Guide des développeurs Python sur Azure Functions
Ce guide est une introduction au développement d’Azure Functions à l’aide de Python. L’article suppose que vous avez déjà lu le Guide de développement Azure Functions.
Important
Cet article prend en charge le modèle de programmation v1 et v2 pour Python dans Azure Functions. Le modèle Python v1 utilise un fichier functions.json pour définir des fonctions, et le nouveau modèle v2 vous permet d’utiliser une approche basée sur les éléments décoratifs. Cette nouvelle approche se traduit par une structure de fichiers plus simple et est plus centrée sur le code. Choisissez le sélecteur v2 en haut de l’article pour en savoir plus sur ce nouveau modèle de programmation.
En tant que développeur Python, vous pouvez également vous intéresser à ces sujets :
- Visual Studio Code : créez votre première application Python à l’aide de Visual Studio Code.
- Terminal ou invite de commandes : créez votre première application Python à partir de l’invite de commandes à l’aide d’Azure Functions Core Tools.
- Exemples : passez en revue certaines applications Python existantes dans le navigateur d’exemples Learn.
- Visual Studio Code : créez votre première application Python à l’aide de Visual Studio Code.
- Terminal ou invite de commandes : créez votre première application Python à partir de l’invite de commandes à l’aide d’Azure Functions Core Tools.
- Exemples : passez en revue certaines applications Python existantes dans le navigateur d’exemples Learn.
Options de développement
Les deux modèles de programmation Python Functions prennent en charge le développement local dans l’un des environnements suivants :
Modèle de programmation Python v2 :
Modèle de programmation Python v1 :
Vous pouvez également créer des fonctions Python v1 dans le Portail Azure.
Conseil
Même si vous pouvez développer votre solution Azure Functions basée sur Python localement sur Windows, Python n’est pris en charge que sur un plan d’hébergement basé sur Linux lors de l’exécution dans Azure. Pour plus d’informations, consultez la liste des combinaisons système d’exploitation/runtime prises en charge.
Modèle de programmation
Azure Functions s’attend à ce qu’une fonction soit une méthode sans état qui traite une entrée et produit une sortie dans un script Python. Par défaut, le runtime s’attend à ce que la méthode soit implémentée en tant que méthode globale nommée main() dans le fichier __init__.py. Vous pouvez également spécifier un autre point d’entrée.
Vous pouvez lier les données issues des déclencheurs et des liaisons à la fonction par des attributs de méthode qui utilisent la propriété name définie dans le fichier function.json. L’exemple de fichier function.json suivant décrit une fonction simple qui est déclenchée par une requête HTTP nommée req :
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Sur la base de cette définition, le fichier __init__.py qui contient le code de fonction peut se présenter comme dans l’exemple suivant :
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
Vous pouvez aussi déclarer explicitement les types d’attributs et le type de retour dans la fonction à l’aide d’annotations de type Python. Ceci vous aide à utiliser les fonctionnalités IntelliSense et les fonctionnalités de saisie semi-automatique qui sont fournies par de nombreux éditeurs de code Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Utilisez les annotations Python qui sont incluses dans le package azure.functions.* pour lier des entrées et des sorties à vos méthodes.
Azure Functions s’attend à ce qu’une fonction soit une méthode sans état qui traite une entrée et produit une sortie dans un script Python. Par défaut, le runtime s’attend à ce que la méthode soit implémentée en tant que méthode globale dans le fichier function_app.py.
Les déclencheurs et les liaisons peuvent être déclarés et utilisés dans une fonction dans une approche basée sur les éléments décoratifs. Vous les définissez dans le même fichier, function_app.py, que les fonctions. Par exemple, le fichier function_app.py suivant représente une fonction déclenchée par une requête HTTP.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
Vous pouvez aussi déclarer explicitement les types d’attributs et le type de retour dans la fonction à l’aide d’annotations de type Python. Ceci vous aide à utiliser les fonctionnalités IntelliSense et les fonctionnalités de saisie semi-automatique qui sont fournies par de nombreux éditeurs de code Python.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Pour en savoir plus sur les limitations connues du modèle v2 et leurs solutions de contournement, consultez Résoudre les erreurs Python dans Azure Functions.
Autre point d’entrée
Vous pouvez changer le comportement par défaut d’une fonction en spécifiant éventuellement les propriétés scriptFile et entryPoint dans le fichier scriptFile. Par exemple, le fichier function.json suivant indique au runtime d’utiliser la méthode customentry() dans le fichier main.py comme point d’entrée de votre fonction Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Le point d’entrée se trouve uniquement dans le fichier function_app.py. Toutefois, vous pouvez référencer les fonctions au sein du projet dans function_app.py à l’aide de blueprints ou par importation.
Structure de dossiers
La structure de dossiers recommandée d’un projet Python Functions se présente comme l’exemple suivant :
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Le dossier principal du projet <project_root> peut contenir les fichiers suivants :
- local.settings.json : Utilisé pour stocker les paramètres d’application et les chaînes de connexion lors d’une exécution locale. Ce fichier n’est pas publié sur Azure. Pour en savoir plus, consultez la section local.settings.file.
- requirements.txt : Contient la liste des packages Python que le système installe lors de la publication sur Azure.
- host.json : contient les options de configuration qui affectent toutes les fonctions d’une instance d’application de fonction. Ce fichier est publié sur Azure. Toutes les options ne sont pas prises en charge lors de l’exécution locale. Pour en savoir plus, consultez la section host.json.
- .vscode/ : (facultatif) contient la configuration Visual Studio Code stockée. Pour plus d’informations, consultez Paramètres Visual Studio Code.
- .venv/ : (Facultatif) Contient un environnement virtuel Python utilisé par le développement local.
- Dockerfile : (Facultatif) Utilisé lors de la publication de votre projet dans un conteneur personnalisé.
- tests/ : (Facultatif) Contient les cas de test de votre application de fonction.
- .funcignore : (Facultatif) Déclare des fichiers qui ne devraient pas être publiés sur Azure. En règle générale, ce fichier contient .vscode/ pour ignorer le paramètre de votre éditeur, .venv/ pour ignorer l’environnement virtuel Python local, tests/ pour ignorer les cas de test et local.settings.json pour empêcher la publication des paramètres de l’application locale.
Chaque fonction a son propre fichier de code et son propre fichier de configuration de liaison function.json.
La structure de dossiers recommandée d’un projet Python Functions se présente comme l’exemple suivant :
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
Le dossier principal du projet <project_root> peut contenir les fichiers suivants :
- .venv/ : (facultatif) contient un environnement virtuel Python utilisé pour le développement local.
- .vscode/ : (facultatif) contient la configuration Visual Studio Code stockée. Pour plus d’informations, consultez Paramètres Visual Studio Code.
- function_app.py : l’emplacement par défaut pour toutes les fonctions et leurs déclencheurs et liaisons associés.
