Métriques pour Application Gateway
Application Gateway publie des points de données sur Azure Monitor pour les performances de vos instances d’Application Gateway et de vos instances principales. Ces points de données sont appelés des métriques, et il s’agit de valeurs numériques contenues dans un jeu ordonné de données de séries chronologiques. Les métriques présentent un certain aspect de votre passerelle applicative à un moment donné. Si des requêtes transitent par Application Gateway, les métriques sont mesurées et envoyées par intervalles de 60 secondes. Si aucune requête ne passe par Application Gateway ou s’il n’y a aucune donnée pour une métrique, la métrique n’est pas signalée. Pour plus d’informations, voir Mesures Azure Monitor.
Métriques prises en charge par le SKU Application Gateway v2
Remarque
Pour obtenir des informations sur le proxy TLS/TCP, consultez référence de données.
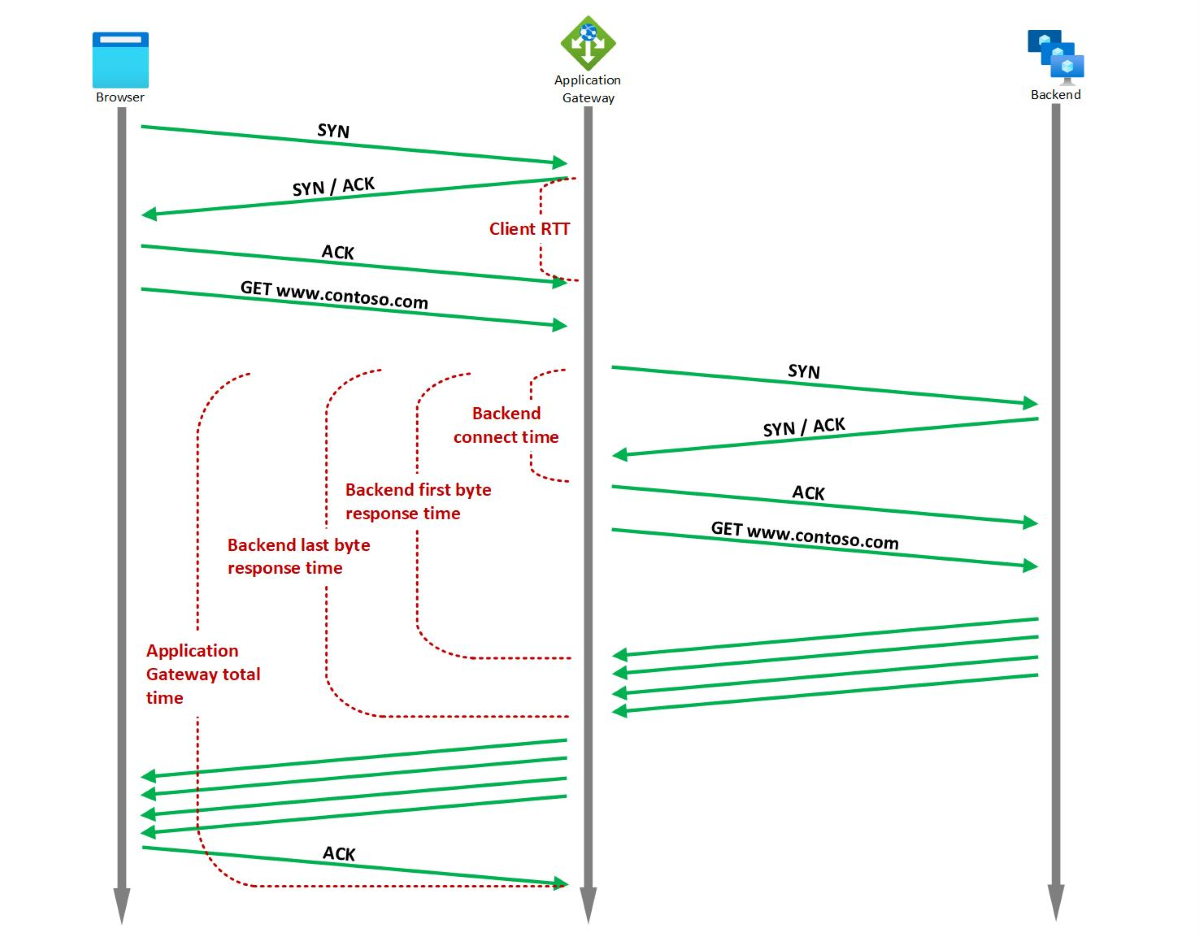
Métriques de minutage
Application Gateway fournit plusieurs métriques de minutage intégrées associées à la requête et à la réponse, qui sont toutes mesurées en millisecondes.
