Remarque
L’accès à cette page requiert une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page requiert une autorisation. Vous pouvez essayer de modifier des répertoires.
S’APPLIQUE À : Tous les niveaux de Gestion des API
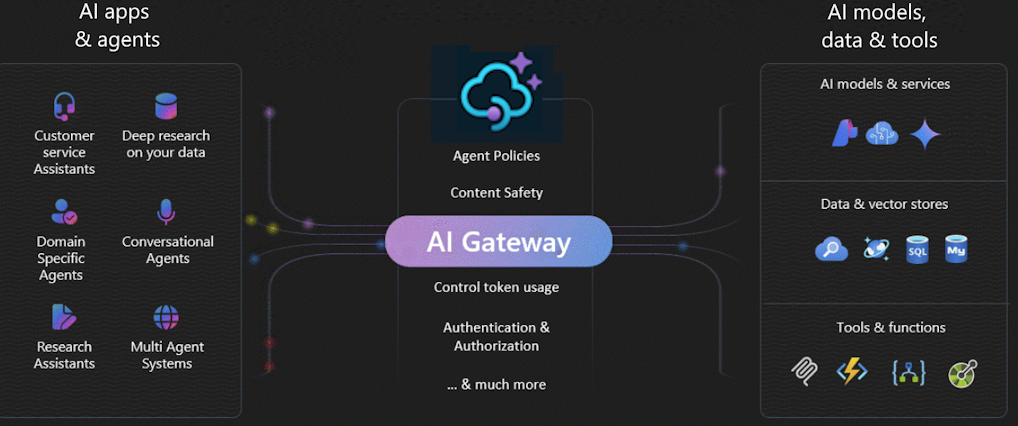
La passerelle IA dans Gestion des API Azure est un ensemble de fonctionnalités qui vous aident à gérer efficacement vos back-ends IA. Ces fonctionnalités vous aident à gérer, sécuriser, mettre à l’échelle, surveiller et régir les déploiements de modèles de langage volumineux (LLM), les API IA et les serveurs MCP (Model Context Protocol) qui sauvegardent vos applications et agents intelligents.
Utilisez la passerelle IA pour gérer un large éventail de points de terminaison IA, notamment :
- Microsoft Foundry et Azure OpenAI dans les déploiements de modèles Microsoft Foundry
- Déploiements d’API d’inférence de modèle Azure AI
- Serveurs MCP distants et API de l’agent A2A
- Modèles et points de terminaison compatibles OpenAI hébergés par des fournisseurs non-Microsoft
- Modèles et points de terminaison auto-hébergés
Remarque
La passerelle IA, y compris les fonctionnalités du serveur MCP, étend la passerelle API existante de Gestion des API ; ce n’est pas une offre distincte. Les fonctionnalités de gouvernance et de développement associées se trouvent dans le Centre des API Azure.
Pourquoi utiliser une passerelle IA ?
L’adoption de l’IA dans les organisations implique plusieurs phases :
- Définition des exigences et évaluation des modèles IA
- Création d’applications et d’agents IA qui ont besoin d’accéder aux modèles et services IA
- Opérationnalisation et déploiement d’applications et de back-ends IA en production
À mesure que l’adoption de l’IA mûrit, en particulier dans les grandes entreprises, la passerelle IA aide à relever les principaux défis, ce qui aide à :
- Authentifier et autoriser l’accès aux services IA
- Équilibre de charge entre plusieurs points de terminaison IA
- Surveiller et journaliser les interactions avec l’IA
- Gérer l’utilisation et les quotas des jetons dans plusieurs applications
- Activer le libre-service pour les équipes de développement
Médiation et contrôle du trafic
Avec la passerelle IA, vous pouvez :
- Importer et configurer rapidement des points de terminaison LLM compatibles OpenAI ou passthrough en tant qu’API
- Gérer les modèles déployés dans Microsoft Foundry ou les fournisseurs tels qu’Amazon Bedrock
- Gérer les achèvements des conversations, les réponses et les API en temps réel
- Exposer vos API REST existantes en tant que serveurs MCP et prendre en charge la transmission directe aux serveurs MCP
- Importer et gérer les API de l’agent A2A (préversion)
Par exemple, pour intégrer un modèle déployé dans Microsoft Foundry ou un autre fournisseur, Gestion des API fournit des Assistants simplifiés pour importer le schéma et configurer l’authentification sur le point de terminaison IA à l’aide d’une identité managée, en supprimant la nécessité d’une configuration manuelle. Dans la même expérience conviviale, vous pouvez préconfigurer des stratégies pour l’extensibilité, la sécurité et l’observabilité des API.