- additional_functions.py : (Facultatif) Tous les autres fichiers Python qui contiennent des fonctions (généralement pour le regroupement logique) référencées dans function_app.py via des blueprints.
- tests/ : (Facultatif) Contient les cas de test de votre application de fonction.
- .funcignore : (Facultatif) Déclare des fichiers qui ne devraient pas être publiés sur Azure. En règle générale, ce fichier contient .vscode/ pour ignorer le paramètre de votre éditeur, .venv/ pour ignorer l’environnement virtuel Python local, tests/ pour ignorer les cas de test et local.settings.json pour empêcher la publication des paramètres de l’application locale.
- host.json : contient les options de configuration qui affectent toutes les fonctions d’une instance d’application de fonction. Ce fichier est publié sur Azure. Toutes les options ne sont pas prises en charge lors de l’exécution locale. Pour en savoir plus, consultez la section host.json.
- local.settings.json : utilisé pour stocker les paramètres d’application et les chaînes de connexion lors d’une exécution en local. Ce fichier n’est pas publié sur Azure. Pour en savoir plus, consultez la section local.settings.file.
- requirements.txt : Contient la liste des packages Python que le système installe lors de la publication sur Azure.
- Dockerfile : (Facultatif) Utilisé lors de la publication de votre projet dans un conteneur personnalisé.
Quand vous déployez votre projet dans une application de fonction sur Azure, tout le contenu du dossier principal du projet, <project_root>, doit être inclus dans le package, mais pas le dossier lui-même, ce qui signifie que host.json doit se trouver à la racine du package. Nous vous recommandons de conserver vos tests dans un dossier avec d’autres fonctions, tests/ dans cet exemple. Pour plus d’informations, consultez Test unitaire.
Se connecter à une base de données
Azure Functions s’intègre bien à Azure Cosmos DB pour de nombreux cas d’usage, notamment l’IoT, l’e-commerce, le gaming, etc.
Par exemple, pour l’approvisionnement en événements, les deux services sont intégrés afin d’alimenter les architectures pilotées par événements au moyen de la fonctionnalité de flux de modifications d’Azure Cosmos DB. Le flux de modification fournit aux microservices en aval la possibilité de lire de façon incrémentielle et fiable les insertions et les mises à jour (par exemple, les événements de commande). Cette fonctionnalité peut être utilisée pour fournir un magasin d’événements persistant en guise de courtier de messages des événements qui changent d’état, et pour gérer le workflow du traitement des commandes entre de nombreux microservices (pouvant être implémentés comme Azure Functions serverless).
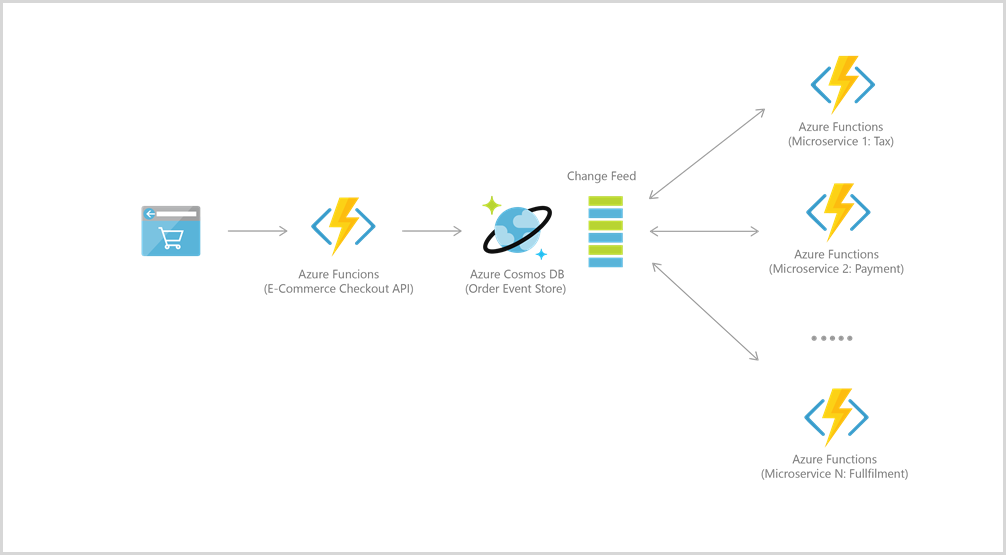
Pour vous connecter à Azure Cosmos DB, vous devez d’abord créer un compte, une base de données et un conteneur. Vous pouvez ensuite connecter votre code de fonction à Azure Cosmos DB à l’aide de déclencheurs et liaisons, comme dans cet exemple.
Pour implémenter une logique d’application plus complexe, vous pouvez également utiliser la bibliothèque Python pour Cosmos DB. Une implémentation d’E/S asynchrone ressemble à ceci :
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Blueprints
Le modèle de programmation Python v2 introduit le concept de blueprints. Un blueprint est une nouvelle classe instanciée pour inscrire des fonctions en dehors de l’application de fonction principale. Les fonctions inscrites dans les instances de blueprint ne sont pas indexées directement par le runtime de fonction. Pour que ces fonctions de blueprint soient indexées, l’application de fonction doit inscrire les fonctions à partir d’instances de blueprint.
Les blueprints offrent les avantages suivants :
- Vous permet de diviser l’application de fonction en composants modulaires, ce qui vous permet de définir des fonctions dans plusieurs fichiers Python et de les diviser en différents composants par fichier.
- Fournit des interfaces d’application de fonction publique extensibles pour créer et réutiliser vos propres API.
L’exemple suivant montre comment utiliser les blueprints :
Tout d’abord, dans un fichier http_blueprint.py, la fonction déclenchée par HTTP est d’abord définie et ajoutée à un objet blueprint.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Ensuite, dans le fichierfunction_app.py, l’objet blueprint est importé et ses fonctions sont inscrites dans l’application de fonction.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Notes
Durable Functions prend également en charge les blueprints. Pour créer des blueprints pour les applications Durable Functions, inscrivez vos déclencheurs d’orchestration, d’activité et d’entité, ainsi que vos liaisons clientes à l’aide de la classe azure-functions-durable Blueprint, comme illustré ici. Le blueprint obtenu peut ensuite être enregistré normalement. Consultez cet échantillon à titre d’exemple.
Comportement d’importation
Vous pouvez importer des modules dans votre code de fonction en utilisant des références absolues et relatives. Sur la base de la structure de dossiers présentée auparavant, les importations suivantes fonctionnent à partir du fichier de fonction <project_root>\my_first_function\__init__.py :
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Notes
Lors de l’utilisation de la syntaxe d’importation absolue, le dossier shared_code/ doit contenir un fichier __init__.py pour le marquer comme package Python.
