runtime d’intégration auto-hébergé.
Le tableau suivant indique les exigences de ports et de domaines sortants pour les pare-feu d’entreprise :
| Noms de domaine | Ports sortants | Description |
|---|---|---|
*.servicebus.windows.net |
443 | Requis par le runtime d’intégration auto-hébergé pour la création interactive. |
{datafactory}.{region}.datafactory.azure.netou *.frontend.clouddatahub.net |
443 | Requis par le runtime d’intégration auto-hébergé pour se connecter au service Data Factory. Pour les nouvelles fabriques de données créées, recherchez le nom de domaine complet à partir de votre clé de runtime d’intégration auto-hébergé dont le format est {fabrique_de_données}.{région}.datafactory.azure.net. Pour une ancienne fabrique de données, si vous ne voyez pas le nom de domaine complet dans votre clé d’intégration auto-hébergée, utilisez *.frontend.clouddatahub.net à la place. |
download.microsoft.com |
443 | Exigé par le runtime d’intégration auto-hébergé pour télécharger les mises à jour. Si vous avez désactivé la mise à jour automatique, vous pouvez ignorer la configuration de ce domaine. |
*.core.windows.net |
443 | Utilisé par le runtime d’intégration auto-hébergé pour se connecter au compte de stockage Azure lorsque vous utilisez la fonctionnalité copie intermédiaire. |
*.database.windows.net |
1433 | Nécessaire seulement quand vous copiez depuis ou vers Azure SQL Database ou Azure Synapse Analytics ; sinon, facultatif. Utilisez la fonctionnalité de copie intermédiaire pour copier des données vers SQL Database ou Azure Synapse Analytics sans ouvrir le port 1433. |
*.azuredatalakestore.netlogin.microsoftonline.com/<tenant>/oauth2/token |
443 | Nécessaire lorsque vous copiez depuis ou vers Azure Data Lake Store, sinon, facultatif. |
Notes
Vous devrez peut-être gérer les ports ou configurer une liste d’autorisation pour les domaines au niveau du pare-feu d’entreprise tel que requis par les sources de données respectives. Ce tableau utilise uniquement Azure SQL Database, Azure Synapse Analytics et Azure Data Lake Store comme exemples.
Le tableau suivant indique les exigences de ports entrants pour le pare-feu Windows :
| Ports entrants | Description |
|---|---|
| 8060 (TCP) | Requis par la cmdlet de chiffrement PowerShell comme décrit dans la rubriqueChiffrer des informations d’identification pour des banques de données locales dans Azure Data Factory et par l’application du gestionnaire des informations d’identification pour définir en toute sécurité les informations d’identification pour les banques de données locales sur le runtime d’intégration auto-hébergé. |

Configurations IP et configuration de la liste d’autorisation dans les magasins de données
Certains magasins de données dans le cloud exigent également que autorisiez l’adresse IP de la machine qui accède au magasin. Vérifiez que l’adresse IP de la machine runtime d’intégration auto-hébergé est autorisée ou configurée correctement dans le pare-feu.
Les magasins de données cloud suivants exigent que vous autorisiez l’adresse IP de la machine runtime d’intégration auto-hébergé. Il est possible que certains de ces magasins de données ne requièrent pas par défaut la liste d’autorisation.
Forum aux questions
Le runtime d’intégration auto-hébergé peut-il être partagé entre différentes fabriques de données ?
Oui. Plus de détails ici.
Quelle sont les exigences de ports pour assurer un bon fonctionnement du runtime d’intégration auto-hébergé ?
Le runtime d’intégration auto-hébergé établit des connexions HTTP pour l’accès à Internet. Le port sortant 443 doit être ouvert pour que le runtime d’intégration autohébergé puisse établir cette connexion. Ouvrez le port entrant 8060 uniquement au niveau de la machine (et non au niveau du pare-feu d’entreprise) pour l’application du gestionnaire des informations d’identification. Si vous utilisez Azure SQL Database ou Azure Synapse Analytics comme source ou destination, vous devez également ouvrir le port 1433. Pour en savoir plus, consultez la section Configurations de pare-feu et configuration de la liste d’autorisation pour les adresses IP.
Contenu connexe
Pour en savoir plus sur les performances de l’activité de copie Azure Data Factory, consultez Guide des performances et d’optimisation de l'activité de copie.