Plus d’informations :
- Importer une API Microsoft Foundry
- Importer une API de modèle de langage
- Exposer une API REST en tant que serveur MCP
- Exposer et régir un serveur MCP existant
- Importer une API d’agent A2A
Scalabilité et performance
L’une des principales ressources des services d’INTELLIGENCE artificielle générative est des jetons. Microsoft Foundry et d’autres fournisseurs attribuent des quotas pour vos déploiements de modèle sous forme de jetons par minute (TPM). Vous distribuez ces jetons au sein de vos utilisateurs du modèle, tels que différentes applications, équipes de développeurs ou départements de l'entreprise.
Si vous avez une seule application connectée à un backend de service d'IA, vous pouvez gérer la consommation de jetons avec une limite TPM que vous définissez directement sur le déploiement du modèle. Toutefois, lorsque votre portefeuille d’applications augmente, vous pouvez avoir plusieurs applications appelant des points de terminaison de service IA uniques ou multiples. Ces points de terminaison peuvent être des instances d’unités de débit approvisionnées (PTU) ou de paiement à l’utilisation. Vous devez vous assurer qu’une application n’utilise pas l’ensemble du quota TPM et empêche les autres applications d’accéder aux back-ends dont elles ont besoin.
Limitation du débit de jetons et quotas
Configurez une stratégie de limite de jetons sur vos API LLM pour gérer et appliquer des limites par consommateur d’API en fonction de l’utilisation des jetons de service AI. Avec cette stratégie, vous pouvez définir une limite TPM ou un quota de jetons sur une période spécifiée, par exemple, chaque heure, chaque jour, chaque semaine, chaque mois ou chaque année.
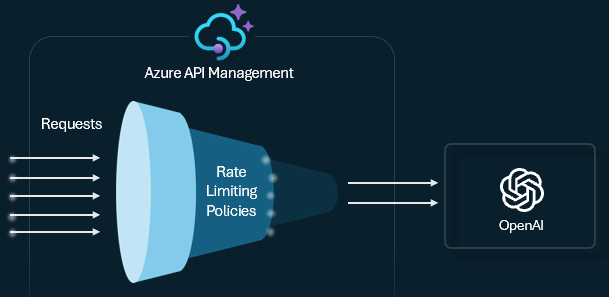
Cette stratégie offre une certaine flexibilité pour attribuer des limites basées sur les jetons sur n’importe quelle clé de compteur, comme une clé d’abonnement, une adresse IP d’origine ou une clé arbitraire définie via une expression de stratégie. La stratégie active également la précalculation des jetons d’invite côté Gestion des API Azure, ce qui réduit les demandes inutiles adressées au serveur principal du service IA si l’invite dépasse déjà la limite.
L’exemple de base suivant montre comment définir une limite de 500 TPM par clé d’abonnement :
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
Plus d’informations :
Mise en cache sémantique
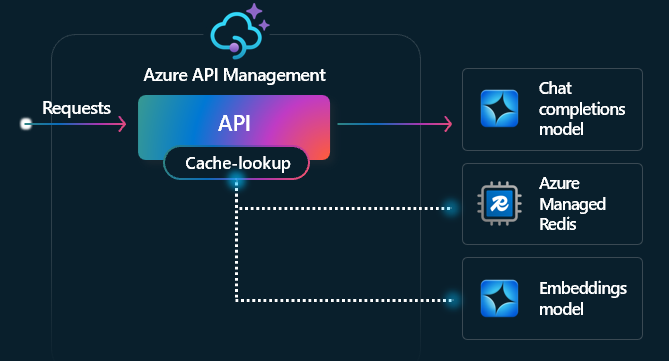
La mise en cache sémantique est une technique qui améliore les performances des API LLM en mettant en cache les résultats (achèvements) des invites précédentes et en les réutilisant en comparant la proximité du vecteur de l’invite aux demandes antérieures. Cette technique réduit le nombre d’appels effectués au back-end du service IA, améliore les temps de réponse pour les utilisateurs finaux et peut contribuer à réduire les coûts.
Dans Gestion des API, activez la mise en cache sémantique à l’aide d’Azure Managed Redis ou d’un autre cache externe compatible avec RediSearch et intégré à Gestion des API Azure. À l’aide de l’API Embeddings, les politiques llm-semantic-cache-store et llm-semantic-cache-lookup stockent et récupèrent depuis le cache des complétions de texte qui sont sémantiquement similaires. Cette approche veille à une réutilisation des saisies semi-automatiques et a donc pour effet de réduire la consommation de jetons et d’améliorer les performances des réponses.