L’importation __app__ import suivante et l’importation relative au-delà du niveau supérieur sont déconseillées, car elles ne sont pas prises en charge par le vérificateur de type statique ni par les infrastructures de test Python :
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Déclencheurs et entrées
Les entrées sont réparties en deux catégories dans Azure Functions : l’entrée du déclencheur et l’autre entrée. Ces entrées sont différentes dans le fichier function.json, mais leur utilisation est identique dans le code Python. Les chaînes de connexion ou les secrets pour les sources de déclencheur et d’entrée sont mappés aux valeurs dans le fichier local.settings.json lors d’une exécution locale, et aux paramètres d’application lors d’une exécution dans Azure.
L’exemple de code suivant illustre la différence entre les deux entrées :
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quand la fonction est appelée, la requête HTTP est passée à la fonction dans req. Une entrée est récupérée à partir du compte Stockage Blob Azure sur la base de l’ID présent dans l’URL de la route, puis elle est mise à disposition comme obj dans le corps de la fonction. Ici, le compte de stockage spécifié est la chaîne de connexion qui se trouve dans le paramètre d’application CONNECTION_STRING.
Les entrées sont réparties en deux catégories dans Azure Functions : l’entrée du déclencheur et l’autre entrée. Bien qu’ils soient définis à l’aide de différents éléments décoratifs, l’utilisation est similaire dans le code Python. Les chaînes de connexion ou les secrets pour les sources de déclencheur et d’entrée sont mappés aux valeurs dans le fichier local.settings.json lors d’une exécution locale, et aux paramètres d’application lors d’une exécution dans Azure.
Par exemple, le code suivant montre comment définir une liaison d’entrée de Stockage Blob :
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quand la fonction est appelée, la requête HTTP est passée à la fonction dans req. Une entrée est récupérée à partir du compte Stockage Blob Azure sur la base de l’ID présent dans l’URL de la route, puis elle est mise à disposition comme obj dans le corps de la fonction. Ici, le compte de stockage spécifié est la chaîne de connexion qui se trouve dans le paramètre d’application STORAGE_CONNECTION_STRING.
Pour les opérations de liaison gourmandes en données, vous pouvez utiliser un compte de stockage distinct. Pour plus d’informations, consultez Aide pour les comptes de stockage.
Liaisons de type SDK (préversion)
Pour sélectionner des déclencheurs et des liaisons, vous pouvez utiliser des types de données implémentés par les frameworks et les kits de développement logiciel (SDK) Azure sous-jacents. Ces liaisons de type SDK vous permettent d’interagir avec les données de liaison comme si vous utilisiez le kit SDK de service sous-jacent.
Important
La prise en charge des liaisons de type SDK nécessite le modèle de programmation Python v2.
Functions prend en charge les liaisons de type SDK Python pour Stockage Blob Azure, ce qui vous permet d’utiliser des données d’objets blob à l’aide du type sous-jacent BlobClient.
Important
La prise en charge des liaisons de type SDK pour Python est actuellement en préversion :
- Vous devez utiliser le modèle de programmation Python v2.
- Actuellement, seuls les types de SDK synchrones sont pris en charge.
Prérequis
- Runtime Azure Functions version 4.34 ou ultérieure
- Python version 3.9, ou une version ultérieure prise en charge
Activer les liaisons de type SDK pour l’extension de stockage d’objets blob
Ajoutez le package d’extension
azurefunctions-extensions-bindings-blobau fichierrequirements.txtdans le projet, qui doit inclure au moins ces packages :azure-functions azurefunctions-extensions-bindings-blobAjoutez ce code au fichier
function_app.pydans le projet, qui importe les liaisons de type SDK :import azurefunctions.extensions.bindings.blob as blob
Exemples de liaisons de type SDK
Cet exemple montre comment obtenir BlobClient à la fois à partir d’un déclencheur de stockage d’objets blob (blob_trigger) et à partir de la liaison d’entrée sur un déclencheur HTTP (blob_input) :
import logging
import azure.functions as func
import azurefunctions.extensions.bindings.blob as blob
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.blob_trigger(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_trigger(client: blob.BlobClient):
logging.info(
f"Python blob trigger function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
@app.route(route="file")
@app.blob_input(
arg_name="client", path="PATH/TO/BLOB", connection="AzureWebJobsStorage"
)
def blob_input(req: func.HttpRequest, client: blob.BlobClient):
logging.info(
f"Python blob input function processed blob \n"
f"Properties: {client.get_blob_properties()}\n"
f"Blob content head: {client.download_blob().read(size=1)}"
)
return "ok"
Vous pouvez afficher d’autres exemples de liaisons de type SDK pour le stockage d’objets blob dans le dépôts d’extensions Python :
Flux HTTP (préversion)
Les flux HTTP vous permettent d’accepter et de retourner des données à partir de vos points de terminaison HTTP à l’aide des API de requête et de réponse FastAPI activées dans vos fonctions. Ces API permettent à l’hôte de traiter des données volumineuses dans des messages HTTP en tant que blocs, au lieu de lire un message entier en mémoire.
Cette fonctionnalité permet de gérer des flux de données volumineux et des intégrations OpenAI, de fournir du contenu dynamique, et de prendre en charge d’autres scénarios HTTP de base nécessitant des interactions en temps réel sur HTTP. Vous pouvez également utiliser des types de réponse FastAPI avec des flux HTTP. Sans flux HTTP, la taille de vos requêtes et réponses HTTP est limitée par des restrictions de mémoire qui peuvent être rencontrées lors du traitement de charges utiles de message entières en mémoire.
Important
La prise en charge des flux HTTP nécessite le modèle de programmation Python v2.
Important
La prise en charge des flux HTTP pour Python est actuellement en préversion, et impose d’utiliser le modèle de programmation Python v2.
Prérequis
- Runtime Azure Functions version 4.34.1 ou ultérieure
- Python version 3.8, ou une version ultérieure prise en charge
Activer les flux HTTP
Les flux HTTP sont désactivés par défaut. Vous devez activer cette fonctionnalité dans les paramètres de votre application, et également mettre à jour votre code pour utiliser le package FastAPI. Notez qu’en activant les flux HTTP, l’application de la fonctionnalité utilisera par défaut le flux HTTP, et la fonctionnalité HTTP d’origine ne fonctionnera pas.
Ajoutez le package d’extension
azurefunctions-extensions-http-fastapiau fichierrequirements.txtdans le projet, qui doit inclure au moins ces packages :azure-functions azurefunctions-extensions-http-fastapiAjoutez ce code au fichier
function_app.pydans le projet, qui importe l’extension FastAPI :from azurefunctions.extensions.http.fastapi import Request, StreamingResponseLors du déploiement sur Azure, ajoutez le paramètres d’application suivant dans votre application de fonction :
"PYTHON_ENABLE_INIT_INDEXING": "1"Si vous déployez sur la consommation Linux, ajoutez également
"PYTHON_ISOLATE_WORKER_DEPENDENCIES": "1"Lors de l’exécution locale, vous devez également ajouter ces mêmes paramètres au fichier projet
local.settings.json.