Remarque
S’il existe plusieurs écouteurs dans Application Gateway, filtrez toujours par dimension Écouteur tout en comparant différentes mesures de latence afin d’obtenir une inférence significative.
Temps de connexion au principal
type d’agrégation : Moy/Max
Temps passé à établir une connexion avec l’application principale.
Cela comprend la latence du réseau ainsi que le temps pris par la pile TCP du serveur back-end pour établir de nouvelles connexions. Pour TLS, il comprend également le temps consacré à l’établissement d’une liaison.
Temps de réponse du premier octet du principal
type d’agrégation : Moy/Max
Intervalle de temps entre le début de l’établissement d’une connexion au serveur principal et la réception du premier octet de l’en-tête de la réponse.
Cela correspond approximativement à la somme du temps de connexion au principal, du temps pris par la demande pour atteindre le principal depuis Application Gateway, du temps pris par l’application principale pour répondre (le temps nécessaire au serveur pour générer du contenu, extraire potentiellement des requêtes de base de données) et du temps mis par le premier octet de la réponse à atteindre Application Gateway à partir du principal.
Temps de réponse du dernier octet du principal
type d’agrégation : Moy/Max
Intervalle de temps entre le début de l’établissement d’une connexion au serveur principal et la réception du dernier octet du corps de la réponse.
Cela correspond approximativement à la somme du temps de réponse du premier octet du principal et du temps de transfert des données (ce nombre peut varier considérablement en fonction de la taille des objets demandés et de la latence du réseau du serveur).
Durée totale d’Application Gateway
type d’agrégation : Moy/Max
Cette métrique capture le temps moyen/maximal nécessaire pour qu’une demande soit reçue, traitée et sa réponse à envoyer.
Il s’agit de l’intervalle entre le moment où Application Gateway reçoit le premier octet de la requête HTTP et le moment où le dernier octet de la réponse a été envoyé au client. Cela comprend le temps qu’Application Gateway prend pour le traitement, le temps de réponse du dernier octet du serveur principal, ainsi que le temps qu’Application Gateway prend pour envoyer toutes les réponses.
RTT client
type d’agrégation : Moy/Max
Cette métrique capture le temps moyen/maximal d’aller-retour entre les clients et Application Gateway.
Ces métriques peuvent être utilisées pour déterminer si le ralentissement observé est dû au réseau client, aux performances d’Application Gateway, à la saturation de la pile TCP du réseau principal et du serveur principal, aux performances de l’application principale ou à la taille volumineuse des fichiers.
Par exemple, s’il existe un pic dans la tendance Temps de réponse du premier octet du principal, mais que la tendance Temps de connexion au principal est stable, il peut être déduit que la latence de la passerelle d’application vers le principal et le temps nécessaire pour établir la connexion sont stables, et que le pic est dû à une augmentation du temps de réponse de l’application principale. En revanche, si le pic dans Temps de réponse du premier octet du principal est associé à un pic correspondant dans Temps de connexion au principal, il peut être déduit que le réseau entre Application Gateway et le serveur principal ou la pile TCP du serveur principal est saturé.
Si vous remarquez un pic dans Temps de réponse du dernier octet du principal, mais que le temps de réponse du premier octet du principal est stable, il peut être déduit que le pic est dû à la demande d’un fichier plus volumineux.
De même, si la durée totale de la passerelle d’application présente un pic, mais que le temps de réponse du dernier octet du principal est stable, cela peut être le signe d’un goulot d’étranglement des performances au niveau d’Application Gateway ou d’un goulot d’étranglement dans le réseau entre le client et Application Gateway. En outre, si le client RTT présente également un pic correspondant, cela indique que la dégradation est due au réseau entre le client et le service Application Gateway.
Mesures Application Gateway
Pour Application Gateway, les métriques suivantes sont disponibles :
Octets reçus
Nombre d’octets reçus par Application Gateway à partir des clients. (Signalé en fonction de la demande « taille de contenu » uniquement. Il ne tient pas compte de la surcharge des négociations TLS, des en-têtes de paquets TCP/IP ou des retransmissions, et ne représente donc pas l’utilisation complète de la bande passante.)
Octets envoyés
Nombre d’octets envoyés par Application Gateway aux clients. (Signalé en fonction de la réponse « taille de contenu » uniquement. Il ne prend pas en compte les en-têtes de paquets TCP/IP ni les retransmissions, et ne représente donc pas l’utilisation complète de la bande passante.)