Plus d’informations :
- Configurer un cache externe dans Gestion des API Azure
- Activer la mise en cache sémantique pour les API IA dans Gestion des API Azure
Fonctionnalités de mise à l’échelle natives dans Gestion des API
Gestion des API fournit également des fonctionnalités de mise à l’échelle intégrées pour aider la passerelle à gérer des volumes élevés de requêtes à vos API IA. Ces fonctionnalités incluent l’ajout automatique ou manuel d’unités d’échelle de passerelle et l’ajout de passerelles régionales pour les déploiements multirégions. Les fonctionnalités spécifiques dépendent du niveau de service Gestion des API.
Plus d’informations :
- Mettre à niveau et mettre à l’échelle une instance gestion des API
- Déployer une instance Gestion des API dans plusieurs régions
Remarque
Bien que la gestion des API puisse mettre à l’échelle la capacité de passerelle, vous devez également mettre à l’échelle et distribuer le trafic vers vos backends IA pour gérer une charge accrue (voir la section Résilience). Par exemple, pour tirer parti de la distribution géographique de votre système dans une configuration multirégion, vous devez déployer des services IA back-end dans les mêmes régions que vos passerelles gestion des API.
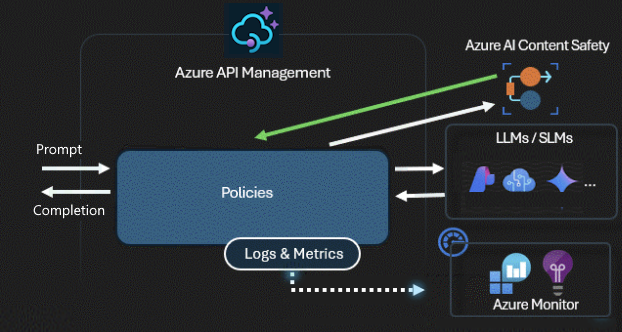
Sécurité et sécurité
Une passerelle IA sécurise et contrôle l’accès à vos API IA. Avec la passerelle IA, vous pouvez :
- Utilisez des identités managées pour vous authentifier auprès des services Azure AI. Vous n’avez donc pas besoin de clés API pour l’authentification
- Configurer l’autorisation OAuth pour les applications et agents IA pour accéder aux API ou aux serveurs MCP à l’aide du gestionnaire d’informations d’identification de Gestion des API
- Appliquer des stratégies pour modérer automatiquement les invites LLM à l’aide d’Azure AI Content Safety
Plus d’informations :
- Authentifier et autoriser l’accès aux API LLM
- À propos des informations d’identification de l’API et du gestionnaire d’informations d’identification
- Appliquer les vérifications de sécurité du contenu sur les requêtes LLM
Résilience
Un défi lors de la création d’applications intelligentes est de s’assurer que les applications sont résilientes aux défaillances du back-end et peuvent gérer des charges élevées. Si vous configurez vos points de terminaison de LLM avec des back-ends dans Gestion des API Azure, vous pouvez équilibrer la charge entre eux. Vous pouvez également définir des règles de disjoncteur pour arrêter le transfert de demandes vers les back-ends du service IA s’ils ne sont pas réactifs.
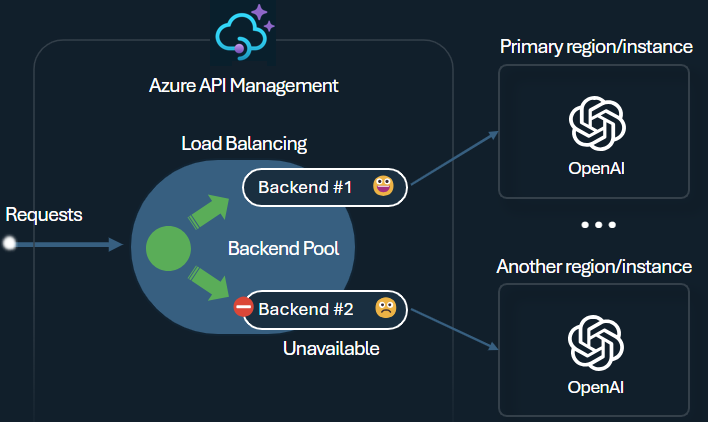
Équilibreur de charge
L’équilibreur de charge back-end prend en charge l’équilibrage de charge en mode round-robin, pondéré, basé sur la priorité et sensible à la session. Vous pouvez définir une stratégie de distribution de charge qui répond à vos besoins spécifiques. Par exemple, définissez des priorités dans la configuration de l’équilibreur de charge pour garantir une utilisation optimale des points de terminaison Microsoft Foundry spécifiques, en particulier ceux achetés en tant qu’instances PTU.