Exemples de flux HTTP
Après avoir activé la fonctionnalité de streaming HTTP, vous pouvez créer des fonctions qui diffusent des données via HTTP.
Cet exemple est une fonction déclenchée par HTTP qui diffuse des données de réponse HTTP. Vous pouvez utiliser ces fonctionnalités pour prendre en charge des scénarios tels que l’envoi de données d’événements via un pipeline pour la visualisation en temps réel ou la détection d’anomalies dans de grands ensembles de données, et pour la fourniture de notifications instantanées.
import time
import azure.functions as func
from azurefunctions.extensions.http.fastapi import Request, StreamingResponse
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
def generate_sensor_data():
"""Generate real-time sensor data."""
for i in range(10):
# Simulate temperature and humidity readings
temperature = 20 + i
humidity = 50 + i
yield f"data: {{'temperature': {temperature}, 'humidity': {humidity}}}\n\n"
time.sleep(1)
@app.route(route="stream", methods=[func.HttpMethod.GET])
async def stream_sensor_data(req: Request) -> StreamingResponse:
"""Endpoint to stream real-time sensor data."""
return StreamingResponse(generate_sensor_data(), media_type="text/event-stream")
Cet exemple est une fonction déclenchée par HTTP qui reçoit et traite des données de streaming à partir d’un client en temps réel. Il illustre les fonctionnalités de chargement de streaming qui peuvent être utiles pour des scénarios tels que le traitement des flux de données continus et la gestion des données d’événements à partir d’appareils IoT.
import azure.functions as func
from azurefunctions.extensions.http.fastapi import JSONResponse, Request
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="streaming_upload", methods=[func.HttpMethod.POST])
async def streaming_upload(req: Request) -> JSONResponse:
"""Handle streaming upload requests."""
# Process each chunk of data as it arrives
async for chunk in req.stream():
process_data_chunk(chunk)
# Once all data is received, return a JSON response indicating successful processing
return JSONResponse({"status": "Data uploaded and processed successfully"})
def process_data_chunk(chunk: bytes):
"""Process each data chunk."""
# Add custom processing logic here
pass
Appel de flux HTTP
Vous devez utiliser une bibliothèque de client HTTP pour passer des appels de streaming aux points de terminaison FastAPI d’une fonction. Le navigateur ou outil client que vous utilisez est susceptible de ne pas prendre en charge le streaming en mode natif, ou de retourner uniquement le premier segment de données.
Vous pouvez utiliser un script client comme celui-ci pour envoyer des données de streaming à un point de terminaison HTTP :
import httpx # Be sure to add 'httpx' to 'requirements.txt'
import asyncio
async def stream_generator(file_path):
chunk_size = 2 * 1024 # Define your own chunk size
with open(file_path, 'rb') as file:
while chunk := file.read(chunk_size):
yield chunk
print(f"Sent chunk: {len(chunk)} bytes")
async def stream_to_server(url, file_path):
timeout = httpx.Timeout(60.0, connect=60.0)
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.post(url, content=stream_generator(file_path))
return response
async def stream_response(response):
if response.status_code == 200:
async for chunk in response.aiter_raw():
print(f"Received chunk: {len(chunk)} bytes")
else:
print(f"Error: {response}")
async def main():
print('helloworld')
# Customize your streaming endpoint served from core tool in variable 'url' if different.
url = 'http://localhost:7071/api/streaming_upload'
file_path = r'<file path>'
response = await stream_to_server(url, file_path)
print(response)
if __name__ == "__main__":
asyncio.run(main())
Sorties
Les sorties peuvent être exprimées aussi bien dans une valeur de retour que dans des paramètres de sortie. S’il n’y a qu’une seule sortie, nous recommandons d’utiliser la valeur de retour. Lorsqu’il y a plusieurs sorties, vous devez utiliser des paramètres de sortie.
Pour utiliser la valeur de retour d’une fonction comme valeur d’une liaison de sortie, la propriété name de la liaison doit être définie sur $return dans function.json.
Pour produire plusieurs sorties, utilisez la méthode set() fournie par l’interface azure.functions.Out afin d’affecter une valeur à la liaison. Par exemple, la fonction suivante peut placer un message dans une file d’attente tout en renvoyant une réponse HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Les sorties peuvent être exprimées aussi bien dans une valeur de retour que dans des paramètres de sortie. S’il n’y a qu’une seule sortie, nous recommandons d’utiliser la valeur de retour. Lorsqu’il y en a plusieurs, il est nécessaire d’utiliser les paramètres de sortie.
Pour produire plusieurs sorties, utilisez la méthode set() fournie par l’interface azure.functions.Out afin d’affecter une valeur à la liaison. Par exemple, la fonction suivante peut placer un message dans une file d’attente tout en renvoyant une réponse HTTP.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Journalisation
L’accès à l’enregistreur d’événements du runtime d’Azure Functions se fait par l’intermédiaire du gestionnaire logging racine dans l’application de fonction. Cet enregistreur d’événements, lié à Application Insights, permet de signaler les avertissements et les erreurs qui se produisent pendant l’exécution de la fonction.
L’exemple suivant enregistre un message d’informations lorsque la fonction est appelée avec un déclencheur HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
D’autres méthodes d’enregistrement permettent d’écrire dans la console à différents niveaux de trace :
| Méthode | Description |
|---|---|
critical(_message_) |
Écrit un message de niveau CRITIQUE sur l’enregistreur racine. |
error(_message_) |
Écrit un message de niveau ERREUR sur l’enregistreur racine. |
warning(_message_) |
Écrit un message de niveau AVERTISSEMENT sur l’enregistreur racine. |
info(_message_) |
Écrit un message de niveau INFO sur l’enregistreur racine. |
debug(_message_) |
Écrit un message de niveau DÉBOGAGE sur l’enregistreur racine. |
Pour en savoir plus sur la journalisation, consultez Surveiller l’exécution des fonctions Azure.
Journalisation à partir de threads créés
Pour consulter les journaux provenant de vos threads créés, insérez l’argument context dans la signature de la fonction. Cet argument contient un attribut thread_local_storage qui stocke un invocation_id local. Cela peut être défini sur le courant de la fonction invocation_id pour garantir que le contexte est modifié.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Enregistrer une télémétrie personnalisée
Par défaut, le runtime Functions collecte les journaux et d’autres données de télémétrie générées par vos fonctions. Ces données de télémétrie finissent comme des traces dans les Insights d’applications. La télémétrie des requêtes et des dépendances pour certains services Azure est également collectée par défaut via des déclencheurs et des liaisons.
Pour collecter une demande et des données de télémétrie de dépendance personnalisées en dehors des liaisons, vous pouvez utiliser les Extensions Python OpenCensus. Cette extension envoie des données de télémétrie personnalisées à votre instance Application Insights. Vous trouverez une liste des extensions prises en charge dans le référentiel OpenCensus.
