Résilience imbriquée pour les espaces de stockage direct
S’applique à : Azure Stack HCI, versions 22H2 et 21H2 ; Windows Server 2022 et Windows Server 2019
La résilience imbriquée est une fonctionnalité des espaces de stockage direct dans Azure Stack HCI et Windows Server. Elle permet à un cluster à deux serveurs de résister à plusieurs défaillances matérielles en même temps sans perte de disponibilité du stockage ; ainsi, les utilisateurs, applications et machines virtuelles continuent à fonctionner sans interruption. Cet article explique comment fonctionne la résilience imbriquée, fournit des instructions pas à pas pour se lancer et répond aux questions les plus fréquemment posées.
Avant de commencer
Envisagez la résilience imbriquée si :
- Votre cluster exécute l’un de ces systèmes d’exploitation : Azure Stack HCI, version 21H2, Azure Stack HCI, version 20H2, Windows Server 2022 ou Windows Server 2019 ; et
- Votre cluster a exactement deux nœuds serveur.
Vous ne pouvez pas utiliser la résilience imbriquée si :
- Votre cluster exécute Windows Server 2016 ; ou
- Votre cluster n’a qu’un seul nœud serveur ou a trois nœuds serveur ou plus.
Pourquoi la résilience imbriquée
Les volumes qui utilisent la résilience imbriquée peuvent rester en ligne et accessibles même si plusieurs défaillances matérielles se produisent en même temps, contrairement à la résilience avec mise en miroir bidirectionnel classique. Par exemple, si deux lecteurs échouent en même temps ou si un serveur tombe en panne et qu’un lecteur échoue, les volumes qui utilisent la résilience imbriquée restent en ligne et accessibles. Dans le cas d’une infrastructure hyperconvergée, cela augmente la durée de bon fonctionnement des applications et des machines virtuelles ; en ce qui concerne les charges de travail du serveur de fichiers, cela signifie que les utilisateurs disposent d’un accès interrompu à leurs fichiers.

En contrepartie, la résilience imbriquée a une efficacité de capacité inférieure à la mise en miroir bidirectionnelle classique, ce qui signifie que l’espace utilisable est légèrement moindre. Pour plus d’informations, consultez la section Efficacité de la capacité suivante.
Fonctionnement
Cette section fournit des informations de base sur la résilience imbriquée pour les espaces de stockage direct et décrit les deux nouvelles options de résilience et leur efficacité de capacité.
Inspiration : RAID 5+1
RAID 5+1 est une forme établie de résilience de stockage distribuée qui aide à comprendre la résilience imbriquée. Dans RAID 5+1, au sein de chaque serveur, la résilience locale est fournie par RAID-5, ou parité unique, pour offrir une protection contre la perte de n’importe quel lecteur. Ensuite, une résilience supplémentaire est fournie par RAID-1, ou mise en miroir bidirectionnelle, entre les deux serveurs pour offrir une protection contre la perte de l’un ou l’autre serveur.

Options de résilience
Les espaces de stockage direct dans Azure Stack HCI et Windows Server proposent deux options de résilience implémentées dans les logiciels, sans qu’il soit nécessaire de recourir à du matériel RAID spécialisé :
Miroir bidirectionnel imbriqué. Au sein de chaque serveur, la résilience locale est fournie par la mise en miroir bidirectionnelle, puis une résilience supplémentaire est fournie par la mise en miroir bidirectionnelle entre les deux serveurs. Il s’agit essentiellement d’un miroir quadridirectionnel, avec deux copies sur chaque serveur qui se trouvent sur des disques physiques différents. La mise en miroir bidirectionnelle imbriquée offre des performances sans compromis : les écritures sont effectuées dans toutes les copies et les lectures proviennent de n’importe quelle copie.