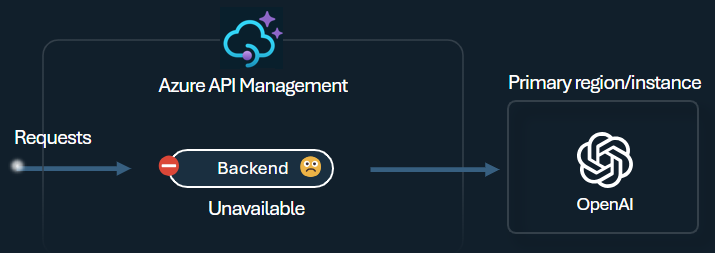
Disjoncteur
Le disjoncteur back-end présente une durée de trajet dynamique et applique des valeurs à partir de l’en-tête Retry-After fourni par le back-end. Cette fonctionnalité garantit une récupération précise et rapide des back-ends, ce qui optimise l’utilisation de vos back-ends prioritaires.
Plus d’informations :
Observabilité et gouvernance
Gestion des API fournit des fonctionnalités de supervision et d’analytique complètes pour suivre les modèles d’utilisation des jetons, optimiser les coûts, garantir la conformité avec vos stratégies de gouvernance IA et résoudre les problèmes liés à vos API IA. Utilisez ces fonctionnalités pour :
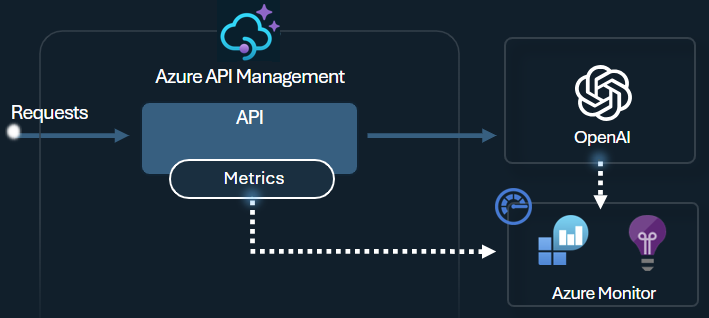
- Invites de journal et achèvements dans Azure Monitor
- Suivre les métriques de jeton par consommateur dans Application Insights
- Afficher le tableau de bord de surveillance intégré
- Configurer des stratégies avec des expressions personnalisées
- Gérer les quotas de jetons entre les applications
Par exemple, vous pouvez émettre des métriques de jeton avec la stratégie llm-emit-token-metric et ajouter des dimensions personnalisées que vous pouvez utiliser pour filtrer la métrique dans Azure Monitor. L’exemple suivant émet des métriques de jeton avec des dimensions pour l’adresse IP du client, l’ID d’API et l’ID utilisateur (à partir d’un en-tête personnalisé) :
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>
En outre, activez la journalisation pour les API LLM dans Gestion des API Azure pour suivre l’utilisation des jetons, les invites et les achèvements pour la facturation et l’audit. Après avoir activé la journalisation, vous pouvez analyser les journaux d’activité dans Application Insights et utiliser un tableau de bord intégré dans Gestion des API pour afficher les modèles de consommation de jetons sur vos API IA.