Remarque
Pour utiliser les extensions Python d’OpenCensus, vous devez activer les extensions de Worker Python dans votre application de fonction en définissant PYTHON_ENABLE_WORKER_EXTENSIONS sur 1. Vous devez également passer à l’utilisation de la chaîne de connexion d’Application Insights en ajoutant le paramètre APPLICATIONINSIGHTS_CONNECTION_STRING à vos APPLICATIONINSIGHTS_CONNECTION_STRING, s’ils ne sont pas déjà présents.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
Déclencheur HTTP
Le déclencheur HTTP est défini dans le fichier function.json. Le name de la liaison doit correspondre au paramètre nommé dans la fonction.
Dans les exemples précédents, un nom de liaison req est utilisé. Ce paramètre est un objet HttpRequest, et un objet HttpResponse est retourné.
À partir de l’objet HttpRequest, vous pouvez obtenir des en-têtes de demande, des paramètres de requête, des paramètres de route et le corps du message.
L’exemple suivant provient du modèle de déclencheur HTTP pour Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
Dans cette fonction, vous obtenez la valeur du paramètre de requête name à partir du paramètre params de l’objet HttpRequest. Vous lisez le corps du message encodé JSON à l’aide de la méthode get_json.
De même, vous pouvez définir les status_code et headers pour le message de réponse dans l’objet status_code retourné.
Le déclencheur HTTP est défini comme une méthode qui accepte un paramètre de liaison nommé (objet HttpRequest) et qui retourne un objet HttpResponse. Vous appliquez le décorateur function_name à la méthode pour définir le nom de la fonction, tandis que vous appliquez le décorateur route pour définir le point de terminaison HTTP.
L’exemple provient du modèle de déclencheur HTTP pour le modèle de programmation Python v2, où req est le nom du paramètre de liaison. Il s’agit de l’exemple de code fourni lorsque vous créez une fonction à l’aide de Azure Functions Core Tools ou de Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
À partir de l’objet HttpRequest, vous pouvez obtenir des en-têtes de demande, des paramètres de requête, des paramètres de route et le corps du message. Dans cette fonction, vous obtenez la valeur du paramètre de requête name à partir du paramètre params de l’objet HttpRequest. Vous lisez le corps du message encodé JSON à l’aide de la méthode get_json.
De même, vous pouvez définir les status_code et headers pour le message de réponse dans l’objet status_code retourné.
Pour passer un nom dans cet exemple, collez l’URL qui est fournie lors de vous exécutez la fonction et ajoutez "?name={name}" à la fin.
Infrastructures web
Vous pouvez utiliser des infrastructures compatibles WSGI (Web Server Gateway Interface) et ASGI (Asynchrone Server Gateway Interface), telles que Flask et FastAPI, avec vos fonctions Python déclenchées par HTTP. Cette section montre comment modifier vos fonctions pour prendre en charge ces infrastructures.
Tout d’abord, le fichier function.json doit être mis à jour pour inclure un route dans le déclencheur HTTP, comme illustré dans l’exemple suivant :
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Le fichier host.json doit également être mis à jour pour inclure un routePrefix HTTP, comme illustré dans l’exemple suivant :
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Mettez à jour le fichier de code Python init.py, en fonction de l’interface utilisée par votre infrastructure. L’exemple suivant illustre une approche de gestionnaire ASGI ou une approche de wrapper WSGI pour Flask :
Vous pouvez utiliser des infrastructures compatibles WSGI (Web Server Gateway Interface) et ASGI (Asynchrone Server Gateway Interface), telles que Flask et FastAPI, avec vos fonctions Python déclenchées par HTTP. Vous devez d’abord mettre à jour le fichier host.json pour inclure un routePrefix HTTP, comme le montre l’exemple suivant :
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Le code du framework ressemble à l’exemple suivant :
AsgiFunctionApp est la classe d’application de fonction de niveau supérieur pour la construction de fonctions HTTP ASGI.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Mise à l’échelle et niveau de performance
Pour connaître les meilleures pratiques en matière de mise à l’échelle et de niveau de performance pour les applications de fonction Python, consultez l’article sur la mise à l’échelle et le niveau de performance Python.
Context
Pour obtenir le contexte d’appel d’une fonction lorsqu’elle est exécutée, ajoutez l’argument context à sa signature.
Par exemple :
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
La classe Context contient les attributs de chaîne suivants :
| Attribut | Description |
|---|---|
function_directory |
Répertoire dans lequel s’exécute la fonction. |
function_name |
Nom de la fonction. |
invocation_id |
ID de l’appel de fonction en cours. |
thread_local_storage |
Le stockage local de thread de la fonction. Contient un invocation_id local pour la journalisation à partir de threads créés. |
trace_context |
Le contexte pour le suivi distribué. Pour plus d’informations, consultez Trace Context. |
retry_context |
Le contexte pour les nouvelles tentatives d’appel de la fonction. Pour plus d’informations, consultez retry-policies. |
Variables globales
L’état de votre application n’est pas systématiquement conservé en vue des exécutions ultérieures. Toutefois, le runtime Azure Functions réutilise souvent le même processus pour plusieurs exécutions de la même application. Pour mettre en cache les résultats d’un calcul coûteux, vous devez le déclarer en tant que variable globale.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Variables d'environnement
Dans Azure Functions, les paramètres de l’application, par exemple, les chaînes de connexion de service, sont exposés en tant que variables d’environnement lorsque c’est exécuté. Il existe deux méthodes principales pour accéder à ces paramètres dans votre code.
| Méthode | Description |
|---|---|
os.environ["myAppSetting"] |
Tente d’accéder au paramètre d’application par nom de clé, en générant une erreur en cas d’échec. |
os.getenv("myAppSetting") |
Tente d’accéder au paramètre d’application par nom de clé, et renvoie None en cas d’échec. |
Ces deux méthodes vous obligent à déclarer import os.
L’exemple suivant utilise os.environ["myAppSetting"] pour obtenir le os.environ["myAppSetting"], avec la clé nommée myAppSetting :
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Pour le développement local, les paramètres d’application sont conservés dans le fichier local.settings.json.
Dans Azure Functions, les paramètres de l’application, par exemple, les chaînes de connexion de service, sont exposés en tant que variables d’environnement lorsque c’est exécuté. Il existe deux méthodes principales pour accéder à ces paramètres dans votre code.
| Méthode | Description |
|---|---|
os.environ["myAppSetting"] |
Tente d’accéder au paramètre d’application par nom de clé, en générant une erreur en cas d’échec. |
os.getenv("myAppSetting") |
Tente d’accéder au paramètre d’application par nom de clé, et renvoie None en cas d’échec. |
Ces deux méthodes vous obligent à déclarer import os.