Protocole TLS du client
Nombre de demandes TLS et non-TLS initiées par le client qui a établi la connexion avec Application Gateway. Pour afficher la distribution du protocole TLS, filtrez par la dimension Protocole TLS. Cette métrique inclut les demandes traitées par la passerelle, telles que les redirections.
Unités de capacité actuelles
Nombre d’unités de capacité consommées pour équilibrer la charge du trafic. Les unités de capacité incluent 3 déterminants : l’unité Compute, les connexions persistantes et le débit. Chaque unité de capacité se compose d’au plus : 1 unité de calcul, ou 2500 connexions persistantes, ou débit de 2,22 Mbits/s.
Unités de calcul actuelles
Capacité processeur consommée. Les facteurs affectant l’unité Compute sont les connexions TLS/s, les calculs de réécriture d’URL et le traitement des règles WAF.
Connexions en cours
Nombre total de connexions simultanées actives de clients à Application Gateway
Unités de capacité facturées estimées
Avec la référence (SKU) v2, le modèle de tarification est déterminé par la consommation. Les unités de capacité mesurent le coût basé sur la consommation qui est facturé en plus du coût fixe. Les unités de capacité facturées estimées indiquent le nombre d’unités de capacité à partir duquel la facturation est estimée. Cette valeur est calculée comme étant la plus grande valeur entre Unités de capacité actuelles (unités de capacité requises pour équilibrer la charge du trafic) et Unités de capacité facturables fixes (unités de capacité minimales approvisionnées conservées).
Requêtes ayant échoué
Nombre de requêtes traitées par Application Gateway avec des codes d'erreur serveur 5xx. Cela comprend les codes 5xx générés à partir d'Application Gateway, ainsi que les codes 5xx générés à partir du serveur principal. Le nombre de demandes peut être filtré pour afficher le nombre d’affichages par combinaison de paramètres HTTP/pool principal spécifique.
Unités de capacité facturables fixes
Nombre minimal d’unités de capacité approvisionnées conservées conformément à la valeur du paramètre Unités d’échelle minimales (une instance se traduit par 10 unités de capacité) dans la configuration du service Application Gateway.
Nouvelles connexions par seconde
Nombre moyen de nouvelles connexions TCP par seconde à partir de clients au Service Application Gateway et à partir du service Application Gateway à des membres principaux.
État de la réponse
État de la réponse HTTP retourné par Application Gateway. La distribution du code d’état de la réponse peut être ultérieurement classée par catégorie afin d’afficher les réponses dans les catégories 2xx, 3xx, 4xx et 5xx.
Débit
Nombre d’octets par seconde servis par Application Gateway. (Signalé en fonction de la « taille de contenu » uniquement. Il ne tient pas compte de la surcharge des négociations TLS, des en-têtes de paquets TCP/IP ou des retransmissions, et ne représente donc pas l’utilisation complète de la bande passante.)
Total de requêtes
Nombre de demandes réussies qu’Application Gateway a traitées par les cibles du pool de back-ends. Les pages servies directement par la passerelle, telles que les redirections, ne sont pas comptabilisées et doivent figurer dans la métrique Protocole TLS du client. La métrique du nombre total de demandes peut être filtrée pour afficher le nombre d’affichages par combinaison de paramètres HTTP/pool de back-ends spécifique.
Métriques du principal
Pour Application Gateway, les métriques suivantes sont disponibles :
État de la réponse du principal
Nombre de codes d’état de réponse HTTP retournés par les principaux. Cela n’inclut pas les codes de réponse générés par Application Gateway. La distribution du code d’état de la réponse peut être ultérieurement classée par catégorie afin d’afficher les réponses dans les catégories 2xx, 3xx, 4xx et 5xx.
Nombre d’hôtes intègres
Le nombre de serveurs principaux déterminés sains par la sonde d’intégrité. Vous pouvez filtrer sur une base de pool principal pour afficher le nombre d’hôtes sains dans un pool principal spécifique.
Nombre d’hôtes défectueux
Nombre de principaux déterminés défectueux par la sonde d’intégrité. Vous pouvez filtrer sur une base de pool principal pour afficher le nombre d’hôtes non sains dans un pool principal spécifique.
Demandes par minute par hôte sain
Nombre moyen de requêtes que chaque membre sain d’un pool principal reçoit par minute. Vous devez spécifier le pool principal à l’aide de la dimension BackendPool HttpSettings.