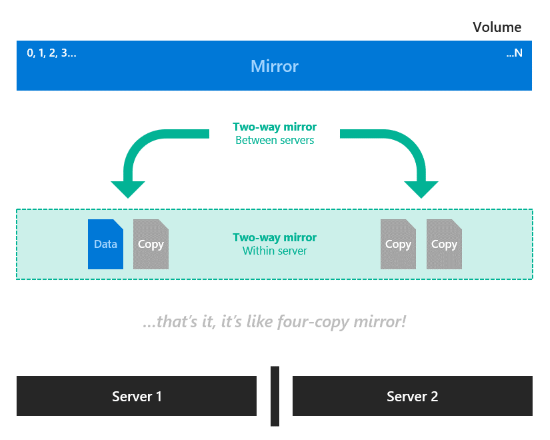
Parité imbriquée avec accélération par miroir. Combinez la mise en miroir bidirectionnelle imbriquée, illustrée dans l’image précédente, avec la parité imbriquée. Dans chaque serveur, la résilience locale pour la plupart des données est fournie par une arithmétique de parité au niveau du bit unique, sauf les nouvelles écritures récentes qui utilisent la mise en miroir bidirectionnelle. Ensuite, une résilience supplémentaire pour toutes les données est fournie par la mise en miroir bidirectionnelle entre les serveurs. Les nouvelles écritures dans le volume sont effectuées dans la partie miroir avec deux copies sur des disques physiques distincts sur chaque serveur. À mesure que se remplit la partie miroir du volume sur chaque serveur, les données les plus anciennes sont converties et enregistrées dans la partie parité en arrière-plan. Ainsi, chaque serveur a les données du volume en miroir bidirectionnel ou dans une structure de parité unique. Ceci est similaire à la façon dont fonctionne la parité avec accélération par miroir, avec la différence que celle-ci nécessite quatre serveurs dans le cluster et le pool de stockage et utilise un algorithme de parité différent.



Efficacité de la capacité
L’efficacité de la capacité est le rapport entre l’espace utilisable et l’empreinte du volume. Elle décrit la surcharge de capacité attribuable à la résilience et dépend de l’option de résilience que vous choisissez. Par exemple, le stockage de données sans résilience présente une efficacité de capacité de 100 % (1 To de données occupe jusqu’à 1 To de capacité de stockage physique), tandis que la mise en miroir bidirectionnelle est efficace à 50 % (1 To de données occupe jusqu’à 2 To de capacité de stockage physique).
La miroir bidirectionnel imbriqué écrit quatre copies de tout. Cela signifie que pour stocker 1 To de données, vous devez disposer de 4 To de capacité de stockage physique. Malgré sa simplicité séduisante, l’efficacité de la capacité du miroir bidirectionnel imbriqué de 25 % est la plus faible de toutes les options de résilience dans les espaces de stockage direct.
La parité imbriquée avec accélération par miroir permet d’atteindre une efficacité de la capacité supérieure, de l’ordre de 35 à 40 %, qui dépend de deux facteurs : le nombre de lecteurs de capacité dans chaque serveur et la combinaison miroir/parité que vous spécifiez pour le volume. Ce tableau indique les configurations courantes :
Lecteurs de capacité par serveur Miroir 10 % Miroir 20 % Miroir 30% 4 35,7 % 34,1 % 32,6 % 5 37,7 % 35,7 % 33,9 % 6 39,1 % 36,8 % 34,7 % 7+ 40,0 % 37,5 % 35,3 % Voici un exemple chiffré complet. Supposons que nous avons six lecteurs de capacité dans deux serveurs distincts et que nous voulons créer un volume de 100 Go composé de 10 Go de miroir et de 90 Go de parité. Le miroir bidirectionnel au niveau des serveurs présente une efficacité de 50,0 %, ce qui signifie que le stockage des 10 Go de données miroir nécessite 20 Go sur chaque serveur. Avec une mise en miroir sur les deux serveurs, l’empreinte totale est de 40 Go. La parité unique locale au niveau des serveurs, dans ce cas, est de 5/6, soit une efficacité de 83,3 %, ce qui signifie que le stockage des 90 Go de données de parité nécessite 108 Go sur chaque serveur. Avec une mise en miroir sur les deux serveurs, l’empreinte totale est de 216 Go. L’empreinte totale est donc [(10 Go / 50,0 %) + (90 Go / 83,3 %)] × 2 = 256 Go, pour une efficacité globale de 39,1 %.
Notez que l’efficacité de la capacité de la mise en miroir bidirectionnelle classique (environ 50 %) et la parité imbriquée avec accélération par miroir (jusqu’à 40 %) ne sont pas très différentes. Selon vos exigences, cela peut valoir la peine d’avoir une efficacité de la capacité légèrement inférieure pour bénéficier d’une augmentation sensible de la disponibilité du stockage. Vous choisissez la résilience par volume, de sorte que vous pouvez combiner des volumes de résilience imbriqués et des volumes de miroir bidirectionnel classiques au sein du même cluster.


Créer des volumes à résilience imbriquée
Vous pouvez utiliser des applets de commande de stockage familières dans PowerShell pour créer des volumes à résilience imbriquée, comme décrit dans la section suivante.