L’exemple suivant utilise os.environ["myAppSetting"] pour obtenir le os.environ["myAppSetting"], avec la clé nommée myAppSetting :
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Pour le développement local, les paramètres d’application sont conservés dans le fichier local.settings.json.
Version Python
Azure Functions prend en charge les versions de Python suivantes :
| Version de Functions | Versions de Python* |
|---|---|
| 4.x | 3.11 3.10 3.9 3.8 3.7 |
| 3.x | 3.9 3.8 3.7 |
*Distributions Python officielles
Pour demander une version de Python particulière lorsque vous créez votre application de fonction dans Azure, utilisez l’option --runtime-version de la commande az functionapp create. La version du runtime Functions est définie par l’option --functions-version. La version de Python est définie lors de la création de l’application de fonction, et elle ne peut pas être modifiée pour les applications s’exécutant dans un plan Consommation.
Le runtime utilise la version de Python disponible lorsqu’il est exécuté en local.
Modification de la version de Python
Pour définir une application de fonction Python sur une version spécifique du langage, vous devez spécifier le langage et sa version dans le champ LinuxFxVersion de la configuration du site. Pour modifier l’application Python de façon à utiliser Python 3.8 par exemple, affectez la valeur linuxFxVersion à python|3.8.
Pour savoir comment afficher et modifier le paramètre de site linuxFxVersion, consultez Comment cibler des versions du runtime Azure Functions.
Pour plus d’informations générales, consultez la Stratégie de prise en charge du runtime Azure Functions et Langages pris en charge dans Azure Functions.
Gestion des packages
Si vous développez en local à l’aide de Core Tools ou de Visual Studio Code, ajoutez les noms et les versions des packages requis au fichier requirements.txt et installez-les à l’aide de pip.
Par exemple, vous pouvez utiliser le fichier requirements.txt suivant et la commande pip pour installer le package requests à partir de PyPI.
requests==2.19.1
pip install -r requirements.txt
Quand vous exécutez vos fonctions dans un plan App Service, les dépendances que vous définissez dans requirements.txt sont prioritaires sur les modules Python intégrés tels que logging. Cette priorité peut entraîner des conflits lorsque les modules intégrés ont des noms identiques à ceux des répertoires de votre code. Quand vous exécutez un plan Consommation ou un plan Elastic Premium, les conflits sont moins probables, car vos dépendances ne sont pas classées par ordre de priorité par défaut.
Pour éviter les problèmes d’exécution dans un plan App Service, ne nommez pas vos répertoires de la même façon que les modules natifs Python et n’incluez pas de bibliothèques natives Python dans le fichier requirements.txt de votre projet.
Publier sur Azure
Avant de procéder à la publication, vérifiez que toutes les dépendances disponibles publiquement figurent dans le fichier requirements.txt. qui se trouve à la racine de votre répertoire de projet.
Vous pouvez trouver les fichiers et dossiers du projet qui sont exclus de la publication, y compris le dossier d’environnement virtuel, dans le répertoire racine de votre projet.
Les actions de build prises en charge pour la publication de votre projet Python sur Azure sont au nombre de trois : build distante, build locale et builds utilisant des dépendances personnalisées.
Vous pouvez également utiliser Azure Pipelines pour générer vos dépendances et publier en livraison continue (CD). Pour plus d’informations, consultez Livraison continue avec Azure Pipelines.
Build distante
Quand la build distante est utilisée, les dépendances restaurées sur le serveur et les dépendances natives correspondent à l’environnement de production. La taille du package de déploiement à charger s’en trouve réduite. Utilisez une build distante lorsque vous développez des applications Python sur Windows. Si votre projet a des dépendances personnalisées, vous pouvez utiliser la build distante avec une URL d’index supplémentaire.
Les dépendances sont obtenues à distance en fonction du contenu du fichier requirements.txt. L’option Build distante est la méthode de génération recommandée. Par défaut, Core Tools demande une build distante lorsque vous utilisez la commande func azure functionapp publishsuivante pour publier votre projet Python dans Azure.
func azure functionapp publish <APP_NAME>
Veillez à remplacer <APP_NAME> par le nom de votre application de fonction dans Azure.
L’extension Azure Functions pour Visual Studio Code demande également une build distante par défaut.
Build locale
Les dépendances sont obtenues localement en fonction du contenu du fichier requirements.txt. Vous pouvez éviter de créer une build distante en utilisant la commande func azure functionapp publish suivante pour publier avec une build locale :
func azure functionapp publish <APP_NAME> --build local
Veillez à remplacer <APP_NAME> par le nom de votre application de fonction dans Azure.
Avec l’option --build local, les dépendances de projet sont lues à partir du fichier requirements.txt. Ces packages dépendants sont téléchargés et installés localement. Les fichiers de projet et les dépendances sont déployés de votre ordinateur local vers Azure, ce qui entraîne le chargement d’un package de déploiement plus important sur Azure. Si pour une raison quelconque les dépendances de votre fichier requirements.txt ne peuvent pas être récupérées par Core Tools, vous devez utiliser l’option de dépendances personnalisées pour la publication.
Nous vous déconseillons d’utiliser des builds locales lorsque vous développez en local sur Windows.
Dépendances personnalisées
Si les dépendances de votre projet sont introuvables dans l’index du package Python, il existe deux façons de générer le projet. La première manière, la méthode de build dépend de la façon dont vous générez le projet.
Build distante avec l’URL d’index supplémentaire
Si vos packages sont disponibles à partir d’un index de package personnalisé accessible, utilisez une build distante. Avant la publication, veillez à créer un paramètre d’application nommé PIP_EXTRA_INDEX_URL. La valeur de ce paramètre est l’URL de votre index de package personnalisé. L’utilisation de ce paramètre indique à la build distante d’exécuter pip install en utilisant l’option --extra-index-url. Pour plus d’informations, consultez la documentation pip installPython.
Vous pouvez aussi utiliser des informations d’authentification de base avec vos URL d’index de package supplémentaires. Pour plus d’informations, consultez informations d'identification de base dans la documentation Python.
Installer des packages locaux
Si votre projet utilise des packages non disponibles publiquement pour nos outils, vous pouvez les rendre disponibles pour votre application en les plaçant dans le répertoire __app__/.python_packages. Avant d’effectuer la publication, exécutez la commande suivante pour installer les dépendances localement :
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
Si vous utilisez des dépendances personnalisées, vous devriez utiliser l’option de publication --no-build suivante, car vous avez déjà installé les dépendances dans le dossier du projet.
func azure functionapp publish <APP_NAME> --no-build
Veillez à remplacer <APP_NAME> par le nom de votre application de fonction dans Azure.
Effectuer des tests unitaires
Les fonctions écrites en Python peuvent être testées comme tout autre code Python à l’aide des frameworks de test standard. Pour la plupart des liaisons, il est possible de créer un objet d’entrée factice en créant une instance d’une classe appropriée à partir du package azure.functions. Dans la mesure où le package azure.functions n’est pas immédiatement disponible, veillez à l’installer par le biais de votre fichier requirements.txt (cf. section ci-dessus, Gestion des packages).