Métriques de pare-feu d’applications web (WAF)
Pour plus d’informations sur la supervision WAF, consultez Métriques WAF v2
Métriques prises en charge par le SKU Application Gateway v1
Mesures Application Gateway
Pour Application Gateway, les métriques suivantes sont disponibles :
Utilisation du processeur
Affiche l’utilisation des processeurs alloués à Application Gateway. Dans des conditions normales, l’utilisation du processeur ne doit pas dépasser 90 %, car cela peut entraîner une latence dans les sites Web hébergés derrière Application Gateway et perturber l’expérience du client. Vous pouvez indirectement contrôler ou améliorer l'utilisation du processeur en modifiant la configuration d'Application Gateway en augmentant le nombre d'instances ou en passant à une taille SKU plus grande, ou en faisant les deux.
Connexions en cours
Nombre de connexions courantes établies avec Application Gateway
Requêtes ayant échoué
Nombre de demandes ayant échoué en raison de problèmes de connexion. Ce nombre comprend les demandes qui ont échoué en raison du paramètre HTTP « Délai d’expiration des demandes » ou de problèmes de connexion entre Application Gateway et le serveur principal. Ne sont pas comptabilisées les défaillances dues à l’absence de serveur principal sain disponible. Les réponses 4xx et 5xx du serveur principal ne sont pas non plus prises en compte dans le cadre de cette métrique.
État de la réponse
État de la réponse HTTP retourné par Application Gateway. La distribution du code d’état de la réponse peut être ultérieurement classée par catégorie afin d’afficher les réponses dans les catégories 2xx, 3xx, 4xx et 5xx.
Débit
Nombre d’octets par seconde servis par Application Gateway
Total de requêtes
Nombre de requêtes réussies servies par Application Gateway. Le nombre de demandes peut être filtré pour afficher le nombre d’affichages par combinaison de paramètres HTTP/pool principal spécifique.
Métriques du principal
Pour Application Gateway, les métriques suivantes sont disponibles :
Nombre d’hôtes intègres
Le nombre de serveurs principaux déterminés sains par la sonde d’intégrité. Vous pouvez filtrer sur une base de pool principal pour afficher le nombre d’hôtes sains dans un pool principal spécifique.
Nombre d’hôtes défectueux
Nombre de principaux déterminés défectueux par la sonde d’intégrité. Vous pouvez filtrer sur une base de pool principal pour afficher le nombre d’hôtes non sains dans un pool principal spécifique.
Métriques de pare-feu d’applications web (WAF)
Pour plus d’informations sur la supervision WAF, consultez Métriques WAF v1
Visualisation des métriques
Accédez à une passerelle d’application, sous Supervision, sélectionnez Métriques. Pour afficher les valeurs disponibles, sélectionnez la liste déroulante MÉTRIQUE.
Dans l’image suivante, consultez un exemple avec trois métriques affichées pour les 30 dernières minutes :

Pour afficher une liste actuelle des métriques, consultez Mesures prises en charge avec Azure Monitor.
Règles d’alerte sur les métriques
Vous pouvez démarrer des règles d’alerte en fonction des métriques d’une ressource. Par exemple, une alerte peut appeler un webhook ou envoyer un e-mail à un administrateur si le débit de la passerelle Application Gateway est au-dessus ou en dessous d’un seuil pour une période spécifiée.
L’exemple suivant vous guide dans la création d’une règle d’alerte qui envoie un e-mail à un administrateur lorsqu’un seuil de débit est dépassé :
Sélectionnez Ajouter une alerte Métrique pour ouvrir la page Ajouter une règle. Cette page est aussi accessible à partir de la page Métriques.