Étape 1 : Créer des modèles de niveau de stockage (Windows Server 2019 uniquement)
Windows Server 2019 nécessite la création de nouveaux modèles de niveaux de stockage à l’aide de l’applet de commande New-StorageTier avant de créer des volumes. Vous ne devez le faire qu’une seule fois. Chaque volume que vous créez par la suite peut référencer ces modèles.
Notes
Si vous exécutez Windows Server 2022, Azure Stack HCI 21H2 ou Azure Stack HCI 20H2, vous pouvez ignorer cette étape.
Spécifiez la valeur -MediaType de vos lecteurs de capacité et, éventuellement, la valeur -FriendlyName de votre choix. Ne modifiez pas d’autres paramètres.
Par exemple, si vos lecteurs de capacité sont des lecteurs de disque dur (HDD), lancez PowerShell en tant qu’administrateur et exécutez les applets de commande suivantes.
Pour créer un niveau NestedMirror :
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedMirrorOnHDD -ResiliencySettingName Mirror -MediaType HDD -NumberOfDataCopies 4
Pour créer un niveau NestedParity :
New-StorageTier -StoragePoolFriendlyName S2D* -FriendlyName NestedParityOnHDD -ResiliencySettingName Parity -MediaType HDD -NumberOfDataCopies 2 -PhysicalDiskRedundancy 1 -NumberOfGroups 1 -FaultDomainAwareness StorageScaleUnit -ColumnIsolation PhysicalDisk
Si vos lecteurs de capacité sont des disques SSD (Solid-State Drives), définissez -MediaType sur SSD, puis remplacez -FriendlyName par *OnSSD. Ne modifiez pas d’autres paramètres.
Conseil
Vérifiez que Get-StorageTier a créé les niveaux correctement.
Étape 2 : Créer des volumes imbriqués
Créez des volumes avec l’applet de commande New-Volume.
Miroir bidirectionnel imbriqué
Pour utiliser un miroir bidirectionnel imbriqué, référencez le modèle de niveau
NestedMirroret spécifiez la taille. Par exemple :New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume01 -StorageTierFriendlyNames NestedMirrorOnHDD -StorageTierSizes 500GBSi vos lecteurs de capacité sont des disques SSD (Solid-State Drives), remplacez
-StorageTierFriendlyNamespar*OnSSD.Parité imbriquée avec accélération par miroir
Pour utiliser la parité imbriquée avec accélération par miroir, référencez les modèles de niveau
NestedMirroretNestedParityet spécifiez deux tailles, une pour chaque partie du volume (miroir d’abord, parité ensuite). Par exemple, pour créer un volume de 500 Go imbriqué à 20 % de miroir bidirectionnel et à 80 % de parité imbriquée, exécutez :New-Volume -StoragePoolFriendlyName S2D* -FriendlyName Volume02 -StorageTierFriendlyNames NestedMirrorOnHDD, NestedParityOnHDD -StorageTierSizes 100GB, 400GBSi vos lecteurs de capacité sont des disques SSD (Solid-State Drives), remplacez
-StorageTierFriendlyNamespar*OnSSD.
Étape 3 : Continuer dans Windows Admin Center
Les volumes qui utilisent la résilience imbriquée apparaissent dans Windows Admin Center avec un étiquetage clair, comme dans la capture d’écran suivante. Une fois qu’ils sont créés, vous pouvez les gérer et les superviser avec Windows Admin Center comme n’importe quel autre volume dans les espaces de stockage direct.

Facultatif : Étendre aux lecteurs de cache
Avec ses paramètres par défaut, la résilience imbriquée offre une protection contre la perte simultanée de plusieurs lecteurs de capacité ou d’un serveur et d’un lecteur de capacité. Pour étendre cette protection aux lecteurs de cache, il existe une autre considération : étant donné que les lecteurs de cache fournissent souvent une mise en cache en lecture et en écriture pour plusieurs lecteurs de capacité, la seule façon de vous assurer que vous pouvez tolérer la perte d’un lecteur de cache lorsque l’autre serveur est en panne consiste à ne pas mettre en cache les écritures, mais cela a un impact sur les performances.