Avec my_second_function comme exemple. Voici un test fictif d’une fonction déclenchée par HTTP :
Tout d’abord, nous devons créer le fichier <project_root>/my_second_function/function.json et définir cette fonction en tant que déclencheur http.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Ensuite, vous pouvez implémenter my_second_function et shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Vous pouvez commencer à écrire des cas de test pour votre déclencheur HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
Dans votre dossier d’environnement virtuel Python .venv, installez votre framework de test Python favori, tel que pip install pytest. Exécutez ensuite pytest tests pour vérifier le résultat du test.
Tout d’abord, créez le <fichier project_root>/function_app.py et implémentez la fonction my_second_functionen tant que déclencheur HTTP et shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
Vous pouvez commencer à écrire des cas de test pour votre déclencheur HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
Dans votre dossier d’environnement virtuel Python .venv, installez votre infrastructure de test Python favorite, telle que pip install pytest. Exécutez ensuite pytest tests pour vérifier le résultat du test.
Fichiers temporaires
La méthode tempfile.gettempdir() retourne un dossier temporaire, /tmp sous Linux. Votre application peut utiliser ce répertoire pour stocker les fichiers temporaires qui sont générés et utilisés par vos fonctions lorsqu’elles sont en cours d’exécution.
Important
Il n’est pas garanti que les fichiers écrits dans le répertoire temporaire persistent d’un appel à l’autre. Lors du scale-out, les fichiers temporaires ne sont pas partagés entre les instances.
L’exemple suivant crée un fichier temporaire nommé dans le répertoire temporaire (/tmp) :
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
Nous vous recommandons de conserver vos tests dans un dossier distinct du dossier de projet. Cette action vous évite d’avoir à déployer du code de test avec votre application.
Bibliothèques préinstallées
Le runtime Functions Python s’accompagne de quelques bibliothèques.
La bibliothèque standard Python
La bibliothèque standard Python contient une liste de modules Python intégrés qui sont fournis avec chaque distribution Python. La plupart de ces bibliothèques vous aident à accéder aux fonctionnalités du système, telles que les entrées/sorties (E/S) de fichiers. Sur les systèmes Windows, ces bibliothèques sont installées avec Python. Sur les systèmes Unix, elles sont fournies par des collections de packages.
Pour afficher la bibliothèque de votre version de Python, accédez à :
- Bibliothèque standard Python 3.8
- Bibliothèque standard Python 3.9
- Bibliothèque standard Python 3.10
- Bibliothèque standard Python 3.11
Dépendances du Worker Python Azure Functions
Le Worker Python Azure Functions a besoin d’un ensemble spécifique de bibliothèques. Vous pouvez aussi utiliser ces bibliothèques dans vos fonctions, mais elles ne font pas partie intégrante du standard Python. Si vos fonctions reposent sur une de ces bibliothèques, il se peut que votre code n’y ait pas accès quand il s’exécute en dehors d’Azure Functions.
Remarque
Si le fichier requirements.txt de votre application de fonction contient une entrée azure-functions-worker, supprimez-la. Le worker functions est géré automatiquement par la Plateforme Azure Functions et nous le mettons régulièrement à jour avec de nouvelles fonctionnalités et de correctifs de bogues. L’installation manuelle d’une ancienne version du worker dans le fichier requirements.txt peut entraîner des problèmes inattendus.
Notes
Si votre package contient certaines bibliothèques susceptibles d’entrer en conflit avec les dépendances du Worker (par exemple, protobuf, tensorflow ou grpcio), configurez PYTHON_ISOLATE_WORKER_DEPENDENCIES sur 1 dans les paramètres de l’application pour empêcher votre application de faire référence aux dépendances du Worker.
La Bibliothèque Python Azure Functions
Chaque mise à jour du Worker Python comprend une nouvelle version de la bibliothèque Python Azure Functions (azure.functions). Cette approche facilite la mise à jour continue de vos applications de fonction Python, car chaque mise à jour offre une compatibilité descendante. Pour une liste des versions de cette bibliothèque, allez à azure-functions PyPi.
La version de la bibliothèque runtime est corrigée par Azure et ne peut pas être remplacée par requirements.txt. L’entrée azure-functions dans requirements.txt est réservée au linting et à la sensibilisation des clients.
Utilisez le code suivant pour effectuer le suivi de la version effective de la bibliothèque Functions Python dans votre runtime :
getattr(azure.functions, '__version__', '< 1.2.1')
Bibliothèques système runtime
Pour obtenir la liste des bibliothèques système préinstallées dans les images Docker du Worker Python, référez-vous aux éléments suivants :
| Runtime Functions | Version de Debian | Versions de Python |
|---|---|---|
| Version 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Extensions de Worker Python
Le processus Worker Python qui s’exécute dans Azure Functions vous permet d’intégrer des bibliothèques tierces dans votre application de fonction. Ces bibliothèques d’extensions jouent le rôle d’intergiciel qui peut injecter des opérations spécifiques pendant le cycle de vie de l’exécution de votre fonction.
Les extensions sont importées dans votre code de fonction de la même manière qu’un module de bibliothèque Python standard. Les extensions sont exécutées en fonction des étendues suivantes :
| Étendue | Description |
|---|---|
| Au niveau de l'application | Lorsqu’elle est importée dans un déclencheur de fonction, l’extension s’applique à chaque exécution de fonction dans l’application. |
| Au niveau de la fonction | L’exécution est limitée uniquement au déclencheur de fonction spécifique dans lequel elle est importée. |
Passez en revue les informations relatives à chaque extension pour en savoir plus sur l’étendue dans laquelle l’extension s’exécute.
Les extensions implémentent une interface d’extension de Worker Python. Cette action permet au processus Worker Python d’appeler le code de l’extension pendant le cycle de vie de l’exécution de la fonction. Pour plus d’informations, consultez Créer des extensions.
Utilisation d’extensions
Vous pouvez utiliser une bibliothèque d’extensions de Worker Python dans vos fonctions Python effectuant les étapes suivantes :
- Ajoutez le package d’extension dans le fichier requirements.txt de votre projet.
- Installez la bibliothèque dans votre application.
- Ajoutez les paramètres d’application suivants :
- Localement : entrez
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"dans la sectionValuesde votre fichierlocal.settings.json. - Azure : entrez
PYTHON_ENABLE_WORKER_EXTENSIONS=1dans les paramètres de votre application.
- Localement : entrez
- Importez le module d’extension dans votre déclencheur de fonction.
- Configurez l’instance d’extension, le cas échéant. Les exigences de configuration doivent être mentionnées dans la documentation de l’extension.