Plus d’informations :
- Journalisation de l’utilisation des jetons, des invites et des achèvements
- Émettre des métriques d'utilisation des jetons
Expérience développeur
Utilisez la passerelle IA et le Centre d’API Azure pour simplifier le développement et le déploiement de vos API IA et serveurs MCP. Outre les expériences de configuration d’importation et de stratégie conviviales pour les scénarios d’IA courants dans Gestion des API, vous pouvez tirer parti des éléments suivants :
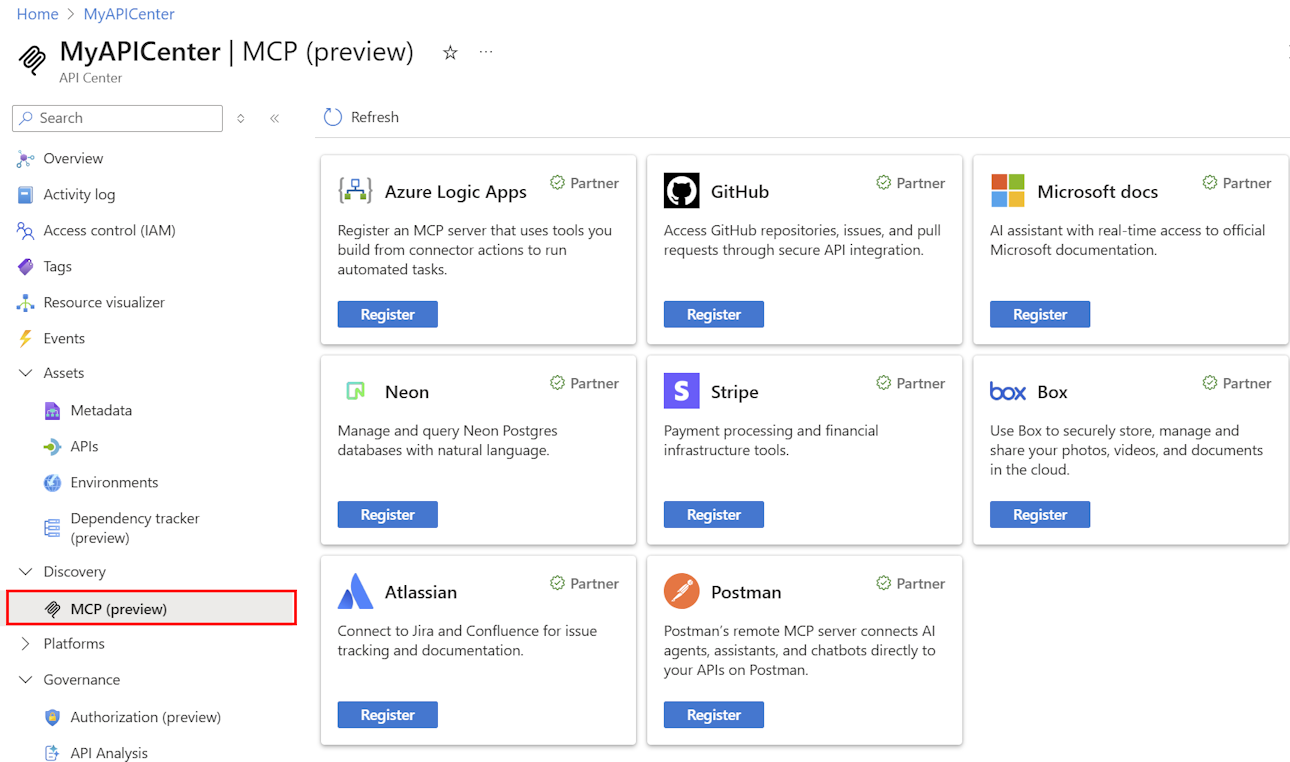
- Inscription facile des API et des serveurs MCP dans un catalogue organisationnel dans le Centre des API Azure
- Accès à l’API libre-service et au serveur MCP via des portails de développement dans gestion des API et le Centre des API
- Outil de personnalisation des stratégies de gestion des API
- Connecteur Copilot Studio du Centre d’API pour étendre les fonctionnalités des agents IA
Plus d’informations :
- Inscrire et découvrir des serveurs MCP dans le Centre des API
- Synchroniser les API et les serveurs MCP entre gestion des API et centre d’API
- Portail des développeurs Gestion des API
- Portail du Centre des API
- Ensemble de stratégies de gestion des API Azure
- Connecteur Copilot Studio du Centre d’API
Accès anticipé aux fonctionnalités de passerelle IA
En tant que client Gestion des API, vous pouvez obtenir un accès anticipé aux nouvelles fonctionnalités et capacités via le canal de publication de la passerelle IA. Cet accès vous permet d’essayer les dernières innovations de passerelle IA avant qu’elles ne soient généralement disponibles et de fournir des commentaires pour aider à mettre en forme le produit.
Plus d’informations :
Laboratoires et exemples de code
- Laboratoires de fonctionnalités de passerelle IA
- Atelier de passerelle IA
- Azure OpenAI avec Gestion des API (Node.js)
- Exemple de code Python
Architecture et conception
- Architecture de référence de passerelle IA à l’aide de Gestion des API
- Accélérateur de zone d’atterrissage de la passerelle de hub IA
- Conception et implémentation d’une solution de passerelle avec des ressources Azure OpenAI
- Utiliser une passerelle devant plusieurs déploiements Azure OpenAI