Pour résoudre ce scénario, les espaces de stockage direct offrent la possibilité de désactiver automatiquement la mise en cache en écriture quand un serveur d’un cluster à deux serveurs est en panne, puis de réactiver la mise en cache en écriture une fois que le serveur est rétabli. Pour autoriser les redémarrages de routine sans impacter les performances, la mise en cache en écriture n’est pas désactivée tant que le serveur n’a pas été arrêté pendant 30 minutes. Une fois la mise en cache en écriture désactivée, le contenu du cache en écriture est écrit sur les appareils de capacité. Ensuite, le serveur peut tolérer la défaillance d’un dispositif de cache dans le serveur en ligne, même si les lectures à partir du cache peuvent être retardées ou échouer en cas de défaillance d’un dispositif de cache.
Notes
Pour un système physique à mise en cache générale (type de support unique), vous n’avez pas besoin d’envisager la désactivation automatique de la mise en cache en écriture quand un serveur d’un cluster à deux serveurs est arrêté. Vous ne devez l’envisager qu’avec le cache SBL (Storage Bus Layer), ce qui est nécessaire uniquement si vous utilisez des disques durs.
(Facultatif) Pour désactiver automatiquement la mise en cache en écriture quand un serveur d’un cluster à deux serveurs est arrêté, lancez PowerShell en tant qu’administrateur et exécutez :
Get-StorageSubSystem Cluster* | Set-StorageHealthSetting -Name "System.Storage.NestedResiliency.DisableWriteCacheOnNodeDown.Enabled" -Value "True"
Une fois défini sur True, le comportement du cache est le suivant :
| Situation | Comportement du cache | Peut tolérer la perte d’un lecteur du cache ? |
|---|---|---|
| Les deux serveurs sont en marche | Mise en cache des lectures et des écritures, performances complètes | Oui |
| Serveur arrêté, les 30 premières minutes | Mise en cache des lectures et des écritures, performances complètes | Non (temporairement) |
| Après les 30 premières minutes | Mise en cache des lectures uniquement, performances impactées | Oui (une fois le cache écrit sur les lecteurs de capacité) |
Forum aux questions
Trouvez des réponses aux questions fréquemment posées sur la résilience imbriquée.
Puis-je convertir un volume existant entre un miroir bidirectionnel et une résilience imbriquée ?
Non, les volumes ne peuvent pas être convertis entre des types de résilience. Pour les nouveaux déploiements sur Azure Stack HCI, Windows Server 2022 ou Windows Server 2019, décidez à l’avance quel type de résilience répond le mieux à vos besoins. Si vous effectuez une mise à niveau à partir de Windows Server 2016, vous pouvez créer des volumes avec résilience imbriquée, migrer vos données, puis supprimer les volumes plus anciens.
Puis-je utiliser la résilience imbriquée avec plusieurs types de lecteurs de capacité ?
Oui, spécifiez simplement le -MediaType de chaque niveau en conséquence à l’étape 1 ci-dessus. Par exemple, si un même cluster combine les technologies NVMe, SSD et HDD, NVMe fournit le cache tandis que les deux autres technologies fournissent la capacité : définissez le niveau NestedMirror sur -MediaType SSD et le niveau NestedParity sur -MediaType HDD. Dans ce cas, l’efficacité de la capacité de parité dépend uniquement du nombre de lecteurs HDD et vous avez besoin d’au moins 4 de ces lecteurs par serveur.
Puis-je utiliser la résilience imbriquée avec trois serveurs ou plus ?
Non, utilisez uniquement la résilience imbriquée si votre cluster a exactement deux serveurs.
De combien de lecteurs ai-je besoin pour utiliser la résilience imbriquée ?
Le nombre minimal de lecteurs requis pour les espaces de stockage direct est de quatre lecteurs de capacité par nœud serveur, plus deux lecteurs de cache par nœud serveur (le cas échéant). Cela n’a pas changé par rapport à Windows Server 2016. Il n’existe aucune autre exigence pour la résilience imbriquée, et la recommandation en matière de capacité de réserve n’a pas changé non plus.
La résilience imbriquée change-t-elle la façon dont un lecteur est remplacé ?
Non.
La résilience imbriquée change-t-elle la façon dont un nœud serveur est remplacé ?
Non. Pour remplacer un nœud serveur et ses lecteurs, suivez cet ordre :
- Mettre hors service les lecteurs sur le serveur de trafic sortant
- Ajouter le nouveau serveur, avec ses lecteurs, au cluster
- Le pool de stockage se rééquilibre
- Supprimer le serveur de trafic sortant et ses lecteurs
Pour plus d’informations, consultez l’article Supprimer des serveurs.