Important
Les bibliothèques d’extension de Worker Python tierces ne sont pas prises en charge ni garanties par Microsoft. Vous devez vous assurer que toutes les extensions que vous utilisez dans votre application de fonction sont dignes de confiance, et vous assumez pleinement le risque lié à l’utilisation d’une extension malveillante ou mal écrite.
Les tiers doivent fournir une documentation spécifique sur la façon d’installer et de consommer leurs extensions dans votre application de fonction. Pour obtenir un exemple de base de la consommation d’une extension, consultez Consommation de votre extension.
Voici des exemples d’utilisation d’extensions dans une application de fonction, par étendue :
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Création d’extensions
Les extensions sont créées par des développeurs de bibliothèques tierces qui ont créé des fonctionnalités qui peuvent être intégrées dans Azure Functions. Un développeur d’extensions conçoit, implémente et publie des packages Python qui contiennent une logique personnalisée conçue spécifiquement pour être exécutée dans le contexte d’une exécution de fonction. Ces extensions peuvent être publiées dans le registre PyPI ou dans des référentiels GitHub.
Pour savoir comment créer, empaqueter, publier et consommer un package d’extension de Worker Python, consultez Développer des extensions de Worker Python pour Azure Functions.
Extensions au niveau de l’application
Une extension héritée de AppExtensionBase s’exécute dans une étendue d’application.
AppExtensionBase expose les méthodes de classe abstraite suivantes que vous pouvez implémenter :
| Méthode | Description |
|---|---|
init |
Appelée après l’importation de l’extension. |
configure |
Appelée à partir du code de fonction lorsque cela est nécessaire pour configurer l’extension. |
post_function_load_app_level |
Appelée juste après le chargement de la fonction. Le nom de la fonction et le répertoire de la fonction sont transmis à l’extension. Gardez à l’esprit que le répertoire de la fonction est en lecture seule et que toute tentative d’écriture dans le fichier local de ce répertoire échoue. |
pre_invocation_app_level |
Appelée juste avant le déclenchement de la fonction. Le contexte de la fonction et les arguments d’appel de la fonction sont transmis à l’extension. Vous pouvez généralement transmettre d’autres attributs dans l’objet de contexte pour que le code de la fonction les consomme. |
post_invocation_app_level |
Appelée juste après la fin de l’exécution de la fonction. Le contexte de la fonction, les arguments d’appel de la fonction et l’objet de retour d’appel sont transmis à l’extension. Cette implémentation est un bon endroit pour vérifier si l’exécution des crochets du cycle de vie a réussi. |
Extensions au niveau de la fonction
Une extension qui hérite de FuncExtensionBase s’exécute dans un déclencheur de fonction spécifique.
FuncExtensionBase expose les méthodes de classe abstraite suivantes que vous pouvez implémenter :
| Méthode | Description |
|---|---|
__init__ |
Constructeur de l’extension. Elle est appelée lorsqu’une instance d’extension est initialisée dans une fonction spécifique. Lorsque vous implémentez cette méthode abstraite, vous souhaiterez peut-être accepter un paramètre filename et le transmettre à la méthode super().__init__(filename) du parent pour une inscription appropriée de l’extension. |
post_function_load |
Appelée juste après le chargement de la fonction. Le nom de la fonction et le répertoire de la fonction sont transmis à l’extension. Gardez à l’esprit que le répertoire de la fonction est en lecture seule et que toute tentative d’écriture dans le fichier local de ce répertoire échoue. |
pre_invocation |
Appelée juste avant le déclenchement de la fonction. Le contexte de la fonction et les arguments d’appel de la fonction sont transmis à l’extension. Vous pouvez généralement transmettre d’autres attributs dans l’objet de contexte pour que le code de la fonction les consomme. |
post_invocation |
Appelée juste après la fin de l’exécution de la fonction. Le contexte de la fonction, les arguments d’appel de la fonction et l’objet de retour d’appel sont transmis à l’extension. Cette implémentation est un bon endroit pour vérifier si l’exécution des crochets du cycle de vie a réussi. |
Partage de ressources cross-origin
Azure Functions prend en charge le partage des ressources cross-origin (CORS). CORS est configuré dans le portail et par le biais d’Azure CLI. La liste des origines autorisées CORS s’applique au niveau de l’application de fonction. Quand CORS est activé, les réponses incluent l’en-tête Access-Control-Allow-Origin. Pour plus d'informations, consultez la page Partage des ressources cross-origin.
Le partage de ressources cross-origin (CORS) est entièrement pris en charge pour les applications de fonction Python.
Async
Par défaut, une instance de l’hôte pour Python ne peut traiter qu’un seul appel de fonction à la fois. Cela s’explique par le fait que Python est un runtime à thread unique. Pour une application de fonction qui traite un grand nombre d’événements d’entrée/sortie ou qui est liée aux entrées/sorties, vous pouvez améliorer considérablement les performances en exécutant les fonctions de manière asynchrone. Pour plus d’informations, consultez Améliorer les performances de débit des applications Python dans Azure Functions.
Mémoire partagée (préversion)
Pour améliorer le débit, Azure Functions permet à votre Worker de langage Python hors processus de partager la mémoire avec le processus hôte Functions. Lorsque votre application de fonction atteint des goulots d’étranglement, vous pouvez activer la mémoire partagée en ajoutant un paramètre d’application nommé FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED avec la valeur 1. Lorsque la mémoire partagée est activée, vous pouvez utiliser le paramètre DOCKER_SHM_SIZE pour définir la mémoire partagée sur une valeur telle que 268435456, ce qui équivaut à 256 Mo.
Par exemple, vous pouvez activer la mémoire partagée pour réduire les goulots d’étranglement lors de l’utilisation de liaisons de Stockage Blob pour transférer des charges utiles supérieures à 1 Mo.
Cette fonctionnalité est disponible uniquement pour les applications de fonction qui s’exécutent dans les plans Premium et Dedicated (Azure App Service). Pour plus d’informations, consultez Mémoire partagée.
Problèmes connus et FAQ
Voici deux guides de résolution des problèmes courants :
Voici deux guides de résolution des problèmes connus liés au modèle de programmation v2 :
- Impossible de charger le fichier ou l’assembly
- Impossible de résoudre la connexion Stockage Azure nommée Storage
Tous les problèmes connus et les demandes de fonctionnalités sont listés dans Liste des problèmes GitHub. Si vous rencontrez un problème qui n’apparaît pas dans GitHub, soumettez un nouveau problème en incluant une description détaillée.
Étapes suivantes
Pour plus d’informations, consultez les ressources suivantes :
- Documentation sur l’API du package Azure Functions
- Meilleures pratiques pour Azure Functions
- Azure Functions triggers and bindings (Déclencheurs et liaisons Azure Functions)
- Liaisons de Stockage Blob
- Liaisons HTTP et webhook
- Liaisons de Stockage File d’attente
- Déclencheurs de minuteur
Vous rencontrez des problèmes avec l’utilisation de Python ? Dites-nous ce qui se passe.