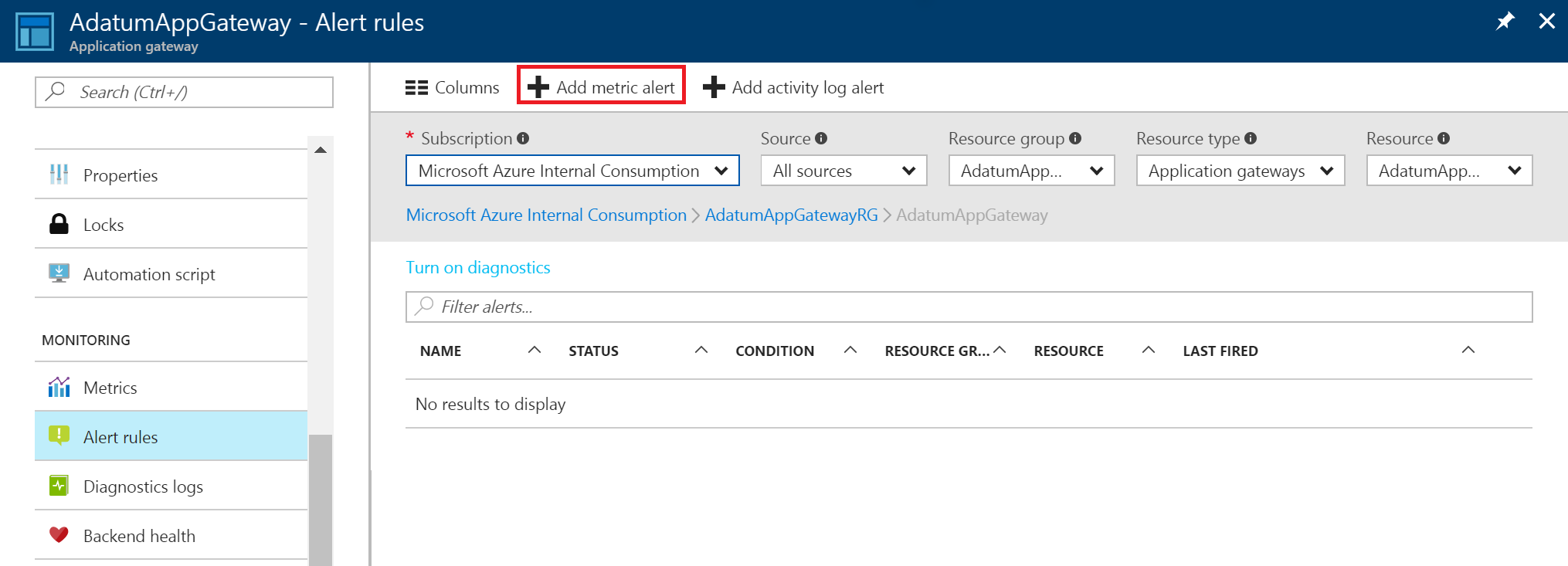
Dans la page Ajouter une règle, remplissez les sections Nom, Condition et Notifier, puis sélectionnez OK.
Dans le sélecteur Condition, sélectionnez une des 4 valeurs : Supérieur à, Supérieur ou égal à, Inférieur à ou Inférieur ou égal à.
Dans le sélecteur Période, sélectionnez une période allant de 5 minutes à 6 heures.
Si vous sélectionnez Envoyer un e-mail aux propriétaires, aux contributeurs et aux lecteurs, l’e-mail peut être dynamique, en fonction des utilisateurs qui ont accès à cette ressource. Dans le cas contraire, vous pouvez fournir une liste d’utilisateurs séparée par des virgules dans la zone Adresse(s) de messagerie d’administrateur(s) supplémentaire(s) .
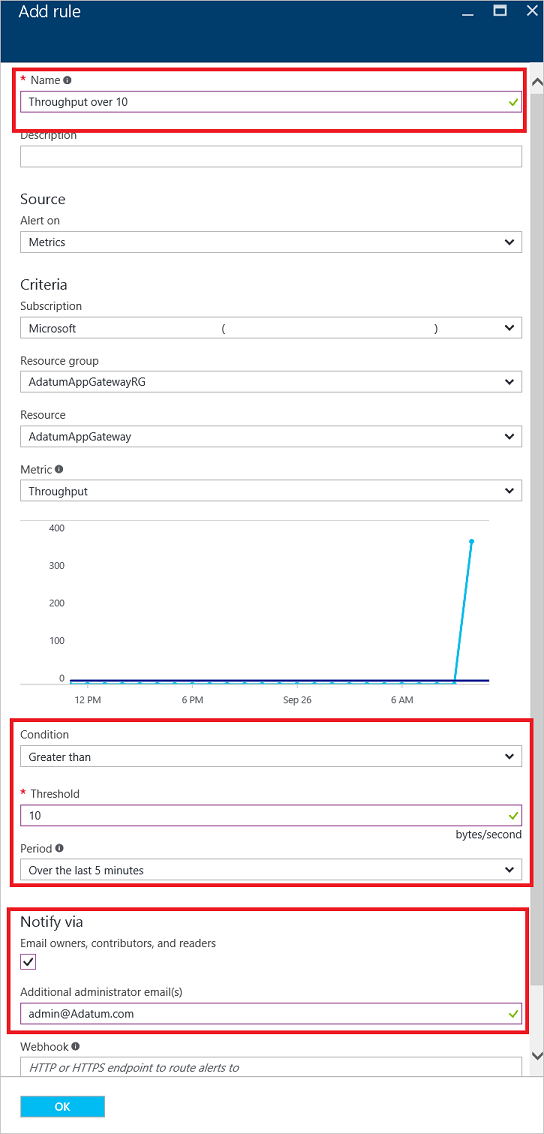
Si le seuil est dépassé, un e-mail similaire à celui de l’image suivante vous est envoyé :
Une liste d’alertes apparaît une fois que vous avez créé une alerte Métrique. Elle fournit une vue d’ensemble de toutes les règles d’alerte.
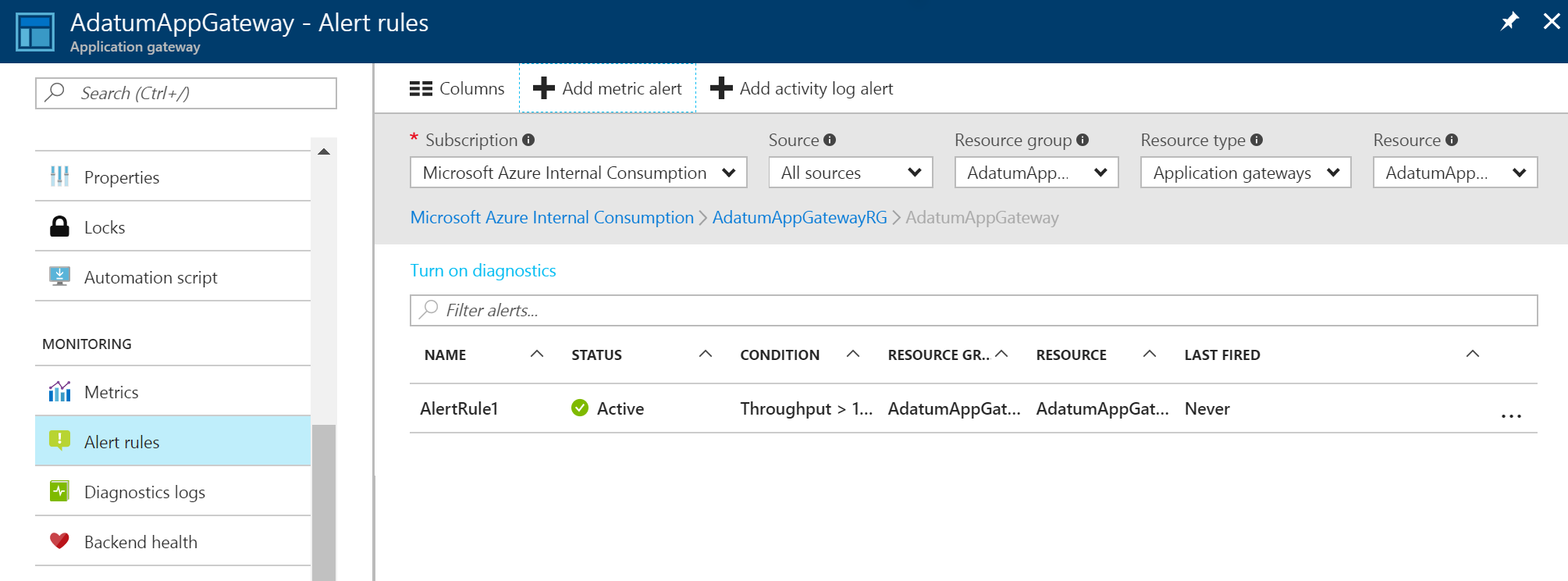
Pour en savoir plus sur les notifications d’alerte, consultez Réception de notifications d’alerte.
Pour en savoir plus sur les webhooks et sur la façon de les utiliser avec des alertes, consultez Configurer un webhook sur une alerte de métrique Azure.
Étapes suivantes
- Visualisez le compteur et les journaux des événements à l’aide des journaux d’activité Azure Monitor.
- Billet de blog sur la visualisation de votre journal d’activité Azure avec Power BI.
- Billet de blog sur l’affichage et l’analyse des journaux d’activité Azure dans Power BI.
Commentaires
Bientôt disponible : Tout au long de l’année 2024, nous abandonnerons progressivement le mécanisme de retour d’information GitHub Issues pour le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez : https://aka.ms/ContentUserFeedback.
Soumettre et afficher des commentaires pour